Architettura di base cruciale in Azure
Questa architettura fornisce indicazioni per la progettazione di un carico di lavoro cruciale in Azure. Usa funzionalità native del cloud per ottimizzare l'affidabilità e l'efficacia operativa. Applica la metodologia di progettazione per Well-Architected carichi di lavoro cruciali a un'applicazione con connessione Internet, in cui il carico di lavoro è accessibile tramite un endpoint pubblico e non richiede la connettività di rete privata ad altre risorse aziendali.
Importante
 Le linee guida sono supportate da un'implementazione di esempio di livello di produzione che illustra lo sviluppo di applicazioni cruciali in Azure. Questa implementazione può essere usata come base per un ulteriore sviluppo di soluzioni nel primo passo verso la produzione.
Le linee guida sono supportate da un'implementazione di esempio di livello di produzione che illustra lo sviluppo di applicazioni cruciali in Azure. Questa implementazione può essere usata come base per un ulteriore sviluppo di soluzioni nel primo passo verso la produzione.
Livello di affidabilità
L'affidabilità è un concetto relativo e affinché un carico di lavoro sia affidabile in modo appropriato, deve riflettere i requisiti aziendali che lo circondano, inclusi gli obiettivi del livello di servizio (SLO) e i contratti di servizio (SLA), per acquisire la percentuale di tempo in cui l'applicazione deve essere disponibile.
Questa architettura è destinata a un SLO di 99,99%, che corrisponde a un tempo di inattività annuale consentito di 52 minuti e 35 secondi. Tutte le decisioni di progettazione includono pertanto lo scopo di raggiungere questo SLO di destinazione.
Suggerimento
Per definire uno SLO realistico, è importante comprendere gli obiettivi di affidabilità di tutti i componenti di Azure e altri fattori nell'ambito dell'architettura. Per ulteriori dettagli, consulta le raccomandazioni per definire gli obiettivi di affidabilità. Questi singoli numeri devono essere aggregati per determinare un SLO composito che deve essere allineato alle destinazioni del carico di lavoro.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Progettare per i requisiti aziendali.
Strategie di progettazione chiave
Molti fattori possono influire sull'affidabilità di un'applicazione, ad esempio la possibilità di recuperare da errori, disponibilità a livello di area, efficacia della distribuzione e sicurezza. Questa architettura applica un set di strategie di progettazione generali destinate a risolvere questi fattori e garantisce che venga raggiunto il livello di affidabilità di destinazione.
Ridondanza nei livelli
Eseguire la distribuzione in più aree in un modello attivo-attivo. L'applicazione viene distribuita tra due o più aree di Azure che gestiscono il traffico utente attivo.
Usare le zone di disponibilità per tutti i servizi considerati per ottimizzare la disponibilità all'interno di una singola area di Azure, distribuendo componenti tra data center separati fisicamente all'interno di un'area.
Scegliere le risorse che supportano la distribuzione globale.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Distribuzione globale.
Francobolli di distribuzione
Distribuire un timbro a livello di area come unità di scala in cui è possibile effettuare il provisioning di un set logico di risorse in modo indipendente per mantenere il passo con le variazioni della domanda. Ogni stamp applica anche più unità di scala annidate, ad esempio le API front-end e i processori in background che possono essere ridimensionati in modo indipendente.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Architettura di unità di scala.
Distribuzioni affidabili e ripetibili
Applicare il principio dell'infrastruttura come codice (IaC) usando tecnologie, ad esempio Terraform, per fornire il controllo della versione e un approccio operativo standardizzato per i componenti dell'infrastruttura.
Implementare pipeline di distribuzione blu/verde senza tempi di inattività. Le pipeline di compilazione e rilascio devono essere completamente automatizzate per distribuire stamp come singola unità operativa, usando distribuzioni blu/verde con convalida continua applicata.
Applicare la coerenza dell'ambiente in tutti gli ambienti considerati, con lo stesso codice della pipeline di distribuzione in ambienti di produzione e pre-produzione. In questo modo si eliminano i rischi associati alla distribuzione e alle variazioni dei processi in tutti gli ambienti.
Eseguire la convalida continua integrando test automatizzati come parte dei processi DevOps, inclusi i test di carico sincronizzati e chaos, per convalidare completamente l'integrità del codice dell'applicazione e dell'infrastruttura sottostante.
Fare riferimento a Well-Architected carichi di lavoro cruciali: distribuzione e test.
Approfondimenti operativi
Disporre di aree di lavoro federate per i dati di osservabilità. I dati di monitoraggio per le risorse globali e le risorse a livello di area vengono archiviati in modo indipendente. Un archivio di osservabilità centralizzato non è consigliato per evitare un singolo punto di guasto. L'esecuzione di query tra aree di lavoro viene usata per ottenere un sink di dati unificato e un singolo riquadro di vetro per le operazioni.
Creare un modello di integrità a più livelli che esegue il mapping dell'integrità dell'applicazione a un modello di luce del traffico per la contestualizzazione. I punteggi di integrità vengono calcolati per ogni singolo componente e quindi aggregati a livello di flusso utente e combinati con i requisiti chiave non funzionali, ad esempio le prestazioni, come coefficienti per quantificare l'integrità dell'applicazione.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Modellazione dell'integrità.
Architettura

*Scaricare un file di Visio di questa architettura.
I componenti di questa architettura possono essere suddivisi in categorie in questo modo. Per la documentazione del prodotto sui servizi di Azure, vedere Risorse correlate.
Risorse globali
Le risorse globali vivono a lungo e condividono la durata del sistema. Hanno la possibilità di essere disponibili a livello globale nel contesto di un modello di distribuzione in più aree.
Ecco le considerazioni generali sui componenti. Per informazioni dettagliate sulle decisioni, vedere Risorse globali.
Servizio di bilanciamento del carico globale
Un servizio di bilanciamento del carico globale è fondamentale per il routing affidabile del traffico verso le distribuzioni a livello di area con un certo livello di garanzia in base alla disponibilità dei servizi back-end in un'area. Inoltre, questo componente deve avere la possibilità di controllare il traffico in ingresso, ad esempio tramite web application firewall.
Frontdoor di Azure viene usato come punto di ingresso globale per tutto il traffico HTTP(S) client in ingresso, con funzionalità web application firewall (WAF) applicate al traffico in ingresso sicuro di livello 7. Usa TCP Anycast per ottimizzare il routing usando la rete backbone Microsoft e consente il failover trasparente in caso di integrità a livello di area danneggiata. Il routing dipende da probe di integrità personalizzati che controllano il calore composito delle risorse internazionali chiave. Frontdoor di Azure offre anche una rete per la distribuzione di contenuti (CDN) predefinita per memorizzare nella cache gli asset statici per il componente del sito Web.
Un'altra opzione è Gestione traffico, ovvero un servizio di bilanciamento del carico di livello 4 basato su DNS. Tuttavia, l'errore non è trasparente per tutti i client perché la propagazione DNS deve verificarsi.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Routing del traffico globale.
Banca dati
Tutto lo stato correlato al carico di lavoro viene archiviato in un database esterno, Azure Cosmos DB per NoSQL. Questa opzione è stata scelta perché dispone del set di funzionalità necessario per l'ottimizzazione delle prestazioni e dell'affidabilità, sia sul lato client che sul lato server. È consigliabile che l'account abbia la scrittura multimaster abilitata.
Annotazioni
Mentre una configurazione di scrittura in più aree rappresenta lo standard gold per l'affidabilità, esiste un notevole compromesso sui costi, che dovrebbe essere considerato correttamente.
L'account viene replicato in ogni stamp a livello di area e ha anche la ridondanza zonale abilitata. Inoltre, la scalabilità automatica è abilitata a livello di contenitore in modo che i contenitori ridimensionano automaticamente la velocità effettiva con provisioning in base alle esigenze.
Per altre informazioni, vedere Piattaforma dati per carichi di lavoro cruciali.
Fare riferimento a Well-Architected carichi di lavoro cruciali: archivio dati multi-scrittura distribuito a livello globale.
Registro dei container
Registro Azure Container viene usato per archiviare tutte le immagini del contenitore. Include funzionalità di replica geografica che consentono alle risorse di funzionare come un unico registro, servendo più aree con registri regionali multimaster.
Come misura di sicurezza, consentire l'accesso solo alle entità necessarie e autenticare tale accesso. Nell'implementazione, ad esempio, l'accesso amministratore è disabilitato. Il cluster di calcolo può quindi eseguire il pull delle immagini solo con assegnazioni di ruolo Microsoft Entra.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Registro Contenitori.
Risorse a livello di area
Il provisioning delle risorse a livello di area viene effettuato come parte di un stamp di distribuzione in una singola area di Azure. Queste risorse non condividono nulla con le risorse in un'altra area. Possono essere rimossi o replicati in modo indipendente in aree aggiuntive. Tuttavia, condividono le risorse globali tra loro.
In questa architettura, una pipeline di distribuzione unificata distribuisce un timbro con queste risorse.
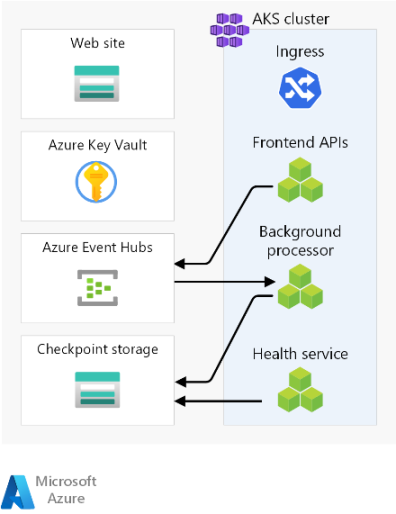
Ecco le considerazioni generali sui componenti. Per informazioni dettagliate sulle decisioni, vedere Risorse stamp a livello di area.
Front-end
Questa architettura usa un'applicazione a pagina singola che invia richieste ai servizi back-end. Un vantaggio è che il calcolo necessario per l'esperienza del sito Web viene scaricato nel client anziché nei server. L'applicazione a pagina singola è ospitata come sito Web statico in un account di archiviazione di Azure.
Il contenuto statico viene in genere memorizzato nella cache in un archivio vicino al client, usando una rete per la distribuzione di contenuti (RETE CDN), in modo che i dati possano essere gestiti rapidamente senza comunicare direttamente con i server back-end. È un modo conveniente per aumentare l'affidabilità e ridurre la latenza di rete. In questa architettura, le funzionalità predefinite della rete CDN di Frontdoor di Azure vengono usate per memorizzare nella cache il contenuto del sito Web statico nella rete perimetrale.
Cluster di elaborazione
Il calcolo back-end esegue un'applicazione composta da tre microservizi ed è senza stato. La containerizzazione è quindi una strategia appropriata per ospitare l'applicazione. Il servizio Azure Kubernetes è stato scelto perché soddisfa la maggior parte dei requisiti aziendali e Kubernetes è ampiamente adottato in molti settori. Il servizio Azure Kubernetes supporta topologie avanzate di scalabilità e distribuzione. Il livello del contratto di servizio Tempo di attività del servizio Azure Kubernetes è altamente consigliato per l'hosting di applicazioni cruciali perché offre garanzie di disponibilità per il piano di controllo Kubernetes.
Azure offre altri servizi di calcolo, ad esempio Funzioni di Azure e Servizi app di Azure. Queste opzioni scaricano responsabilità di gestione aggiuntive in Azure a costo di flessibilità e densità.
Annotazioni
Evitare di archiviare lo stato nel cluster di calcolo, tenendo presente la natura temporanea dei francobolli. Quanto più possibile, rendere persistente lo stato in un database esterno per mantenere leggere le operazioni di ridimensionamento e ripristino. Ad esempio, nel servizio Azure Kubernetes i pod cambiano frequentemente. Il collegamento dello stato ai pod aggiungerà il carico di coerenza dei dati.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Orchestrazione dei contenitori e Kubernetes.
Broker messaggi a livello di area
Per ottimizzare le prestazioni e mantenere la velocità di risposta durante il picco di carico, la progettazione usa la messaggistica asincrona per gestire flussi di sistema intensivi. Poiché una richiesta viene riconosmessa rapidamente alle API front-end, la richiesta viene accodata anche in un broker di messaggi. Questi messaggi vengono successivamente utilizzati da un servizio back-end che, ad esempio, gestisce un'operazione di scrittura in un database.
L'intero timbro è senza stato tranne in determinati punti, ad esempio questo broker di messaggi. I dati vengono accodati nel broker per un breve periodo di tempo. Il broker di messaggi deve garantire almeno una volta il recapito. Ciò significa che i messaggi saranno nella coda, se il broker non sarà più disponibile dopo il ripristino del servizio. Tuttavia, è responsabilità dell'utente determinare se tali messaggi richiedono ancora l'elaborazione. La coda viene svuotata dopo l'elaborazione e l'archiviazione del messaggio in un database globale.
In questa progettazione viene usato Hub eventi di Azure . Viene effettuato il provisioning di un account di archiviazione di Azure aggiuntivo per il checkpoint. Hub eventi è la scelta consigliata per i casi d'uso che richiedono una velocità effettiva elevata, ad esempio lo streaming di eventi.
Per i casi d'uso che richiedono garanzie di messaggio aggiuntive, è consigliabile usare il bus di servizio di Azure. Consente commit in due fasi con un cursore lato client, nonché funzionalità come una coda di messaggi non recapitabili predefinita e funzionalità di deduplicazione.
Per altre informazioni, vedere Servizi di messaggistica per carichi di lavoro cruciali.
Fare riferimento a Well-Architected carichi di lavoro cruciali: architettura basata su eventi ad accoppiamento debole.
Archivio segreti a livello di area
Ogni stamp ha un proprio insieme di credenziali delle chiavi di Azure che archivia i segreti e la configurazione. Esistono segreti comuni, ad esempio le stringhe di connessione al database globale, ma esistono anche informazioni univoche per un singolo stamp, ad esempio la stringa di connessione di Hub eventi. Inoltre, le risorse indipendenti evitano un singolo punto di errore.
Fare riferimento a Well-Architected carichi di lavoro cruciali: Protezione dell'integrità dei dati.
Pipeline di distribuzione
Le pipeline di compilazione e rilascio per un'applicazione mission-critical devono essere completamente automatizzate. Non è pertanto necessario eseguire manualmente alcuna azione. Questa progettazione illustra pipeline completamente automatizzate che distribuiscono un timbro convalidato in modo coerente ogni volta. Un altro approccio alternativo consiste nel distribuire solo gli aggiornamenti in sequenza in un timbro esistente.
Repository del codice sorgente
GitHub viene usato per il controllo del codice sorgente, fornendo una piattaforma basata su Git a disponibilità elevata per la collaborazione sul codice dell'applicazione e sul codice dell'infrastruttura.
Pipeline di integrazione continua/recapito continuo (CI/CD)
Le pipeline automatizzate sono necessarie per la compilazione, il test e la distribuzione di un carico di lavoro mission in ambienti di preproduzione e produzione. Azure Pipelines viene scelto in base al set di strumenti avanzato che può essere destinato ad Azure e ad altre piattaforme cloud.
Un'altra scelta è GitHub Actions per le pipeline CI/CD. Il vantaggio aggiunto è che il codice sorgente e la pipeline possono essere collocati. Tuttavia, Azure Pipelines è stato scelto a causa delle funzionalità cd più avanzate.
Fare riferimento a Well-Architected carichi di lavoro cruciali: processi DevOps.
Agenti di compilazione
Gli agenti di compilazione ospitati da Microsoft vengono usati da questa implementazione per ridurre la complessità e il sovraccarico di gestione. Gli agenti self-hosted possono essere usati per scenari che richiedono un comportamento di sicurezza con protezione avanzata.
Annotazioni
L'uso di agenti self-hosted è illustrato nell'implementazione di riferimento Mission Critical - Connected .
Risorse di osservabilità
I dati operativi dell'applicazione e dell'infrastruttura devono essere disponibili per consentire operazioni efficaci e ottimizzare l'affidabilità. Questo riferimento fornisce una baseline per ottenere un'osservabilità olistica di un'applicazione.
Sink di dati unificato
- Azure Log Analytics viene usato come sink unificato per archiviare log e metriche per tutti i componenti dell'applicazione e dell'infrastruttura.
- Azure Application Insights viene usato come strumento APM (Application Performance Management) per raccogliere tutti i dati di monitoraggio delle applicazioni e archiviarlo direttamente all'interno di Log Analytics.

I dati di monitoraggio per le risorse globali e le risorse a livello di area devono essere archiviati in modo indipendente. Un singolo archivio di osservabilità centralizzato non è consigliato per evitare un singolo punto di guasto. L'esecuzione di query tra aree di lavoro viene usata per ottenere un singolo riquadro di vetro.
In questa architettura, il monitoraggio delle risorse all'interno di un'area deve essere indipendente dal timbro stesso, perché se si elimina un timbro, si vuole comunque mantenere l'osservabilità. Ogni stamp a livello di area ha un proprio application insights dedicato e un'area di lavoro Log Analytics. Le risorse vengono sottoposte a provisioning per area, ma hanno una vita maggiore degli indicatori.
Analogamente, i dati di servizi condivisi, ad esempio Frontdoor di Azure, Azure Cosmos DB e Registro Contenitori, vengono archiviati in un'istanza dedicata dell'area di lavoro Log Analytics.
Archiviazione e analisi dei dati
I dati operativi non necessari per le operazioni attive vengono esportati da Log Analytics negli account di archiviazione di Azure per scopi di conservazione dei dati e per fornire un'origine analitica per AIOps, che può essere applicata per ottimizzare il modello di integrità delle applicazioni e le procedure operative.
Fare riferimento a Carichi di lavoro cruciali ben progettato: azione predittiva e operazioni di intelligenza artificiale.
Flussi di richiesta e processore
Questa immagine mostra il flusso della richiesta e del processore in background dell'implementazione di riferimento.

La descrizione di questo flusso è descritta nelle sezioni seguenti.
Flusso di richiesta del sito Web
Una richiesta per l'interfaccia utente Web viene inviata a un servizio di bilanciamento del carico globale. Per questa architettura, il servizio di bilanciamento del carico globale è Frontdoor di Azure.
Le regole WAF vengono valutate. Le regole WAF influiscono positivamente sull'affidabilità del sistema proteggendo da un'ampia gamma di attacchi, ad esempio XSS (Cross-Site Scripting) e SQL injection. Frontdoor di Azure restituirà un errore al richiedente se una regola WAF viene violata e l'elaborazione viene arrestata. Se non sono state violate regole WAF, Frontdoor di Azure continua l'elaborazione.
Frontdoor di Azure usa regole di routing per determinare il pool back-end a cui inoltrare una richiesta. Modalità di corrispondenza delle richieste con una regola di routing. In questa implementazione di riferimento, le regole di routing consentono a Frontdoor di Azure di instradare le richieste dell'interfaccia utente e dell'API front-end a risorse back-end diverse. In questo caso, il modello "/*" corrisponde alla regola di routing dell'interfaccia utente. Questa regola indirizza la richiesta a un pool back-end che contiene account di archiviazione con siti Web statici che ospitano l'applicazione a pagina singola. Frontdoor di Azure usa la priorità e il peso assegnati ai back-end nel pool per selezionare il back-end per instradare la richiesta. Metodi di routing del traffico all'origine. Frontdoor di Azure usa probe di integrità per assicurarsi che le richieste non vengano instradate ai back-end non integri. L'applicazione a pagina singola viene servita dall'account di archiviazione selezionato con il sito Web statico.
Annotazioni
I termini pool back-end e back-end nella versione classica di Frontdoor di Azure sono denominatigruppi di origine e origini nei livelli Standard o Premium di Frontdoor di Azure.
L'applicazione a pagina singola effettua una chiamata API all'host front-end di Frontdoor di Azure. Il modello dell'URL della richiesta API è "/api/*".
Flusso di richieste API front-end
Le regole WAF vengono valutate come nel passaggio 2.
Frontdoor di Azure corrisponde alla richiesta alla regola di routing dell'API in base al modello "/api/*". La regola di routing api indirizza la richiesta a un pool back-end che contiene gli indirizzi IP pubblici per i controller di ingresso NGINX che sanno instradare le richieste al servizio corretto nel servizio Azure Kubernetes. Come in precedenza, Frontdoor di Azure usa la priorità e il peso assegnati ai back-end per selezionare il back-end corretto del controller di ingresso NGINX.
Per le richieste GET, l'API front-end esegue operazioni di lettura in un database. Per questa implementazione di riferimento, il database è un'istanza globale di Azure Cosmos DB. Azure Cosmos DB offre diverse funzionalità che lo rendono una buona scelta per un carico di lavoro cruciale, inclusa la possibilità di configurare facilmente aree con più scritture, consentendo il failover automatico per le letture e le scritture nelle aree secondarie. L'API usa l'SDK client configurato con la logica di ripetizione dei tentativi per comunicare con Azure Cosmos DB. L'SDK determina l'ordine ottimale delle aree di Azure Cosmos DB disponibili con cui comunicare in base al parametro ApplicationRegion.
Per le richieste POST o PUT, l'API Front-end esegue operazioni di scrittura in un broker di messaggi. Nell'implementazione di riferimento, il broker di messaggi è Hub eventi di Azure. In alternativa, è possibile scegliere il bus di servizio. Un gestore leggerà successivamente i messaggi dal broker di messaggi ed eseguirà le operazioni di scrittura necessarie in Azure Cosmos DB. L'API usa l'SDK client per eseguire operazioni di scrittura. Il client può essere configurato per i tentativi.
Flusso del processore in background
I processori in background elaborano i messaggi dal broker di messaggi. I processori in background usano l'SDK client per eseguire letture. Il client può essere configurato per i tentativi.
I processori in background eseguono le operazioni di scrittura appropriate nell'istanza globale di Azure Cosmos DB. I processori in background usano l'SDK client configurato con nuovi tentativi per connettersi ad Azure Cosmos DB. L'elenco di aree preferite del client può essere configurato con più aree. In tal caso, se una scrittura ha esito negativo, il nuovo tentativo verrà eseguito nella successiva area preferita.
Aree di progettazione
È consigliabile esplorare queste aree di progettazione per consigli e indicazioni sulle procedure consigliate durante la definizione dell'architettura mission-critical.
| Area di progettazione | Descrizione |
|---|---|
| progettazione di applicazioni | Schemi di progettazione che consentono il ridimensionamento e la gestione degli errori. |
| piattaforma dell'applicazione | Scelte e mitigazioni dell'infrastruttura per potenziali casi di errore. |
| piattaforma dati | Scelte nelle tecnologie dell'archivio dati, informate valutando le caratteristiche necessarie di volume, velocità, varietà e veridicità. |
| Rete e connettività | Considerazioni sulla rete per il routing del traffico in ingresso agli indicatori. |
| Modellazione dell'integrità | Considerazioni sull'osservabilità tramite l'analisi dell'impatto del cliente correlate al monitoraggio per determinare l'integrità complessiva dell'applicazione. |
| Distribuzione e test | Strategie per le pipeline CI/CD e considerazioni sull'automazione, con scenari di test incorporati, ad esempio test di carico sincronizzati e test di iniezione di errori (chaos). |
| sicurezza | Mitigazione dei vettori di attacco tramite il modello Microsoft Zero Trust. |
| Procedure operative | Processi correlati alla distribuzione, alla gestione delle chiavi, all'applicazione di patch e agli aggiornamenti. |
** Indica le considerazioni relative all'area di progettazione specifiche di questa architettura.
" output is necessary.)
Per la documentazione del prodotto sui servizi di Azure usati in questa architettura, vedere questi articoli.
- Frontdoor di Azure
- Azure Cosmos DB
- Registro dei contenitori di Azure
- Log Analytics di Azure
- Azure Key Vault
- Bus di servizio di Azure
- Servizio Azure Kubernetes
- Azure Application Insights
- Hub eventi di Azure
- Archiviazione BLOB di Azure
Distribuire questa architettura
Distribuire l'implementazione di riferimento per ottenere una comprensione completa delle risorse considerate, incluso il modo in cui vengono operative in un contesto mission-critical. Contiene una guida alla distribuzione destinata a illustrare un approccio orientato alla soluzione per lo sviluppo di applicazioni cruciali in Azure.
Passaggi successivi
Per estendere l'architettura di base con controlli di rete sul traffico in ingresso e in uscita, vedere questa architettura.