Provider di archiviazione di Azure (Funzioni di Azure)
Questo documento descrive le caratteristiche del provider di archiviazione di Azure Durable Functions, con un focus sugli aspetti di prestazioni e scalabilità. Il provider di archiviazione di Azure è il provider predefinito. Archivia gli stati dell'istanza e le code in un account di Archiviazione di Azure (versione classica).
Nota
Per altre informazioni sui provider di archiviazione supportati per Durable Functions e su come confrontano, vedere la documentazione dei provider di archiviazione Durable Functions.
Nel provider di archiviazione di Azure tutte le operazioni vengono guidate dalle code di Archiviazione di Azure. L'orchestrazione e lo stato e la cronologia delle entità vengono archiviati in Tabelle di Azure. I BLOB e i lease BLOB di Azure vengono usati per distribuire istanze e entità di orchestrazione in più istanze dell'app (note anche come lavoratori o semplicemente macchine virtuali). Questa sezione illustra in dettaglio i vari artefatti di Archiviazione di Azure e il modo in cui influiscono sulle prestazioni e sulla scalabilità.
Rappresentazione di archiviazione
Un hub attività mantiene duramente tutti gli stati di istanza e tutti i messaggi. Per una rapida panoramica del modo in cui vengono usati per tenere traccia dello stato di avanzamento di un'orchestrazione, vedere l'esempio di esecuzione dell'hub attività.
Il provider di archiviazione di Azure rappresenta l'hub attività nell'archiviazione usando i componenti seguenti:
- Tra due e tre tabelle di Azure. Due tabelle vengono usate per rappresentare cronologie e stati di istanza. Se Gestione partizioni tabelle è abilitato, viene introdotta una terza tabella per archiviare le informazioni di partizione.
- Una coda di Azure archivia i messaggi di attività.
- Una o più code di Azure archivia i messaggi di istanza. Ognuna di queste code di controllo cosiddette rappresenta una partizione assegnata a un subset di tutti i messaggi di istanza, in base all'hash dell'ID istanza.
- Alcuni contenitori BLOB aggiuntivi usati per i BLOB di lease e/o i messaggi di grandi dimensioni.
Ad esempio, un hub attività denominato xyz con PartitionCount = 4 contiene le code e le tabelle seguenti:

In seguito, vengono descritti questi componenti e il ruolo che svolgono in modo più dettagliato.
Tabella di cronologia
La tabella Cronologia di Archiviazione di Azure contiene gli eventi di cronologia per tutte le istanza di orchestrazione in un hub attività. Il nome della tabella è nel formato NomeHubAttivitàHistory. Durante l'esecuzione di istanze vengono aggiunte nuove righe alla tabella. La chiave di partizione della tabella deriva dall'ID di istanza dell'orchestrazione. Gli ID istanza sono casuali per impostazione predefinita, garantendo una distribuzione ottimale delle partizioni interne in Archiviazione di Azure. La chiave di riga per questa tabella è un numero di sequenza usato per ordinare gli eventi della cronologia.
Quando un'istanza di orchestrazione deve essere eseguita, le righe corrispondenti della tabella Cronologia vengono caricate in memoria usando una query di intervallo all'interno di una singola partizione di tabella. Tali eventi di cronologia vengono riprodotti nel codice di funzione dell'agente di orchestrazione per riportarlo allo stato precedente all'ultimo checkpoint. L'utilizzo della cronologia di esecuzione per ricompilare lo stato in questo modo è influenzato dal modello di origine evento.
Suggerimento
I dati di orchestrazione archiviati nella tabella Cronologia includono payload di output dalle funzioni di attività e sotto orchestrazione. I payload degli eventi esterni vengono archiviati anche nella tabella Cronologia. Poiché la cronologia completa viene caricata in memoria ogni volta che un agente di orchestrazione deve essere eseguito, una cronologia sufficiente può causare una pressione significativa sulla memoria in una determinata macchina virtuale. La lunghezza e le dimensioni della cronologia dell'orchestrazione possono essere ridotte suddividendo le orchestrazioni di grandi dimensioni in più sotto orchestrazioni o riducendo le dimensioni degli output restituiti dall'attività e dalle funzioni di sotto orchestrazione chiamate. In alternativa, è possibile ridurre l'utilizzo della memoria riducendo le limitazioni di concorrenza per vm per limitare il numero di orchestrazioni caricate simultaneamente nella memoria.
Tabella delle istanze
La tabella Istanze contiene gli stati di tutte le istanze di orchestrazione ed entità all'interno di un hub attività. In seguito alla creazione di istanze, nuove righe vengono aggiunte alla tabella. La chiave di partizione di questa tabella è l'ID dell'istanza di orchestrazione o la chiave di entità e la chiave di riga è una stringa vuota. Esiste una riga per orchestrazione o istanza di entità.
Questa tabella viene usata per soddisfare le richieste di query di istanza dal codice e per eseguire query di stato su chiamate API HTTP . Il contenuto della tabella viene mantenuto coerente con quello della tabella Cronologia citata in precedenza. L'uso di una tabella di Archiviazione di Azure separata per soddisfare in modo efficiente le operazioni di query di istanza in questo modo è influenzata dal modello di separazione e responsabilità per query e comandi (CQRS, Command and Query Responsibility Segregation).
Suggerimento
Il partizionamento della tabella Istanze consente di archiviare milioni di istanze di orchestrazione senza alcun impatto evidente sulle prestazioni o sulla scalabilità di runtime. Tuttavia, il numero di istanze può avere un impatto significativo sulle prestazioni delle query su più istanze . Per controllare la quantità di dati archiviati in queste tabelle, è consigliabile eliminare periodicamente i dati dell'istanza precedente.
Tabella partizioni
Nota
Questa tabella viene visualizzata nell'hub attività solo quando Table Partition Manager è abilitata. Per applicarla, configurare useTablePartitionManagement l'impostazione nell'host.json dell'app.
La tabella Partizioni archivia lo stato delle partizioni per l'app Durable Functions e viene usato per distribuire le partizioni nei ruoli di lavoro dell'app. Esiste una riga per partizione.
Code
Le funzioni di orchestrazione, entità e attività sono tutte attivate dalle code interne nell'hub attività dell'app per le funzioni. L'uso delle code in base a questa modalità supporta la garanzia di recapito "At-Least-Once". In Funzioni permanenti esistono due tipi di code: la coda di controllo e la coda di elementi di lavoro.
Coda di elementi di lavoro
Esiste una coda di elementi di lavoro per ogni hub attività in Funzioni permanenti. Si tratta di una coda di base e si comporta in modo analogo a qualsiasi altra queueTrigger coda in Funzioni di Azure. Tale coda consente di attivare funzioni di attività senza stato rimuovendo dalla coda un solo messaggio alla volta. Ognuno di questi messaggi contiene gli input della funzione di attività e metadati aggiuntivi, ad esempio la funzione da eseguire. Quando un'applicazione Durable Functions aumenta il numero di macchine virtuali, queste macchine virtuali sono tutte in grado di acquisire attività dalla coda dell'elemento di lavoro.
Code di controllo
In Funzioni permanenti sono presenti più code di controllo per hub attività. Una coda di controllo è più complessa della coda di elementi di lavoro. Le code di controllo vengono usate per attivare l'agente di orchestrazione con stato e le funzioni di entità. Poiché le istanze dell'agente di orchestrazione e delle funzioni di entità sono singleton con stato, è importante che ogni orchestrazione o entità venga elaborata solo da un ruolo di lavoro alla volta. Per ottenere questo vincolo, ogni istanza di orchestrazione o entità viene assegnata a una singola coda di controllo. Queste code di controllo sono bilanciate tra i ruoli di lavoro per garantire che ogni coda venga elaborata solo da un ruolo di lavoro alla volta. Altre informazioni su questo comportamento sono disponibili nelle sezioni successive.
Le code di controllo contengono messaggi di diverso tipo relativi al ciclo di vita di orchestrazione. Gli esempi includono i messaggi di controllo dell'agente di orchestrazione, i messaggi di risposta delle funzioni di attività e i messaggi del timer. In una singola operazione di polling dalla coda di controllo verranno rimossi al massimo 32 messaggi. Tali messaggi contengono dati di payload, nonché altri metadati, ad esempio l'istanza di orchestrazione a cui sono destinati. Se più messaggi rimossi dalla coda sono destinati alla stessa istanza di orchestrazione, verranno elaborati in batch.
I messaggi della coda di controllo vengono continuamente sottoposto a polling usando un thread in background. Le dimensioni batch di ogni polling della coda sono controllate dall'impostazione controlQueueBatchSize in host.json e hanno un valore predefinito pari a 32 (il valore massimo supportato dalle code di Azure). Il numero massimo di messaggi prefeted control-queue memorizzati nel buffer è controllato dall'impostazione controlQueueBufferThreshold in host.json. Il valore predefinito per controlQueueBufferThreshold varia a seconda di diversi fattori, tra cui il tipo di piano di hosting. Per altre informazioni su queste impostazioni, vedere la documentazione dello schema host.json .
Suggerimento
L'aumento del valore per controlQueueBufferThreshold consente a una singola orchestrazione o entità di elaborare gli eventi più velocemente. Tuttavia, l'aumento di questo valore può anche comportare un utilizzo maggiore della memoria. L'utilizzo di memoria maggiore è in parte dovuto al pull di più messaggi dalla coda e in parte a causa del recupero di cronologie di orchestrazione in memoria. La riduzione del valore per controlQueueBufferThreshold può quindi essere un modo efficace per ridurre l'utilizzo della memoria.
Polling code
L'estensione dell'attività durevole implementa un algoritmo di back-off esponenziale casuale per ridurre l'effetto del polling inattiva della coda sui costi delle transazioni di archiviazione. Quando viene trovato un messaggio, il runtime verifica immediatamente la presenza di un altro messaggio. Quando non viene trovato alcun messaggio, attende un periodo di tempo prima di riprovare. Dopo i tentativi successivi non riusciti di ottenere un messaggio di coda, il tempo di attesa continua ad aumentare fino a raggiungere il tempo di attesa massimo, che viene predefinito a 30 secondi.
Il ritardo massimo di polling è configurabile tramite la maxQueuePollingInterval proprietà nel file host.json. L'impostazione di questa proprietà su un valore superiore potrebbe comportare latenze di elaborazione dei messaggi più elevate. Le latenze più elevate dovrebbero essere previste solo dopo periodi di inattività. L'impostazione di questa proprietà su un valore inferiore potrebbe comportare costi di archiviazione superiori a causa di un aumento delle transazioni di archiviazione.
Nota
Quando si esegue nei piani consumo Funzioni di Azure e Premium, il controller di scalabilità Funzioni di Azure esegue il polling di ogni controllo e coda di elementi di lavoro una volta ogni 10 secondi. Questo polling aggiuntivo è necessario per determinare quando attivare le istanze dell'app per le funzioni e prendere decisioni di scalabilità. Al momento della scrittura, questo intervallo di 10 secondi è costante e non può essere configurato.
Ritardi di avvio dell'orchestrazione
Le istanze di orchestrazione vengono avviate inserendo un ExecutionStarted messaggio in una delle code di controllo dell'hub attività. In determinate condizioni, è possibile osservare ritardi multi-secondo tra quando viene pianificata l'esecuzione di un'orchestrazione e quando viene effettivamente avviata l'esecuzione. Durante questo intervallo di tempo, l'istanza di orchestrazione rimane nello Pending stato. Esistono due possibili cause di questo ritardo:
Code di controllo registrate: se la coda di controllo per questa istanza contiene un numero elevato di messaggi, potrebbe richiedere tempo prima che il
ExecutionStartedmessaggio venga ricevuto ed elaborato dal runtime. I backlog dei messaggi possono verificarsi quando le orchestrazioni elaborano un sacco di eventi simultaneamente. Gli eventi che entrano nella coda di controllo includono eventi di avvio dell'orchestrazione, completamento attività, timer durevoli, terminazione ed eventi esterni. Se questo ritardo si verifica in circostanze normali, è consigliabile creare un nuovo hub attività con un numero maggiore di partizioni. La configurazione di più partizioni causerà la creazione di più code di controllo per la distribuzione del carico. Ogni partizione corrisponde a 1:1 con una coda di controllo, con un massimo di 16 partizioni.Ritardo del polling: un'altra causa comune dei ritardi di orchestrazione è il comportamento di back-off del polling descritto in precedenza per le code di controllo. Tuttavia, questo ritardo è previsto solo quando un'app viene ridimensionata in due o più istanze. Se esiste solo un'istanza dell'app o se l'istanza dell'app che avvia l'orchestrazione è anche la stessa istanza che esegue il polling della coda di controllo di destinazione, non vi sarà alcun ritardo di polling della coda. È possibile ridurre i ritardi di polling aggiornando le impostazioni host.json , come descritto in precedenza.
BLOB
Nella maggior parte dei casi, Durable Functions non usa BLOB di archiviazione di Azure per rendere persistenti i dati. Tuttavia, le code e le tabelle hanno limiti di dimensioni che possono impedire Durable Functions di rendere persistenti tutti i dati necessari in una riga di archiviazione o in un messaggio di coda. Ad esempio, quando una parte di dati che deve essere mantenuta in una coda è maggiore di 45 KB quando viene serializzata, Durable Functions comprimerà i dati e lo archivierà in un BLOB. Quando si mantienono i dati nell'archiviazione BLOB in questo modo, La funzione durevole archivia un riferimento a tale BLOB nella riga della tabella o nel messaggio della coda. Quando Durable Functions deve recuperare i dati che recupera automaticamente dal BLOB. Questi BLOB vengono archiviati nel contenitore <taskhub>-largemessagesBLOB .
Considerazioni sulle prestazioni
I passaggi di compressione e operazioni BLOB aggiuntivi per i messaggi di grandi dimensioni possono essere costosi in termini di costi di latenza cpu e I/O. Inoltre, Durable Functions deve caricare dati persistenti in memoria e può farlo per molte esecuzioni di funzioni diverse contemporaneamente. Di conseguenza, anche il payload di dati di grandi dimensioni può causare un utilizzo elevato della memoria. Per ridurre al minimo il sovraccarico della memoria, è consigliabile rendere persistenti i payload di dati di grandi dimensioni manualmente (ad esempio, nell'archiviazione BLOB) e passare invece riferimenti a questi dati. In questo modo il codice può caricare i dati solo quando necessario per evitare carichi ridondanti durante la riproduzione delle funzioni dell'agente di orchestrazione. Tuttavia, l'archiviazione dei payload nei dischi locali non è consigliata poiché lo stato del disco non è garantito perché le funzioni possono essere eseguite in macchine virtuali diverse durante la loro durata.
Selezione dell'account di archiviazione
Le code, le tabelle e i BLOB usati da Durable Functions vengono creati in un account di archiviazione di Azure configurato. L'account da usare può essere specificato usando l'impostazione (o durableTask/azureStorageConnectionStringName l'impostazione durableTask/storageProvider/connectionStringName in Durable Functions 1.x) nel file host.json.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
Se non specificato, come valore predefinito viene usato l'account di archiviazione AzureWebJobsStorage. Per carichi di lavoro sensibili alle prestazioni, è tuttavia consigliabile configurare un account di archiviazione non predefinito. Funzioni permanenti usa di frequente Archiviazione di Azure e l'uso di un account di archiviazione dedicato separa l'uso dell'archiviazione di Funzioni permanenti dall'uso interno da parte dell'host di Funzioni di Azure.
Nota
Gli account di archiviazione generici standard di Azure sono necessari quando si usa il provider di archiviazione di Azure. Tutti gli altri tipi di account di archiviazione non sono supportati. È consigliabile usare account di archiviazione per utilizzo generico v1 legacy per Durable Functions. Gli account di archiviazione v2 più recenti possono essere notevolmente più costosi per i carichi di lavoro Durable Functions. Per altre informazioni sui tipi di account di archiviazione di Azure, vedere la documentazione di panoramica dell'account di archiviazione .
Scalabilità orizzontale dell'agente di orchestrazione
Anche se le funzioni di attività possono essere ridimensionate in modo infinito aggiungendo più macchine virtuali in modo elastico, le singole istanze e le entità dell'agente di orchestrazione sono vincolate a vivere una singola partizione e il numero massimo di partizioni viene associato dall'impostazione nell'oggetto partitionCounthost.json.
Nota
In generale, le funzioni dell'agente di orchestrazione devono essere semplici, senza richiedere potenza di calcolo in grande quantità. Non è quindi necessario creare un numero elevato di partizioni della coda di controllo per ottenere una velocità effettiva elevata per le orchestrazioni. La maggior parte del lavoro più intenso deve essere eseguita nelle funzioni di attività senza stato, che possono essere scalate orizzontalmente all'infinito.
Il numero di code di controllo viene definito nel file host.json. Nell'esempio seguente il frammento di codice host.json imposta la durableTask/storageProvider/partitionCount proprietà (o durableTask/partitionCount in Durable Functions 1.x) su 3. Si noti che sono presenti quante code di controllo sono presenti partizioni.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Un hub attività può essere configurato con un numero di partizioni compreso tra 1 e 16. Se non specificato, il numero di partizioni predefinito è 4.
Durante gli scenari di traffico ridotto, l'applicazione verrà ridimensionata in modo che le partizioni vengano gestite da un numero ridotto di lavoratori. Si consideri, ad esempio, il diagramma seguente.
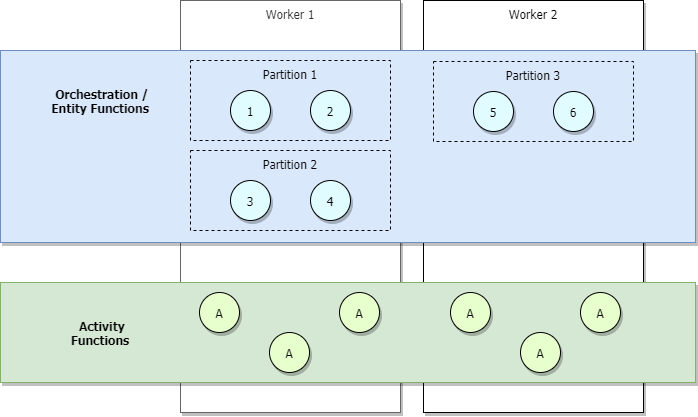
Nel diagramma precedente si noterà che gli agenti di orchestrazione da 1 a 6 vengono caricati bilanciati tra partizioni. Analogamente, le partizioni, come le attività, sono bilanciate tra i ruoli di lavoro. Le partizioni sono bilanciate tra i ruoli di lavoro indipendentemente dal numero di orchestratori che iniziano.
Se si esegue nei piani Funzioni di Azure Consumo o Elastic Premium oppure se si dispone di scalabilità automatica basata sul carico configurato, altri lavoratori verranno allocati come aumento del traffico e le partizioni verranno infine riequilibcati in tutti i ruoli di lavoro. Se si continua a ridimensionare, alla fine ogni partizione verrà gestita da un singolo ruolo di lavoro. Le attività, d'altra parte, continueranno a essere bilanciate tra tutti i lavoratori. Questa operazione è illustrata nell'immagine seguente.
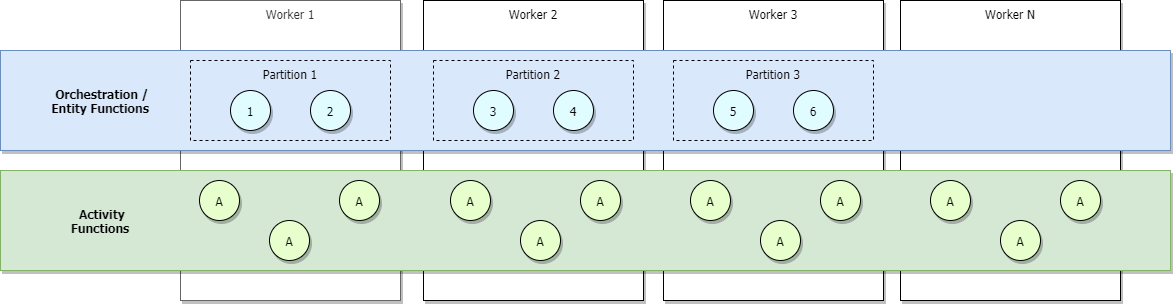
Il limite superiore del numero massimo di orchestrazioni attive simultanee in qualsiasi momento è uguale al numero di lavoratori allocati all'applicazione al momento del valore per maxConcurrentOrchestratorFunctions. Questo limite superiore può essere reso più preciso quando le partizioni sono completamente ridimensionate tra i ruoli di lavoro. Quando si esegue il ridimensionamento completo e poiché ogni ruolo di lavoro avrà solo un'istanza host di Funzioni, il numero massimo di istanze dell'agente di orchestrazione simultanee attive sarà uguale al numero di partizioni in cui il valore per maxConcurrentOrchestratorFunctions.
Nota
In questo contesto , attivo significa che un'orchestrazione o un'entità viene caricata in memoria ed elaborazione di nuovi eventi. Se l'orchestrazione o l'entità è in attesa di più eventi, ad esempio il valore restituito di una funzione di attività, viene scaricato dalla memoria e non viene più considerato attivo. Le orchestrazioni e le entità verranno successivamente ricaricate in memoria solo quando sono presenti nuovi eventi da elaborare. Non esiste un numero massimo pratico di orchestrazioni totali o entità che possono essere eseguite in una singola macchina virtuale, anche se sono tutti nello stato "Esecuzione". L'unica limitazione è il numero di istanze di orchestrazione o entità attive simultaneamente .
L'immagine seguente illustra uno scenario completamente ridimensionato in cui vengono aggiunti più orchestratori, ma alcuni sono inattivi, visualizzati in grigio.
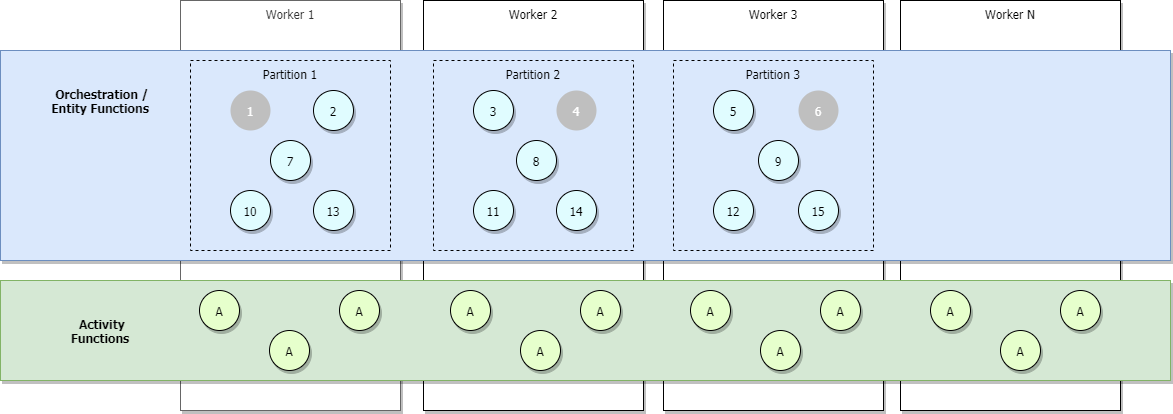
Durante la scalabilità orizzontale, i lease delle code di controllo possono essere ridistribuiti tra le istanze host di Funzioni per garantire che le partizioni vengano distribuite in modo uniforme. Questi lease vengono implementati internamente come lease di archiviazione BLOB di Azure e garantiscono che qualsiasi singola istanza di orchestrazione o entità venga eseguita solo in una singola istanza host alla volta. Se un hub attività è configurato con tre partizioni (e quindi tre code di controllo), le istanze di orchestrazione e le entità possono essere bilanciate dal carico in tutte e tre le istanze host di gestione del lease. È possibile aggiungere altre macchine virtuali per aumentare la capacità per l'esecuzione della funzione di attività.
Il diagramma seguente illustra l'interazione tra l'host di Funzioni di Azure e le entità di archiviazione in un ambiente con scalabilità orizzontale.
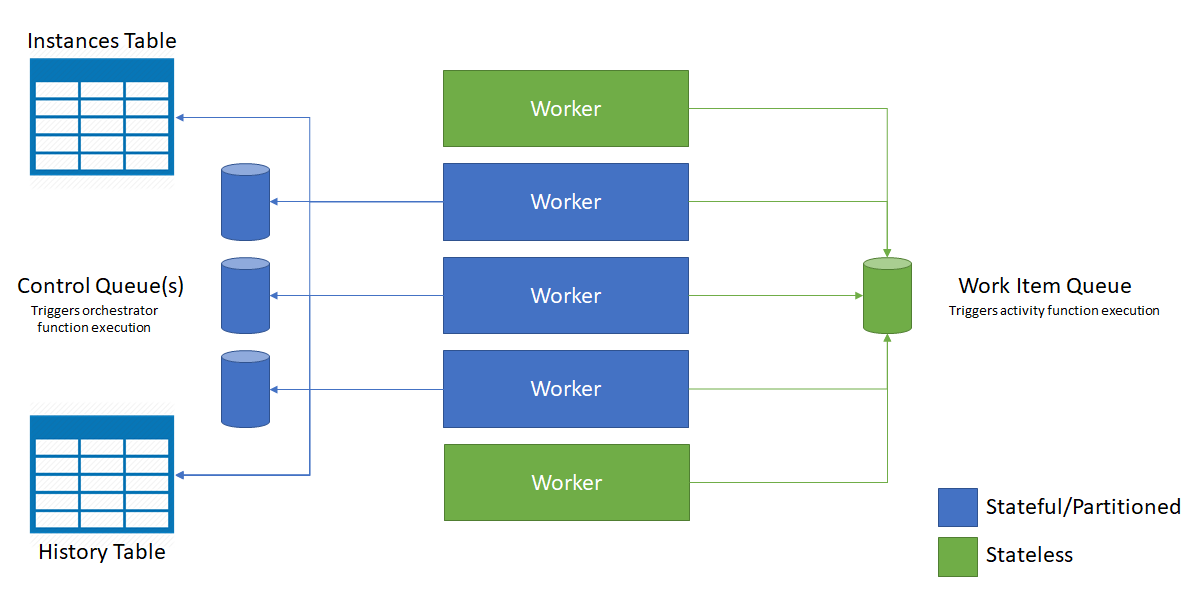
Come illustrato nel diagramma precedente, tutte le macchine virtuali sono in conflitto per i messaggi presenti nella coda degli elementi di lavoro. Tuttavia, solo tre macchine virtuali possono acquisire i messaggi dalle code di controllo e ogni macchina virtuale blocca una singola coda di controllo.
Le istanze e le entità di orchestrazione vengono distribuite in tutte le istanze della coda di controllo. La distribuzione viene eseguita tramite l'hashing dell'ID istanza dell'orchestrazione o del nome dell'entità e della coppia di chiavi. Gli ID dell'istanza di orchestrazione per impostazione predefinita sono GUID casuali, assicurandosi che le istanze siano distribuite equamente in tutte le code di controllo.
In generale, le funzioni dell'agente di orchestrazione devono essere semplici, senza richiedere potenza di calcolo in grande quantità. Non è quindi necessario creare un numero elevato di partizioni della coda di controllo per ottenere una velocità effettiva elevata per le orchestrazioni. La maggior parte del lavoro più intenso deve essere eseguita nelle funzioni di attività senza stato, che possono essere scalate orizzontalmente all'infinito.
Sessioni estese
Le sessioni estese sono un meccanismo di memorizzazione nella cache che mantiene orchestrazioni ed entità in memoria anche dopo aver completato l'elaborazione dei messaggi. L'effetto tipico dell'abilitazione delle sessioni estese è ridotto di I/O rispetto all'archivio durevole sottostante e alla velocità effettiva complessivamente migliorata.
È possibile abilitare le sessioni estese impostando durableTask/extendedSessionsEnabled su true nel file host.json . L'impostazione durableTask/extendedSessionIdleTimeoutInSeconds può essere usata per controllare per quanto tempo verrà mantenuta in memoria una sessione inattiva:
Funzioni 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Funzioni 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Esistono due potenziali svantaggi di questa impostazione per essere consapevoli di:
- Si verifica un aumento complessivo dell'utilizzo della memoria dell'app per le funzioni perché le istanze inattive non vengono scaricate dalla memoria più rapidamente.
- Può verificarsi una diminuzione complessiva della velocità effettiva se sono presenti molte esecuzioni simultanee, distinte e di breve durata dell'agente di orchestrazione o di funzioni di entità.
Ad esempio, se durableTask/extendedSessionIdleTimeoutInSeconds è impostato su 30 secondi, un episodio di orchestrazione o funzione di entità di breve durata che viene eseguito in meno di 1 secondo occupa ancora memoria per 30 secondi. Viene inoltre conteggiato rispetto alla durableTask/maxConcurrentOrchestratorFunctions quota menzionata in precedenza, impedendo potenzialmente l'esecuzione di altre funzioni di orchestrazione o entità.
Gli effetti specifici delle sessioni estese sulle funzioni di orchestrazione ed entità sono descritti nelle sezioni successive.
Nota
Le sessioni estese sono attualmente supportate solo nei linguaggi .NET, ad esempio C# o F#. L'impostazione di extendedSessionsEnabled su true per altre piattaforme può causare problemi di runtime, ad esempio l'errore invisibile all'utente di eseguire attività e funzioni attivate dall'orchestrazione.
Riproduzione delle funzioni dell'agente di orchestrazione
Come accennato in precedenza, le funzioni dell'agente di orchestrazione vengono riprodotte tramite il contenuto della tabella Cronologia. Per impostazione predefinita, il codice della funzione dell'agente di orchestrazione viene riprodotto ogni volta che un batch di messaggi viene rimosso da un coda di controllo. Anche se si usa il modello fan-out, fan-in e sono in attesa del completamento di tutte le attività (ad esempio, usando Task.WhenAll() in .NET, context.df.Task.all() in JavaScript o context.task_all() in Python), ci saranno riproduzioni che si verificano come batch di risposte alle attività vengono elaborate nel tempo. Quando le sessioni estese sono abilitate, le istanze della funzione dell'agente di orchestrazione vengono mantenute in memoria più a lungo e i nuovi messaggi possono essere elaborati senza una riproduzione completa della cronologia.
Il miglioramento delle prestazioni delle sessioni estese viene spesso osservato nelle situazioni seguenti:
- Quando è presente un numero limitato di istanze di orchestrazione in esecuzione simultaneamente.
- Quando le orchestrazioni hanno un numero elevato di azioni sequenziali ,ad esempio centinaia di chiamate di funzione di attività, che vengono completate rapidamente.
- Quando orchestrazioni fan-out e fan-in un numero elevato di azioni che si completano contemporaneamente.
- Quando le funzioni dell'agente di orchestrazione devono elaborare messaggi di grandi dimensioni o eseguire qualsiasi elaborazione dati con utilizzo intensivo della CPU.
In tutte le altre situazioni, in genere non esiste alcun miglioramento osservabile delle prestazioni per le funzioni dell'agente di orchestrazione.
Nota
Tali impostazioni devono essere usate solo dopo che una funzione dell'agente di orchestrazione è stata completamente sviluppata e testata. Il comportamento di riproduzione aggressivo predefinito può essere utile per rilevare violazioni dei vincoli del codice della funzione dell'agente di orchestrazione in fase di sviluppo e pertanto è disabilitato per impostazione predefinita.
Prestazioni richieste
La tabella seguente illustra i numeri di velocità effettiva massima previsti per gli scenari descritti nella sezione Obiettivi di prestazioni dell'articolo Prestazioni e scalabilità .
"Istanza" si riferisce a una singola istanza di una funzione dell'agente di orchestrazione in esecuzione in un'unica macchina virtuale di piccole dimensioni (A1) in Servizio app di Azure. In tutti i casi si presuppone che le sessioni estese siano abilitate. I risultati effettivi possono variare a seconda delle operazioni della CPU o di I/O eseguite dal codice della funzione.
| Scenario | Velocità effettiva massima |
|---|---|
| Esecuzione di attività sequenziali | 5 attività al secondo, per istanza |
| Esecuzione di attività parallele (fan-out) | 100 attività al secondo, per istanza |
| Elaborazione di risposte parallele (fan-in) | 150 risposte al secondo, per istanza |
| Elaborazione di eventi esterni | 50 eventi al secondo, per istanza |
| Elaborazione dell'operazione di entità | 64 operazioni al secondo |
Se non si realizzano in valori di velocità effettiva previsti e l'uso della CPU e della memoria sembra tuttavia corretto, verificare se la causa è correlata allo stato dell'account di archiviazione. L'estensione Funzioni permanenti può aggiungere carico significativo a un account di Archiviazione di Azure e carichi sufficientemente elevati possono comportare la limitazione delle richieste dell'account di archiviazione.
Suggerimento
In alcuni casi è possibile aumentare significativamente la velocità effettiva di eventi esterni, fan-in attività ed entità aumentando il valore dell'impostazione controlQueueBufferThreshold in host.json. Aumentando questo valore oltre il valore predefinito, il provider di archiviazione Durable Task Framework usa più memoria per prelettura di questi eventi in modo più aggressivo, riducendo i ritardi associati alla rimozione della coda dei messaggi dalle code di controllo di Archiviazione di Azure. Per altre informazioni, vedere la documentazione di riferimento su host.json .
Elaborazione con velocità effettiva elevata
L'architettura del back-end di Archiviazione di Azure pone alcune limitazioni sulle massime prestazioni e scalabilità teorica di Durable Functions. Se il test mostra che Durable Functions in Archiviazione di Azure non soddisfa i requisiti di velocità effettiva, è consigliabile usare invece il provider di archiviazione Netherite per Durable Functions.
Per confrontare la velocità effettiva ottenibile per vari scenari di base, vedere la sezione Scenari di base della documentazione del provider di archiviazione Netherite.
Il back-end di archiviazione Netherite è stato progettato e sviluppato da Microsoft Research. Usa Hub eventi di Azure e la tecnologia di database FASTER oltre ai BLOB di pagine di Azure. La progettazione di Netherite consente un'elaborazione significativamente più elevata della velocità effettiva delle orchestrazioni e delle entità rispetto ad altri provider. In alcuni scenari di benchmark, la velocità effettiva è stata mostrata per aumentare di più di un ordine di grandezza rispetto al provider di archiviazione di Azure predefinito.
Per altre informazioni sui provider di archiviazione supportati per Durable Functions e sul relativo confronto, vedere la documentazione dei provider di archiviazione Durable Functions.