Strategie di ripristino di emergenza per le applicazioni con i pool elastici del database SQL di Azure
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
Il database SQL offre diverse funzionalità utili per la continuità aziendale dell'applicazione in caso di eventi irreversibili imprevisti. Pool elastici e i database singoli supportano lo stesso tipo di funzionalità per il ripristino di emergenza. Questo articolo illustra alcune strategie di ripristino di emergenza per i pool elastici che sfruttano i vantaggi di queste funzionalità per la continuità aziendale del database SQL di Azure.
In questo articolo viene usato il modello classico di applicazione ISV SaaS:
Un'applicazione Web moderna basata sul cloud effettua il provisioning di un database per ogni utente finale. L'ISV ha un numero elevato di clienti e usa quindi molti database, definiti database tenant. Poiché i database tenant presentano in genere modelli di attività imprevedibili, l'ISV usa un pool elastico per rendere molto prevedibili i costi del database in periodi estesi di tempo. Il pool elastico semplifica anche la gestione delle prestazioni in caso di picchi dell'attività degli utenti. Oltre ai database tenant, l'applicazione usa anche alcuni database per gestire i profili utente e la sicurezza e per raccogliere i modelli di utilizzo e altro ancora. La disponibilità dei singoli database tenant non influisce sulla disponibilità generale dell'applicazione. La disponibilità e le prestazioni dei database di gestione, tuttavia, sono essenziali per il funzionamento dell'applicazione e se i database di gestione sono offline, l'intera applicazione è offline.
Questo articolo illustra le strategie di ripristino di emergenza in diversi scenari, dalle applicazioni per start-up attente ai costi a quelle con requisiti di disponibilità rigorosi.
Nota
Se si usano pool elastici e database premium o business critical, è possibile renderli resistenti alle interruzioni a livello di area convertendoli in una configurazione di distribuzione con ridondanza della zona. Vedere Database con ridondanza della zona.
Scenario 1. Start-up attente ai costi
Una start-up estremamente attenta ai costi vuole semplificare la distribuzione e la gestione dell'applicazione e può avere un contratto di servizio limitato per singoli clienti. Vuole tuttavia assicurarsi che l'applicazione nel suo complesso non sia mai offline.
Per rispettare il requisito relativo alla semplicità, distribuire tutti i database tenant in un pool elastico nell'area di Azure scelta e quindi distribuire i database di gestione come database singoli con replica geografica. Per il ripristino di emergenza dei tenant, usare il ripristino geografico, disponibile senza costi aggiuntivi. Per assicurare la disponibilità dei database di gestione, configurarne la replica geografica in un'altra area usando un gruppo di failover, come illustrato nel passaggio 1. In questo scenario, i costi di esercizio della configurazione per il ripristino di emergenza equivalgono al costo totale dei database secondari. Questa configurazione è illustrata nel diagramma seguente.
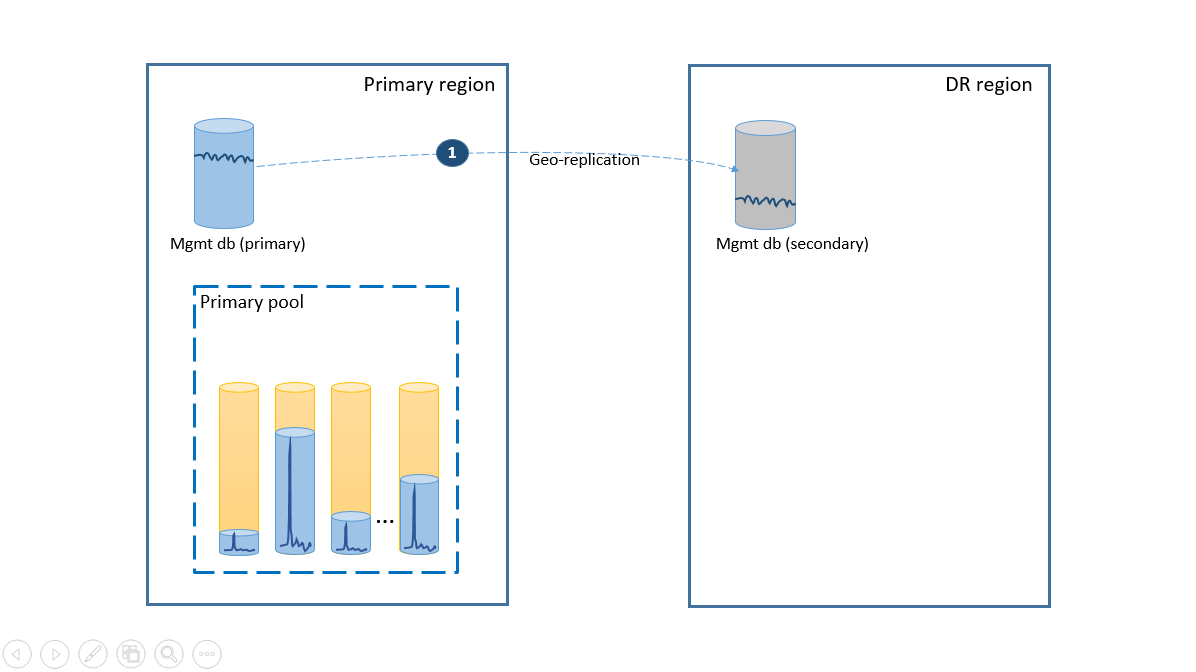
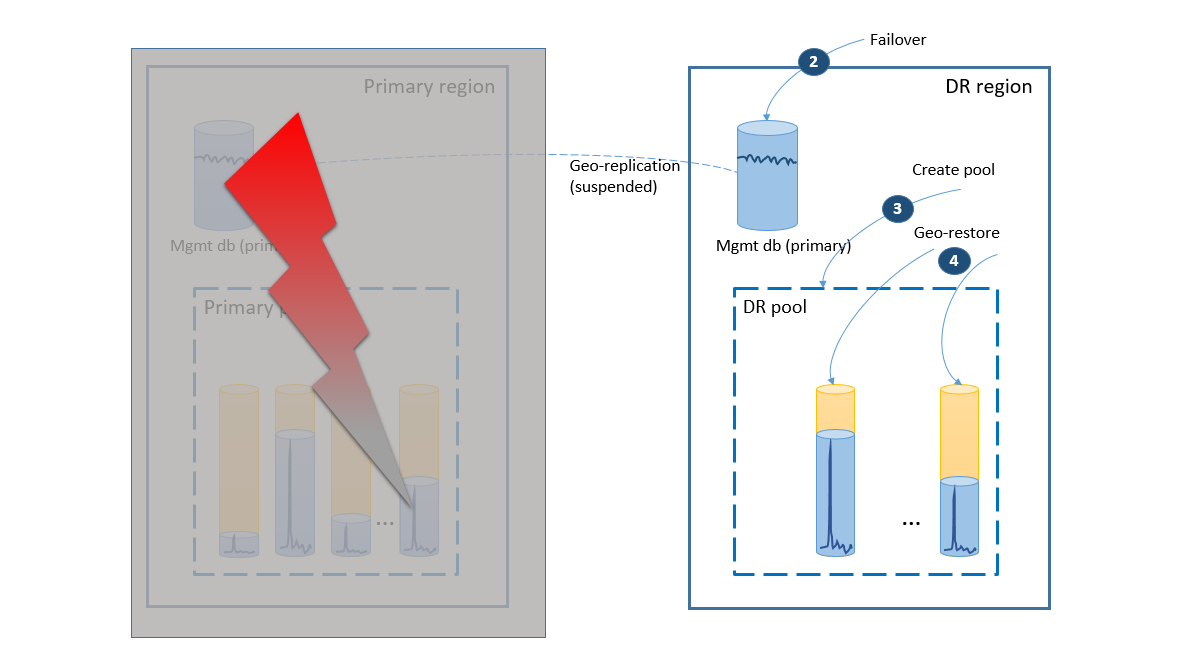
In caso di interruzione nell'area primaria, la procedura di ripristino per riportare online l'applicazione è illustrata nel diagramma seguente.
- Il gruppo di failover avvia il failover automatico del database di gestione per l'area di ripristino di emergenza. L'applicazione viene riconnessa automaticamente al nuovo account primario e a tutti i nuovi account e vengono creati i database tenant nell'area di ripristino di emergenza. I dati risultano temporaneamente non disponibili per i clienti esistenti.
- Creare il pool elastico con la stessa configurazione del pool originale (2).
- Usare il ripristino geografico per creare copie dei database tenant (3). È possibile prendere in considerazione l'attivazione dei singoli ripristini in base alle connessioni degli utenti finali oppure l'uso di un altro schema di priorità specifico dell'applicazione.
A questo punto l'applicazione è di nuovo online nell'area di ripristino di emergenza, ma alcuni clienti riscontrano un ritardo nell'accesso ai dati.
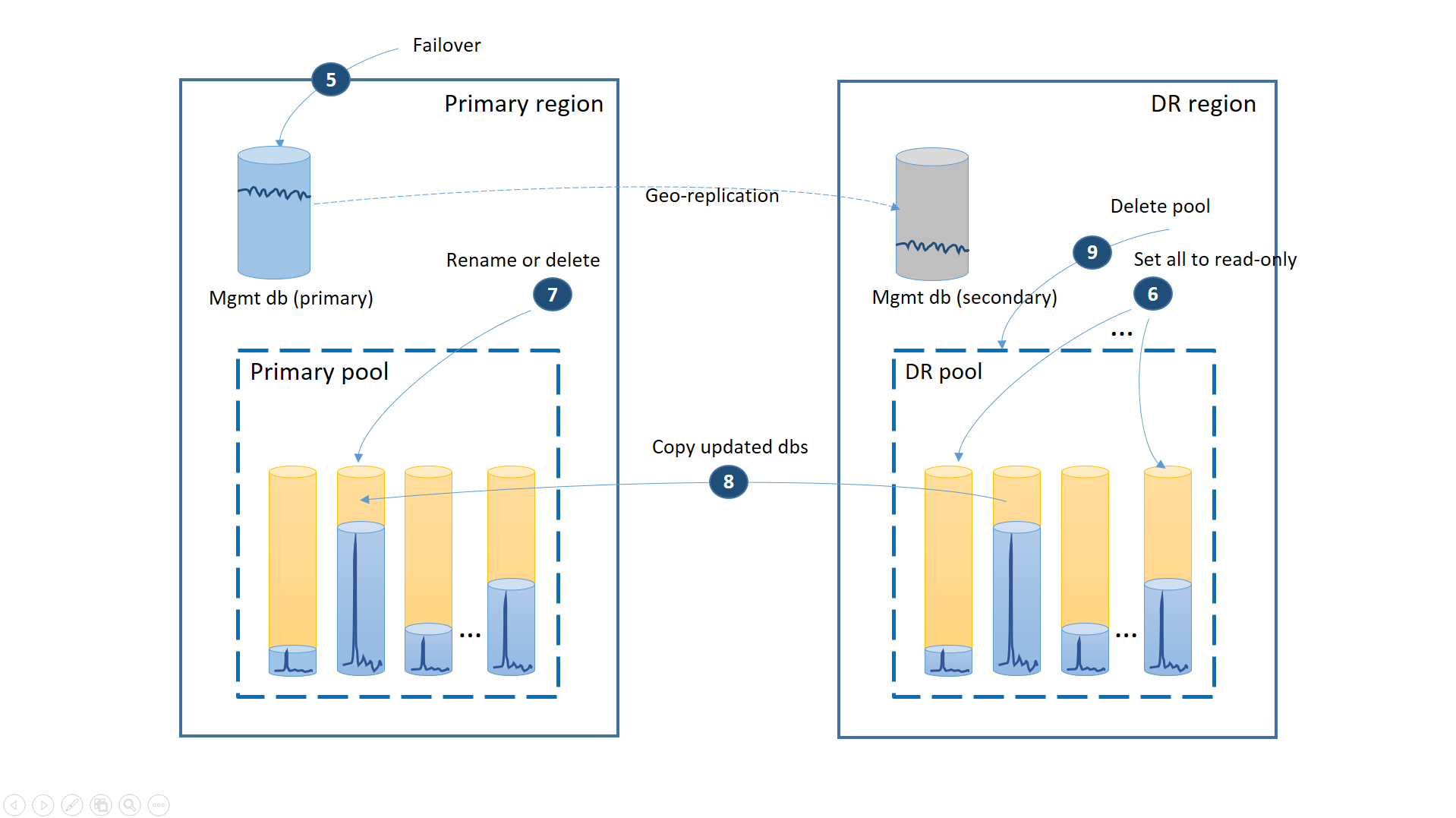
Se l'interruzione è stata temporanea, l'area primaria potrebbe essere ripristinata da Azure prima del completamento di tutti i ripristini dei database nell'area di ripristino di emergenza. In questo caso, orchestrare il ritorno dell'applicazione all'area primaria. Il processo esegue la procedura illustrata nel diagramma seguente.
- Annullare tutte le richieste di ripristino geografico in sospeso.
- Effettuare il failover dei database di gestione nell'area primaria (5). Dopo il ripristino dell'area, gli elementi primari precedenti sono diventati automaticamente secondari. Ora i ruoli vengono nuovamente invertiti.
- Modificare la stringa di connessione dell'applicazione in modo che faccia di nuovo riferimento all'area primaria. Tutti i nuovi account e database tenant verranno ora creati nell'area primaria. I dati risultano temporaneamente non disponibili per alcuni clienti esistenti.
- Impostare tutti i database nel pool di ripristino di emergenza su sola lettura, per assicurare che non possano essere modificati nell'area di ripristino di emergenza (6).
- Per ogni database nel pool di ripristino di emergenza modificato dopo il ripristino, rinominare o eliminare i database corrispondenti nel pool primario (7).
- Copiare i database aggiornati dal pool di ripristino di emergenza al pool primario (8).
- Eliminare il pool di ripristino di emergenza (9).
A questo punto l'applicazione è online nell'area primaria con tutti i database tenant disponibili nel pool primario.
Vantaggio
Il vantaggio principale di questa strategia è costituito dai costi di esercizio ridotti per la ridondanza a livello dati. I backup dei database vengono eseguiti automaticamente dal database SQL di Azure, senza riscrittura di applicazioni e senza costi aggiuntivi. I costi vengono addebitati solo quando i database elastici vengono ripristinati.
Compromesso
Lo svantaggio consiste nel fatto che il ripristino completo di tutti i database tenant richiede molto tempo, in base al numero totale di ripristini avviati nell'area di ripristino di emergenza e alle dimensioni complessive dei database tenant. Anche se si attribuisce priorità maggiore ai ripristini di alcuni tenant rispetto ad altri, si verificano conflitti con tutti gli altri ripristini avviati nella stessa area, perché il servizio esegue l'arbitraggio e applica la limitazione per ridurre al minimo l'impatto complessivo sui database dei clienti esistenti. Il ripristino dei database tenant, inoltre, può essere avviato solo dopo la creazione del nuovo pool elastico nell'area di ripristino di emergenza.
Scenario 2. Applicazione matura con più livelli di servizio
Un'applicazione SaaS matura con più livelli di offerte del servizio e diversi contratti di servizio per i clienti delle versioni di valutazione e i clienti delle versioni a pagamento deve ridurre il più possibile i costi per i clienti delle versioni di valutazione. Questi clienti possono accettare i tempi di inattività, ma si vuole ridurne la probabilità. Per i clienti delle versioni a pagamento, i tempi di inattività possono costituire un rischio inaccettabile. Si vuole quindi assicurare che i clienti delle versioni a pagamento riescano sempre ad accedere ai propri dati.
Per supportare questo scenario, separare i tenant delle versioni di valutazione dai tenant delle versioni a pagamento, inserendoli in pool elastici separati. I clienti delle versioni di valutazione avranno valori di eDTU o vCore per tenant inferiori e un contratto di servizio inferiore con tempi di ripristino più lunghi. I clienti delle versioni a pagamento saranno inclusi in un pool con valori di eDTU o vCore per tenant superiori e un contratto di servizio superiore. Per garantire tempi di ripristino minimi, i database tenant dei clienti delle versioni a pagamento sono sottoposti a replica geografica. Questa configurazione è illustrata nel diagramma seguente.
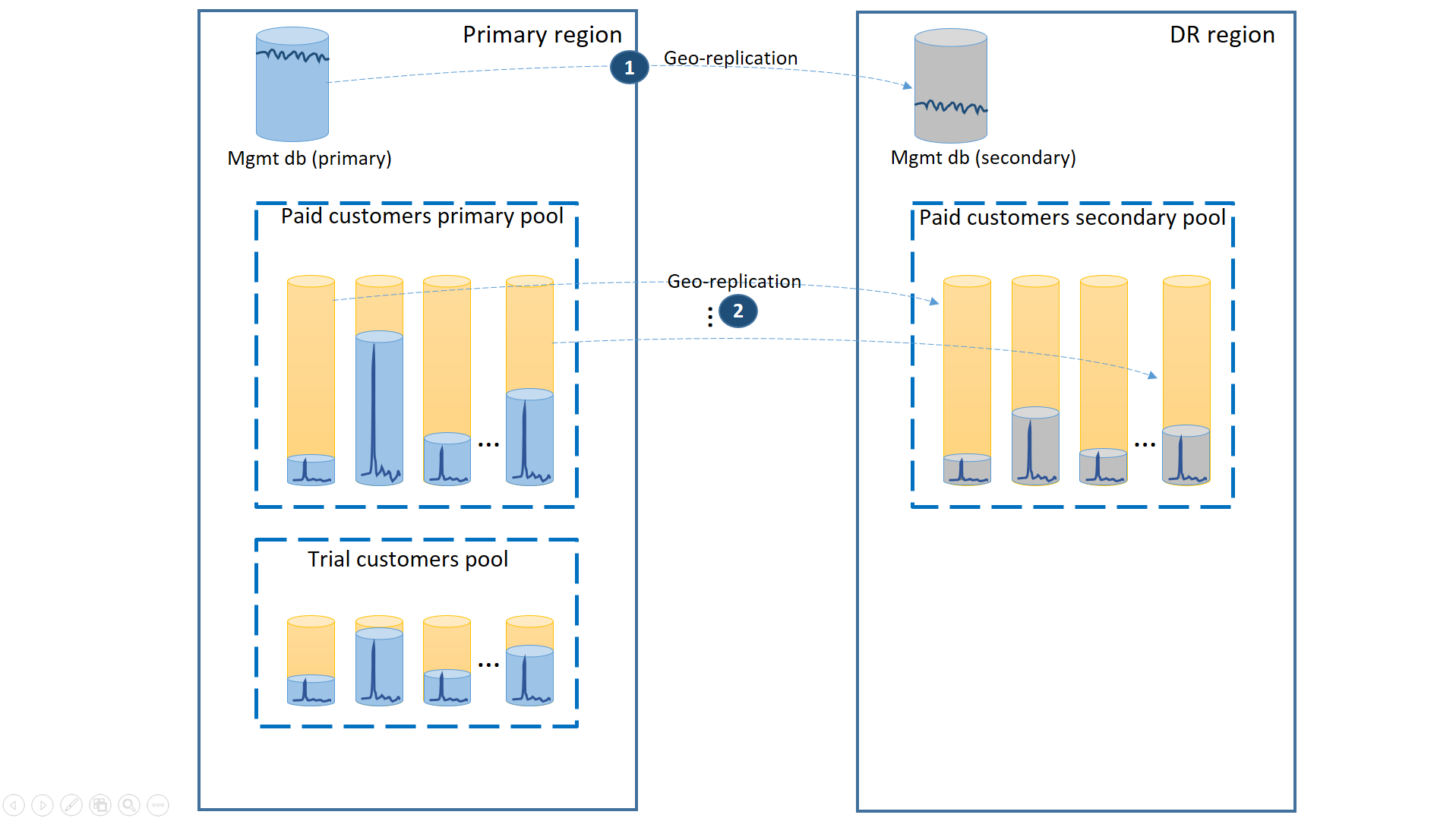
Come nel primo scenario, i database di gestione sono abbastanza attivi, quindi si usa allo scopo un database singolo con replica geografica (1). In questo modo si assicurano prestazioni prevedibili per le sottoscrizioni dei nuovi clienti, gli aggiornamenti dei profili e altre operazioni di gestione. L'area in cui risiedono gli elementi primari dei database di gestione è l'area primaria e quella in cui si trovano gli elementi secondari dei database di gestione è l'area di ripristino di emergenza.
I database tenant dei clienti delle versioni a pagamento hanno database attivi nel pool a pagamento sottoposto a provisioning nell'area primaria. Effettuare il provisioning di un pool secondario con lo stesso nome nell'area di ripristino di emergenza. Ogni tenant viene sottoposto a replica geografica nel pool secondario (2). Ciò consente un ripristino rapido di tutti i database tenant con il failover.
In caso di interruzione nell'area primaria, la procedura di ripristino per riportare online l'applicazione è illustrata nel diagramma seguente.
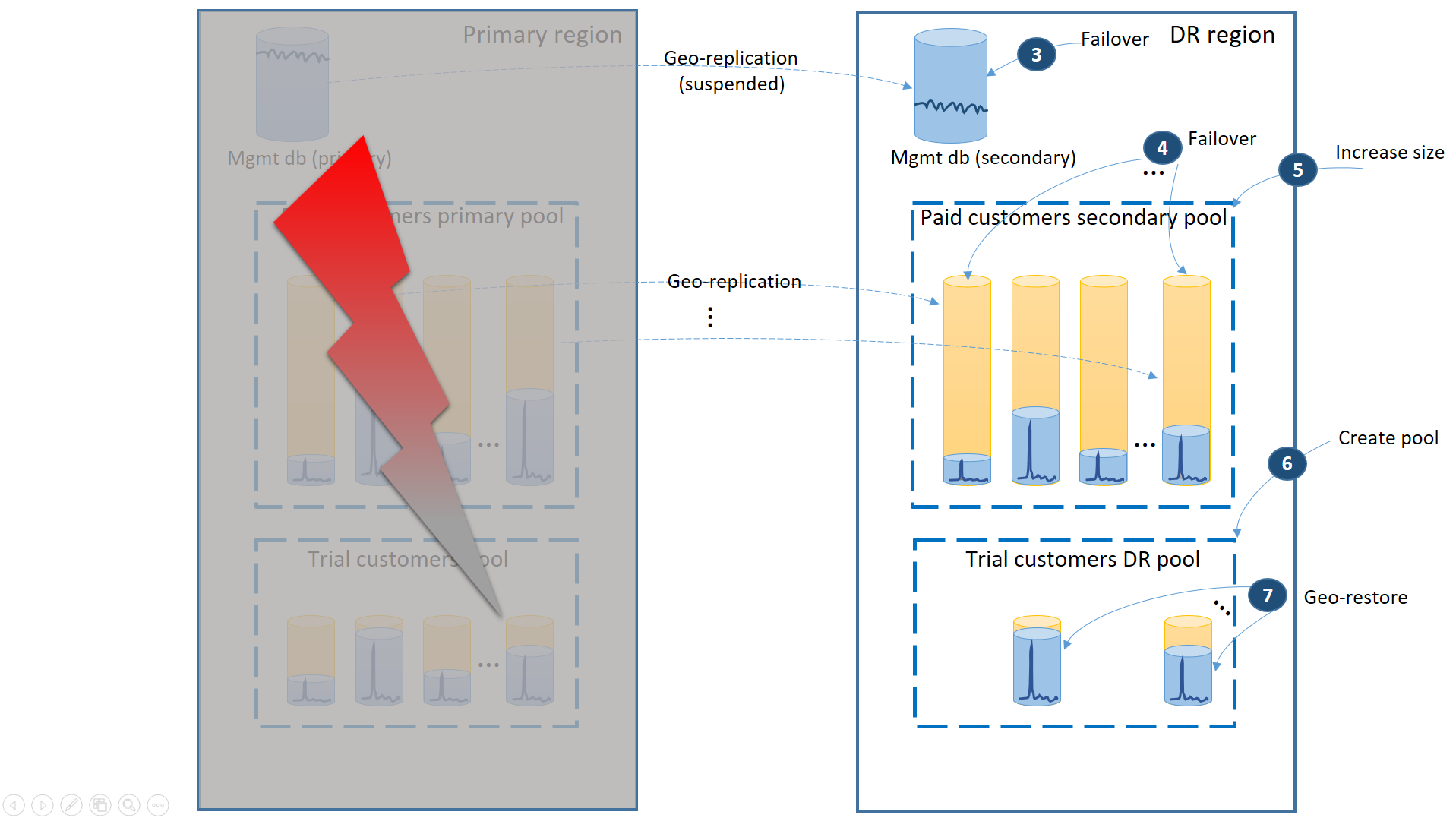
- Effettuare immediatamente il failover dei database di gestione nell'area di ripristino di emergenza (3).
- Modificare la stringa di connessione dell'applicazione in modo che faccia riferimento all'area di ripristino di emergenza. Tutti i nuovi account e database tenant verranno ora creati nell'area di ripristino di emergenza. I dati risulteranno temporaneamente non disponibili per i clienti esistenti delle versioni di valutazione.
- Effettuare il failover dei database tenant a pagamento nel pool nell'area di ripristino di emergenza per ripristinarne immediatamente la disponibilità (4). Dato che il failover è una rapida modifica a livello di metadati, prendere in considerazione un'ottimizzazione con attivazione su richiesta dei singoli failover da parte delle connessioni degli utenti finali.
- Se le dimensioni di eDTU o il valore di vCore del pool secondario sono inferiori a quelli del pool primario perché i database secondari richiedevano solo le funzionalità necessarie per elaborare i log delle modifiche durante l'impostazione come secondari, aumentare immediatamente la capacità del pool per adeguarla all'intero carico di lavoro di tutti i tenant (5).
- Creare il nuovo pool elastico con lo stesso nome e la stessa configurazione nell'area di ripristino di emergenza per i database dei clienti della versione di valutazione (6).
- Dopo la creazione del pool dei clienti della versione di valutazione, usare il ripristino geografico per ripristinare i singoli database tenant della versione di valutazione nel nuovo pool (7). Prendere in considerazione l'attivazione dei singoli ripristini in base alle connessioni degli utenti finali oppure l'uso di un altro schema di priorità specifico dell'applicazione.
A questo punto l'applicazione è di nuovo online nell'area di ripristino di emergenza. Tutti i clienti delle versioni a pagamento possono accedere ai propri dati, mentre i clienti delle versioni di valutazione riscontrano un ritardo nell'accesso ai dati.
Quando l'area primaria viene ripristinata da Azure dopo il ripristino dell'applicazione nell'area di ripristino di emergenza, è possibile continuare a eseguire l'applicazione in tale area oppure eseguire il failback nell'area primaria. Se l'area primaria viene ripristinata prima che il processo di failover sia completato, valutare la possibilità di effettuare immediatamente il failback. Il failback prevede la procedura illustrata nel diagramma seguente:
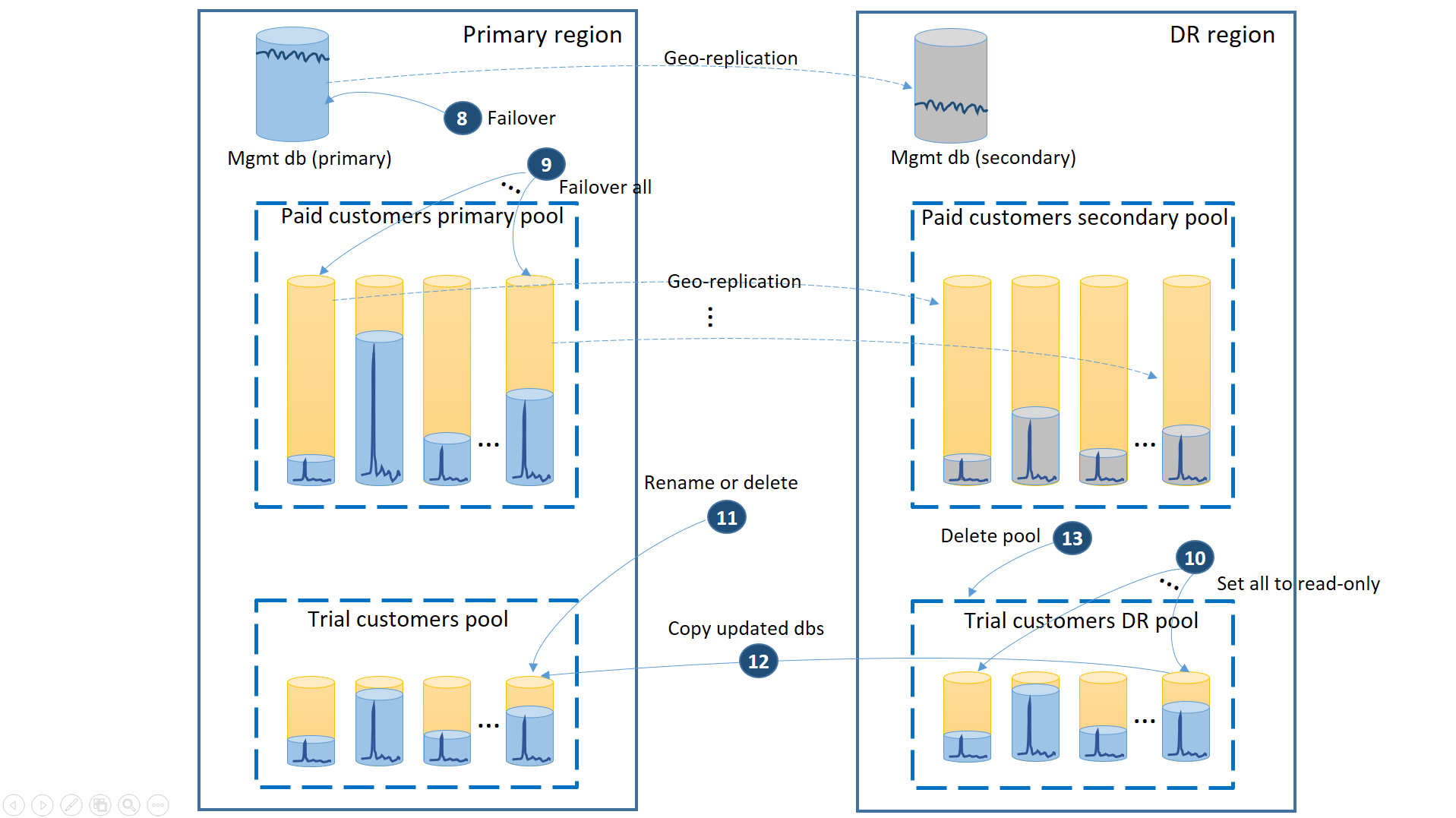
- Annullare tutte le richieste di ripristino geografico in sospeso.
- Effettuare il failover dei database di gestione (8). Dopo il ripristino dell'area, l'elemento primario precedente diventa automaticamente l'elemento secondario. Ora diventa di nuovo primario.
- Effettuare il failover dei database tenant delle versioni a pagamento (9). Analogamente, dopo il ripristino dell'area, gli elementi primari precedenti diventano automaticamente secondari. Ora diventano di nuovo primari.
- Impostare su sola lettura i database della versione di valutazione ripristinati che hanno subito modifiche nell'area di ripristino di emergenza (10).
- Per ogni database nel pool di ripristino di emergenza dei clienti della versione di valutazione modificato dopo il ripristino, rinominare o eliminare il database corrispondente nel pool primario dei clienti della versione di valutazione (11).
- Copiare i database aggiornati dal pool di ripristino di emergenza al pool primario (12).
- Eliminare il pool di ripristino di emergenza (13).
Nota
L'operazione di failover è asincrona. Per ridurre al minimo il tempo necessario per il ripristino, è importante eseguire il comando di failover dei database tenant in batch di almeno 20 database.
Vantaggio
Il vantaggio principale di questa strategia consiste nel fatto che offre il Contratto di servizio migliore per i clienti a pagamento. Garantisce anche che le nuove versioni di valutazione vengano sbloccate non appena viene creato il pool di ripristino di emergenza della versione di valutazione.
Compromesso
Lo svantaggio consiste nel fatto che questa configurazione aumenta il costo totale dei database tenant in base al costo del pool di ripristino di emergenza secondario per i clienti a pagamento. Se il pool secondario ha dimensioni diverse, inoltre, i clienti delle versioni a pagamento riscontrano prestazioni inferiori dopo il failover fino al completamento dell'aggiornamento del pool nell'area di ripristino di emergenza.
Scenario 3. Applicazione geograficamente distribuita con più livelli di servizio
Un'applicazione SaaS matura con offerte di più livelli di servizio vuole offrire un Contratto di servizio molto aggressivo ai clienti della versione a pagamento e vuole ridurre al minimo il rischio di impatto di eventuali interruzioni, perché anche una breve interruzione può causare l'insoddisfazione dei clienti. È essenziale che i clienti della versione a pagamento possano accedere sempre ai propri dati. Le versioni di valutazione sono gratuite e non è disponibile alcun Contratto di servizio durante il periodo di valutazione.
Per supportare questo scenario, usare tre pool elastici separati. È necessario effettuare il provisioning di due pool di dimensioni uguali con valori eDTU o vCore elevati per ogni database in due aree diverse per includere i database tenant dei clienti della versione a pagamento. Il terzo pool contenente i tenant delle versioni di valutazione può avere valori eDTU o vCore inferiori per ogni database e viene sottoposto a provisioning in una delle due aree.
Per garantire tempi di ripristino minimi durante le interruzioni, i database tenant dei clienti della versione a pagamento sono sottoposti a replica geografica con il 50% dei database primari in ognuna delle due aree. Analogamente, ogni area include il 50% dei database secondari. In questo modo, lo stato offline di un'area influisce solo sul 50% dei database dei clienti a pagamento, di cui viene effettuato il failover. Gli altri database rimangono inalterati. Questa configurazione è illustrata nel diagramma seguente:
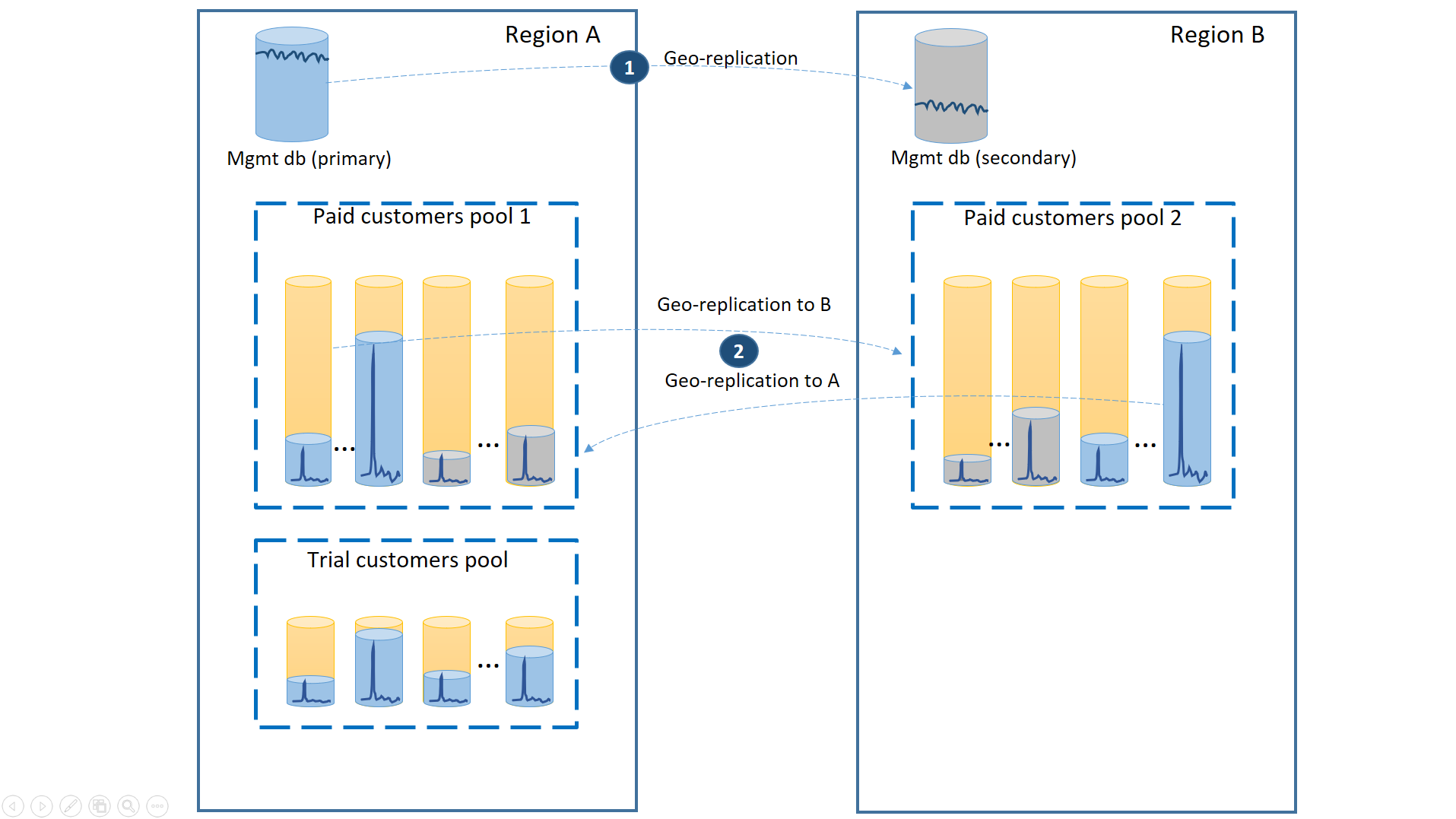
Come nello scenario precedente, i database di gestione sono abbastanza attivi, quindi devono essere configurati come database singoli con replica geografica (1). In questo modo si assicurano prestazioni prevedibili per le sottoscrizioni dei nuovi clienti, gli aggiornamenti dei profili e altre operazioni di gestione. L'area A è l'area primaria per i database di gestione e l'area B viene usata per il ripristino dei database di gestione.
I database tenant dei clienti della versione a pagamento vengono sottoposti anche a replica geografica, ma con suddivisione degli elementi primari e secondari tra area A e area B (2). In questo modo, i database tenant primari interessati dall'interruzione possono essere sottoposti a failover nell'altra area e risultare disponibili. Sull'altra metà dei database tenant non si verifica alcun impatto.
Il diagramma seguente illustra la procedura di ripristino da eseguire in caso di interruzione nell'area A.
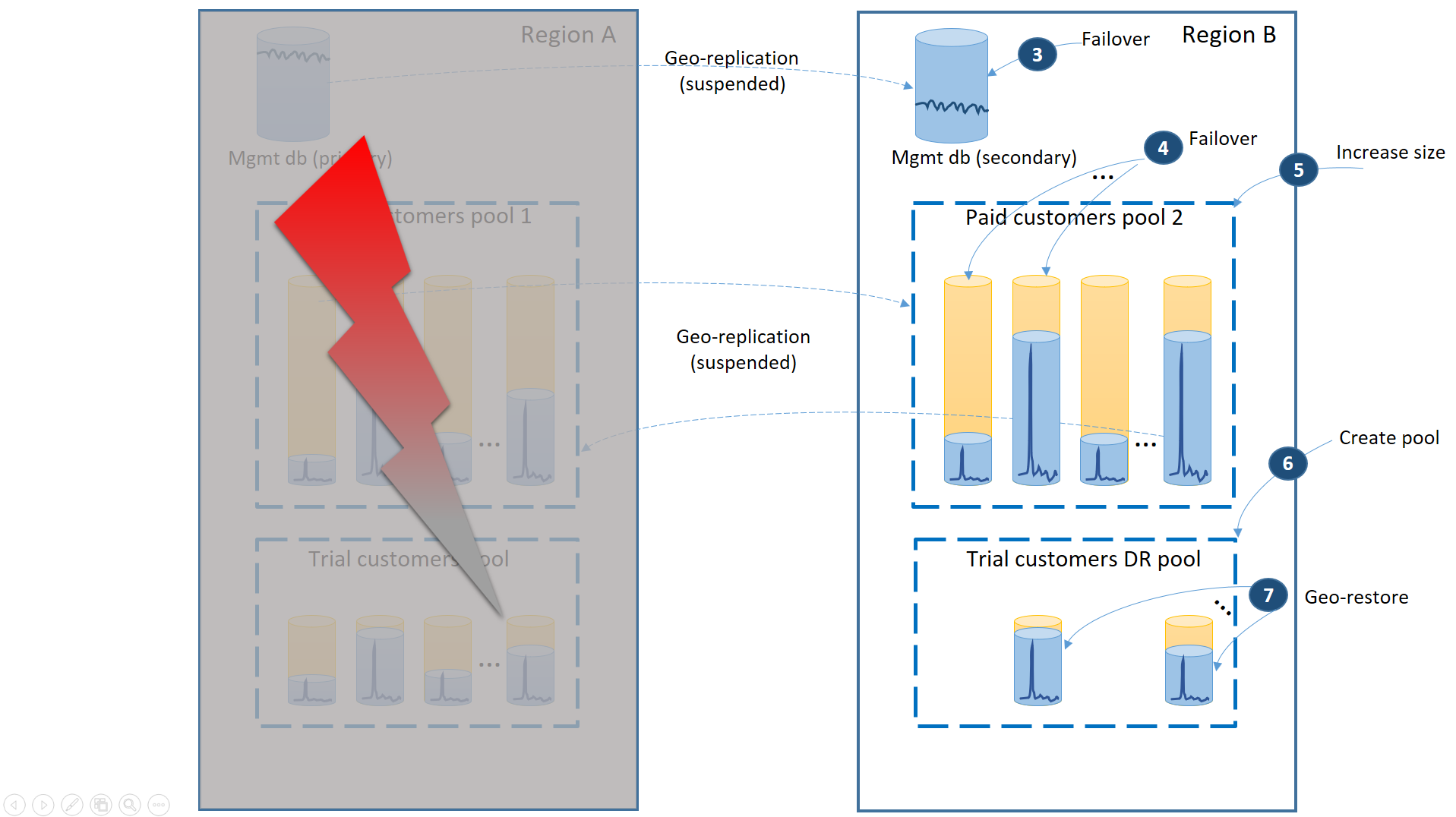
- Eseguire immediatamente il failover dei database di gestione nell'area B (3).
- Modificare la stringa di connessione dell'applicazione in modo che faccia riferimento ai database di gestione nell'area B. Modificare i database di gestione affinché i nuovi account e database tenant vengano creati nell'area B e i database tenant esistenti siano disponibili in tale area. I dati risulteranno temporaneamente non disponibili per i clienti esistenti delle versioni di valutazione.
- Effettuare il failover dei database tenant a pagamento nel pool 2 nell'area B per ripristinarne immediatamente la disponibilità (4). Dato che il failover è una rapida modifica a livello di metadati, è possibile prendere in considerazione un'ottimizzazione con attivazione su richiesta dei singoli failover da parte delle connessioni degli utenti finali.
- Dato che il pool 2 ora contiene solo database primari, il carico di lavoro totale nel pool aumenta ed è possibile incrementare immediatamente le dimensioni di eDTU (5) o il numero di vCore.
- Creare il nuovo pool elastico con lo stesso nome e la stessa configurazione nell'area B per i database dei clienti della versione di valutazione (6).
- Dopo la creazione del pool, usare il ripristino geografico per ripristinare il singolo database tenant della versione di valutazione nel pool (7). È possibile prendere in considerazione l'attivazione dei singoli ripristini in base alle connessioni degli utenti finali oppure l'uso di un altro schema di priorità specifico dell'applicazione.
Nota
L'operazione di failover è asincrona. Per ridurre al minimo i tempi di ripristino, è importante eseguire il comando di failover dei database tenant in batch di almeno 20 database.
A questo punto l'applicazione è di nuovo online nell'area B. Tutti i clienti a pagamento possono accedere ai propri dati, mentre i clienti delle versioni di valutazione riscontrano un ritardo nell'accesso ai dati.
Al termine del ripristino dell'area A, è necessario decidere se si vuole usare l'area B per i clienti della versione di valutazione o eseguire il failback e usare di nuovo il pool dei clienti della versione di valutazione nell'area A. Un criterio per la decisione potrebbe essere rappresentato dalla percentuale di database tenant della versione di valutazione modificati dopo il ripristino. Indipendentemente da questa decisione, è necessario ribilanciare i tenant della versione a pagamento tra i due pool. Il diagramma seguente illustra il processo di failback dei database tenant della versione di valutazione nell'area A.
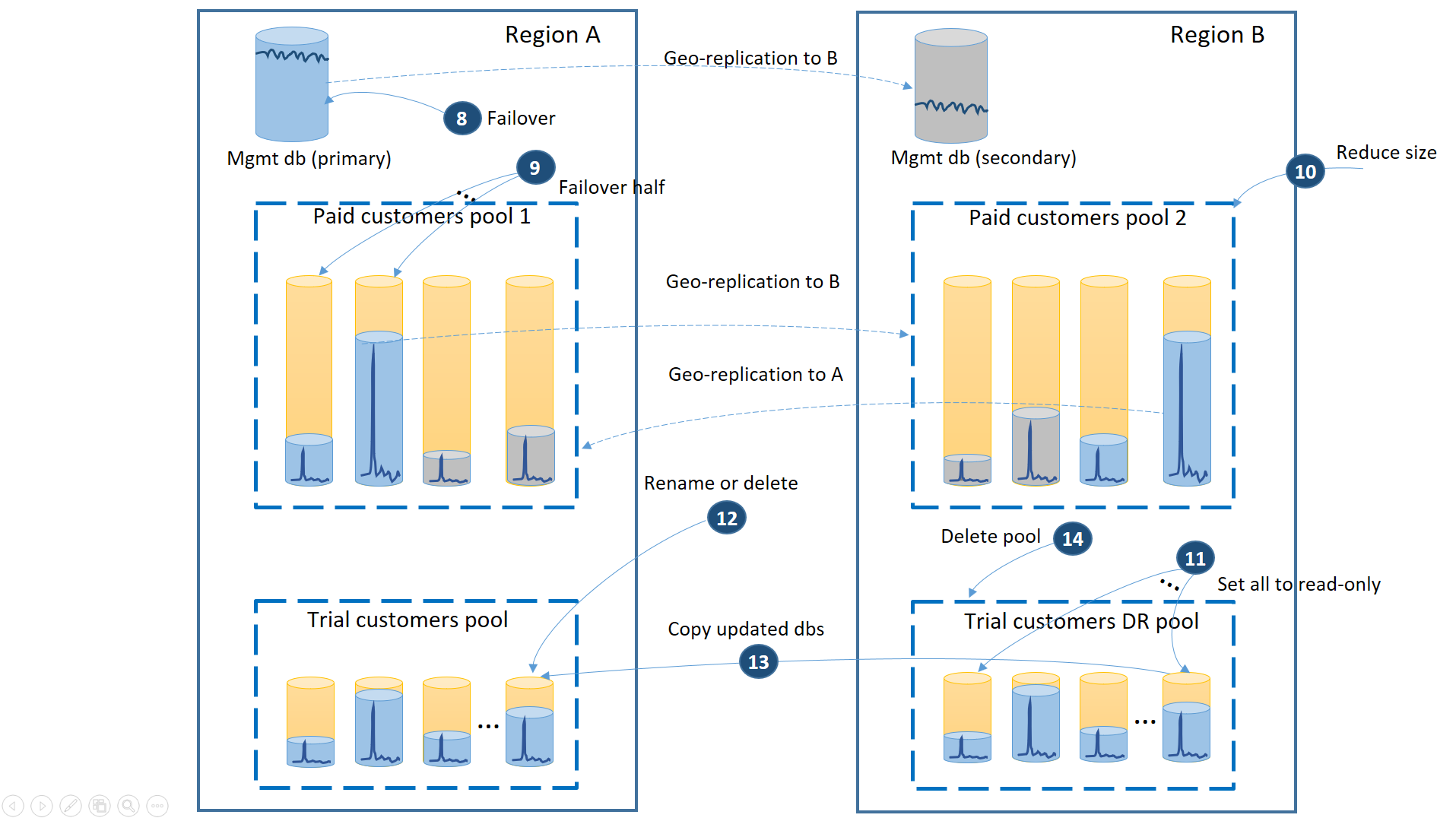
- Annullare tutte le richieste di ripristino geografico in sospeso verso il pool di ripristino di emergenza della versione di valutazione.
- Effettuare il failover del database di gestione (8). Dopo il ripristino dell'area, l'elemento primario precedente è diventato automaticamente l'elemento secondario. Ora diventa di nuovo primario.
- Selezionare i database tenant della versione a pagamento di cui verrà effettuato il failback nel pool 1 e avviare il failover negli elementi secondari (9). Dopo il ripristino dell'area, tutti i database nel pool 1 sono diventati automaticamente secondari. Ora il 50% dei database diventa di nuovo primario.
- Ridurre le dimensioni del pool 2 al valore eDTU (10) o al numero di vCore originale.
- Impostare su sola lettura tutti i database della versione di valutazione ripristinati nell'area B (11).
- Per ogni database nel pool di ripristino di emergenza delle versioni di valutazione modificato dopo il ripristino, rinominare o eliminare il database corrispondente nel pool primario delle versioni di valutazione (12).
- Copiare i database aggiornati dal pool di ripristino di emergenza al pool primario (13).
- Eliminare il pool di ripristino di emergenza (14).
Vantaggio
Ecco i vantaggi principali di questa strategia:
- Supporta il Contratto di servizio più aggressivo per i clienti della versione a pagamento, perché assicura che un'interruzione non possa influire su oltre il 50% dei database tenant.
- Garantisce che le nuove versioni di valutazione vengano sbloccate non appena viene creato il pool di ripristino di emergenza della versione di valutazione durante il ripristino.
- Consente un uso più efficiente della capacità dei pool, perché il 50% dei database secondari nel pool 1 e nel pool 2 risulta sicuramente meno attiva rispetto ai database primari.
Compromessi
Ecco gli svantaggi principali:
- Le operazioni CRUD sui database di gestione hanno una latenza minore per gli utenti finali connessi all'area A rispetto agli utenti finali connessi all'area B, perché verranno eseguite sui database di gestione primari.
- Richiede una progettazione più complessa per il database di gestione. Ogni record dei tenant, ad esempio, ha un tag di posizione che deve essere modificato durante il failover e il failback.
- I clienti della versione a pagamento potrebbero notare prestazioni inferiori al consueto fino al completamento dell'aggiornamento del pool nell'area B.
Riepilogo
Questo articolo illustra le strategie di ripristino di emergenza per il livello database usato da un'applicazione multi-tenant ISV SaaS. La scelta della strategia si basa sulle esigenze dell'applicazione, ad esempio il modello aziendale, il contratto di servizio da offrire ai clienti, i vincoli di budget e così via. Ogni strategia descritta illustra i vantaggi e i compromessi, in modo da consentire una decisione informata. È anche probabile che l'applicazione specifica includa altri componenti di Azure. Esaminare quindi le rispettive indicazioni relative alla continuità aziendale e orchestrare il ripristino del livello database con tali componenti. Per altre informazioni sulla gestione del ripristino di applicazioni di database in Azure, vedere l'articolo relativo alla progettazione di soluzioni cloud per il ripristino di emergenza.
Passaggi successivi
- Per informazioni sui backup automatici del database SQL di Azure, vedere Backup automatici del database SQL di Azure.
- Per la panoramica e gli scenari della continuità aziendale, vedere Continuità aziendale del database SQL di Azure.
- Per altre informazioni sull'uso dei backup automatici per il ripristino, vedere l'articolo relativo al ripristino di un database dai backup avviati dal servizio.
- Per altre informazioni su opzioni di ripristino più veloci, consultare l'articolo sulla replica geografica attiva e i gruppi di failover.
- Per altre informazioni sull'uso dei backup automatici per l'archiviazione, vedere Copiare un database SQL di Azure.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per