Progettazione di servizi disponibili a livello globale con il database SQL di Azure
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Nella creazione e distribuzione di servizi cloud con il database SQL di Azure, la replica geografica attiva o i gruppi di failover forniscono resilienza in caso di interruzioni a livello di area ed errori irreversibili. La stessa funzionalità consente di creare applicazioni distribuite a livello globale ottimizzate per l'accesso locale ai dati. Questo articolo illustra modelli di applicazione comuni, nonché i vantaggi e gli svantaggi di ogni opzione.
Nota
Se si usano pool elastici e database premium o business critical, è possibile renderli resistenti alle interruzioni a livello di area convertendoli in una configurazione di distribuzione con ridondanza della zona. Vedere Database con ridondanza della zona.
Scenario 1: Uso di due aree di Azure per la continuità aziendale con tempo di inattività minimo
In questo scenario le applicazioni presentano le caratteristiche seguenti:
- L'applicazione è attiva in un'area di Azure
- Tutte le sessioni del database richiedono l'accesso in lettura e scrittura ai dati
- Il livello Web e il livello dati devono essere collocati in modo da ridurre la latenza e il costo del traffico
- Essenzialmente, il tempo di inattività rappresenta per queste applicazioni un rischio aziendale più elevato rispetto alla perdita di dati
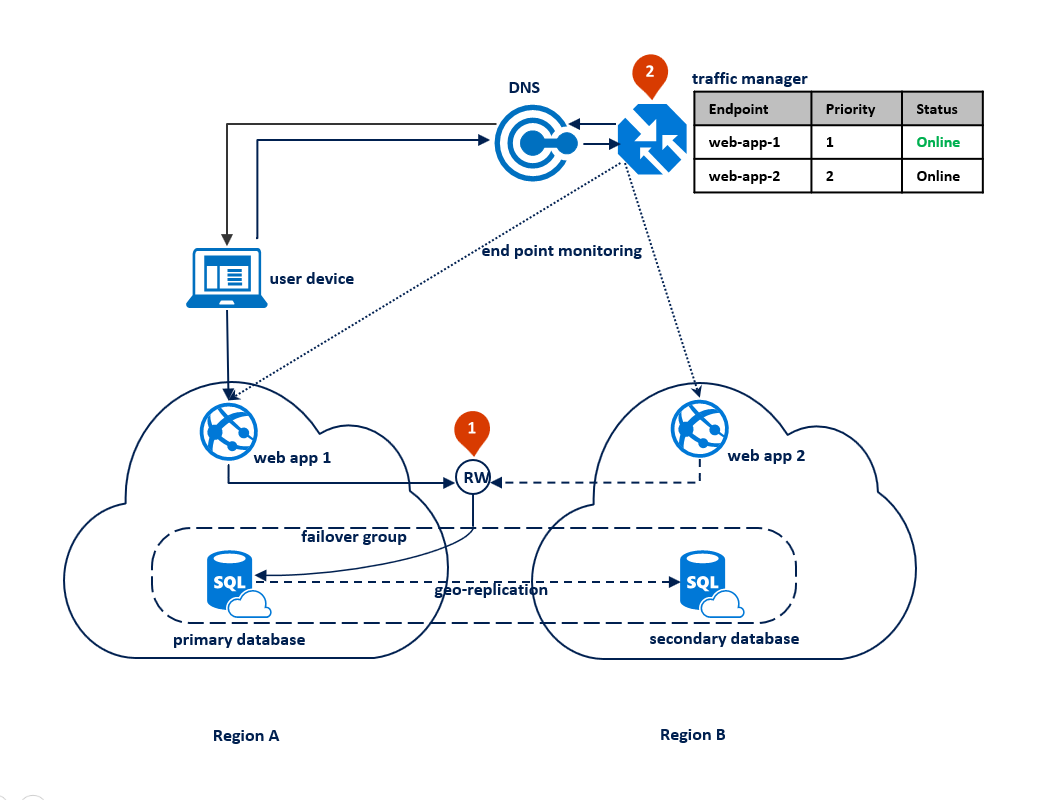
In questo caso, la topologia di distribuzione dell'applicazione è ottimizzata per la gestione delle emergenze a livello di area quando tutti i componenti devono essere sottoposti a failover contemporaneamente. Il diagramma seguente illustra questa topologia. Per garantire la ridondanza geografica, le risorse dell'applicazione vengono distribuite nelle aree A e B. Tuttavia, le risorse nell'area B non vengono utilizzate finché non si verifica un errore nell'area A. Tra le due aree viene configurato un gruppo di failover per gestire la connettività del database, la replica e il failover. Il servizio Web in entrambe le aree è configurato per accedere al database tramite il listener di lettura/scrittura <nome-gruppo-failover>.database.windows.net (1). La Gestione traffico di Azure è configurata per usare il metodo di routing per priorità (2).
Nota
La Gestione traffico di Azure viene usata in questo articolo solo a scopi illustrativi. È possibile usare qualsiasi soluzione di bilanciamento del carico che supporti il metodo di routing per priorità.
Il diagramma seguente illustra questa configurazione prima di un'interruzione:
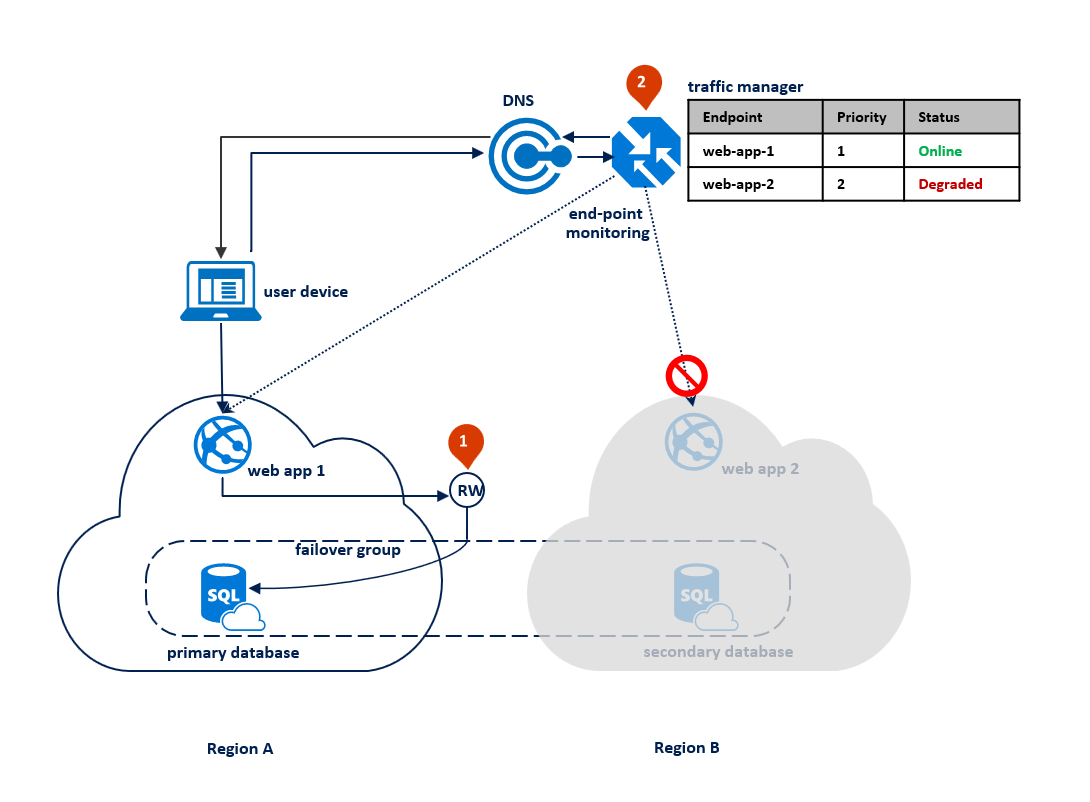
Dopo un'interruzione nell'area primaria, il database SQL rileva che il database primario non è accessibile e attiva il failover nell'area secondaria in base ai parametri dei criteri di failover automatico (1). A seconda del contratto di servizio dell'applicazione, è possibile configurare un periodo di tolleranza che controlla l'intervallo di tempo tra il rilevamento dell'interruzione e il failover stesso. La Gestione traffico di Azure potrebbe avviare il failover degli endpoint prima che il gruppo di failover attivi il failover del database. In tal caso, l'applicazione Web non può riconnettersi immediatamente al database. Le riconnessioni, tuttavia, avranno automaticamente esito positivo non appena verrà completato il failover del database. Quando l'area in cui si è verificato l'errore è ripristinata e di nuovo online, il database primario precedente si riconnette automaticamente come nuovo database secondario. Il diagramma seguente illustra la configurazione dopo il failover.
Nota
Tutte le transazioni di cui è stato eseguito il commit dopo il failover andranno perse durante la riconnessione. Dopo il completamento del failover, l'applicazione nell'area B può riconnettersi e riavviare l'elaborazione delle richieste utente. Sia l'applicazione Web che il database primario si trovano nell'area B e continuano a condividere lo stesso percorso.
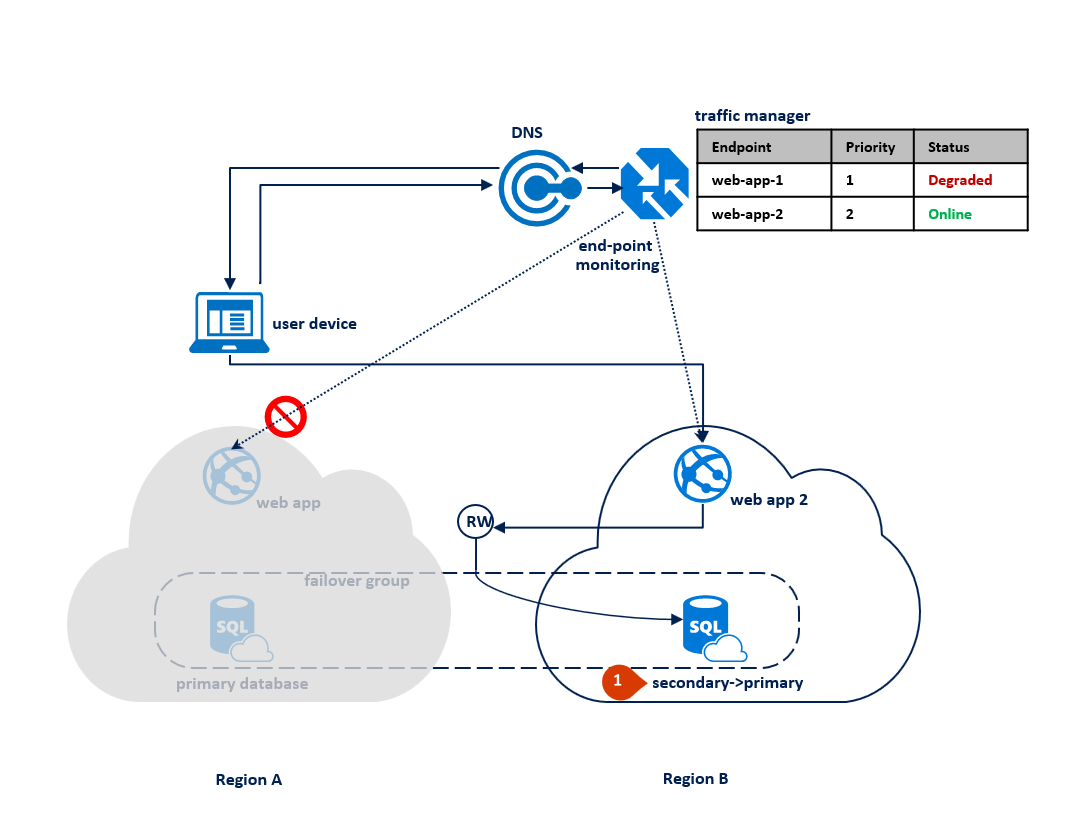
In caso di interruzione nell'area B, il processo di replica tra il database primario e quello secondario viene sospeso ma il collegamento tra i due resta intatto (1). La Gestione traffico rileva l'interruzione della connettività all'area B e contrassegna l'endpoint web-app-2 come danneggiato (2). Le prestazioni dell'applicazione non subiscono alcun impatto in questo caso, ma il database risulta esposto e quindi maggiormente a rischio di perdita di dati in caso di errore in successione nell'area A.
Nota
Per il ripristino di emergenza è consigliabile la configurazione con distribuzione dell'applicazione limitata a due aree. Infatti la maggior parte delle geografie di Azure ha solo due aree. Questa configurazione non protegge l'applicazione da un errore irreversibile simultaneo in entrambe le aree. Nell'improbabile eventualità di un errore di questo genere, è possibile recuperare i database in una terza area con un'operazione di ripristino geografico. Per ulteriori informazioni, vedere Materiale sussidiario per il ripristino di emergenza del database SQL di Azure.
Dopo che l'interruzione è stata risolta, il database secondario viene automaticamente risincronizzato con quello primario. Durante la sincronizzazione, le prestazioni del database primario possono risultare peggiorate. L'impatto specifico dipende dalla quantità di dati acquisita dal nuovo database primario dal momento del failover.
Nota
Dopo aver risolto l'interruzione, la Gestione traffico inizierà a instradare le connessioni all'applicazione nell'area A come endpoint con priorità più alta. Se si intende mantenere la replica primaria nell'area B per un po', è necessario modificare di conseguenza la tabella delle priorità nel profilo della Gestione traffico.
Il diagramma seguente illustra un'interruzione nell'area secondaria:
I vantaggi chiave di questo modello di progettazione sono:
- La stessa applicazione Web viene implementata in entrambe le aree senza alcuna configurazione specifica dell'area e non richiede logica aggiuntiva per la gestione del failover.
- Il failover non influisce sulle prestazioni dell'applicazione perché l'applicazione Web e il database condividono sempre lo stesso percorso.
Il principale svantaggio è rappresentato dal fatto che le risorse dell'applicazione nell'area B sono sottoutilizzate nella maggior parte dei casi.
Scenario 2: Aree di Azure per la continuità aziendale con mantenimento massimo dei dati
Questa opzione è particolarmente indicata per le applicazioni con le caratteristiche seguenti:
- Qualsiasi perdita di dati rappresenta un rischio aziendale elevato. Il failover del database può essere usato solo come ultima soluzione se l'interruzione è causata da un errore irreversibile.
- L'applicazione supporta le modalità di sola lettura e lettura/scrittura delle operazioni e può funzionare in "modalità di sola lettura" per un periodo di tempo.
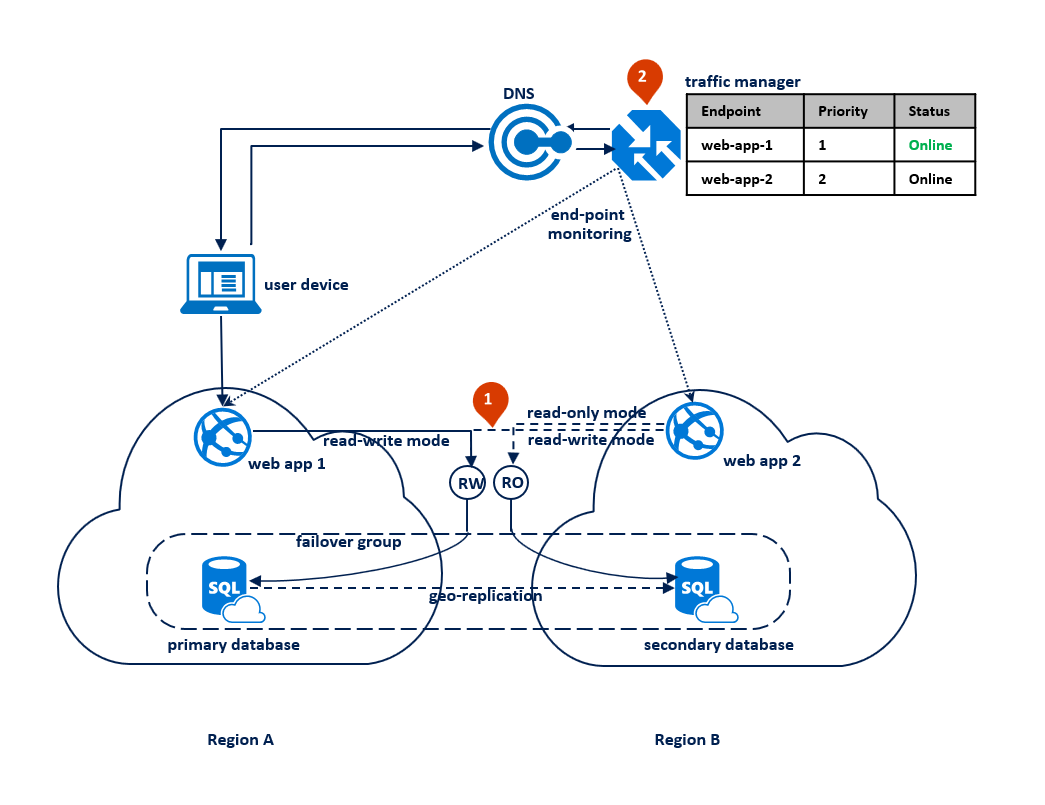
In questo modello l'applicazione passa alla modalità di sola lettura quando le connessioni di lettura-scrittura iniziano a dare errori di timeout. L'applicazione Web viene implementata in entrambe le aree e include una connessione all'endpoint listener di lettura/scrittura e una diversa connessione all'endpoint listener di sola lettura (1). Il profilo della Gestione traffico dovrebbe usare il routing per priorità. Il monitoraggio degli endpoint dovrà essere abilitato per l'endpoint applicazione in ogni area (2).
Il diagramma seguente illustra questa configurazione prima di un'interruzione:
Quando la Gestione traffico rileva un errore di connettività all'area A, trasferisce automaticamente il traffico utente all'istanza dell'applicazione nell'area B. Con questo criterio, è importante impostare il periodo di tolleranza con perdita di dati su un valore sufficientemente elevato, ad esempio 24 ore. In questo modo si impedisce la perdita di dati se l'interruzione del servizio viene risolta entro tale intervallo di tempo. Quando l'applicazione Web nell'area B viene attivata, le operazioni di lettura/scrittura iniziano ad avere esito negativo. A questo punto, passerà alla modalità di sola lettura (1). In questa modalità, le richieste vengono instradate automaticamente al database secondario. Se l'interruzione è causata da un errore irreversibile, molto probabilmente non potrà essere risolta entro il periodo di tolleranza. Alla scadenza, il gruppo di failover attiva il failover. Il listener di lettura/scrittura diventa quindi disponibile e le connessioni non hanno più esito negativo (2). Il diagramma seguente illustra le due fasi del processo di ripristino.
Nota
Se l'interruzione nell'area primaria viene risolta entro il periodo di tolleranza, la Gestione traffico rileva il ripristino della connettività nell'area primaria e trasferisce di nuovo il traffico utente all'istanza dell'applicazione nell'area A. Tale istanza riprende l'esecuzione e funziona in modalità lettura/scrittura usando il database primario nell'area A come illustrato nel diagramma precedente.
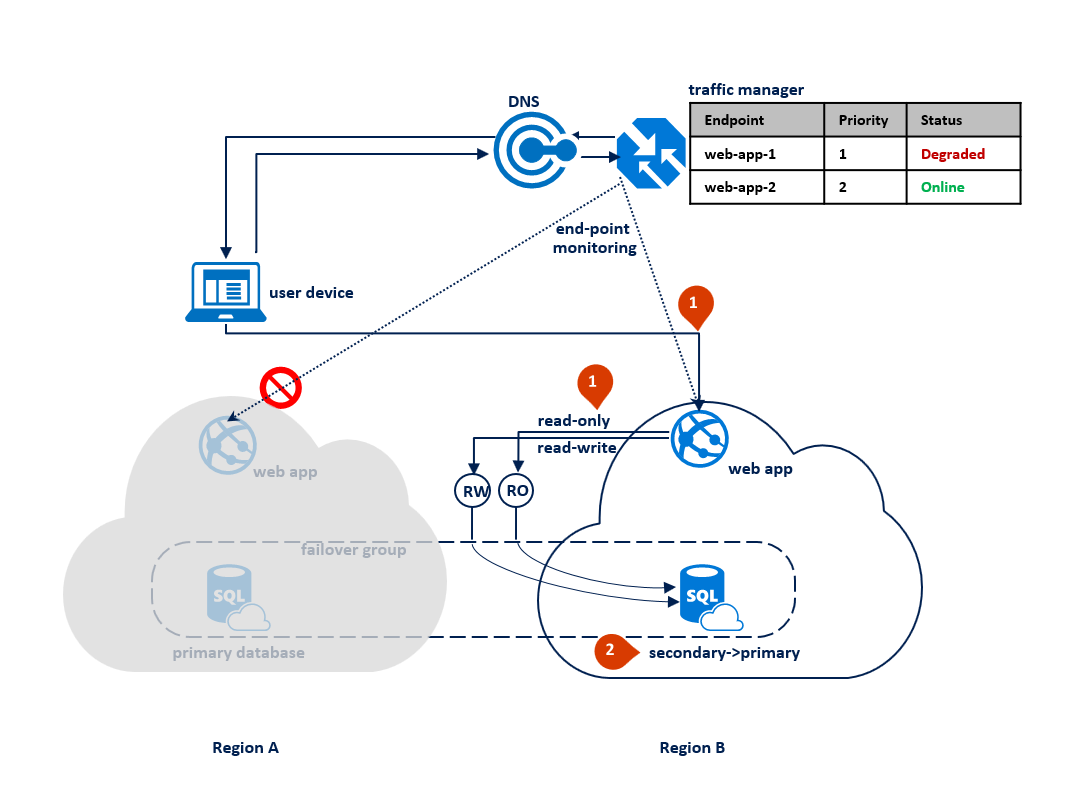
In caso di interruzione nell'area B, la Gestione traffico rileva l'errore dell'endpoint web-app-2 nell'area B e lo contrassegna come danneggiato (1). Nel frattempo, il gruppo di failover trasferisce il listener di sola lettura all'area A (2). L'interruzione non influisce sull'esperienza degli utenti finali, ma il database primario viene esposto durante l'interruzione. Il diagramma seguente illustra un errore nell'area secondaria:
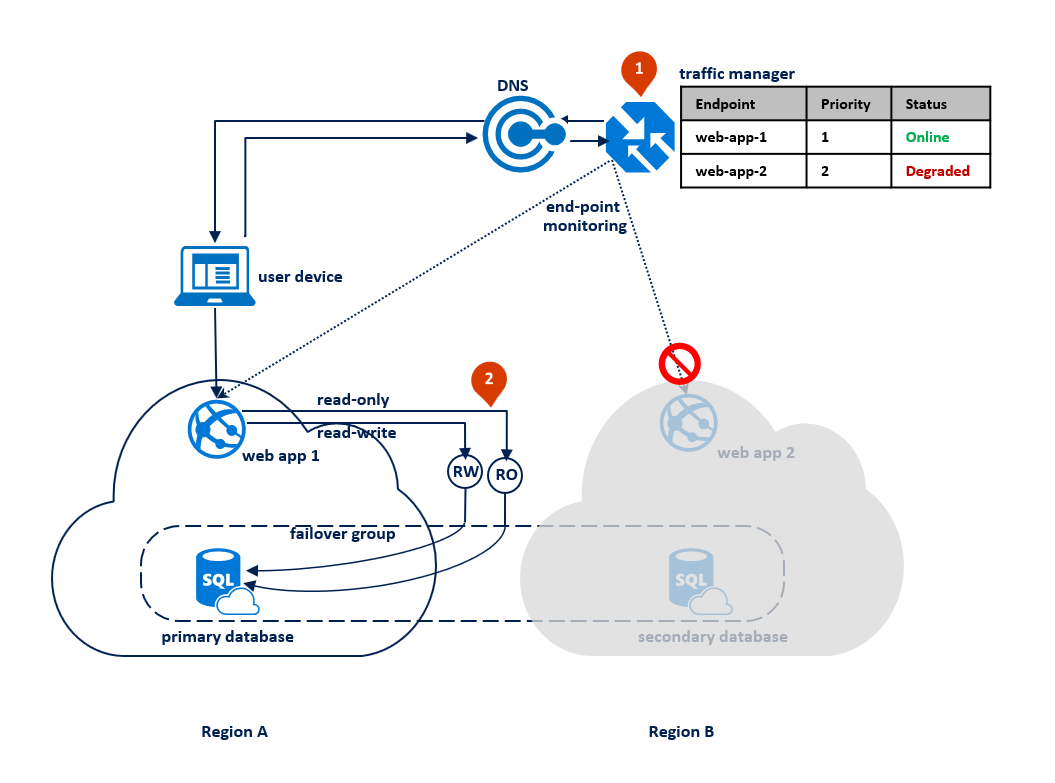
Dopo che l'interruzione del servizio è stata risolta, il database secondario viene immediatamente sincronizzato con quello primario e il listener di sola lettura viene passato nuovamente al database secondario nell'area B. Durante la sincronizzazione, le prestazioni del database primario potrebbero essere leggermente influenzate a seconda della quantità di dati che deve essere sincronizzata.
Questo modello di progettazione presenta diversi vantaggi:
- Impedisce la perdita dei dati durante le interruzioni temporanee.
- Il tempo di inattività dipende solo dalla velocità con cui la Gestione traffico rileva l'errore di connettività, che è configurabile.
Lo svantaggio è rappresentato dal fatto che l'applicazione deve poter funzionare in modalità di sola lettura.
Pianificazione della continuità aziendale: Scegliere una progettazione di applicazioni per il ripristino di emergenza cloud
La strategia di ripristino di emergenza cloud specifica può combinare o estendere questi modelli di progettazione per soddisfare al meglio le esigenze dell'applicazione. Come accennato in precedenza, la strategia scelta si basa sul contratto di servizio che si vuole offrire ai clienti e sulla topologia di distribuzione dell'applicazione. Per facilitare la decisione, la tabella seguente confronta le opzioni in base all'obiettivo del punto di ripristino (RPO) e al tempo di recupero stimato (ERT).
| Modello | RPO | ERT |
|---|---|---|
| Distribuzione attiva/passiva per il ripristino di emergenza con accesso al database con percorso condiviso | Accesso in lettura/scrittura < 5 sec | Ora di rilevamento dell'errore + DNS TTL |
| Distribuzione attiva/attiva per il bilanciamento del carico dell'applicazione | Accesso in lettura/scrittura < 5 sec | Ora di rilevamento dell'errore + DNS TTL |
| Distribuzione attiva/passiva per la conservazione dei dati | Accesso in sola lettura < 5 sec | Accesso in sola lettura = 0 |
| Accesso in lettura/scrittura = zero | Accesso in lettura-scrittura = ora di rilevamento dell'errore + periodo di tolleranza con perdita di dati |
Passaggi successivi
- Per le informazioni generali e gli scenari della continuità aziendale, vedere Continuità aziendale del database SQL di Azure
- Per informazioni sulla replica geografica attiva, vedere Replica geografica attiva.
- Per informazioni sui gruppi di failover, vedere Gruppi di failover.
- Per informazioni sulla replica geografica attiva con i pool elastici, vedere Strategie di ripristino di emergenza per i pool elastici.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per