Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() Istanza gestita di SQL di Azure SQL
Istanza gestita di SQL di Azure SQL
Questo articolo offre una panoramica della funzionalità del gruppo di failover con procedure consigliate e consigli da usare con Istanza gestita di SQL di Azure. La funzionalità gruppi di failover consente di gestire la replica e il failover di tutti i database utente in un'istanza gestita di SQL in un'altra area di Azure.
Per iniziare, consultare Configurare un gruppo di failover per Azure SQL Managed Instance.
Panoramica
La funzionalità gruppi di failover consente di gestire la replica e il failover dei database utente da un'istanza gestita di SQL a un'altra istanza gestita di SQL in un'area di Azure diversa. I gruppi di failover sono progettati per semplificare la distribuzione e la gestione dei database con replica geografica su larga scala.
Per altre informazioni, vedere Disponibilità elevata di Istanza gestita di SQL di Azure. Per i dati RPO e RTO del failover geografico, vedere Panoramica della continuità aziendale.
Reindirizzamento dell'endpoint
I gruppi di failover forniscono endpoint listener di lettura/scrittura e di sola lettura che rimangono invariati durante i failover geografici. Non è necessario modificare la stringa di connessione per l'applicazione dopo un failover geografico, perché i collegamenti vengono indirizzati automaticamente al database primario corrente. Un failover geografico passa tutti i database secondari del gruppo al ruolo primario. Dopo aver completato il failover geografico, il record DNS viene automaticamente aggiornato per reindirizzare gli endpoint alla nuova area.
Scaricare i carichi di lavoro di sola lettura
Per ridurre il traffico ai database primari, è anche possibile usare i database secondari in un gruppo di failover per eseguire l'offload dei carichi di lavoro di sola lettura. Usare il listener di sola lettura per indirizzare il traffico di sola lettura a un database secondario leggibile.
Ripristino di un'applicazione
Per ottenere una continuità aziendale completa, l'aggiunta di ridondanza dei database regionali è solo una parte della soluzione. Per ripristinare un'applicazione (servizio) end-to-end dopo un problema grave, è necessario effettuare il ripristino di tutti i componenti del servizio e gli eventuali servizi dipendenti. Esempi di questi componenti includono il software client (ad esempio, un browser con JavaScript personalizzato), front-end Web, spazio di archiviazione e DNS. È di importanza cruciale che tutti i componenti siano resilienti agli stessi problemi e diventino disponibili entro l'obiettivo del tempo di ripristino (RTO) dell'applicazione. È perciò necessario identificare tutti i servizi dipendenti e comprendere quali garanzie e funzionalità vengono fornite. È quindi necessario intraprendere le azioni appropriate per assicurare il funzionamento del servizio durante il failover dei servizi da cui dipende.
Politica di failover
I gruppi di failover supportano due politiche di failover.
-
Gestito dal cliente (scelta consigliata): i clienti possono eseguire un failover di un gruppo quando rilevano un'interruzione imprevista che influisce su uno o più database nel gruppo di failover. Quando si usano strumenti della riga di comando come PowerShell, l'interfaccia della riga di comando di Azure o l'API REST, il valore dei criteri di failover per la gestione del cliente è
manual. -
Gestito da Microsoft : in caso di un'interruzione diffusa che influisce su un'area primaria, Microsoft avvia il failover di tutti i gruppi di failover interessati con i criteri di failover configurati per essere gestiti da Microsoft. Il failover gestito da Microsoft non verrà avviato per singoli gruppi o per un sottoinsieme di gruppi di failover in un'area. Quando si utilizzano strumenti da riga di comando come PowerShell, la CLI di Azure o l'API REST, il valore dei criteri di failover per i servizi gestiti da Microsoft è
automatic.
Ogni criterio di failover ha un set univoco di casi d'uso e le aspettative corrispondenti sull'ambito di failover e sulla perdita di dati, come riepiloga la tabella seguente:
| Politica di failover | Ambito di failover | Caso d'uso | Potenziale perdita di dati |
|---|---|---|---|
| Gestito dal cliente (consigliato) |
Gruppi di failover | Uno o più database in un gruppo di failover sono interessati da un'interruzione e diventano non disponibili. È possibile scegliere di effettuare il failover. | Sì |
| Gestita da Microsoft | Tutti i gruppi di failover nell'area | Un'interruzione diffusa in un'area causa l'indisponibilità dei database e il team del servizio SQL di Microsoft Azure decide di attivare un failover forzato. Usare questa opzione solo quando si vuole delegare la responsabilità del ripristino di emergenza a Microsoft e l'applicazione è tollerante a RTO (tempo inattivo) di almeno un'ora o più. Il failover gestito da Microsoft potrebbe essere eseguito solo in circostanze estreme. È altamente consigliabile una politica di failover gestita dal cliente. |
Sì |
Gestito dal cliente
In rari casi, la disponibilità predefinita o la disponibilità elevata non è sufficiente per attenuare un'interruzione e i database in un gruppo di failover potrebbero non essere disponibili per una durata non accettabile per il contratto di servizio delle applicazioni che usano i database. I database possono non essere disponibili a causa di un problema localizzato che influisce solo su alcuni database oppure a livello di data center, zona di disponibilità o area. In uno di questi casi, per ripristinare la continuità aziendale, è possibile avviare un failover forzato.
L'impostazione dei criteri di failover sul cliente gestito è altamente consigliata, in quanto consente di controllare quando avviare un failover e ripristinare la continuità aziendale. È possibile avviare un failover quando si nota un'interruzione imprevista che influisce su uno o più database nel gruppo di failover.
Gestita da Microsoft
Con un criterio di failover gestito da Microsoft, la responsabilità del ripristino di emergenza viene delegata al servizio Azure SQL. Affinché il servizio Azure SQL avvii un failover forzato, è necessario soddisfare le condizioni seguenti:
- Interruzione a livello di area causata da un evento di emergenza naturale, modifiche alla configurazione, bug software o errori dei componenti hardware e molti database nell'area sono interessati.
- Periodo di tolleranza scaduto. Poiché la verifica della scalabilità e la mitigazione dell'interruzione dipendono dalle azioni umane, il periodo di tolleranza non può essere impostato al di sotto di un'ora.
Quando queste condizioni vengono soddisfatte, il servizio Azure SQL avvia i failover forzati per tutti i gruppi di failover nella regione in cui la politica di failover è impostata su gestione Microsoft.
Importante
Usare i criteri di failover gestiti dal cliente per testare e implementare il piano di ripristino di emergenza. Non basarsi sul failover gestito da Microsoft, che verrebbe eseguito da Microsoft solo in circostanze estreme. Viene avviato un failover gestito da Microsoft per tutti i gruppi di failover nell'area che hanno la loro politica di failover impostata su gestito da Microsoft. Non può essere avviato per singoli gruppi di failover. Se è necessario eseguire il failover selettivo del gruppo di failover, usare la politica di failover gestita dal cliente.
Impostare i criteri di failover su gestiti da Microsoft solo quando:
- Si vuole delegare la responsabilità del ripristino di emergenza al servizio Azure SQL.
- L'applicazione è tollerante all'indisponibilità del database per almeno un'ora o più.
- È accettabile attivare i failover forzati qualche volta dopo la scadenza del periodo di tolleranza, perché il tempo effettivo per il failover forzato può variare significativamente.
- È accettabile che tutti i database all'interno del gruppo di failover subiscano il failover, indipendentemente dalla configurazione della ridondanza della zona o dallo stato di disponibilità. Anche se i database configurati per la ridondanza della zona sono resilienti agli errori di zona e potrebbero non essere interessati da un'interruzione, verranno comunque sottoposti a failover se fanno parte di un gruppo di failover con criteri di failover gestiti da Microsoft.
- È accettabile forzare il failover dei database nel gruppo di failover senza prendere in considerazione la dipendenza dell'applicazione da altri servizi o componenti di Azure utilizzati dall'applicazione, il che può causare un deterioramento delle prestazioni o l'indisponibilità dell'applicazione.
- È accettabile incorrere in una quantità sconosciuta di perdita di dati, perché l'ora esatta del failover forzato non può essere controllata e ignora lo stato di sincronizzazione dei database secondari.
- Le repliche primarie e secondarie nel gruppo di failover hanno lo stesso livello di servizio, il livello di calcolo e le dimensioni di calcolo.
Quando un failover viene attivato da Microsoft, al log attività di Azure Monitor viene aggiunta una voce per il nome dell'operazione failover del gruppo di failover di Azure SQL. La voce include il nome del gruppo di failover in Risorsa e l’Evento avviato da visualizza un solo trattino (-) per indicare che il failover è stato avviato da Microsoft. Queste informazioni sono disponibili anche nella pagina Log attività del nuovo server primario o dell'istanza del portale di Azure.
Terminologia e funzionalità
Gruppo di failover (FOG)
Un gruppo di failover consente a tutti i database utente all'interno di un'istanza gestita di SQL di eseguire il failover come unità in un'altra area di Azure nel caso in cui l'istanza gestita di SQL primaria non sia più disponibile a causa di un'interruzione dell'area primaria. Poiché i gruppi di failover per Istanza gestita di SQL contengono tutti i database utente all'interno dell'istanza, è possibile configurare un solo gruppo di failover in un'istanza.
Importante
Il nome del gruppo di failover deve essere univoco a livello globale all'interno del dominio
.database.windows.net.Primario
Istanza gestita di SQL che ospita i database primari nel gruppo di failover.
Secondario
Istanza gestita di SQL che ospita i database secondari nel gruppo di failover. Il server secondario non può trovarsi nella stessa area di Azure del server primario.
Importante
Se un database contiene oggetti OLTP in memoria, l'istanza della replica geografica primaria e secondaria deve avere livelli di servizio corrispondenti, perché gli oggetti OLTP in memoria risiedono in memoria. Un livello di servizio inferiore nell'istanza di replica geografica può causare problemi di memoria insufficiente. In questo caso, la replica secondaria potrebbe non riuscire a recuperare il database, causando l'indisponibilità del database secondario insieme agli oggetti OLTP in memoria nel database geografico secondario. Questo, a sua volta, potrebbe causare il fallimento del failover. Per evitare questo problema, assicurarsi che il livello di servizio dell'istanza geografica secondaria corrisponda a quello del database primario. Gli aggiornamenti del livello di servizio possono essere operazioni che dipendono dalla dimensione dei dati e possono richiedere tempo per completarsi.
Failover (nessuna perdita di dati)
Il failover esegue la sincronizzazione dei dati completa tra il database primario e il database secondario prima che il database secondario passi al ruolo primario. In questo modo si esclude la perdita di dati. Il failover è possibile solo quando il database primario è accessibile. Il failover viene usato negli scenari seguenti:
- Eseguire esercitazioni di recupero di emergenza in produzione quando la perdita di dati non è accettabile
- Rilocare il carico di lavoro in un'area diversa
- Ripristinare il carico di lavoro nell'area primaria dopo aver mitigato l'interruzione (failback)
Failover forzato (potenziale perdita di dati)
Con il failover forzato il database secondario passa immediatamente al ruolo primario senza dover aspettare che le modifiche recenti si propaghino dal database primario. Questa operazione può comportare la potenziale perdita di dati. Un failover forzato viene utilizzato come metodo di ripristino durante le interruzioni quando il primario non è accessibile. Quando l'interruzione viene prevenuta, il database primario precedente si riconnette automaticamente e diventa un nuovo database secondario. È possibile eseguire un failover per ripristinare le repliche, riportandole ai ruoli primari e secondari originali.
Periodo di tolleranza con perdita di dati
Poiché i dati vengono replicati nel database secondario usando la replica asincrona, il failover forzato dei gruppi con i criteri di failover gestiti da Microsoft può comportare la perdita di dati. È possibile personalizzare i criteri di failover per riflettere la tolleranza dell'applicazione verso la perdita dei dati. Configurando
GracePeriodWithDataLossHours, è possibile controllare per quanto tempo il servizio SQL di Azure attende prima di avviare un failover forzato, con conseguente perdita di dati.
Zona DNS
ID univoco generato automaticamente quando viene creata una nuova istanza gestita SQL. È emesso un certificato multi-dominio (SAN) per questa istanza per autenticare le connessioni client a qualsiasi istanza nella stessa zona DNS. Le due istanze gestite di SQL nello stesso gruppo di failover devono condividere la zona DNS.
Listener del gruppo di failover per lettura/scrittura
Un record CNAME DNS che punta al server primario attuale. Viene creato automaticamente al momento della creazione del gruppo di failover e consente al carico di lavoro in lettura-scrittura di riconnettersi in modo trasparente all'istanza primaria quando questa cambia dopo il failover. Quando il gruppo di failover viene creato in un'istanza gestita di SQL, il record CNAME DNS per l'URL del listener viene formato come
<fog-name>.<zone_id>.database.windows.net.Listener di sola lettura del gruppo di failover
Un record CNAME DNS che punta al server secondario corrente. Viene creato automaticamente al momento della creazione del gruppo di failover e consente ai carichi di lavoro SQL in sola lettura di connettersi in modo trasparente al secondario quando quest'ultimo cambia dopo il failover. Quando il gruppo di failover viene creato in un'istanza gestita di SQL, il record CNAME DNS per l'URL del listener viene formato come
<fog-name>.secondary.<zone_id>.database.windows.net. Per impostazione predefinita, il failover del listener di sola lettura è disabilitato perché garantisce che le prestazioni del database primario non siano interessate quando il database secondario è offline. Ciò significa anche che le sessioni di sola lettura non sono in grado di connettersi fino a quando il database secondario non viene recuperato. Se non è possibile consentire alcun tempo inattivo per le sessioni di sola lettura ed è possibile usare il database primario sia per il traffico di sola lettura che per quello di lettura/scrittura a scapito della potenziale riduzione del livello delle prestazioni del database primario, è possibile abilitare il failover per il listener di sola lettura configurando la proprietàAllowReadOnlyFailoverToPrimary. In tal caso il traffico di sola lettura verrà reindirizzato automaticamente al database primario qualora il database secondario non sia disponibile.Nota
La proprietà
AllowReadOnlyFailoverToPrimaryha effetto solo se i criteri di failover gestiti da Microsoft sono abilitati e viene attivato un failover forzato. In tal caso, se la configurazione è impostata su True, il nuovo nodo primario gestisce sia le sessioni di lettura/scrittura che quelle di sola lettura.
Architettura del gruppo di failover
Il gruppo di failover deve essere configurato nell'istanza primaria e lo connette all'istanza secondaria in un'area di Azure diversa. Tutti i database utente nell'istanza primaria vengono replicati nell'istanza secondaria. I database di sistema come master e msdb non vengono replicati.
Il diagramma seguente illustra una configurazione tipica di un'applicazione cloud con ridondanza geografica usando un'istanza gestita di SQL e un gruppo di failover:
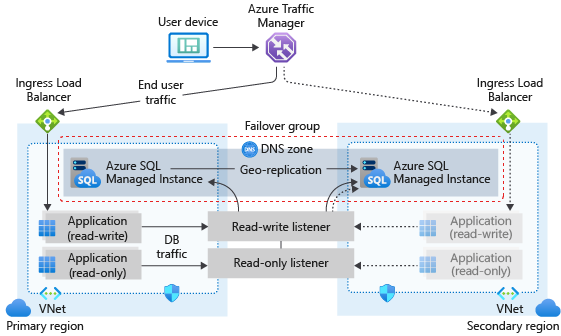
Se l'applicazione usa Istanza SQL gestita come livello dati, seguire le linee guida generali e le procedure consigliate delineate all’interno di questo articolo durante la progettazione della continuità aziendale.
Creare l'istanza geografica secondaria
Per garantire una connettività ininterrotta all'istanza gestita di SQL primaria dopo il failover, sia le istanze primarie che secondarie devono trovarsi nella stessa zona DNS. Garantisce che lo stesso certificato multi-dominio (SAN) possa essere utilizzato per autenticare le connessioni client a una delle due istanze nel gruppo di failover. Quando l'applicazione è pronta per la distribuzione in produzione, creare un'istanza gestita di SQL secondaria in un'area diversa e assicurarsi che condivida la zona DNS con l'istanza gestita di SQL primaria. A tale scopo, è possibile specificare un parametro facoltativo quando si crea l'istanza. Se si usa PowerShell o l'API REST, il nome del parametro opzionale è DNSZonePartner. Il nome del campo facoltativo corrispondente nel portale di Azure è Istanza gestita primaria.
Importante
La prima istanza gestita di SQL creata nella subnet determina la zona DNS per tutte le istanze successive nella stessa subnet. Ciò significa che due istanze della stessa subnet non possono appartenere a zone DNS diverse.
Per altre informazioni sulla creazione dell'istanza gestita di SQL secondaria nella stessa zona DNS dell'istanza primaria, vedere Configurare un gruppo di failover per Istanza gestita di SQL di Azure.
Usare aree accoppiate
Distribuire entrambe le istanze gestite di SQL in aree abbinate per motivi di prestazioni. I gruppi di failover di istanza gestita di SQL nelle regioni accoppiate hanno prestazioni migliori rispetto alle regioni non accoppiate.
Istanza gestita di SQL di Azure segue una procedura di distribuzione sicura in cui le aree abbinate di Azure in genere non vengono distribuite contemporaneamente. Tuttavia, non è possibile stimare l'area aggiornata per prima, quindi l'ordine di distribuzione non è garantito. In alcuni casi, l'istanza primaria viene aggiornata per prima e talvolta l'istanza secondaria viene aggiornata per prima.
In situazioni in cui Istanza gestita di SQL di Azure fa parte di un gruppo di failover e le istanze nel gruppo non si trovano in aree abbinate di Azure, selezionare diverse pianificazioni della finestra di manutenzione per il database primario e secondario. Ad esempio, selezionare una finestra di manutenzione della settimana per il database geografico secondario e una finestra di manutenzione fine settimana per il database geo-primario.
Abilitare e ottimizzare il flusso del traffico di replica geografica tra le istanze
La connettività tra le subnet di rete virtuale che ospitano l'istanza primaria e secondaria deve essere stabilita e mantenuta per il flusso ininterrotto del traffico di replica geografica. Esistono diversi modi per fornire la connettività tra le istanze tra cui è possibile scegliere in base alla topologia di rete e ai criteri:
Il peering globale delle reti virtuali è il modo consigliato per stabilire la connettività tra due istanze in un gruppo di failover. Consente di avere una connessione privata a bassa latenza e con larghezza di banda elevata tra le reti virtuali con peering usando l'infrastruttura backbone di Microsoft. Nella comunicazione tra le reti virtuali con peering non sono necessari gateway, la rete Internet pubblica o una crittografia aggiuntiva.
Impostazione iniziale
Quando si stabilisce un gruppo di failover tra istanze gestite di SQL, è presente una fase di seeding iniziale prima dell'avvio della replica dei dati. La fase iniziale del seeding è la parte più lunga e più costosa dell'operazione. Al termine del seeding iniziale, i dati vengono sincronizzati e vengono replicate solo le modifiche ai dati successive. Il tempo necessario per il completamento del seeding iniziale dipende dalle dimensioni dei dati, dal numero di database replicati, dall'intensità del carico di lavoro nei database primari e dalla velocità del collegamento tra le reti virtuali che ospitano l'istanza primaria e secondaria, che dipende principalmente dal modo in cui viene stabilita la connettività. In circostanze normali e quando la connettività viene stabilita utilizzando il peering consigliato delle reti virtuali globali, la velocità di seeding può raggiungere fino a 360 GB all'ora per l'Istanza SQL gestita. Il seeding viene eseguito per un batch di database utente in parallelo, ma non necessariamente per tutti i database contemporaneamente. Potrebbero essere necessari più batch se sono presenti molti database ospitati nell'istanza.
Se la velocità del collegamento tra le due istanze è più lenta rispetto a quella necessaria, è probabile che il tempo di inizializzazione sia notevolmente influenzato. È possibile usare la velocità di seeding indicata, il numero di database, le dimensioni totali dei dati e la velocità di collegamento per stimare il tempo necessario per la fase di seeding iniziale prima dell'avvio della replica dei dati. Ad esempio, per un singolo database da 100 GB, la fase di inizializzazione iniziale richiederà circa 1,2 ore se il collegamento è in grado di eseguire il push di 84 GB all'ora e se non sono presenti altri database di cui viene eseguito il seeding. Se il collegamento può trasferire solo 10 GB all'ora, il seeding di un database da 100 GB può richiedere circa 10 ore. Se sono presenti più database da replicare, il seeding viene eseguito in parallelo. In combinazione con una velocità di collegamento lenta, la fase di seeding iniziale potrebbe richiedere molto più tempo, soprattutto se il seeding parallelo dei dati di tutti i database supera la larghezza di banda del collegamento disponibile.
Importante
La fase iniziale di seeding può richiedere giorni con collegamenti a velocità estremamente bassa o molto occupati. In questo caso, il processo di creazione del gruppo di failover può andare in timeout. La creazione del gruppo di failover viene automaticamente annullata dopo sei giorni.
Gestire il failover geografico in un'istanza geografica secondaria
Il gruppo di failover gestisce il failover geografico di tutti i database nell'istanza gestita di SQL primaria. Quando viene creato un gruppo, ogni database nell'istanza viene automaticamente replicato geograficamente nell'istanza geografica secondaria. Non è possibile usare gruppi di failover per avviare un failover parziale di un subset dei database.
Importante
Se un database viene eliminato nell'istanza gestita di SQL primaria, viene eliminato automaticamente anche nell'istanza gestita di SQL geografica secondaria.
Usare il listener di lettura-scrittura (MI primaria)
Per i carichi di lavoro di lettura/scrittura, usare <fog-name>.zone_id.database.windows.net come nome del server. Le connessioni vengono indirizzate automaticamente al database primario. Questo nome non cambia dopo il failover. Il failover geografico comporta l'aggiornamento del record DNS, quindi le nuove connessioni client vengono instradate al nuovo server primario solo dopo che la cache DNS del client è stata aggiornata. Poiché l'istanza secondaria condivide la zona DNS con l'istanza primaria, l'applicazione client sarà in grado di riconnettervisi mediante lo stesso certificato SAN del lato server. Le connessioni client esistenti devono essere terminate e quindi ricreate per essere indirizzate al nuovo database primario. Il listener di lettura/scrittura e il listener di sola lettura non possono essere raggiunti tramite l'endpoint pubblico per l'istanza gestita di SQL.
Usare il listener di sola lettura (MI secondario)
Se hai carichi di lavoro di sola lettura isolati logicamente e tolleranti alla latenza dei dati, puoi eseguirli nella replica geografica secondaria. Per stabilire una connessione diretta con la replica geografica secondaria, usare <fog-name>.secondary.<zone_id>.database.windows.net come nome del server.
Nel livello Business Critical, l'Istanza gestita di SQL supporta l'uso di repliche di sola lettura per scaricare i carichi di lavoro di query di sola lettura, utilizzando il parametro ApplicationIntent=ReadOnly nella stringa di connessione. Dopo aver configurato un database secondario con replica geografica, sarà possibile usare questa funzionalità per connettersi a una replica di sola lettura nella posizione primaria o nella posizione con replica geografica:
- Per connettersi a una replica di sola lettura nella posizione principale, utilizzare
ApplicationIntent=ReadOnlye<fog-name>.<zone_id>.database.windows.net. - Per connettersi a una replica di sola lettura nella posizione secondaria, usare
ApplicationIntent=ReadOnlye<fog-name>.secondary.<zone_id>.database.windows.net.
I listener di lettura/scrittura e quelli di sola lettura non sono raggiungibili tramite il punto di accesso pubblico per un'istanza SQL gestita.
Potenziale riduzione delle prestazioni dopo il failover
Un'applicazione Azure tipica usa più servizi di Azure ed è costituita da più componenti. Il failover geografico di un gruppo viene attivato solo in base allo stato dei componenti di Azure SQL. Un'interruzione potrebbe non influire su altri servizi di Azure nell'area primaria e i relativi componenti potrebbero essere ancora disponibili in tale area. Quando i database primari passano all'area secondaria, la latenza tra i componenti dipendenti può aumentare. Assicurarsi che ci sia la ridondanza di tutti i componenti dell'applicazione nella regione secondaria e che il failover dei componenti dell'applicazione, insieme al database, sia attuato in modo che una latenza interregionale più elevata non influisca sulle prestazioni dell'applicazione.
Potenziale perdita di dati dopo il failover forzato
Se si verifica un'interruzione nell'area primaria, le transazioni recenti potrebbero non essere state replicate nell'area geografica secondaria e potrebbero verificarsi perdite di dati se viene eseguito un failover forzato.
Aggiornamento del DNS
Subito dopo l'avvio del failover si verificherà l'aggiornamento DNS del listener di lettura/scrittura. Questa operazione non comporterà la perdita di dati. Tuttavia, il processo di cambio dei ruoli del database può richiedere fino a cinque minuti in condizioni normali. Durante il processo alcuni database nella nuova istanza primaria rimarranno di sola lettura. Se un failover viene avviato tramite PowerShell, l'operazione per cambiare il ruolo di replica primaria è sincrona. Se viene avviato mediante il portale di Azure, l'interfaccia utente indicherà lo stato di completamento. Se viene avviato mediante l'API REST, usare il meccanismo di polling standard di Azure Resource Manager per monitorare il completamento.
Importante
Usare il failover pianificato manuale per spostare nuovamente il database primario nella posizione originale dopo l'interruzione che ha causato il failover geografico.
Risparmia sui costi con una replica DR senza licenza
È possibile risparmiare sui costi delle licenze di SQL Server configurando l'istanza gestita di SQL secondaria da usare solo per il ripristino di emergenza. Per configurare questa impostazione, vedere Configurare una replica standby senza licenza per Istanza gestita di SQL di Azure.
Se l'istanza secondaria non viene utilizzata per i carichi di lavoro di lettura, Microsoft fornisce gratuitamente un numero di vCore pari all'istanza primaria. Viene comunque addebitato il costo per la risorsa di calcolo e quella di archiviazione usate dall'istanza secondaria. I gruppi di failover supportano una sola replica e la replica deve essere una replica leggibile o designata come replica esclusivamente per il ripristino di emergenza.
Abilitare scenari dipendenti da oggetti dai database di sistema
Non vengono replicati i database di sistema nell'istanza secondaria in un gruppo di failover. Per abilitare scenari che dipendono da oggetti dai database di sistema, assicurarsi di creare gli stessi oggetti nell'istanza secondaria. Mantenerli sincronizzati con l'istanza primaria.
Ad esempio, se si prevede di usare gli stessi account di accesso nell'istanza secondaria, assicurarsi di crearli con l'identico SID.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Per ulteriori informazioni, vedere Replica di accessi e processi agente.
Sincronizzare le proprietà dell'istanza e le istanze dei criteri di conservazione
Le istanze di un gruppo di failover rimangono separate dalle risorse di Azure e non vengono replicate automaticamente nell'istanza secondaria alcuna modifica apportata alla configurazione dell'istanza primaria. Assicurarsi di eseguire tutte le modifiche rilevanti nell'istanza primaria e secondaria. Ad esempio, se si modifica la ridondanza dell'archiviazione di backup o i criteri di conservazione dei backup a lungo termine nell'istanza primaria, assicurarsi di modificarla anche nell'istanza secondaria.
Scalabilità delle istanze
La configurazione dell'istanza primaria e secondaria deve essere la stessa. Sono incluse le dimensioni di calcolo, le dimensioni di archiviazione e il livello di servizio. Se è necessario modificare la configurazione del gruppo di failover, è possibile farlo ridimensionando ogni istanza alla stessa configurazione di conseguenza. Per altre informazioni, vedere Ridimensionare le istanze in un gruppo di failover.
Evitare la perdita di dati critici
A causa della latenza elevata delle reti Wide Area Network, per la replica geografica viene usato un meccanismo di replica asincrona. La replica asincrona può comportare la perdita di dati nel caso in cui il database primario abbia esito negativo. Per informazioni su come proteggere i dati, vedere Impedire la perdita di dati.
Stato del gruppo di failover
Il gruppo di failover riporta il proprio stato descrivendo lo stato corrente della replica dei dati.
- Seeding: il seeding iniziale viene eseguito dopo la creazione del gruppo di failover, fino a quando non vengono inizializzati tutti i database utente nell'istanza secondaria. Non è possibile avviare il failover mentre il gruppo di failover si trova nello stato seeding , perché i database utente non vengono ancora copiati nell'istanza secondaria.
- Sincronizzazione: stato consueto del gruppo di failover. Ciò significa che le modifiche ai dati nell'istanza primaria vengono replicate in modo asincrono nell'istanza secondaria. Questo stato non garantisce che i dati siano completamente sincronizzati in ogni momento. Possono essere apportate modifiche ai dati dal database primario ancora da replicare al database secondario a causa della natura asincrona del processo di replica tra istanze in un gruppo di failover. I failover automatici e manuali possono essere avviati mentre il gruppo di failover si trova nello stato di sincronizzazione .
- Failover in corso: questo stato indica che il failover è stato avviato automaticamente o manualmente ed è in fase di esecuzione. Non è possibile apportare modifiche al gruppo di failover o avviare altri failover mentre il gruppo di failover si trova in questo stato.
Ripristino
Quando i gruppi di failover sono configurati con criteri di failover gestiti da Microsoft, il failover forzato nel server secondario geografico viene avviato durante uno scenario di emergenza in base al periodo di tolleranza definito. Il ritorno al vecchio primario deve essere avviato manualmente.
Interoperabilità delle funzionalità
Backup
Nei seguenti scenari viene eseguito un backup completo:
- Prima dell'avvio del seeding iniziale, quando si crea un gruppo di failover.
- Dopo un failover.
Un backup completo è un'operazione su un volume considerevole di dati che non può essere ignorata o differita e che può richiedere tempo per essere completata. Il tempo necessario per il completamento dipende dalle dimensioni dei dati, dal numero di database e dall'intensità del carico di lavoro nei database primari. Un backup completo può ritardare notevolmente il seeding iniziale e può ritardare o impedire un'operazione di failover su una nuova istanza poco dopo un failover.
Tenere presente quanto segue:
- I database ospitati nell'istanza secondaria di un gruppo di failover non vengono sottoposti a backup fino a quando tale istanza non diventa primaria dopo un failover o fino all'eliminazione del gruppo di failover.
- Dopo che un database viene modificato nel ruolo primario dopo un failover o diventa autonomo dopo l'eliminazione di un gruppo di failover, viene avviato automaticamente un backup completo del database per facilitare i ripristini temporizzato.
- Non è possibile ripristinare un database da un'istanza a un punto nel tempo in cui tale istanza era una replica secondaria in un gruppo di failover. Per eseguire il ripristino a un punto nel tempo, è necessario ripristinare il database dall'istanza primaria in quel momento.
- Per ricreare un gruppo di failover eliminato nella stessa coppia di istanze gestite di SQL, è necessario rimuovere tutti i database utente dal database secondario previsto dopo l'eliminazione del gruppo di failover. Un database viene rimosso completamente solo dopo il completamento di tutte le operazioni di backup in sospeso, incluso un backup completo se non è stato eseguito (operazione relativa alle dimensioni dei dati). Lascia il tempo necessario per pulire l'istanza secondaria dopo aver rimosso un gruppo di failover con database molto grandi, poiché ogni database potrebbe avere un'operazione di backup completo che potrebbe essere ancora in corso.
Un backup completo è un'operazione di gestione dei dati che non può essere ignorata né posticipata e può richiedere del tempo per essere completata. Il tempo necessario per il completamento dipende dalle dimensioni dei dati, dal numero di database e dall'intensità del carico di lavoro nei database primari. Un backup completo può ritardare notevolmente il seeding iniziale e può ritardare o impedire un'operazione di failover in una nuova istanza poco dopo un failover.
Servizio di riproduzione log
I database migrati all’istanza gestita di SQL di Azure usando il servizio di riproduzione log (LRS) non possono essere aggiunti a un gruppo di failover fino a quando non viene eseguito il passaggio di cutover. Un database migrato con LRS (archiviazione con ridondanza locale) è in modalità di ripristino fino al cutover e i database in modalità di ripristino non possono essere aggiunti a un gruppo di failover. Il tentativo di creare un gruppo failover con un database in stato di ripristino ritarda la creazione del gruppo failover fino al completamento del ripristino del database.
Replica transazionale
È supportato l’uso della replica transazionale con istanze incluse in un gruppo di failover. Tuttavia, se si configura la replica prima di aggiungere l'istanza gestita di SQL in un gruppo di failover, la replica viene sospesa quando si inizia a creare il gruppo di failover. Monitor replica mostra lo stato di Replicated transactions are waiting for the next log backup or for mirroring partner to catch up. La replica riprende una volta che il gruppo di failover è stato creato con successo.
Se un’istanza gestita di SQL di pubblicazione o distribuzione si trova in un gruppo di failover, l'amministratore dell'istanza gestita di SQL deve pulire tutte le pubblicazioni nel database primario precedente e riconfigurarle nel nuovo database primario dopo che si verifica un failover. Esaminare la guida alla replica transazionale per la sequenza delle attività necessarie in questo scenario.
Autorizzazioni e limitazioni
Prima di configurare un gruppo di failover, controllare l’elenco di autorizzazioni e limitazioni.
Gestione programmatica di gruppi di failover
I gruppi di failover possono anche essere gestiti a livello di codice usando Azure PowerShell, l'interfaccia della riga di comando di Azure e l'API REST. Rivedi Configura il gruppo di failover per saperne di più.
Simulazioni di ripristino dopo disastri
Il modo consigliato per eseguire un'esercitazione di ripristino di emergenza consiste nell'usare il failover pianificato manuale, come illustrato nell'esercitazione seguente: Failover di prova.
Non è consigliabile eseguire una simulazione utilizzando il failover forzato, poiché questa operazione non offre garanzie contro la perdita di dati. Tuttavia, è possibile ottenere un failover forzato senza perdita di dati assicurandosi che vengano soddisfatte le condizioni seguenti prima di avviare il failover forzato:
- Il carico di lavoro viene arrestato nell'istanza gestita di SQL primaria.
- Tutte le transazioni a esecuzione prolungata sono state completate.
- Tutte le connessioni client all'istanza gestita di SQL primaria sono state disconnesse.
- Lo stato del gruppo di failover è “Sincronizzazione in corso”.
Assicurarsi che le due istanze gestite di SQL abbiano cambiato ruolo. Inoltre, lo stato del gruppo di failover è passato da "Failover in corso" a "Sincronizzazione" prima di stabilire facoltativamente le connessioni alla nuova istanza gestita di SQL primaria e avviare il carico di lavoro di lettura-scrittura.
Per eseguire un failback senza perdita di dati nei ruoli dell'istanza gestita di SQL originale, è consigliabile usare il failover pianificato manuale anziché il failover forzato. Se viene usato il failback forzato:
- Seguire gli stessi passaggi per il failover senza perdita di dati.
- È previsto un tempo di esecuzione del failback più lungo se il failback forzato viene eseguito poco dopo il completamento del failover forzato iniziale, perché deve attendere il completamento di operazioni di backup automatiche in sospeso nell'istanza gestita di SQL primaria precedente.
- Tutte le operazioni di backup automatico in sospeso in un'istanza che passano dal ruolo primario al ruolo secondario possono influire sulla disponibilità del database in questa istanza.
- Usare lo stato del gruppo di failover per determinare se entrambe le istanze hanno modificato correttamente i ruoli e sono pronte per accettare le connessioni client.
Contenuto correlato
- Configurare un gruppo di failover per Istanza gestita di SQL di Azure
- Usare PowerShell per aggiungere un'istanza gestita di SQL a un gruppo di failover
- Configurare una replica standby senza licenza per Istanza gestita di SQL di Azure
- Panoramica della continuità aziendale con Istanza gestita di SQL di Azure
- Backup automatizzati nell'Istanza SQL gestita di Azure
- Ripristinare un database da un backup - Istanza gestita di SQL di Azure