Livello di calcolo serverless per il database SQL di Azure
Si applica a: ![]() database SQL di Azure
database SQL di Azure
Il livello serverless è un livello di calcolo per database singoli in Database SQL di Azure che ridimensiona automaticamente il calcolo in base alle esigenze dei carichi di lavoro, addebitando la quantità di calcolo usata al secondo. Il livello di calcolo serverless inoltre sospende automaticamente i database durante i periodi di inattività, in cui viene addebitata solo l'archiviazione, e li riprende automaticamente quando necessario. Il livello di elaborazione serverless è disponibile nel livello di servizio per utilizzo generico e nel livello di servizio Hyperscale.
Nota
La sospensione automatica e il riavvio automatico sono attualmente supportati solo nel livello di servizio per utilizzo generico.
Panoramica
Un intervallo di scalabilità di calcolo automatica e un ritardo di sospensione automatica sono parametri importanti per il livello di elaborazione serverless. La configurazione di questi parametri determina l'esperienza a livello di prestazioni e i costi di calcolo del database.
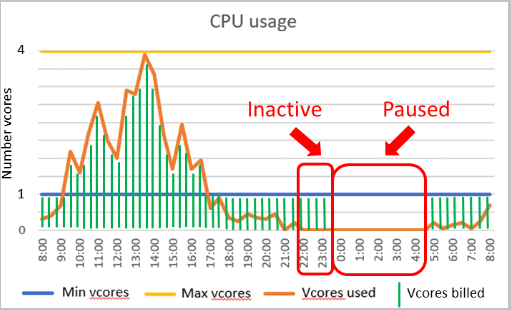
Configurazione delle prestazioni
- Il numero minimo di vCore e il numero massimo di vCore sono i parametri configurabili che definiscono l'intervallo della capacità di calcolo disponibile per il database. I limiti di memoria e I/O sono proporzionali all'intervallo vCore specificato.
- Il ritardo di sospensione automatica è un parametro configurabile che definisce il periodo di tempo per cui il database deve rimanere inattivo prima che venga sospeso automaticamente. Il database viene ripristinato automaticamente in seguito all'accesso successivo o quando si verificano altre attività. In alternativa, è possibile disabilitare la sospensione automatica.
Costo
- Il costo di un database serverless corrisponde alla somma del costo per le risorse di calcolo e del costo per le risorse di archiviazione.
- Quando l'uso delle risorse di calcolo è compreso tra i limiti minimo e massimo configurati, il costo di calcolo è basato sui vCore e sulla memoria usati.
- Quando l'uso delle risorse di calcolo è inferiore ai limiti minimi configurati, il costo per le risorse di calcolo è basato sul numero minimo di vCore e sulla memoria minima configurata.
- Quando il database è sospeso, il costo per le risorse di calcolo è pari a zero e vengono addebitati solo i costi per le risorse di archiviazione.
- Il costo per le risorse di archiviazione è determinato come nel livello di calcolo con provisioning.
Per informazioni più dettagliate sui costi, vedere Fatturazione.
Scenari
Il modello serverless è caratterizzato da un rapporto qualità-prezzo ottimizzato per database singoli con modelli di utilizzo intermittenti e imprevedibili che possono permettersi qualche ritardo all'avvio del calcolo dopo periodi di inattività. Al contrario, il livello di calcolo con provisioning è caratterizzato da un rapporto prezzo-prestazioni ottimizzato per database singoli o per più database in pool elastici con un utilizzo medio più elevato che non possono tollerare ritardi nella fase di avvio del calcolo.
Scenari particolarmente adatti per l’elaborazione serverless
- Database singoli con modelli di utilizzo intermittenti e imprevedibili intercalati con periodi di inattività e minore utilizzo medio del calcolo nel corso del tempo.
- Database singoli nel livello di calcolo con provisioning che vengono spesso ridimensionati e clienti che preferiscono delegare il ridimensionamento del calcolo al servizio.
- Nuovi database singoli senza cronologia di utilizzo in cui il dimensionamento di calcolo è difficile o impossibile da stimare prima della distribuzione nel database SQL di Azure.
Scenari particolarmente adatti per il calcolo con provisioning
- Database singoli con modelli d'uso più regolari e prevedibili e un superiore utilizzo medio del calcolo nel corso del tempo.
- Database che non possono tollerare compromessi delle prestazioni dovuti a blocchi di memoria più frequenti o ritardi nel riavvio automatico da uno stato in pausa.
- Più database con modelli d'uso intermittenti e imprevedibili che possono essere consolidati in pool elastici per una migliore ottimizzazione del rapporto prezzo-prestazioni.
Confrontare i livelli di calcolo
La tabella seguente riepiloga le differenze tra il livello di calcolo serverless e il livello di calcolo con provisioning:
| Calcolo serverless | Calcolo con provisioning | |
|---|---|---|
| Modello d'uso del database | Uso intermittente e imprevedibile, con un minore utilizzo medio del calcolo nel corso del tempo. | Modelli d'uso più regolari, con un superiore utilizzo medio del calcolo nel corso del tempo o più database con pool elastici. |
| Impegno per la gestione delle prestazioni | Lower | Maggiore |
| Ridimensionamento delle risorse di calcolo | Automatico | Manuale |
| Tempo di risposta per le risorse di calcolo | Inferiore dopo periodi di inattività | Immediate |
| Granularità della fatturazione | Al secondo | All'ora |
Modello di acquisto e livello di servizio
La tabella seguente descrive il supporto serverless in base al modello di acquisto, ai livelli di servizio e all'hardware:
| Categoria | Supportata | Non supportato |
|---|---|---|
| Modello di acquisto | vCore | DTU |
| Livello di servizio | Utilizzo generico Hyperscale |
Business Critical |
| Hardware | Serie standard (Gen5) | Tutto l’hardware restante |
Scalabilità automatica
Tempo di risposta per il ridimensionamento
In generale, i database serverless vengono eseguiti in un computer con capacità sufficiente a soddisfare la richiesta di risorse senza interruzioni per qualsiasi quantità di risorse di calcolo richiesta entro i limiti fissati dal valore per il numero massimo di vCore. Di tanto in tanto, viene eseguito automaticamente il bilanciamento del carico se il computer non è in grado di soddisfare la richiesta di risorse entro pochi minuti. Se ad esempio la richiesta di risorse è di 4 vCore, ma sono disponibili solo 2 vCore, potrebbero essere necessari alcuni minuti per il bilanciamento del carico prima che vengano forniti 4 vCore. Durante il bilanciamento del carico il database rimane online ad eccezione di un breve periodo al termine dell'operazione, quando vengono rilasciate le connessioni.
Gestione della memoria
Nei livelli di servizio per utilizzo generico e Hyperscale, la memoria per i database serverless viene recuperata più frequentemente rispetto ai database di calcolo con provisioning. Questo comportamento è importante per controllare i costi nei database serverless e può influire sulle prestazioni.
Recupero della cache
A differenza dei database di calcolo con provisioning, la memoria della cache SQL viene recuperata da un database serverless quando l'uso della CPU o della cache attiva è basso.
- L'uso della cache attiva è considerato basso quando la dimensione totale delle voci della cache usate di recente scende al di sotto di una soglia per un periodo di tempo.
- Quando viene attivato il recupero della cache, le dimensioni della cache di destinazione vengono ridotte in modo incrementale a una frazione della dimensione precedente e il recupero continua solo se l'uso rimane basso.
- Quando viene eseguito il recupero della cache, i criteri per la selezione delle voci della cache da rimuovere sono gli stessi criteri di selezione applicati per i database di calcolo con provisioning quando l'uso della memoria è elevato.
- Le dimensioni della cache non vengono mai ridotte al di sotto del limite di memoria minimo, definito dal numero minimo di vCore.
Sia nei database di calcolo serverless che in quelli con provisioning, le voci della cache possono essere rimosse se viene usata tutta la memoria disponibile.
Quando l'utilizzo della CPU è basso, l'utilizzo della cache attiva può rimanere elevato a seconda del criterio di utilizzo e impedire il recupero della memoria. Inoltre, possono verificarsi altri ritardi dopo che l'attività dell'utente si arresta prima che si verifichi il recupero della memoria a causa di processi in background periodici che rispondono alle attività precedenti dell'utente. Ad esempio, le operazioni di eliminazione e i task di pulizia di Query Store generano record fantasma contrassegnati per l'eliminazione, ma non vengono eliminati fisicamente fino all'esecuzione del processo di pulizia fantasma. La pulizia fantasma potrebbe comportare la lettura delle pagine di dati nella cache.
Idratazione della cache
La cache SQL aumenta man mano che i dati vengono recuperati dal disco nello stesso modo e con la stessa velocità dei database con provisioning. Quando il database è occupato, la cache può aumentare senza vincoli fino al limite massimo di memoria disponibile.
Gestione della cache del disco
Nel livello di servizio Hyperscale per i livelli di elaborazione serverless e con provisioning, ogni replica di calcolo usa una cache di estensione del pool di buffer resiliente (RBPEX), che archivia le pagine di dati nell'unità SSD locale per migliorare le prestazioni di I/O. Tuttavia, nel livello di elaborazione serverless per Hyperscale, la cache RBPEX per ogni replica di calcolo aumenta e si compatta automaticamente in risposta all'aumento e alla riduzione della domanda del carico di lavoro. Le dimensioni massime della cache RBPEX possono aumentare fino a tre volte la memoria massima configurata per il database. Per dettagli sui limiti massimi di memoria e ridimensionamento automatico di RBPEX in serverless, vedi Limiti delle risorse Hyperscale serverless.
Sospensione automatica e ripresa automatica
Attualmente, la sospensione automatica serverless e la ripresa automatica sono supportate solo nel livello per utilizzo generico.
Sospensione automatica
La sospensione automatica viene attivata in presenza di tutte le condizioni seguenti per la durata del ritardo della sospensione automatica:
- Numero di sessioni = 0
- CPU = 0 per il carico di lavoro utente in esecuzione nel pool di risorse
Se lo si desidera, è disponibile un'opzione per disabilitare la sospensione automatica.
Le seguenti caratteristiche non supportano la sospensione automatica, ma supportano il ridimensionamento automatico. Se quindi si usa una delle caratteristiche seguenti, la sospesione automatica deve essere disabilitata e il database rimane online indipendentemente dall'intervallo di inattività del database:
- Replica geografica (replica geografica attiva e gruppi di failover).
- Conservazione backup a lungo termine (LTR).
- Il database di sincronizzazione utilizzato in sincronizzazione dati SQL. A differenza dei database di sincronizzazione, i database hub e i database membri supportano la sospensione automatica.
- Alias DNS creato per il server logico contenente un database serverless.
- Processi elastici, il database serverless abilitato per la sospensione automatica non è supportato come database del processo. I database serverless destinati ai lavori elastici supportano la sospensione automatica. I collegamenti di lavoro riavviano un database.
La sospensione automatica viene temporaneamente impedita durante la distribuzione di alcuni aggiornamenti dei servizi che richiedono che il database sia online. In questi casi, la sospensione automatica diventa nuovamente consentita al termine dell'aggiornamento del servizio.
Risoluzione dei problemi di sospensione automatica
Se la sospensione automatica è abilitata e le funzionalità che bloccano la sospensione automatica non vengono usate, ma un database non viene sospeso automaticamente dopo il periodo di ritardo, l'applicazione o le sessioni utente potrebbero impedire la sospensione automatica.
Per verificare se sono presenti sessioni utente o applicazioni attualmente connesse al database, connettersi al database usando uno strumento client ed eseguire la query seguente:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Suggerimento
Dopo aver eseguito la query, accertati di disconnetterti dal database. In caso contrario, la sessione aperta usata dalla query impedirà la sospensione automatica.
- Se il set di risultati non è vuoto, significa che sono presenti sessioni che attualmente impediscono la sospensione automatica.
- Se il set di risultati è vuoto, è comunque possibile che le sessioni fossero aperte, forse per un breve periodo di tempo, in un momento precedente durante il periodo di ritardo della sospensione automatica. Per verificare se tale attività è avvenuta durante il periodo di ritardo, puoi usare il controllo di Azure SQL ed esaminare i dati di controllo per il periodo pertinente.
Importante
La presenza di sessioni aperte, con o senza utilizzo simultaneo della CPU nel pool di risorse utente, è il motivo più comune per cui un database serverless non viene sospeso automaticamente come previsto.
Ripresa automatica
La ripresa automatica viene attivata in presenza di una qualsiasi delle condizioni seguenti in un qualsiasi momento:
| Funzionalità | Grilletto di ripresa automatica |
|---|---|
| Autenticazione e autorizzazione | Accedi |
| Rilevamento delle minacce | Abilitazione/disabilitazione delle impostazioni di rilevamento delle minacce a livello di database o server. Modifica delle impostazioni di rilevamento delle minacce a livello di database o server. |
| Individuazione e classificazione dei dati | Aggiunta, modifica, eliminazione o visualizzazione delle etichette di riservatezza |
| Controllo | Visualizzazione dei record di controllo Aggiornamento o visualizzazione di criteri di controllo. |
| Maschera dati | Aggiunta, modifica, eliminazione o visualizzazione delle regole di maschera dati |
| Transparent Data Encryption | Stato di visualizzazione o stato di Transparent Data Encryption |
| Valutazione della vulnerabilità | Analisi ad hoc e analisi periodiche, se abilitate |
| Esecuzione di query sulle prestazioni dell'archivio dati | Modifica o visualizzazione delle impostazioni dell'archivio dati |
| Consigli sulle prestazioni | Visualizzazione o applicazione di consigli sulle prestazioni |
| Ottimizzazione automatica | Applicazione e verifica dei consigli per l'ottimizzazione automatica, ad esempio l'indicizzazione automatica |
| Copia del database | Creazione del database come copia. Esportazione in un file BACPAC. |
| Sincronizzazione dati SQL | Sincronizzazione tra database hub e membro che viene eseguita secondo un calendario configurabile o manualmente |
| Modifica di alcuni metadati del database | Aggiunta di nuovi tag del database. Modifica del numero massimo di vCore, del numero minimo di vCore o ritardo di sospensione automatica. |
| SQL Server Management Studio (SSMS) | Se si usano le versioni di SSMS precedenti alla 18.1 e si apre un nuovo intervallo di query per un qualsiasi database nel server, verranno ripresi tutti i database sospesi automaticamente nello stesso server. Questo comportamento non si verifica se si usa SSMS 18.1 o versione successiva. |
Il monitoraggio, la gestione o altre soluzioni che eseguono una delle operazioni elencate in precedenza attiveranno la ripresa automatica. La ripresa automatica viene attivata anche durante la distribuzione di alcuni aggiornamenti dei servizi che richiedono che il database sia online.
Connettività
Se un database serverless è in pausa, verrà ripreso al primo tentativo di connessione. Verrà inoltre restituito un errore con codice errore 40613 che indica che il database non è disponibile. Dopo la ripresa del database sarà necessario ripetere l'accesso per stabilire la connettività. I client del database con i seguenti consigli sulla logica di ripetizione dei tentativi di connessione non devono essere modificati. Per le opzioni e i consigli relativi alla logica di ripetizione dei tentativi di connessione, vedere:
- Logica di ripetizione dei tentativi di connessione in SqlClient
- Logica di ripetizione dei tentativi di connessione in database SQL con Entity Framework Core
- Logica di ripetizione dei tentativi di connessione in database SQL con Entity Framework 6
- Logica di ripetizione dei tentativi di connessione in database SQL tramite ADO.NET
Latenza
La latenza per riprendere e sospendere automaticamente un database serverless è in genere di circa un minuto per la ripresa automatica e di 1-10 minuti dopo la scadenza del periodo di ritardo per la sospensione automatica.
Transparent Data Encryption gestita dal cliente (BYOK)
Eliminazione o revoca della chiave
Se si usa Transparent Data Encryption gestita dal cliente (BYOK) e il database serverless viene sospeso automaticamente quando si verifica l'eliminazione o la revoca della chiave, il database rimane nello stato di sospensione automatica. In questo caso, dopo la successiva ripresa del database, il database diventa inaccessibile entro circa 10 minuti. Quando il database diventa inaccessibile, il processo di ripristino è identico a quello per i database di calcolo con provisioning. Se il database serverless è online quando si verifica l'eliminazione o la revoca della chiave, il database diventa inaccessibile entro circa 10 minuti, come nel caso dei database di calcolo con provisioning.
Rotazione delle chiavi
Se si usa transparent data encryption gestito dal cliente (BYOK) e la sospensione automatica serverless è abilitata, il database viene ripreso automaticamente ogni volta che le chiavi vengono ruotate e successivamente sospese automaticamente quando vengono soddisfatte condizioni di sospensione automatica.
Creare un nuovo database serverless
La procedura di creazione di un nuovo database o di spostamento di un database esistente in un livello di calcolo serverless è analoga a quella di creazione di un nuovo database nel livello di calcolo con provisioning e prevede i due passaggi seguenti:
Specificare l'obiettivo di servizio. L'oggetto assistenza descrive il livello di servizio, la configurazione dell'hardware e il numero massimo di vCore. Per le opzioni degli oggetti assistenza, vedi Limiti delle risorse serverless
Facoltativamente, specifica il numero minimo di vCore e il ritardo di sospensione automatica per modificarne i valori predefiniti. La tabella seguente illustra i valori disponibili per questi parametri.
Parametro Valori disponibili Default value Numero minimo di vCore Dipende dal numero massimo di vCore configurati. Vedi Limiti delle risorse. 0,5 vCore Ritardo di sospensione automatica Minimo: 15 minuti
Massimo: 10.080 minuti (7 giorni)
Incrementi: 1 minuto
Disabilita la sospensione automatica: -160 minuti
Negli esempi seguenti viene creato un nuovo database nel livello di calcolo serverless.
Usare il portale di Azure
Vedi Avvio rapido: creare un database singolo nel database SQL di Azure usando il portale di Azure.
Utilizzare PowerShell
Crea un nuovo database per utilizzo generico serverless con l'esempio di PowerShell seguente:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Utilizzare l'interfaccia della riga di comando di Azure
Crea un nuovo database per utilizzo generico serverless con l'esempio seguente dell'interfaccia della riga di comando di Azure:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Usare Transact-SQL (T-SQL)
Quando si usa T-SQL per creare un nuovo database serverless, i valori predefiniti vengono applicati per il numero minimo di vCore e il ritardo di sospensione automatica. I valori possono essere successivamente modificati dal portale di Azure o tramite API, tra cui PowerShell, l'interfaccia della riga di comando di Azure e REST.
Per informazioni dettagliate, vedere CREATE DATABASE.
Crea un nuovo database serverless per utilizzo generico con l'esempio T-SQL seguente:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Spostare un database tra livelli di calcolo o i livello di servizio
È possibile spostare un database tra il livello di calcolo con provisioning e il livello di calcolo serverless.
Un database serverless può anche essere spostato dal livello di servizio Utilizzo generico al livello di servizio Hyperscale. Per altre informazioni, vedi Gestire i database Hyperscale.
Quando si sposta un database tra livelli di calcolo, specificare il parametro del modello di calcolo come Serverless o Provisioned quando si usa PowerShell o l'interfaccia della riga di comando di Azure, o il SERVICE_OBJECTIVE quando si usa T-SQL. Esaminare i limiti delle risorse per identificare l'obiettivo di servizio appropriato.
Negli esempi seguenti un database esistente viene spostato dal calcolo con provisioning al serverless.
Utilizzare PowerShell
Sposta un database per utilizzo generico di calcolo con provisioning nel livello di elaborazione serverless con l'esempio di PowerShell seguente:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Utilizzare l'interfaccia della riga di comando di Azure
Sposta un database per utilizzo generico di calcolo con provisioning nel livello di elaborazione serverless con l'esempio seguente dell'interfaccia della riga di comando di Azure:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Usare Transact-SQL (T-SQL)
Quando si usa T-SQL per spostare un database tra livelli di calcolo, i valori predefiniti vengono applicati per il numero minimo di vCore e il ritardo di sospensione automatica. I valori possono essere successivamente modificati dal portale di Azure o tramite API, tra cui PowerShell, l'interfaccia della riga di comando di Azure e REST. Per altre informazioni, vedere ALTER DATABASE.
Sposta un database per utilizzo generale di calcolo con provisioning al livello di elaborazione serverless. con il seguente esempio T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Modifica della configurazione serverless
Utilizzare PowerShell
Usa Set-AzSqlDatabase per modificare il numero massimo o minimo di vCore e il ritardo di sospensione automatica. Usa gli argomenti MaxVcore, MinVcore e AutoPauseDelayInMinutes. La sospensione automatica serverless non è attualmente supportata nel livello Hyperscale, quindi l'argomento ritardo di sospensione automatica è applicabile solo al livello per utilizzo generico.
Utilizzare l'interfaccia della riga di comando di Azure
Usa az sql db update per modificare il numero massimo o minimo di vCore e il ritardo di sospensione automatica. Usa gli argomenti capacity, min-capacity e auto-pause-delay. La sospensione automatica serverless non è attualmente supportata nel livello Hyperscale, quindi l'argomento ritardo di sospensione automatica è applicabile solo al livello per utilizzo generico.
Monitoraggio
Risorse usate e fatturate
Le risorse di un database serverless includono le entità per il pacchetto dell'app, l'istanza di SQL e il pool di risorse utente.
Pacchetto dell'app
Il pacchetto app è il limite più esterno di gestione delle risorse per un database, indipendentemente dal fatto che il database si trovi in un livello di calcolo serverless o con provisioning. Il pacchetto dell'app contiene i servizi esterni e l'istanza di SQL, come ricerca full-text, che definiscono congiuntamente l'ambito di tutte le risorse utente e di sistema usate da un database nel database SQL. L'istanza di SQL è in genere la voce più onerosa nell'utilizzo complessivo delle risorse nel pacchetto dell'app.
Pool di risorse utente
Il pool di risorse utente è il limite più interno di gestione delle risorse per un database, indipendentemente dal fatto che il database si trovi in un livello di elaborazione serverless o con provisioning. Il pool di risorse utente definisce l'ambito della CPU e dell'I/O per il carico di lavoro utente generato da query DDL (CREATE e ALTER) e DML (INSERT, UPDATE, DELETE, MERGE e SELECT). Queste domande rappresentano in genere la percentuale più consistente di utilizzo all'interno del pacchetto dell'app.
Metrica
La tabella seguente include le metriche per il monitoraggio dell'uso della risorsa del pacchetto dell'app e del pool di risorse utente di un database serverless, tra cui le repliche geografiche:
| Entità | Metrico | Descrizione | Unità |
|---|---|---|---|
| Pacchetto dell'app | app_cpu_percent | Percentuale di vCore usati dall'app rispetto al numero massimo di vCore consentito per l'app. Per Hyperscale serverless, questa metrica viene esposta per tutte le repliche primarie, le repliche denominate e le repliche geografiche. | Percentuale |
| Pacchetto dell'app | app_cpu_billed | Quantità di risorse di calcolo fatturata per l'app durante il periodo di riferimento. L'importo pagato durante questo periodo è dato dal prodotto di questa metrica per il prezzo unitario dei vCore. I valori di questa metrica sono determinati dall'aggregazione del numero massimo di CPU usate e dalla memoria usata al secondo. Se la quantità usata è inferiore a quella minima di cui è stato effettuato il provisioning in base al numero minimo di vCore e alla quantità minima di memoria, viene fatturata la quantità minima con provisioning. Per confrontare la quantità di CPU e di memoria ai fini della fatturazione, la memoria viene normalizzata in unità di vCore ridimensionando la quantità di memoria in GB in base a 3 GB per vCore. Per Hyperscale serverless, questa metrica viene esposta per la replica primaria ed eventuali repliche denominate. |
Secondi per vCore |
| Pacchetto dell'app | app_cpu_billed_HA_replicas | Applicabile solo a Hyperscale serverless. Somma dell’ambiente di calcolo fatturato in tutte le app per le repliche a disponibilità elevata durante il periodo di riferimento. Questa somma ha come ambito le repliche a disponibilità elevata appartenenti alla replica primaria o alle repliche a disponibilità elevata appartenenti a una determinata replica denominata. Prima di calcolare questa somma tra le repliche a disponibilità elevata, la quantità di calcolo fatturata per una singola replica a disponibilità elevata viene determinata allo stesso modo della replica primaria o di una replica denominata. Per Hyperscale serverless, questa metrica viene esposta per tutte le repliche primarie, le repliche denominate e le repliche geografiche. L'importo pagato durante questo periodo di riferimento è il prodotto di questa metrica per il prezzo unitario dei vCore. | Secondi per vCore |
| Pacchetto dell'app | app_memory_percent | Percentuale di memoria usata dall'app rispetto alla memoria massima consentita per l'app. Per Hyperscale serverless, questa metrica viene esposta per tutte le repliche primarie, le repliche denominate e le repliche geografiche. | Percentuale |
| Pool di risorse utente | cpu_percent | Percentuale di vCore usati dal carico di lavoro utente rispetto al numero massimo di vCore consentiti per il carico di lavoro utente. | Percentuale |
| Pool di risorse utente | data_IO_percent | Percentuale di operazioni di I/O al secondo sui dati usate dal carico di lavoro utente rispetto al numero massimo di operazioni di I/O al secondo sui dati consentite per il carico di lavoro utente. | Percentuale |
| Pool di risorse utente | log_IO_percent | Percentuale di MB/s di log usati dal carico di lavoro utente rispetto al numero massimo di MB/s di log consentiti per il carico di lavoro utente. | Percentuale |
| Pool di risorse utente | workers_percent | Percentuale di ruoli di lavoro usati dal carico di lavoro utente rispetto al numero massimo di ruoli di lavoro consentiti per il carico di lavoro utente. | Percentuale |
| Pool di risorse utente | sessions_percent | Percentuale di sessioni usate dal carico di lavoro utente rispetto al numero massimo di sessioni consentite per il carico di lavoro utente. | Percentuale |
Stato di sospensione e ripresa
Nel caso di un database serverless con sospensione automatica abilitata, lo stato segnalato include i valori seguenti:
| Stato | Descrizione |
|---|---|
| Online | Il database è online. |
| Sospensione in corso | Il database passa da online a sospeso. |
| In pausa | Il database è sospeso. |
| Ripresa in corso | Il database sta passando da sospeso a online. |
Usare il portale di Azure
Nel portale di Azure lo stato del database è visualizzato nella pagina di panoramica del database e nella pagina di panoramica del relativo server. Inoltre, nella portale di Azure, la cronologia degli eventi di sospensione e ripresa di un database serverless può essere visualizzata nel log attività.
Utilizzare PowerShell
È possibile visualizzare le impostazioni correnti usando l'esempio di PowerShell seguente:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Utilizzare l'interfaccia della riga di comando di Azure
Visualizzare lo stato corrente del database usando l'esempio seguente dell'interfaccia della riga di comando di Azure:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Limiti delle risorse
Per i limiti delle risorse, vedere Livello di calcolo serverless.
Fatturazione
La quantità di ambiente di calcolo fatturata per un database serverless corrisponde alla quantità massima di CPU e di memoria usata ogni secondo. Se la quantità di CPU e di memoria usata è inferiore alla quantità minima del provisioning per ciascuna risorsa, viene fatturata la quantità del provisioning. Per confrontare la quantità di CPU e di memoria ai fini della fatturazione, la memoria viene normalizzata in unità di vCore ridimensionando il numero di GB a 3 GB per vCore.
- Risorsa fatturata: CPU e memoria
- Importo fatturato: prezzo unitario vCore * massimo (numero minimo di vCore, numero di vCore usati, quantità minima di memoria in GB * 1/3, quantità di memoria in GB usata * 1/3)
- Frequenza di fatturazione: al secondo
Il prezzo unitario vCore è il costo per vCore al secondo.
Per i prezzi unitari in una determinata area, vedere la pagina dei prezzi del database SQL di Azure.
La quantità di ambiente di calcolo fatturata in serverless per un database per utilizzo generico o una replica primaria o denominata Hyperscale viene esposta dalla metrica seguente:
- Metrica: app_cpu_billed (secondi per vCore)
- Definizione: massimo (numero minimo di vCore, numero di vCore usati, quantità minima di memoria in GB * 1/3, quantità di memoria in GB usata * 1/3)
- Frequenza di reporting: al minuto in base alle misurazioni al secondo aggregate in più di 1 minuto.
La quantità di ambiente di calcolo fatturata in serverless per le repliche a disponibilità elevata Hyperscale appartenenti alla replica primaria o qualsiasi replica denominata viene esposta dalla metrica seguente:
- Metrica: app_cpu_billed_HA_replicas (secondi per vCore)
- Definizione: somma del valore massimo (numero minimo di vCore, numero di vCore usati, quantità minima di memoria in GB * 1/3, quantità di memoria in GB usata * 1/3) per tutte le repliche a disponibilità elevata appartenenti alla risorsa padre.
- Risorsa padre ed endpoint metrica: la replica primaria e qualsiasi replica denominata espongono separatamente questa metrica, che misura l’ambiente di calcolo fatturato per le repliche a disponibilità elevata associate.
- Frequenza di reporting: al minuto in base alle misurazioni al secondo aggregate in più di 1 minuto.
Fatturazione minima di calcolo
Se un database serverless è in pausa, la fattura di calcolo è zero. Se un database serverless non è in pausa, la fattura minima di calcolo non è inferiore alla quantità di vCore in base al massimo (numero minimo di vCore, quantità minima di memoria in GB * 1/3).
Esempi:
- Si supponga che un database serverless nel livello per utilizzo generico non sia in pausa e sia configurato con 8 vCore al massimo e 1 vCore al minimo corrispondenti a 3,0 GB di memoria al minimo. La fattura minima di calcolo è quindi basata sul massimo (1 vCore, 3,0 GB * 1 vCore / 3 GB) = 1 vCore.
- Si supponga che un database serverless nel livello per utilizzo generico non sia in pausa e configurato con 4 vCore al massimo e 0,5 vCore al minimo corrispondenti a 2,1 GB di memoria al minimo. La fattura minima di calcolo è quindi basata sul massimo (0,5 vCore, 2,1 GB * 1 vCore / 3 GB) = 0,7 vCore.
- Si supponga che un database serverless nel livello Hyperscale abbia una replica primaria con una replica a disponibilità elevata e una replica denominata senza repliche a disponibilità elevata. Si supponga che ogni replica sia configurata con 8 vCore al massimo e 1 vCore al minimo corrispondenti a 3 GB di memoria al minimo. La fattura di calcolo minima per la replica primaria, la replica a disponibilità elevata e la replica denominata sono quindi ognuna in base al massimo (1 vCore, 3 GB * 1 vCore / 3 GB) = 1 vCore.
La calcolatrice dei prezzi del database SQL di Azure per serverless può essere usata per determinare la memoria minima configurabile in base al numero massimo e minimo di vCore configurati. Come regola, se i vCore minimi configurati sono maggiori di 0,5 vCore, la fattura minima di calcolo è indipendente dalla memoria minima configurata ed è basata solo sul numero di vCore minimi configurati.
Scenari esemplificativi
Si consideri un database serverless nel livello per utilizzo generico configurato con 1 vCore al minimo e 4 vCore al massimo. Questa configurazione corrisponde a una quantità minima di memoria di circa 3 GB e a una quantità massima di memoria di 12 GB. Si supponga che il ritardo di sospensione automatica sia impostato su 6 ore e che il carico di lavoro del database sia attivo nelle prime 2 ore di un periodo di 24 ore e inattivo nelle ore seguenti.
In questo caso, il database viene fatturato per le risorse di calcolo e di archiviazione durante le prime 8 ore. Anche se il database è inattivo a partire dalla seconda ora, viene comunque fatturato per il calcolo nelle 6 ore successive, in base al calcolo minimo con provisioning mentre il database è online. Durante il resto del periodo di 24 ore in cui il database è sospeso, viene fatturata solo l'archiviazione.
Più precisamente, la fattura per le risorse di calcolo in questo esempio viene calcolata come segue:
| Intervallo di tempo | vCore usati al secondo | GB usati al secondo | Dimensione di calcolo fatturata | Secondi per vCore fatturati nell'intervallo di tempo |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | vCore usati | 4 vCore * 3.600 secondi = 14.400 secondi per vCore |
| 1:00-2:00 | 1 | 12 | Memoria usata | 12 GB * 1/3 * 3.600 secondi = 14.400 secondi per vCore |
| 2:00-8:00 | 0 | 0 | Memoria minima con provisioning | 3 GB * 1/3 * 21.600 secondi = 21.600 secondi per vCore |
| 8:00-24:00 | 0 | 0 | Nessuna fatturazione delle risorse di calcolo durante la sospensione | 0 secondi per vCore |
| Totale secondi per vCore fatturati nel periodo di 24 ore | 50.400 secondi per vCore |
Si supponga che il prezzo delle unità di calcolo sia $0,000145/vCore/secondo. Il calcolo fatturato per questo periodo di 24 ore è il prodotto del prezzo delle unità di calcolo e dei secondi per vCore fatturati: $0,000145/vCore/secondo * 50.400 secondi per vCore ~ $7,31.
Vantaggio Azure Hybrid e capacità riservata
Vantaggio Azure Hybrid e gli sconti per la capacità riservata non si applicano al livello di calcolo serverless.
Aree disponibili
Serverless per i livelli per utilizzo generico e Hyperscale con supporto fino a 40 vCore al massimo è disponibile in tutto il mondo, ad eccezione delle aree seguenti:
- Cina orientale
- Cina settentrionale
- Germania centrale
- Germania nord-orientale
- Stati Uniti centrali (Iowa)
Aree che supportano 80 vCore al massimo senza zone di disponibilità per utilizzo generico e Hyperscale
Attualmente, 80 vCore al massimo in serverless per i livelli per utilizzo generico e Hyperscale sono attualmente supportati nelle aree seguenti:
- Australia centrale 1
- Australia centrale 2
- Australia orientale
- Australia sud-orientale
- Brasile meridionale
- Brasile meridionale
- Canada centrale
- Canada orientale
- Stati Uniti centrali
- Cina orientale 2
- Cina orientale 3
- Cina settentrionale 2
- Cina settentrionale 3
- Asia orientale
- Stati Uniti orientali
- Stati Uniti orientali 2
- Francia centrale
- Francia meridionale
- Germania settentrionale
- Germania centro-occidentale
- India centrale
- India meridionale
- Israele centrale
- Italia settentrionale
- Giappone orientale
- Giappone occidentale
- Jio - India centrale
- India occidentale Jio
- Corea centrale
- Corea meridionale
- Malesia meridionale
- Messico centrale
- Stati Uniti centro-settentrionali
- Europa settentrionale
- Norvegia orientale
- Norvegia occidentale
- Polonia Centrale
- Qatar centrale
- Sudafrica settentrionale
- Sudafrica occidentale
- Stati Uniti centro-meridionali
- Asia sud-orientale
- Spagna centrale
- Svezia centrale
- Svezia meridionale
- Svizzera settentrionale
- Svizzera occidentale
- Taiwan settentrionale
- Taiwan Nord-Occidentale
- Emirati Arabi Uniti centrali
- Emirati Arabi Uniti settentrionali
- Regno Unito meridionale
- Regno Unito occidentale
- US Gov orientale
- US Gov centro-meridionale
- US Gov Sud-orientale
- Europa occidentale
- Stati Uniti centro-occidentali
- Stati Uniti occidentali
- West US 2
- Stati Uniti occidentali 3
Aree che supportano 80 vCore al massimo con zone di disponibilità per utilizzo generico e Hyperscale
Attualmente, 80 vCore al massimo con supporto della zona di disponibilità in serverless per il livello per utilizzo generico e per il livello Hyperscale sono disponibili nelle aree seguenti con più aree pianificate:
- Australia orientale
- Brasile meridionale
- Canada centrale
- Stati Uniti centrali
- Asia orientale
- Stati Uniti orientali
- Stati Uniti orientali 2
- Francia centrale
- Germania centro-occidentale
- India centrale
- Giappone orientale
- Corea centrale
- Europa settentrionale
- Sudafrica settentrionale
- Stati Uniti centro-meridionali
- Asia sud-orientale
- Svezia centrale
- Emirati Arabi Uniti settentrionali
- Regno Unito meridionale
- US Gov orientale
- Europa occidentale
- West US 2
- Stati Uniti occidentali 3
Contenuto correlato
- Per iniziare, vedi Avvio rapido: Creare un database singolo, database SQL di Azure.
- Per le opzioni del livello di servizio serverless, vedi Per utilizzo generico e Hyperscale.