Aumento del numero di istanze con il database SQL di Azure
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
È possibile aumentare facilmente il numero di istanze dei database SQL di Azure con gli strumenti dei database elastici. Questi strumenti e funzionalità consentono di usare le risorse di database di Database SQL di Azure per creare soluzioni per carichi di lavoro transazionali e soprattutto applicazioni SaaS (Software as a Service). Le funzionalità dei database elastici sono costituite dai seguenti elementi:
- Libreria client dei database elastici: la libreria client è una funzionalità che consente di creare e gestire i database partizionati. Vedere Iniziare a usare gli strumenti di database elastici.
- Strumento divisione-unione del database elastico: consente di spostare dati tra database partizionati. Questo strumento è utile per lo spostamento di dati da un database multi-tenant in un database single-tenant (o viceversa). Vedere Esercitazione relativa allo strumento divisione-unione del database elastico.
- Processi elastici: usare i processi per gestire un numero elevato di database SQL di Azure. Consente di eseguire facilmente operazioni amministrative, ad esempio le modifiche dello schema, la gestione delle credenziali, gli aggiornamenti dei dati di riferimento, la raccolta dei dati sulle prestazioni o la raccolta di dati di telemetria tenant (cliente) utilizzando i processi.
- Query di database elastico (anteprima): consente di eseguire una query Transact-SQL che si estende in più database. Tale query consente una connessione a strumenti di report, ad esempio Excel, Power BI, Tableau e così via.
- Transazioni di database elastico: questa funzionalità consente di eseguire transazioni estese a più database. Le transazioni di database elastico sono disponibili per le applicazioni .NET tramite ADO .NET e si integrano con i tipi di programmazione più diffusi grazie alle classi System.Transaction.
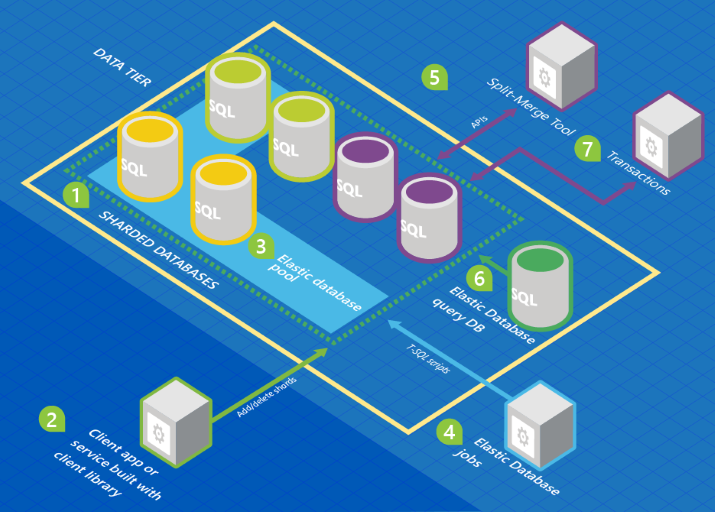
Nel grafico seguente è illustrata un'architettura che include le funzionalità dei database elastici in relazione a una raccolta di database.
In questo grafico, i colori del database rappresentano gli schemi. I database con lo stesso colore condividono gli stessi schemi.
- Un set di database SQL è ospitato in Azure tramite l'architettura di partizionamento orizzontale.
- La libreria client di database elastici viene utilizzata per gestire un set di partizioni.
- Un subset dei database viene inserito in un pool elastico. Vedere l'articolo su che cos'è un pool.
- Un processo di database elastico esegue gli script T-SQL pianificati o ad-hoc in tutti i database.
- Lo strumento di suddivisione-unione viene utilizzato per spostare i dati da una partizione a un’altra.
- La query di database elastico consente di scrivere una query che si estende a tutti i database nel set di partizioni.
- Transazioni di database elastico è una funzionalità che consente di eseguire transazioni che si estendono su più database.
Perché usare gli strumenti?
Il raggiungimento dell'elasticità e della scalabilità delle applicazioni cloud è stato semplice per le VM e l'archiviazione BLOB in quanto è bastato aggiungere o sottrarre le unità nonché aumentare la potenza. Tuttavia, resta una sfida per l’elaborazione dei dati con stato in database relazionali. Sfide emerse in questi scenari:
- Aumento e riduzione della capacità per la parte del carico di lavoro relativa al database relazionale.
- Gestione degli hotspot che potrebbero verificarsi interessando un subset specifico di dati, quali ad esempio clienti finali (tenant) impegnati.
In genere, questi scenari sono stati affrontati effettuando investimenti in server di database su scala maggiore per supportare l'applicazione. Questa opzione offre però possibilità limitate negli ambienti cloud, in cui l'intera elaborazione viene eseguita su appositi componenti hardware predefiniti. Invece, la distribuzione dei dati e l'elaborazione in molti database strutturati in modo identico (un modello di scalabilità orizzontale noto come "partizionamento orizzontale") fornisce un'alternativa agli approcci tradizionali di scalabilità verticale sia in termini di costi che di elasticità.
Scalabilità orizzontale e verticale
Nella figura seguente vengono illustrate le dimensioni orizzontali e verticali della scalabilità, che sono i metodi di base in cui possono essere ridimensionati i database elastici.
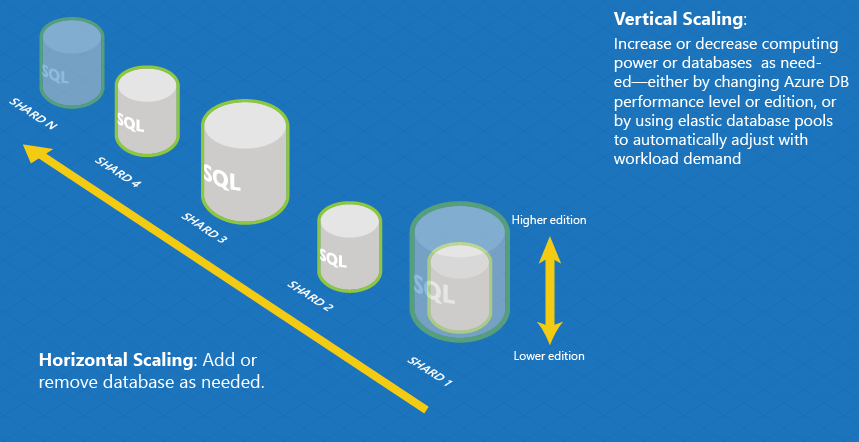
Per ridimensionamento orizzontale (o "scaling out") si intende l'aggiunta o la rimozione di database per regolare le prestazioni complessive o la capacità. Il partizionamento orizzontale, in cui i dati vengono partizionati in una raccolta di database strutturati in modo identico, è un approccio comune per implementare la scalabilità orizzontale .
Per scalabilità verticale (o "scaling up") si intende l'aumento o la riduzione delle dimensioni di calcolo di un singolo database.
La maggior parte delle applicazioni di database su scala cloud usano una combinazione di questi due strategie. Un'applicazione di Software as a Service può, ad esempio, usare il ridimensionamento per eseguire il provisioning di nuovi clienti finali e la scalabilità verticale per consentire l’espansione o la compattazione delle risorse del database di ogni cliente finale in base alle esigenze del carico di lavoro.
- La scalabilità orizzontale è gestita tramite la Libreria client di database elastici.
- La scalabilità verticale viene eseguita con i cmdlet di Azure PowerShell per modificare il livello di servizio o posizionando i database in un pool elastico.
Partizionamento orizzontale
Il partizionamento orizzontale è una tecnica per distribuire grandi quantità di dati strutturati in modo identico tra più database indipendenti. È molto usato dagli sviluppatori cloud che creano offerte Software as a Service (SAAS) per clienti finali o aziende. Questi clienti finali vengono spesso definiti "tenant". Il partizionamento orizzontale può essere necessario per vari motivi:
- La quantità totale di dati è troppo elevata per un singolo database
- La velocità effettiva delle transazioni del carico di lavoro complessivo supera le capacità di un singolo database
- Può essere necessario isolare fisicamente i tenant, quindi predisporre database separati per ogni tenant
- È possibile che sezioni diverse di un database risiedano in aree geografiche diverse per motivi di conformità, di prestazioni o geopolitici.
In altri scenari, ad esempio l'inserimento di dati da dispositivi distribuiti, il partizionamento orizzontale può essere usato per riempire un set di database organizzati secondo una logica temporale. Ad esempio, è possibile destinare un database separato a ogni giorno o settimana. In tal caso, la chiave di partizionamento orizzontale può essere un integer che rappresenta la data (presente in tutte le righe delle tabelle partizionate) e l'applicazione deve instradare le query che recuperano informazioni per un intervallo di date al subset di database che coprono l'intervallo in questione.
Il partizionamento orizzontale rappresenta la scelta ottimale quando tutte le transazioni in un'applicazione possono essere limitate a un singolo valore di una chiave di partizionamento orizzontale. Questo garantisce che tutte le transazioni saranno locali rispetto a uno specifico database.
Multi-tenant e single-tenant
Alcune applicazioni usano l'approccio più semplice di creare un database separato per ogni tenant. Questo approccio è il modello di partizionamento orizzontale per singolo tenant, che offre isolamento, funzionalità di backup e ripristino e scalabilità delle risorse in base alla granularità del tenant. Con il partizionamento orizzontale per singolo tenant, ogni database è associato a uno specifico valore di ID tenant (o valore di chiave del cliente), ma tale chiave non deve essere necessariamente presente nei dati. È responsabilità dell'applicazione instradare ogni richiesta al database appropriato e la libreria client può semplificare questa operazione.
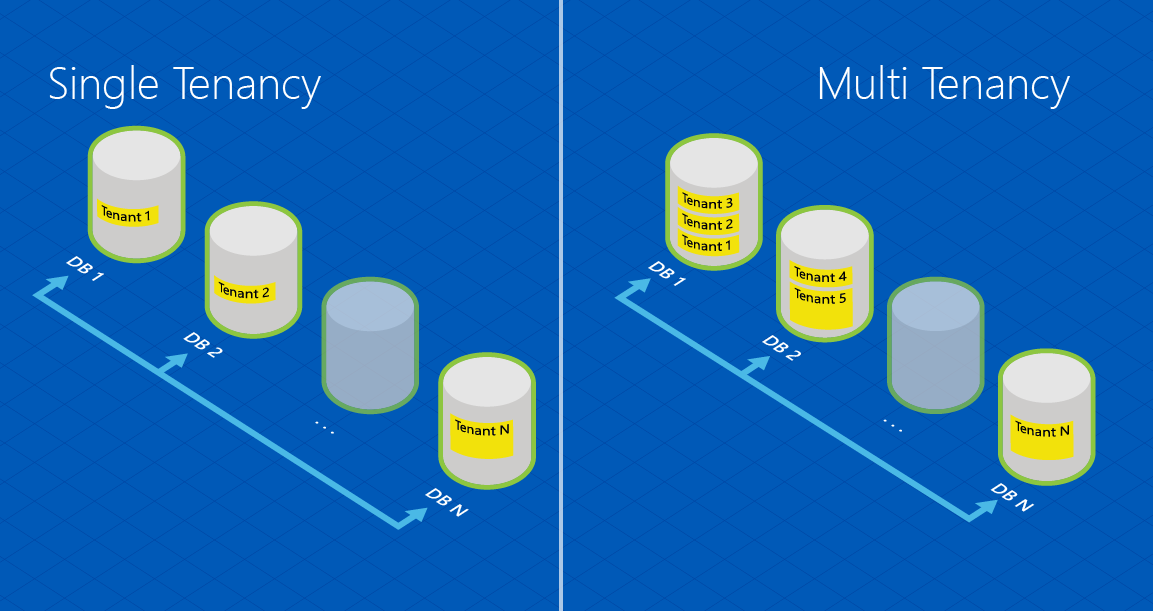
Altri scenari prevedono di riunire più tenant all'interno dei database, anziché isolarli in database separati. Si tratta di un modello di partizionamento orizzontale multi-tenant tipico e la scelta di un modello di questo tipo può essere dovuta al fatto che un'applicazione gestisce un numero elevato di tenant di dimensioni limitate. Nel partizionamento orizzontale multi-tenant, tutte le righe delle tabelle di database sono progettate per contenere una chiave che identifica l'ID tenant o una chiave di partizionamento orizzontale. Anche in questo caso, il livello applicazione è responsabile dell'instradamento delle richieste del tenant al database appropriato e questo può essere supportato dalla libreria client dei database elastici. Inoltre, la sicurezza a livello di riga può essere utilizzata per filtrare le righe a cui ogni tenant può accedere: per informazioni dettagliate, vedere Applicazioni multi-tenant con strumenti di database elastici e sicurezza a livello di riga. Con lo schema di partizionamento orizzontale multi-tenant potrebbe essere necessaria la ridistribuzione dei dati tra database e questa operazione è facilitata dallo strumento di suddivisione-unione dei database elastici. Per altre informazioni sui modelli di progettazione per applicazioni SaaS con pool elastici, vedere l'articolo relativo ai modelli di progettazione per applicazioni SaaS multi-tenant con database SQL di Azure.
Spostare i dati da database a più tenancy a database a singolo tenancy
Quando si crea un'applicazione SaaS, in genere ai clienti potenziali viene offerta una versione di valutazione del software. In questo caso, è conveniente utilizzare un database multi-tenant per i dati. Tuttavia, quando un potenziale cliente diventa un cliente reale, è consigliabile utilizzare un database single-tenant, poiché garantisce prestazioni migliori. Se il cliente ha creato dati durante il periodo di valutazione, utilizzare lo strumento di suddivisione-unione per spostare i dati dal database multi-tenant al nuovo database single-tenant.
Nota
Il ripristino da database multi-tenant a singolo tenant non è possibile.
Passaggi successivi
Per un'app di esempio che illustra la libreria client, vedere Iniziare a usare gli strumenti di database elastici.
Per convertire i database esistenti e usare gli strumenti, vedere l'articolo sulla migrazione dei database esistenti per aumentare il numero di istanze.
Per visualizzare le specifiche del pool elastico, vedere Considerazioni di prezzo e prestazioni per un pool elastico oppure creare un nuovo pool con pool elastici.
Contenuto correlato
Se non si usano gli strumenti di database elastici, vedere la Guida introduttiva. In caso di domande, usare la pagina Microsoft Q&A per il database SQL, mentre è possibile inserire le richieste di nuove funzionalità, aggiungere nuove idee o votare quelle esistenti nel forum relativo al feedback sul database SQL.