Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
I pool elastici di Database SQL di Azure offrono una soluzione semplice e conveniente a livello di costo per la gestione e il ridimensionamento di più database con esigenze di utilizzo variabili e imprevedibili. I database in un pool elastico si trovano in un singolo server e condividono un determinato numero di risorse a un prezzo stabilito. I pool elastici nel database SQL di Azure consentono agli sviluppatori di Software as a Service (SaaS) di ottimizzare il rapporto qualità-prezzo per un gruppo di database all'interno di un budget definito, garantendo allo stesso tempo prestazioni elastiche per ogni database.
Che cosa sono i pool elastici SQL?
Gli sviluppatori di SaaS costruiscono applicazioni basate su livelli dati su larga scala costituiti da più database. Un tipico modello di applicazione è il provisioning di un database singolo per ogni cliente. Tuttavia, diversi clienti spesso hanno modelli di utilizzo differenti e non prevedibili ed è difficile prevedere i requisiti di risorse di ogni singolo utente del database. In genere, le opzioni erano due:
- Effettuare un provisioning eccessivo di risorse in base all'utilizzo massimo e pagare più del necessario.
- Ricorrere a un provisioning insufficiente per risparmiare sui costi, a scapito delle prestazioni e della soddisfazione del cliente durante i picchi di utilizzo.
I pool elastici risolvono questo problema garantendo che i database ottengano delle risorse di prestazione necessarie, quando richieste. Forniscono un meccanismo semplice di allocazione delle risorse che rientra in un budget prevedibile. Per altre informazioni sui modelli di progettazione per le applicazioni SaaS che usano pool elastici, vedere modelli di tenancy del database SaaS multi-tenant.
Importante
Non è previsto alcun addebito per database per i pool elastici. Viene fatturata ogni ora in cui un pool esiste con il livello massimo di eDTU o vCore, indipendentemente dall'utilizzo o dal fatto che il pool sia stato attivo per meno di un'ora.
I pool elastici consentono di acquistare risorse per un pool condiviso da più database, in modo da supportare periodi di utilizzo imprevisti da parte dei singoli database. È possibile configurare le risorse per il pool in base al modello di acquisto basato su DTU o al modello di acquisto basato su vCore. La richiesta di risorse per un pool è determinata dall’utilizzo aggregato dei relativi database.
La quantità di risorse disponibili per il pool dipende dal proprio budget. Ti basta fare quanto segue:
- Aggiungere database al pool.
- Facoltativamente, impostare le risorse minime e massime per i database, nel modello di acquisto DTU o vCore.
- Impostare le risorse del pool in base al proprio budget.
È possibile usare i pool per far crescere con facilità i servizi offerti da una piccola nuova impresa fino a un'azienda matura in continua crescita.
All'interno del pool i singoli database sono sufficientemente flessibili da consentire l'uso delle risorse nell'ambito di parametri prefissati. Se il carico di lavoro è importante, un database può utilizzare più risorse per soddisfare la domanda. I database con carichi di lavoro leggeri consumano meno, e quelli senza carico non utilizzano risorse. La possibilità di effettuare il provisioning delle risorse per l'intero pool e non per i singoli database semplifica le attività di gestione. Inoltre, hai un budget prevedibile per la piscina.
È possibile aggiungere altre risorse a un pool esistente con un tempo inattivo minimo. Se le risorse aggiuntive non sono più necessarie, è possibile rimuoverle da un pool esistente in qualsiasi momento. Inoltre, è possibile aggiungere o rimuovere i database dal pool. Se si prevede che un database utilizzerà meno risorse del necessario, è possibile rimuoverlo.
Nota
Quando si spostano database all'interno o all'esterno di un pool elastico, non si verificano interruzioni, ad eccezione di un breve periodo (nell'ordine di pochi secondi) alla fine dell'operazione, quando vengono interrotte le connessioni al database.
Quando considerare un pool elastico del database SQL?
I pool sono adatti per un numero elevato di database con modelli di utilizzo specifici. Questo modello è caratterizzato da un utilizzo medio ridotto con picchi di utilizzo relativamente rari per un determinato database. Al contrario, più database con utilizzo medio-elevato persistente non devono essere collocati nello stesso pool elastico.
Più database è possibile aggiungere a un pool, maggiori sono i risparmi. In base al modello di uso dell'applicazione, è possibile osservare un risparmio anche con soli due database S3.
Le sezioni seguenti aiutano a comprendere se l'insieme specifico di database può trarre vantaggio dall'uso di un pool. Gli esempi usano pool Standard, ma si applicano gli stessi principi anche ai pool elastici in altri livelli di servizio.
Valutare i modelli di utilizzo di database
La figura seguente mostra un esempio di un database che trascorre gran parte del tempo inattivo, ma periodicamente presenta picchi di attività. Questo modello di utilizzo è adatto per un pool.
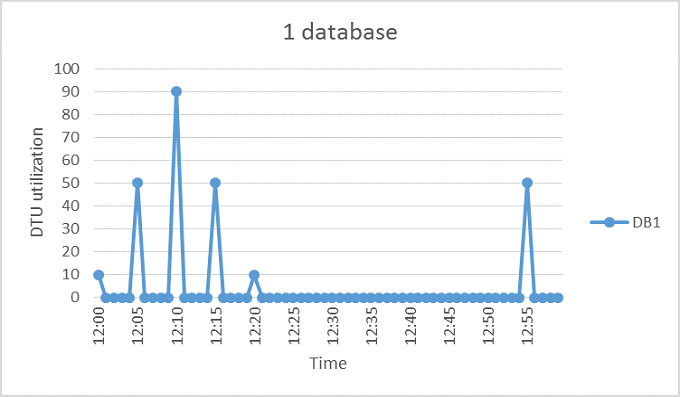
Il grafico illustra l'utilizzo di DTU nell'arco di un'ora dalle 12:00 alle 13:00 in cui ogni punto dati ha una granularità di un minuto. Alle 12:10, DB1 raggiunge un picco di 90 DTU, ma l'utilizzo medio complessivo è inferiore a cinque DTU. L'esecuzione di questo carico di lavoro in un database singolo richiede dimensioni di calcolo S3, ma in questo modo la maggior parte delle risorse rimane inutilizzata durante i periodi di minore attività.
Un pool consente la condivisione tra più database di queste DTU inutilizzate. Un pool riduce le DTU necessarie e il costo complessivo.
Basandoci sull'esempio precedente, si suppone che vi siano altri database con modelli di utilizzo simili a DB1. Nelle due figure seguenti vengono presentati in parallelo l'utilizzo di 4 database e quello di 20 database all'interno di uno stesso grafico per mostrare l'assenza di sovrapposizione del loro utilizzo dei database nel tempo quando viene usato il modello di acquisto basato su DTU:
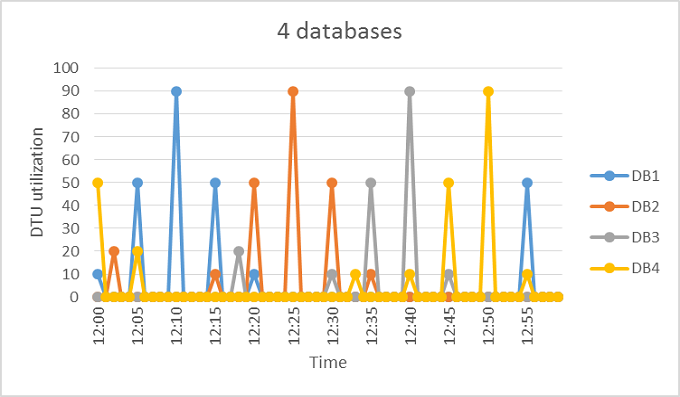
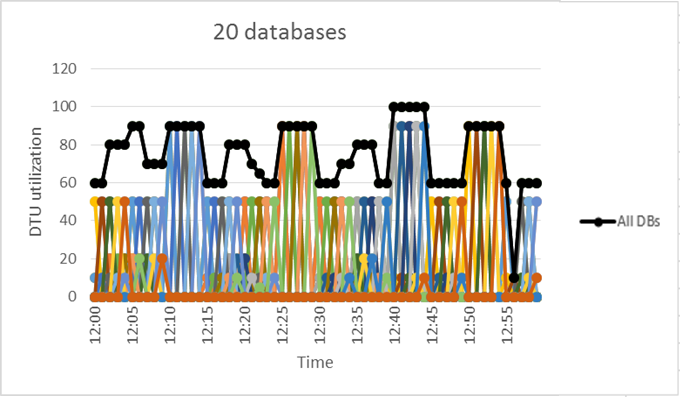
La linea di colore nero nel grafico precedente illustra l'utilizzo di DTU di aggregazione in tutti i 20 database. Questa linea mostra che l'utilizzo di DTU aggregato non supera mai le 100 DTU, ciò indica che i 20 database possono condividere 100 eDTU nel corso di tale periodo di tempo. Il risultato è una riduzione delle DTU di 20 volte una riduzione del prezzo di 13 volte rispetto all'inserimento di ogni database in dimensioni di calcolo S3 per database singolo.
Questo esempio é ideale perché:
- Esistono grandi differenze tra i picchi di utilizzo e l'utilizzo medio per ogni database.
- Il picco di utilizzo per ogni database si verifica in diversi momenti nel tempo.
- Le eDTU vengono condivise tra più database.
Nel modello di acquisto delle DTU, il prezzo di un pool è una funzione delle eDTU del pool. Mentre il prezzo unitario delle eDTU di un pool è 1,5 volte maggiore rispetto al prezzo unitario delle DTU per un database singolo, le eDTU del pool possono essere condivise da molti database ed è necessario un minor numero totale di eDTU. Queste distinzioni nella determinazione dei prezzi e nella condivisione di eDTU costituiscono la base del potenziale risparmio sul prezzo che il pool è in grado di fornire.
Nel modello di acquisto vCore il prezzo unitario vCore per i pool elastici corrisponde al prezzo unitario vCore per i database singoli.
Come scegliere le dimensioni più adatte del pool
La dimensione ottimale per un pool dipende dalle risorse di aggregazione e dalle risorse di archiviazione necessarie per tutti i database nel pool. È necessario determinare:
- Utilizzo delle risorse di calcolo massime utilizzate da tutti i database nel pool. Le risorse di calcolo vengono indicizzate sia tramite eDTU che tramite vCore, a seconda del modello di acquisto scelto.
- Byte di archiviazione massima utilizzati da tutti i database nel pool.
Per i livelli di servizio e i limiti delle risorse per ogni modello di acquisto, vedere il modello di acquisto basato su DTU o il modello di acquisto basato su vCore.
I seguenti passaggi consentono di stimare se un pool è più conveniente rispetto ai database singoli:
Stimare le eDTU o i vCore necessari per il pool:
- Per il modello di acquisto basato su DTU:
- MAX(<Numero totale di DB × utilizzo medio di DTU per DB>, <numero di database con picchi simultanei × massimo utilizzo di DTU per DB>)
- Per il modello di acquisto basato su vCore:
- MAX(<Numero totale di DB × utilizzo medio di vCore per DB>, <numero di database con picchi simultanei × Massimo utilizzo di vCore per DB>)
- Per il modello di acquisto basato su DTU:
Stimare lo spazio di archiviazione totale necessario per il pool aggiungendo le dimensioni dei dati necessari per tutti i database nel pool. Per il modello di acquisto DTU, determinare la dimensione del pool di eDTU che fornisce questa quantità di spazio di archiviazione.
Per il modello di acquisto basato su DTU, considerare la stima di eDTU maggiore tra il passaggio 1 e il passaggio 2.
- Per il modello di acquisto basato su "vCore", utilizzare la stima di "vCore" del passaggio 1.
Vedere la pagina dei prezzi di Database SQL.
- Trova la dimensione del pool più piccola maggiore della stima ottenuta nel passaggio 3.
Confrontare il prezzo del pool ottenuto nel passaggio 4 con l'utilizzo delle dimensioni di calcolo appropriate per database singoli.
Importante
Se il numero di database in un pool si avvicina al massimo supportato, assicurarsi di fare riferimento a Gestione delle risorse nei pool elastici densi.
Proprietà di ciascun database
È possibile impostare le proprietà per database per modificare i modelli di consumo delle risorse nei pool elastici. Per altre informazioni, vedere la documentazione sui limiti delle risorse per i pool elastici DTU e vCore.
Uso di altre funzionalità del database SQL con i pool elastici
È possibile usare altre funzionalità del database SQL con i pool elastici.
Processi elastici e pool elastici
L'uso di un pool permette di semplificare le attività di gestione con l'esecuzione di script in processi elastici. Un processo elastico elimina la maggior parte delle attività ripetitive associate a un elevato numero di database.
Per ulteriori informazioni su altri strumenti di database per lavorare con più database, vedere Ridimensionamento orizzontale con il database SQL di Azure.
Pool elastici Hyperscale
La panoramica dei pool elastici Hyperscale in Database SQL di Azure è generalmente disponibile.
Istanze di espansione orizzontale di sola lettura
Non è possibile utilizzare le istanze di scalabilità orizzontale di sola lettura del Database SQL di Azure con la query elastica.
Opzioni di continuità aziendale per i database in un pool elastico
In genere, i database in pool supportano le stesse funzionalità di continuità aziendale disponibili per i database singoli:
- Ripristino temporizzato: il ripristino temporizzato usa i backup automatici del database per ripristinare un database in un pool a un punto specifico nel tempo. Vedere Ripristino temporizzato.
- Ripristino geografico: il ripristino geografico fornisce un'opzione predefinita di ripristino quando un database non è disponibile a causa di un evento imprevisto nell'area in cui è ospitato. Vedere Ripristino geografico.
- Replica geografica attiva: per le applicazioni che hanno requisiti di ripristino più elevati di quelli offerti dal ripristino geografico, configurare la replica geografica attiva o un gruppo di failover.
Per altre informazioni sulle strategie precedenti, vedere Indicazioni sul ripristino di emergenza.
Creare un nuovo pool elastico del database SQL usando il portale di Azure
Esistono due modi per creare un pool elastico nel portale di Azure:
- Creare un pool elastico e selezionare un server esistente o un nuovo server.
- Creare un pool elastico da un server esistente.
Per creare un pool elastico e selezionare un server esistente o un nuovo server:
Andare sul portale di Azure per creare un pool elastico. Cercare e selezionare Azure SQL.
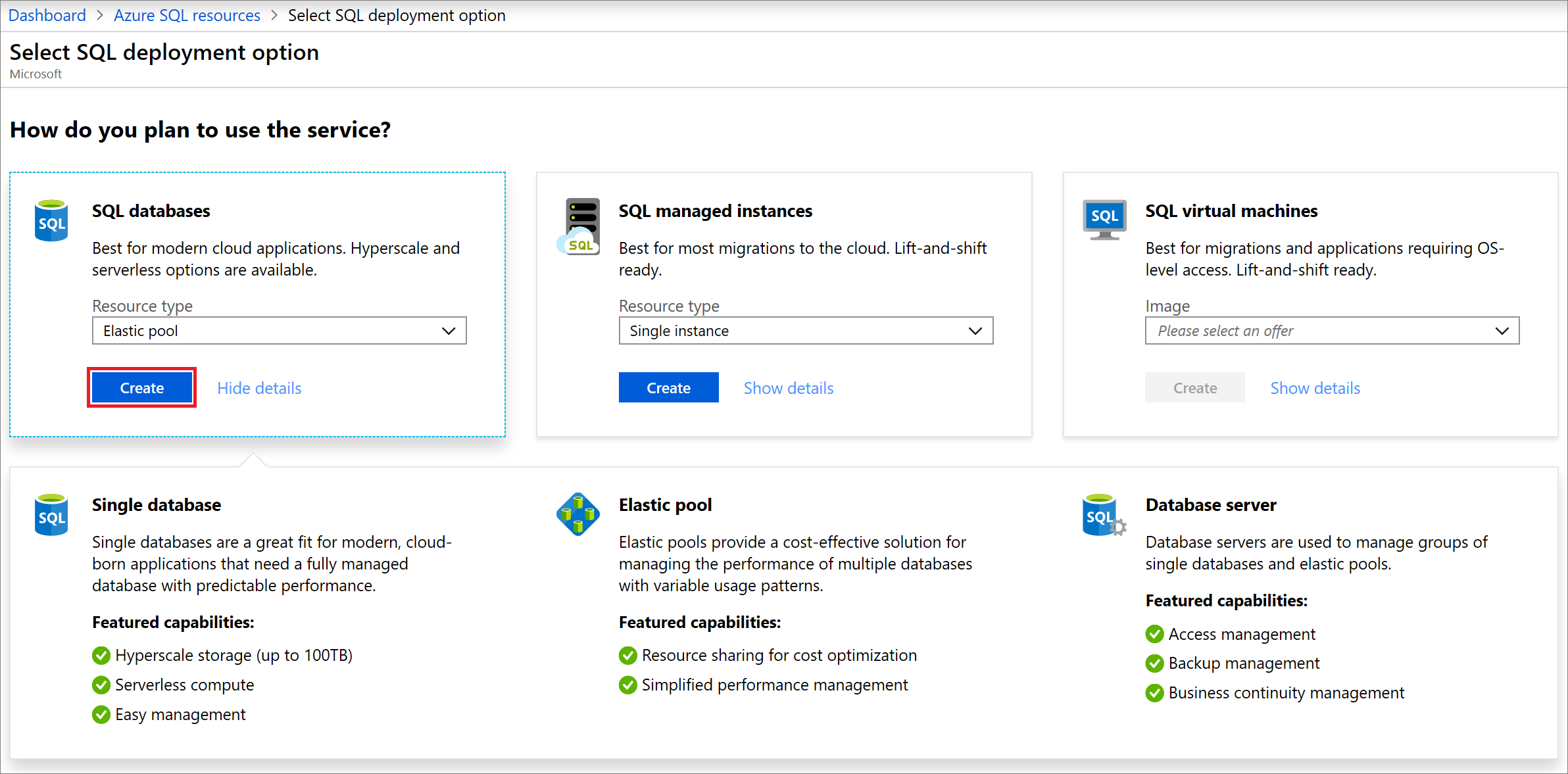
Selezionare Creare per aprire la finestra Selezionare l'opzione di distribuzione SQL. Per visualizzare altre informazioni sui pool elastici, nella finestra del Database selezionare Mostra dettagli.
Nella finestra del Database, nell'elenco a discesa del Tipo di risorsa, selezionare Pool elastico. Quindi selezionare Crea.
Quindi, Gestire il pool elastico tramite il portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure, l'API REST o T-SQL.

Per creare un pool elastico da un server esistente:
Andare su un server esistente e selezionare Nuovo pool per creare un pool direttamente in quel server.
Nota
È possibile creare più pool in un server, ma non aggiungere database da diversi server nello stesso pool.
Il livello di servizio del pool determina le funzionalità disponibili per i database elastici nel pool e la quantità massima di risorse disponibili per ogni database. Per altre informazioni, vedere i limiti delle risorse per i pool elastici nel Modello DTU. Per i limiti delle risorse basate su vCore per i pool elastici, vedere Limiti di risorse basate su vCore - pool elastici.
Per configurare le risorse e i prezzi del pool, selezionare Configura pool. Selezionare quindi un livello di servizio, aggiungere database al pool e configurare i limiti delle risorse per il pool e i relativi database.
Dopo aver configurato il pool, selezionare Applica, assegnare un nome al pool e selezionare OK per creare il pool.
Quindi, Gestire il pool elastico tramite il portale di Azure, PowerShell, l'interfaccia della riga di comando di Azure, l'API REST o T-SQL.
Monitorare un pool elastico e i relativi database
Dal portale di Azure è possibile monitorare l'uso di un pool elastico e dei database al suo interno. È anche possibile apportare un set di modifiche al pool elastico e inviare tutte le modifiche contemporaneamente. Le modifiche includono l'aggiunta o la rimozione di database, la modifica delle impostazioni del pool elastico o la modifica delle impostazioni del database.
È possibile usare gli strumenti di monitoraggio delle prestazioni e gli strumenti di avviso predefiniti combinati con le valutazioni delle prestazioni. Inoltre, Database SQL può generare log di metriche e di risorse per semplificare il monitoraggio.
Contenuto correlato
- Per informazioni sui prezzi, vedi Prezzi del pool elastico.
- Per ridimensionare i pool elastici, vedere Ridimensionamento dei pool elastici e Ridimensionare un pool elastico - codice di esempio.
- Imparare a come Gestire i pool elastici nel database SQL di Azure.
- Per altre informazioni sui modelli di progettazione per applicazioni SaaS che usano pool elastici, vedere Modelli di progettazione per applicazioni SaaS multi-tenant con database SQL.
- Per informazioni sulla gestione delle risorse nei pool elastici con molti database, vedere Gestione delle risorse nei pool elastici densi.
- Altre informazioni sui pool elastici Hyperscale.