Backup automatizzati per i database Hyperscale
Si applica a: ![]() Database SQL di Azure
Database SQL di Azure
Questo articolo illustra la funzionalità di backup automatizzato con i database Hyperscale nel database SQL di Azure.
I database Hyperscale usano un'architettura unica con livelli di archiviazione e di calcolo altamente scalabili. I backup Hyperscale sono basati su snapshot e perciò sono quasi istantanei. I backup dei log vengono memorizzati nell'archiviazione di Azure a lungo termine per il periodo di conservazione dei backup.
Un'architettura Hyperscale non richiede backup completi, differenziali o dei log. Di conseguenza, la frequenza di backup, i costi di archiviazione, la pianificazione, la ridondanza dell'archiviazione e le funzionalità di ripristino differiscono da quelle degli altri database nel database SQL di Azure.
Prestazioni di backup e ripristino
La separazione tra calcolo e archiviazione consente a Hyperscale di portare le operazioni di backup e ripristino a livello di archiviazione per eliminare il consumo di risorse nelle repliche del calcolo. I backup dei database non influiscono sulle prestazioni delle repliche di calcolo primarie o secondarie.
Le operazioni di backup e ripristino per i database Hyperscale sono veloci indipendentemente dalle dimensioni dei dati, perché usano gli snapshot di archiviazione. Il backup è praticamente istantaneo.
È possibile ripristinare un database a qualsiasi punto nel tempo entro il periodo di conservazione del backup:
- Ripristinando gli snapshot dei file applicabili.
- Applicando i log delle transazioni per rendere coerente dal punto di vista transazionale il database ripristinato.
Pertanto, il ripristino non è un'operazione che comporta il ridimensionamento dei dati, che rimangono invariati. Il ripristino di un database Hyperscale nella stessa area di Azure viene completato in pochi minuti anziché in ore o giorni, anche per i database di più terabyte.
La modifica della ridondanza dell'archiviazione quando si esegue un ripristino può comportare tempi di ripristino più lunghi, poiché il ripristino corrisponde alla dimensione dei dati e quindi il tempo necessario è proporzionale alle dimensioni del database.
Anche la creazione di nuovi database, ripristinando un backup esistente o copiando il database, sfrutta la separazione delle risorse di calcolo e archiviazione in Hyperscale. È possibile creare copie di database per scopi di sviluppo o test, anche di più terabyte, in pochi minuti all'interno della stessa area se si usa lo stesso tipo di archiviazione.
Conservazione dei backup
Il tempo predefinito di conservazione dei backup a breve termine per i database Hyperscale è di 7 giorni.
La conservazione a breve termine dei backup nell'intervallo tra 1 e 35 giorni e la funzionalità di conservazione a lungo termine (LTR) dei backup per i database Hyperscale sono generalmente disponibili a partire da settembre 2023. Per ulteriori informazioni, vedere Conservazione a lungo termine - database SQL di Azure e istanza gestita di SQL di Azure.
Pianificazione del backup
Per i database Hyperscale non sono previsti i tradizionali backup dei log completi, differenziali e delle transazioni. Sono invece disponibili i normali snapshot di archiviazione dei file di dati.
I log delle transazioni generati vengono mantenuti invariati per il periodo di conservazione configurato. Al momento del ripristino, i record deli log delle transazioni pertinenti vengono applicati allo snapshot di archiviazione ripristinato. Il risultato è un database coerente dal punto di vista transazionale senza perdite di dati a partire dal punto temporale specificato entro il periodo di conservazione.
Monitoraggio del consumo di risorse dell'archivio di backup
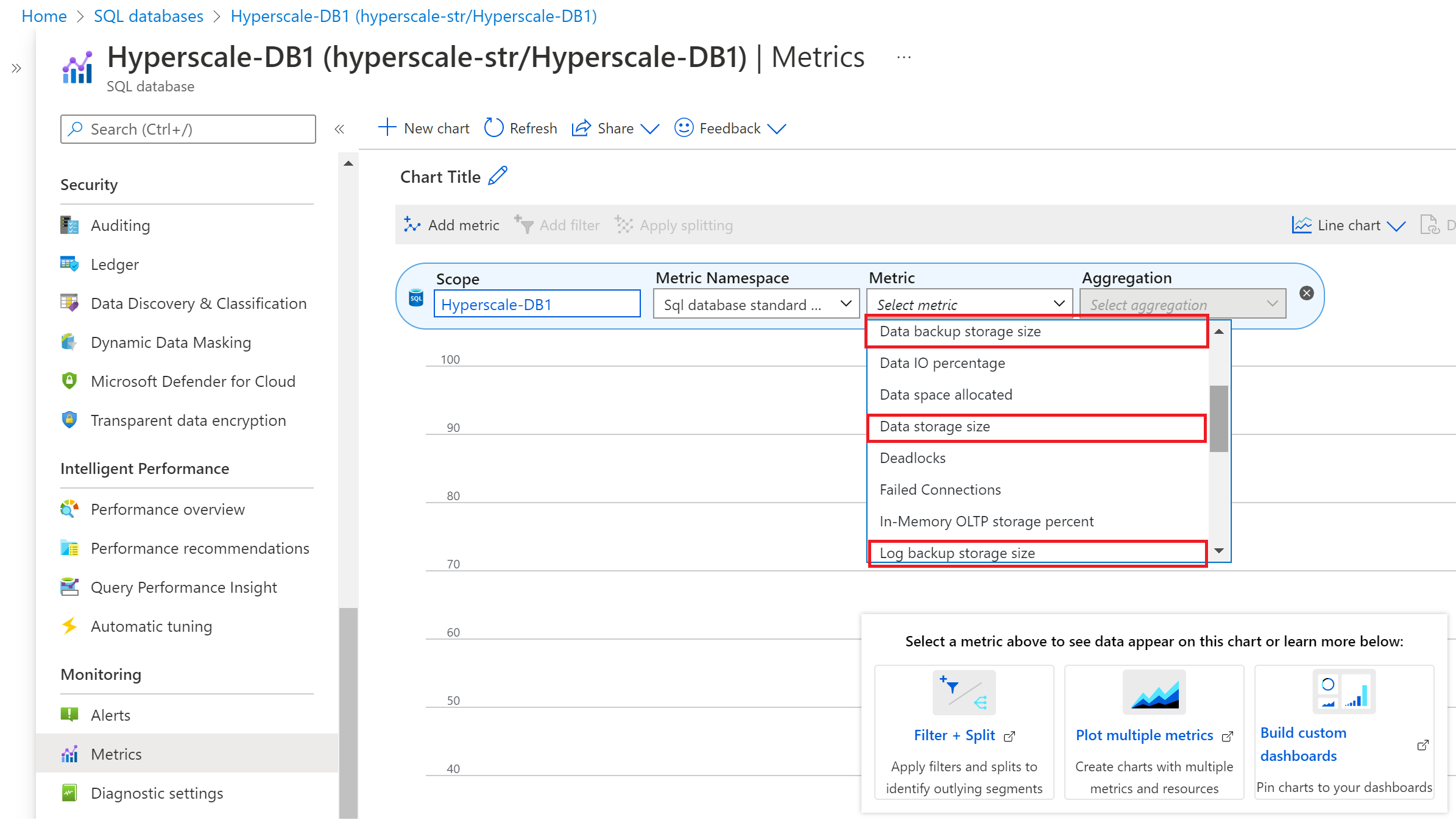
In Hyperscale, le metriche di monitoraggio di Azure riportano le seguenti informazioni sul consumo:
- Dimensioni dell'archivio di backup dei dati (dimensioni del backup dello snapshot)
- Dimensioni di archiviazione dei dati (dimensioni del database allocato)
- Dimensioni dell'archivio di backup del log (dimensioni del backup del log delle transazioni)
Per visualizzare le metriche di backup e archiviazione dei dati nel portale di Azure, procedere come segue:
- Accedere al database Hyperscale per il quale si desidera monitorare le metriche di backup e archiviazione dei dati.
- Nella sezione Monitoraggio, selezionare Metriche.
- Nell'elenco a discesa Metrica selezionare le metriche Archivio di backup dei dati, Dimensioni di archiviazione dei dati e Archivio di backup del log, con una regola di aggregazione appropriata.
Riduzione del consumo di risorse dell'archivio di backup
Il consumo di risorse dell'archivio di backup per un database Hyperscale dipende dal periodo di conservazione, dalla scelta dell'area, dalla ridondanza dell'archivio di backup e dal tipo di carico di lavoro. Prendere in considerazione alcune delle seguenti tecniche di ottimizzazione per ridurre il consumo di risorse dell'archivio di backup per un database Hyperscale:
- Ridurre il periodo di conservazione dei backup al minimo indispensabile per le proprie esigenze.
- Evitare di eseguire operazioni di scrittura di grandi dimensioni, ad esempio la manutenzione degli indici, con una frequenza superiore al necessario. Per le raccomandazioni sulla manutenzione degli indici, vedere Ottimizzare la manutenzione degli indici per migliorare le prestazioni delle query e ridurre il consumo di risorse.
- Per le operazioni di caricamento di dati di grandi dimensioni, si consiglia di usare la compressione dei dati quando opportuno.
- Usare il database
tempdbinvece delle tabelle permanenti nella logica dell'applicazione per archiviare i risultati e/o i dati temporanei. - Usare l'archivio di backup con ridondanza locale o con ridondanza della zona quando la funzionalità di ripristino geografico non è necessaria (ad esempio ambienti di sviluppo/test).
Costi di archiviazione dei backup
I costi di archiviazione dei backup Hyperscale dipendono dalla scelta dell'area e della ridondanza dell'archiviazione di backup. Dipendono anche dal tipo di carico di lavoro.
I carichi di lavoro con scrittura intensiva cambiano frequentemente con più probabilità le pagine di dati, cosa che porta a snapshot di archiviazione più grandi. Questi carichi di lavoro generano anche un maggior numero di log delle transazioni, contribuendo ai costi di backup complessivi. L'archivio di backup viene addebitato in base ai gigabyte consumati al mese. Per altre informazioni sui prezzi, consultare la pagina dei prezzi del database SQL di Azure.
Per Hyperscale, l'archivio di backup fatturabile viene calcolato come segue:
Total billable backup storage size = (data backup storage size + log backup storage size)
Le dimensioni di archiviazione dei dati non sono incluse nel backup fatturabile perché sono già state fatturate come risorsa di archiviazione del database allocato.
I database Hyperscale eliminati comportano costi di backup per supportare il ripristino a un punto nel tempo precedente l'eliminazione. Per un database Hyperscale eliminato, l'archivio di backup fatturabile viene calcolato come segue:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Le dimensioni di archiviazione dei dati sono incluse nella formula perché l'archiviazione del database allocato non viene fatturata separatamente per un database eliminato. Per un database eliminato, i dati vengono archiviati dopo l'eliminazione per consentire il ripristino durante il periodo di conservazione del backup configurato.
L'archivio di backup fatturabile per un database eliminato diminuisce gradualmente nel tempo dopo l'eliminazione. Diventa zero quando i backup non sono più conservati e il ripristino non è più possibile. Se si tratta di un'eliminazione permanente e non sono più necessari backup, è possibile ottimizzare i costi riducendo il tempo di conservazione prima di eliminare il database.
Monitoraggio dei costi di backup
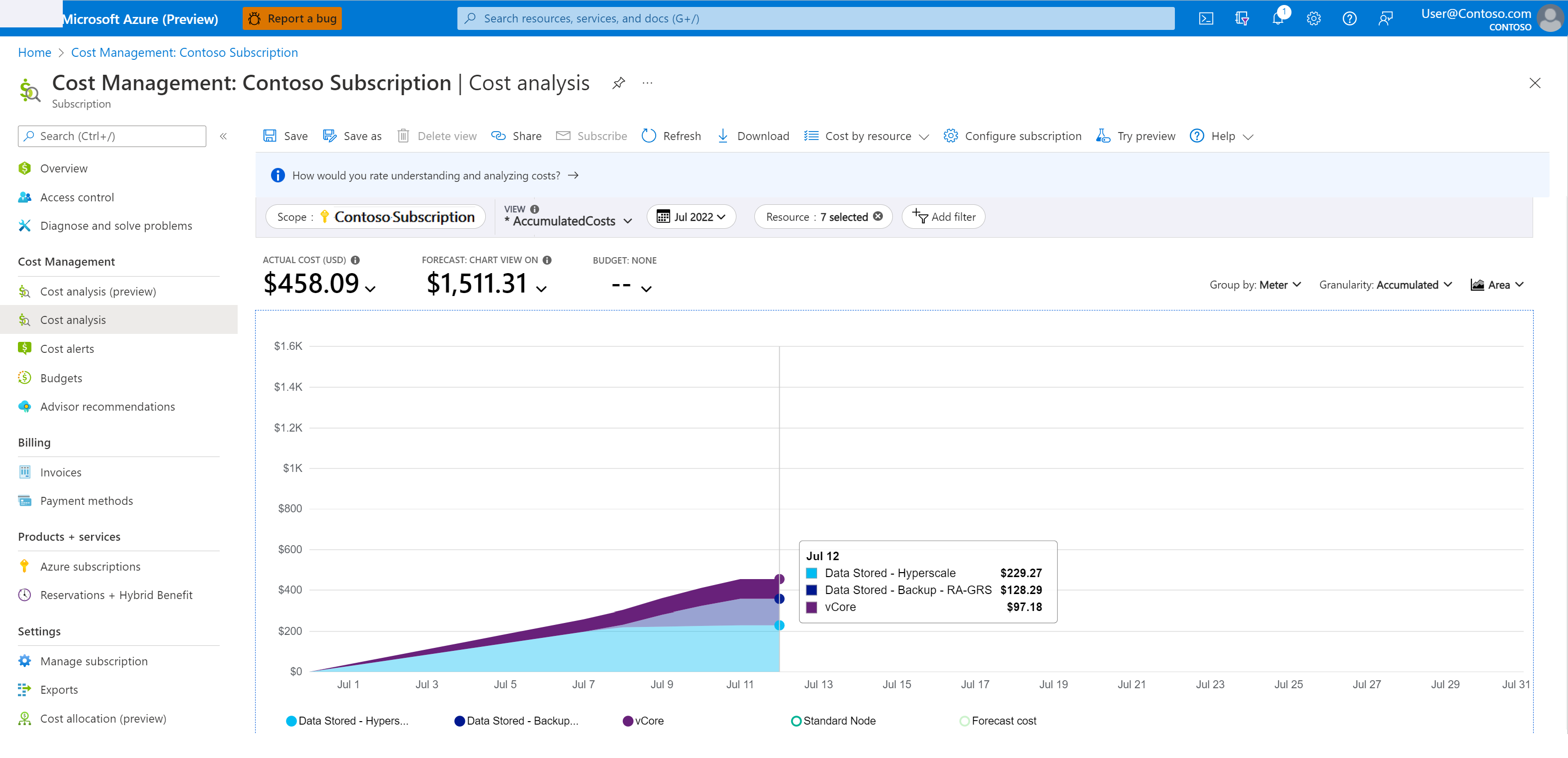
Per conoscere i costi di archiviazione dei backup:
Nel portale di Azure, passare a Gestione dei costi e fatturazione.
Selezionare Gestione dei costi>Analisi dei costi.
Come Ambito, selezionare la sottoscrizione desiderata.
Filtrare il periodo di tempo e il servizio desiderati seguendo questa procedura:
- Aggiungere un filtro per il Nome del servizio.
- Dall'elenco a discesa, scegliere sql-database.
- Aggiungere un altro filtro per il Contatore.
- Per monitorare i costi di backup per il recupero temporizzato, selezionare Dati archiviati - Backup - RA dall'elenco a discesa.
La seguente schermata mostra un esempio di analisi dei costi.
Ridondanza dell'archiviazione dei dati e dei backup
Hyperscale supporta la configurazione della ridondanza di archiviazione. Quando si crea un database Hyperscale, è possibile scegliere il tipo di archiviazione preferito: archiviazione con ridondanza geografica della zona e accesso in lettura (RA-GZRS), archiviazione con ridondanza geografica e accesso in lettura (RA-GRS), archiviazione con ridondanza della zona (ZRS) o archiviazione con ridondanza locale (LRS).
- Archiviazione con ridondanza geografica della zona: copia i backup in modo sincrono in tre zone di disponibilità di Azure nell'area primaria. simile all'archiviazione con ridondanza della zona (ZRS). Inoltre, copia i dati in modo asincrono in un'unica posizione fisica nell'area secondaria associata. Questa opzione è attualmente disponibile solo in alcune aree.
Per ulteriori informazioni sulla modalità di replica dei backup per altri tipi di archiviazione, vedere Ridondanza dell'archivio di backup.
Poiché Hyperscale usa gli snapshot di archiviazione per i backup, i dati e i backup condividono lo stesso account di archiviazione. Di conseguenza, la ridondanza dell'archivio di backup selezionata è applicabile sia ai dati che ai backup.
Nota
Valutare attentamente la ridondanza dell'archivio di backup quando si crea un database Hyperscale, perché è possibile impostarla solo in fase di creazione del database. Non è possibile modificare questa impostazione una volta avvenuto il provisioning della risorsa.
Usare la replica geografica attiva per aggiornare le impostazioni di ridondanza dell'archivio di backup per un database Hyperscale esistente con tempi di inattività minimi. In alternativa, è possibile usare la copia del database.
Avviso
- Il ripristino geografico viene disabilitato non appena un database viene aggiornato per usare l'archiviazione con ridondanza locale o con ridondanza della zona.
- L'archiviazione con ridondanza della zona è attualmente disponibile solo in alcune aree.
- L'archiviazione con ridondanza geografica della zona è attualmente disponibile solo in alcune aree.
Ripristino di un database Hyperscale in un'area diversa
Potrebbe essere necessario ripristinare il database Hyperscale in un'area diversa da quella attuale. I motivi comuni includono un'operazione o un'esercitazione di ripristino di emergenza, o una rilocazione. Il metodo principale consiste nell'eseguire un ripristino geografico del database. Si seguono gli stessi passaggi che si seguirebbero per ripristinare qualsiasi altro database nel database SQL di Azure in un'area diversa:
- Creare un server nell'area di destinazione, se non è già presente un server idoneo. Questo server dev'essere di proprietà della stessa sottoscrizione del server originale (di origine).
- Seguire le istruzioni nella sezione ripristino geografico della pagina sul ripristino di un database nel database SQL di Azure da backup automatici.
Nota
Poiché l'origine e la destinazione si trovano in aree separate, il database non può condividere l'archiviazione snapshot con il database di origine, come avviene nei ripristini non geografici. I ripristini non geografici terminano rapidamente, indipendentemente dalle dimensioni del database.
Il ripristino geografico di un database Hyperscale è un'operazione che comporta il ridimensionamento dei dati, anche se la destinazione si trova nell'area associata dell'archiviazione con replica geografica. Dunque un ripristino geografico richiederà molto più tempo rispetto a un ripristino temporizzato nella stessa area.
Se la destinazione si trova nell'area associata, il trasferimento dei dati avverrà all'interno di una stessa area. Tale trasferimento sarà notevolmente più veloce rispetto a un trasferimento di dati tra aree diverse. Tuttavia, si tratterà comunque di un'operazione che comporta il ridimensionamento dei dati.
Se si preferisce, si può copiare il database in un'area diversa. Usare questo metodo se il ripristino geografico non è disponibile perché non è supportato con il tipo di ridondanza di archiviazione selezionato. Per informazioni dettagliate, consultare Copia del database per Hyperscale.
Contenuto correlato
I backup dei database sono una parte essenziale di qualsiasi strategia di continuità aziendale e ripristino di emergenza, poiché aiutano a proteggere i dati dal danneggiamento o dall'eliminazione accidentale.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per