Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra come prepararsi per un'interruzione a livello di area Azure replicando le risorse, la gestione e l'inserimento di Esplora dati di Azure in aree Azure diverse. L'articolo include un esempio di inserimento dati con Hub eventi di Azure. Illustra anche l'ottimizzazione dei costi per diverse configurazioni di architettura. Per un'analisi più approfondita delle considerazioni sull'architettura e sulle soluzioni di ripristino, vedere la panoramica della continuità aziendale.
Preparare l'interruzione a livello di area di Azure per proteggere i dati
Esplora dati di Azure non supporta la protezione automatica contro l'indisponibilità di un'intera area di Azure. Questa interruzione può verificarsi durante una calamità naturale, ad esempio un terremoto. Se è necessaria una soluzione di ripristino di emergenza, seguire questa procedura per garantire la continuità aziendale. In questi passaggi si replicano i cluster, le attività di gestione e l'inserimento dati in due aree abbinate Azure.
- Creare due o più cluster indipendenti in due aree abbinate di Azure.
- Replicare tutte le attività di gestione, ad esempio la creazione di nuove tabelle o la gestione dei ruoli utente in ogni cluster.
- Inserire i dati in ogni cluster in parallelo.
Creare più cluster indipendenti
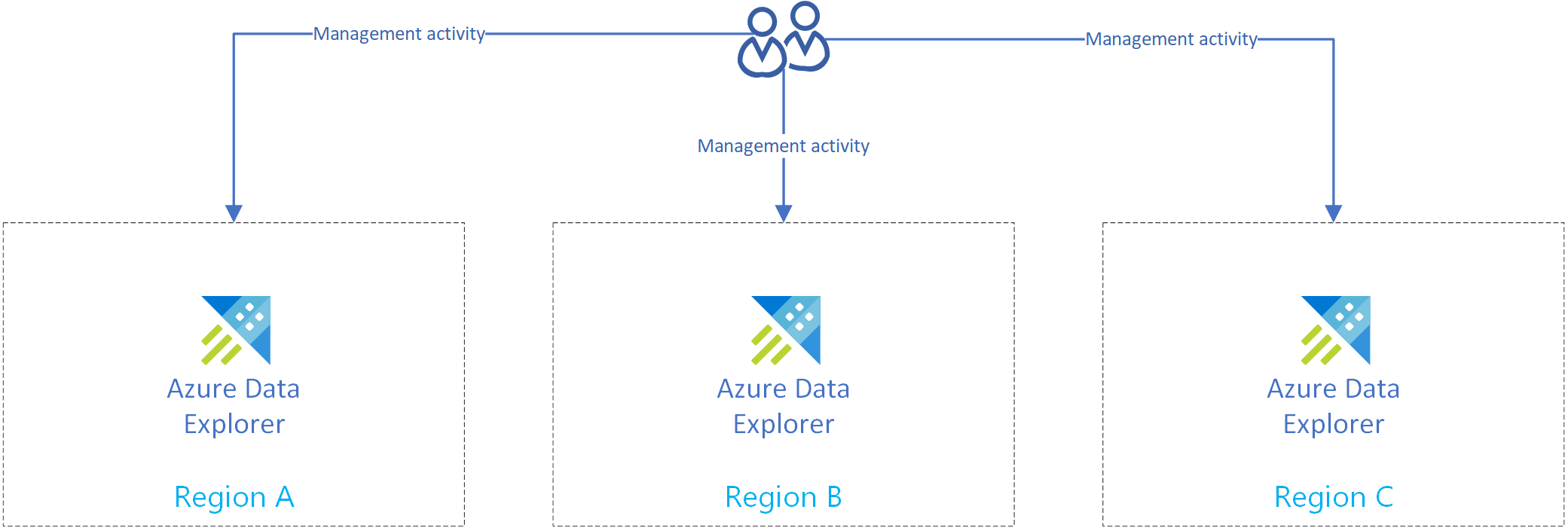
Creare più di un cluster di Esplora dati di Azure in più di un'area geografica. Creare almeno due di questi cluster nelle aree associate di Azure.
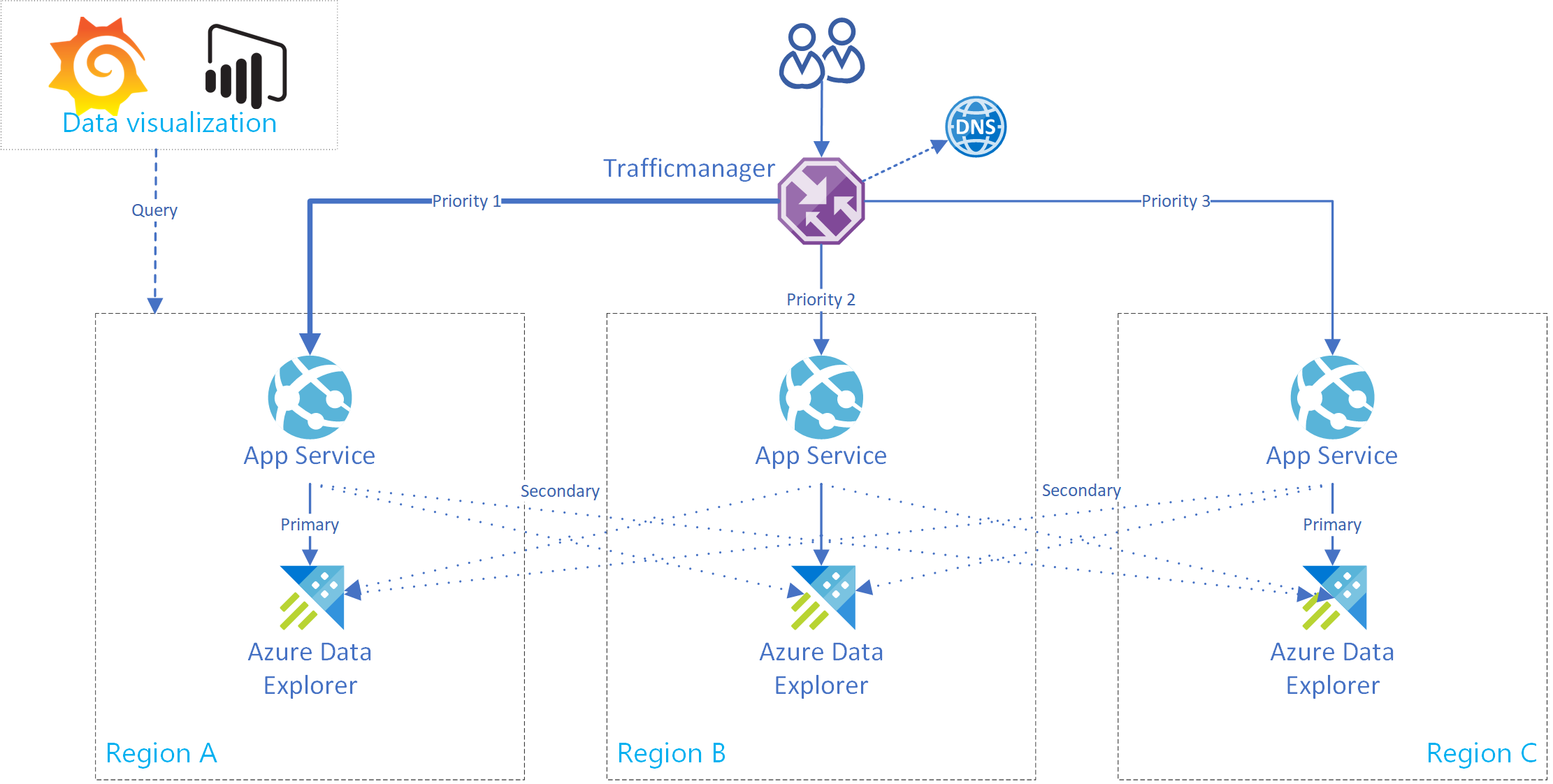
Il diagramma seguente mostra tre cluster di replica in tre aree diverse.

Replicare le attività di gestione
Replicare le attività di gestione in modo che ogni replica abbia la stessa configurazione del cluster.
Creare le stesse risorse in ogni replica:
- Database: usare il portale di Azure o uno degli SDK per creare un nuovo database.
- Tabelle
- Mapping
- Policy
Gestire l'autenticazione e l'autorizzazione in ogni replica.
Soluzione di ripristino di emergenza con l'inserimento di Hub eventi
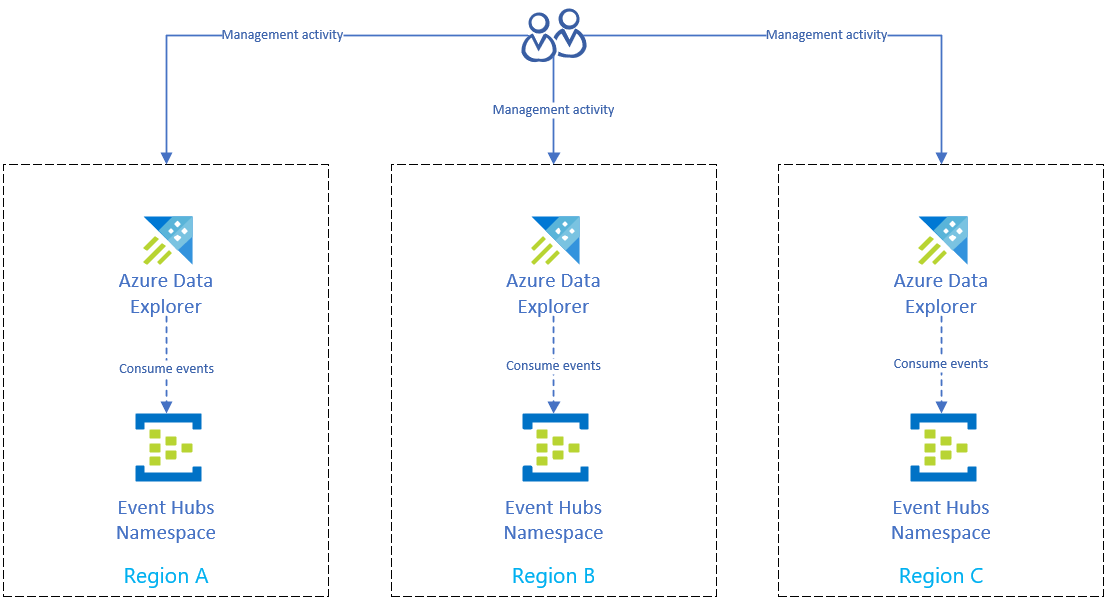
Dopo aver completato Prepararsi a un'interruzione di Azure a livello di area geografica per proteggere i dati, Esplora dati di Azure archivia i dati e le informazioni di gestione in più aree geografiche. Se si verifica un'interruzione in un'area, Esplora dati di Azure può usare le altre repliche.
Configurare l'acquisizione usando Event Hubs
Per inserire dati da Hub eventi di Azure nel cluster di Azure Esplora dati di ogni area, replicare prima di tutto la configurazione di Hub eventi di Azure in ogni area. Configurare quindi la replica di Esplora dati di Azure di ogni area geografica per acquisire dati dai corrispondenti Event Hubs.
Nota
L'acquisizione tramite Hub eventi di Azure, hub IoT o Storage è affidabile. Se un cluster non è disponibile per un certo periodo di tempo, si riallinea successivamente e inserisce gli eventuali messaggi o blob in sospeso. Questo processo si basa sul checkpointing.
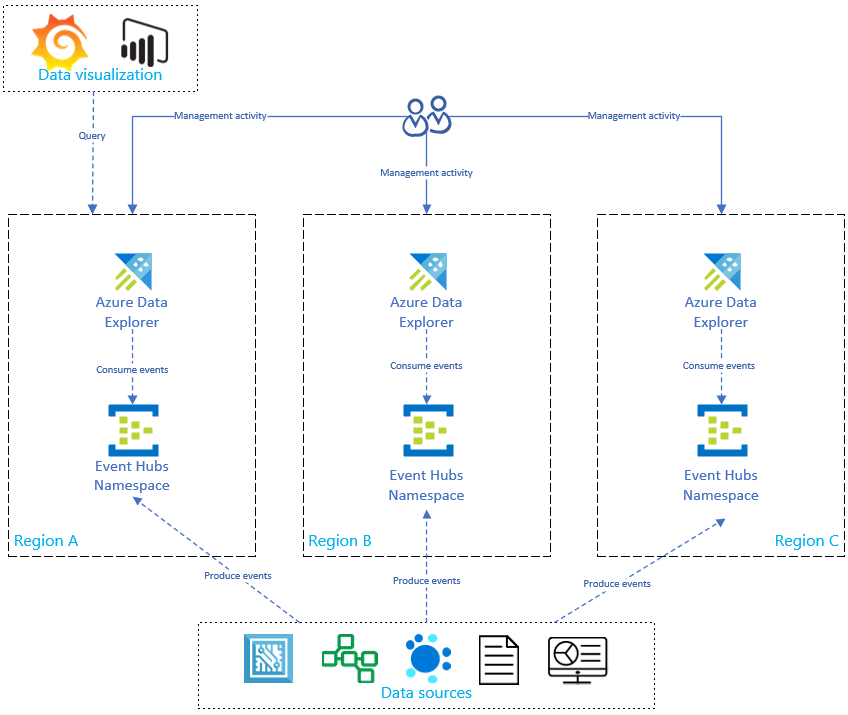
Questo diagramma mostra che le fonti di dati producono eventi in Event Hubs in tutte le regioni e ogni replica di Esplora dati di Azure li elabora. I componenti di visualizzazione dei dati, ad esempio Power BI, Grafana o app Web basate su SDK, possono eseguire query su una replica.
Ottimizzazione dei costi
A questo momento è possibile ottimizzare le repliche usando alcuni dei metodi seguenti:
- Creare una configurazione di ripristino dei dati su richiesta.
- Avviare e arrestare le repliche.
- Implementa un servizio applicativo ad alta disponibilità.
- Ottimizzare i costi in una configurazione attiva-attiva.
Creare una configurazione di ripristino dei dati su richiesta
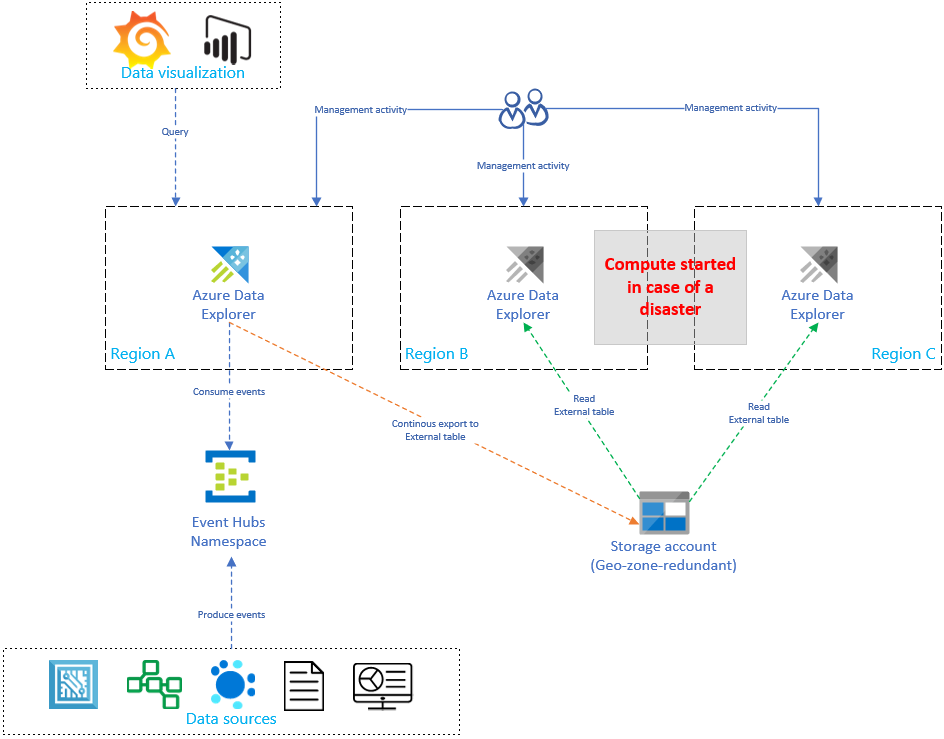
La replica e l'aggiornamento della configurazione Esplora dati di Azure aumentano in modo lineare i costi man mano che aumenta il numero di repliche. Per ottimizzare i costi, implementare una variante dell'architettura che bilancia il tempo, il failover e i costi. Una configurazione di ripristino dei dati su richiesta ottimizza i costi usando repliche di Esplora dati di Azure passive. Queste repliche vengono attivate solo se si verifica un'emergenza nell'area primaria, ad esempio l'area A. Le repliche nelle aree B e C non devono essere attive 24/7, riducendo in modo significativo il costo. Ma nella maggior parte dei casi queste repliche non offrono le stesse prestazioni del cluster primario. Per altre informazioni, vedere Configurazione del ripristino dei dati su richiesta.
Nel diagramma seguente un solo cluster inserisce i dati da Hub eventi. Il cluster primario nell'Area geografica A esegue la esportazione continua dei dati di tutti i dati in un account di archiviazione. Le repliche secondarie accedono ai dati usando tabelle esterne.
Avviare e arrestare le repliche
Avviare e interrompere le repliche secondarie usando uno dei metodi seguenti:
Connettore per Esplora dati di Azure per Power Automate (anteprima)
Pulsante Arresta nella scheda Panoramica della portale di Azure. Per altre informazioni, vedere Arrestare e riavviare il cluster.
Interfaccia della riga di comando di Azure:
az kusto cluster stop --name=<clusterName> --resource-group=<rgName> --subscription=<subscriptionId>
Implementare un servizio applicazioni a disponibilità elevata
Creare il client BCDR del servizio app Azure
Questa sezione illustra come creare un servizio app Azure che supporta una connessione a un singolo cluster di Azure Esplora dati primario e secondario. L'immagine seguente illustra la configurazione del servizio app Azure.
Suggerimento
La presenza di più connessioni tra repliche nello stesso servizio offre una maggiore disponibilità. Questa configurazione non è utile solo in caso di interruzioni a livello di area.
Usa questo codice boilerplate per un servizio dell'app. Per implementare un client multicluster, usare la classe AdxBcdrClient . Ogni query eseguita dal client viene inviata prima al cluster primario. Se si verifica un errore, la query viene inviata alle repliche secondarie.
Usare le metriche personalizzate di Application Insights per misurare le prestazioni e richiedere la distribuzione nei cluster primari e secondari.
Testare il client BCDR del servizio app Azure
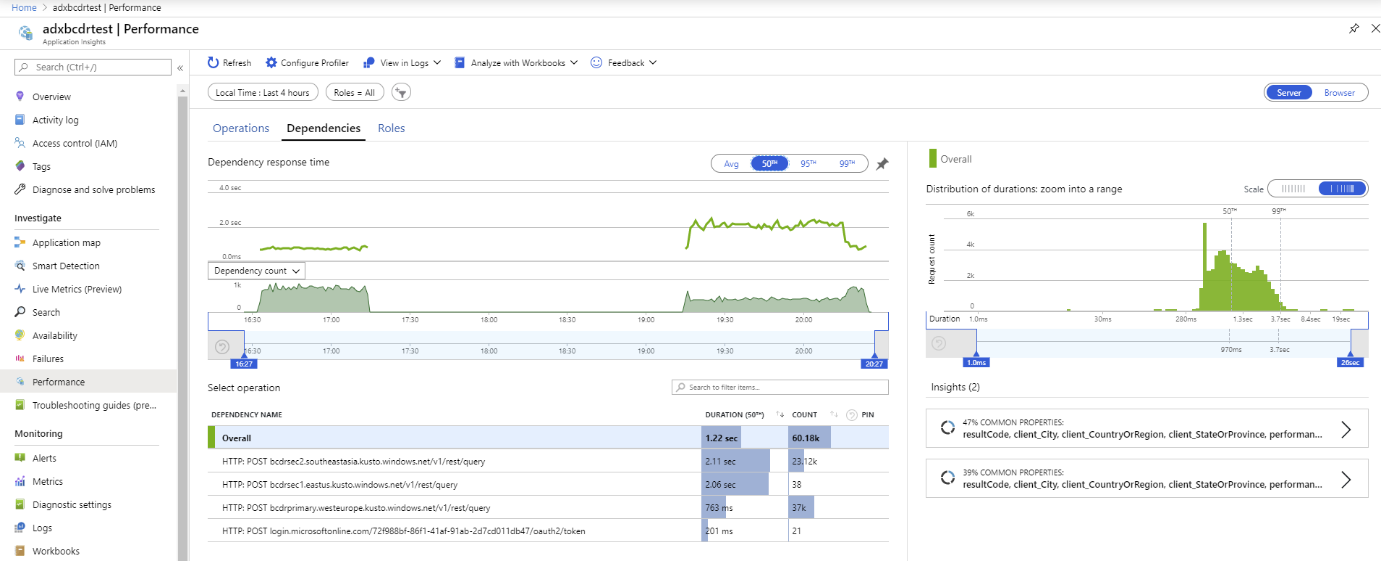
Il test seguente usa più repliche di Esplora dati di Azure. Dopo un'interruzione simulata dei cluster primari e secondari, il client BCDR del servizio app si comporta come previsto.
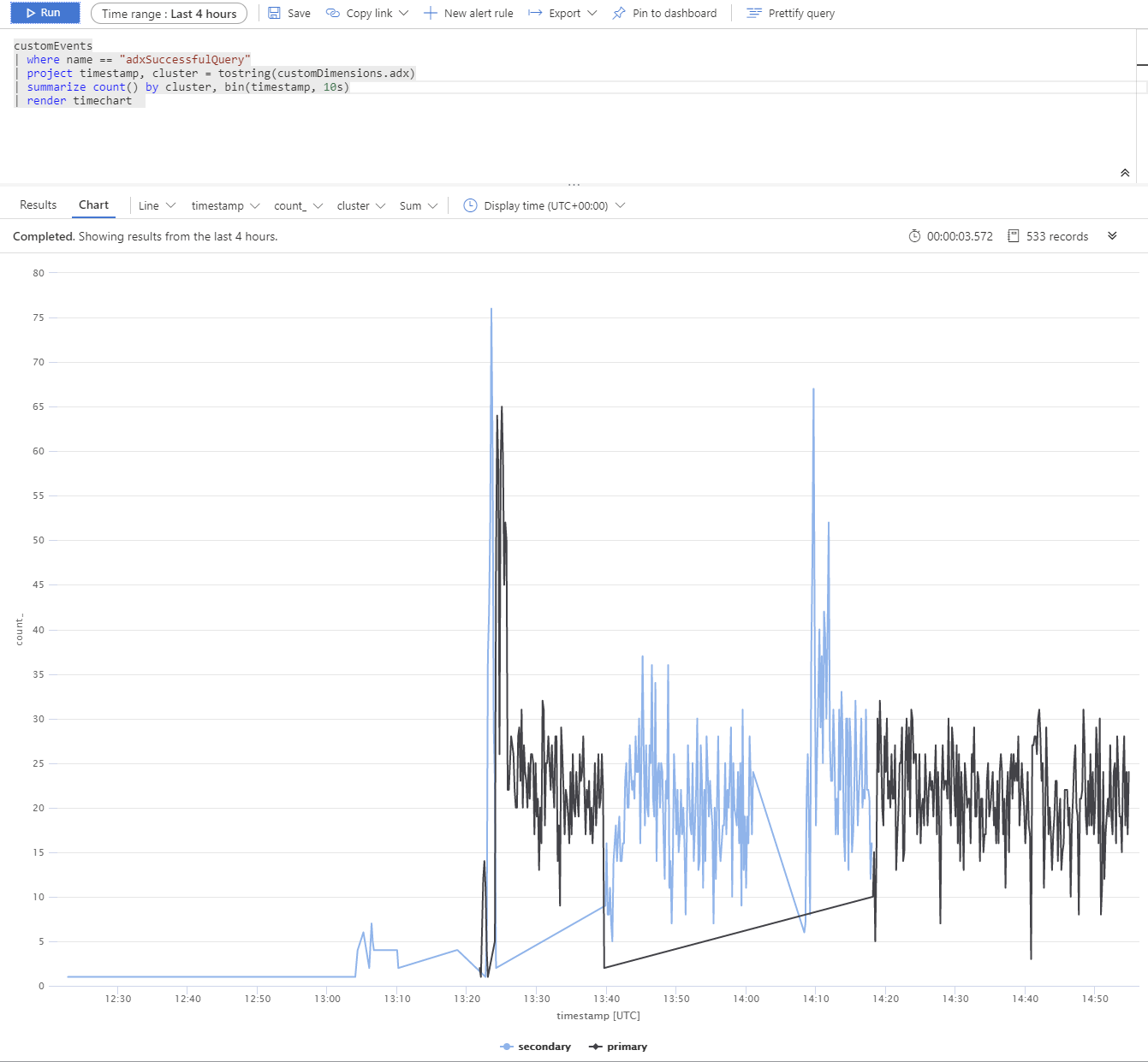
I cluster di Esplora dati di Azure sono distribuiti in West Europe (2 cluster primari D14v2), South East Asia ed East US (2 cluster D11v2).
Nota
I tempi di risposta più lenti sono dovuti a SKU diversi e a query tra pianeti diversi.
Eseguire il routing dinamico o statico
Usare Gestione traffico di Azure metodi di routing per il routing di richieste dinamiche o statiche. Gestione traffico di Azure è un servizio di bilanciamento del carico del traffico basato su DNS che è possibile usare per distribuire il traffico del servizio app. Questo traffico è ottimizzato per i servizi tra aree di Azure globali, offrendo al tempo stesso disponibilità elevata e velocità di risposta.
È anche possibile usare il routing basato su Frontdoor di Azure. Per un confronto tra questi due metodi, vedere Bilanciamento del carico con la suite di distribuzione di applicazioni di Azure.
Ottimizzare i costi in una configurazione attiva-attiva
L'uso di una configurazione attiva-attiva per il ripristino di emergenza aumenta il costo in modo lineare. Il costo include nodi, archiviazione, markup e costi di rete maggiori per la larghezza di banda.
Usare la scalabilità automatica ottimizzata per ottimizzare i costi
Usare la funzionalità di scalabilità automatica ottimizzata per configurare la scalabilità orizzontale per i cluster secondari. Dimensionare i cluster secondari per gestire il carico di acquisizione. Quando il cluster primario non è raggiungibile, i cluster secondari aumentano il traffico e la scalabilità in base alla configurazione.
In questo esempio, la scalabilità automatica ottimizzata consente di risparmiare circa 50% in termini di costi rispetto all'uso della stessa scala orizzontale e verticale in tutte le repliche.