Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo illustra come usare l'attività di copia nelle pipeline di Azure Data Factory e Synapse Analytics per copiare dati da Google BigQuery. Si basa sull'articolo di panoramica dell'attività di copia che presenta informazioni generali sull'attività di copia.
Importante
Il connettore Google BigQuery V1 è in fase di rimozione. È consigliabile aggiornare il connettore Google BigQuery da V1 a V2.
Funzionalità supportate
Questo connettore di Google BigQuery è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (fonte/-) | (1) (2) |
| Attività di ricerca | (1) (2) |
① Azure Integration Runtime ② Runtime di integrazione self-hosted
Per un elenco degli archivi dati supportati come origini o sink dall'attività di copia, vedere la tabella relativa agli archivi dati supportati.
Il servizio fornisce un driver predefinito per abilitare la connettività. Non è pertanto necessario installare manualmente un driver per usare questo connettore.
Note
Questo connettore Google BigQuery si basa sulle API BigQuery. Tenere presente che BigQuery limita la velocità massima delle richieste in arrivo e applica le quote appropriate in base al progetto: vedere la sezione Quotas & Limits - API requests (Limiti e quote - Richieste API). Assicurarsi di non attivare troppe richieste simultanee verso l'account.
Introduzione
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o degli SDK seguenti:
- Strumento Copia dati
- portale Azure
- .NET SDK
- Python SDK
- Azure PowerShell
- API REST
- modello Azure Resource Manager
Creare un servizio collegato a Google BigQuery usando l'interfaccia utente
Usare la procedura seguente per creare un servizio collegato a Google BigQuery nell'interfaccia utente del portale di Azure.
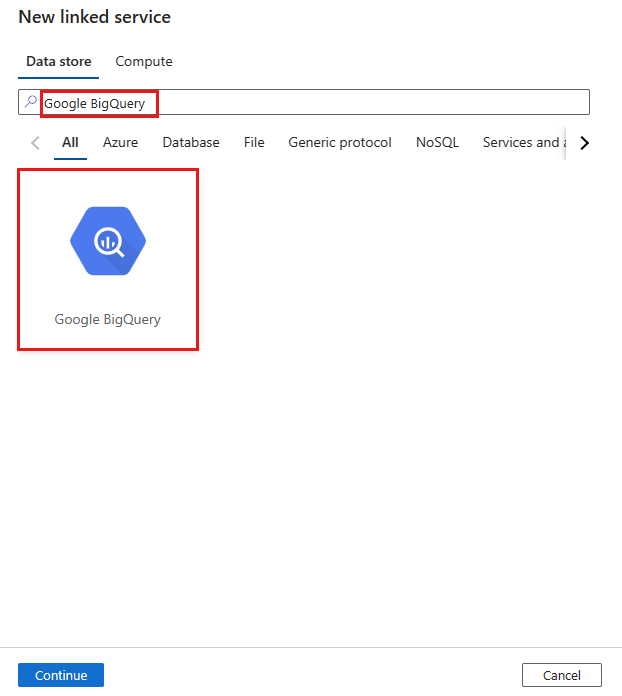
Passare alla scheda Gestisci nell'area di lavoro Azure Data Factory o Synapse e selezionare Servizi collegati, quindi fare clic su Nuovo:
Cercare Google BigQuery e selezionare il connettore.
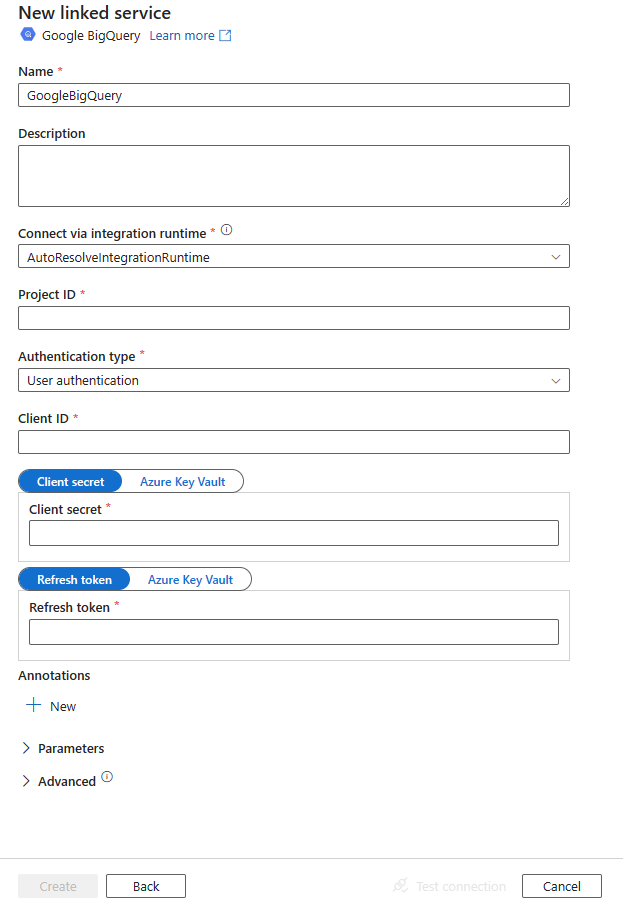
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
Dettagli di configurazione del connettore
Le sezioni seguenti riportano informazioni dettagliate sulle proprietà usate per definire entità specifiche per il connettore Google BigQuery.
Proprietà del servizio collegato
Per il servizio collegato Google BigQuery sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type deve essere impostata su GoogleBigQueryV2. | Sì |
| version | Versione specificata. È consigliabile eseguire l'aggiornamento alla versione più recente per sfruttare i miglioramenti più recenti. | Sì per la versione 1.1 |
| projectId | ID di progetto del progetto BigQuery su cui eseguire query. | Sì |
| tipo di autenticazione | Meccanismo di autenticazione OAuth 2.0 usato per l'autenticazione.
I valori consentiti sono UserAuthentication e ServiceAuthentication. Fare riferimento alle sezioni sotto questa tabella per altre proprietà e altri esempi JSON per questi tipi di autenticazione. |
Sì |
Uso dell'autenticazione utente
Impostare la proprietà "authenticationType" su UserAuthentication e specificare le proprietà seguenti insieme alle proprietà generiche descritte nella precedente sezione:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| ID cliente | ID dell'applicazione usata per generare il token di aggiornamento. | Sì |
| clientSecret | Segreto dell'applicazione usata per generare il token di aggiornamento. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o referenziare un segreto archiviato in Azure Key Vault. | Sì |
| refreshToken | Token di aggiornamento ottenuto da Google e usato per autorizzare l'accesso a BigQuery. Per informazioni su come ottenerne uno, vedere Obtaining OAuth 2.0 access tokens (Ottenere token di accesso OAuth 2.0) e questo blog della community. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o referenziare un segreto archiviato in Azure Key Vault. | Sì |
Esempio:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId" : "<project ID>",
"authenticationType" : "UserAuthentication",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value":"<client secret>"
},
"refreshToken": {
"type": "SecureString",
"value": "<refresh token>"
}
}
}
}
Uso dell'autenticazione del servizio
Impostare la proprietà "authenticationType" su ServiceAuthentication e specificare le proprietà seguenti insieme alle proprietà generiche descritte nella precedente sezione.
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| keyFileContent | File di chiave in formato JSON usato per autenticare l'account del servizio. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o referenziare un segreto archiviato in Azure Key Vault. | Sì |
Esempio:
{
"name": "GoogleBigQueryLinkedService",
"properties": {
"type": "GoogleBigQueryV2",
"version": "1.1",
"typeProperties": {
"projectId": "<project ID>",
"authenticationType": "ServiceAuthentication",
"keyFileContent": {
"type": "SecureString",
"value": "<key file JSON string>"
}
}
}
}
Proprietà del set di dati
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere l'articolo Set di dati. Questa sezione presenta un elenco delle proprietà supportate dal set di dati di Google BigQuery.
Per copiare dati da Google BigQuery, impostare la proprietà type del set di dati su GoogleBigQueryV2Object. Sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà tipo del set di dati deve essere impostata su: GoogleBigQueryV2Object | Sì |
| dataset | Nome del set di dati di Google BigQuery. | No (se nell'origine dell'attività è specificato "query") |
| tabella | Nome della tabella. | No (se nell'origine dell'attività è specificato "query") |
Esempio
{
"name": "GoogleBigQueryDataset",
"properties": {
"type": "GoogleBigQueryV2Object",
"linkedServiceName": {
"referenceName": "<Google BigQuery linked service name>",
"type": "LinkedServiceReference"
},
"schema": [],
"typeProperties": {
"dataset": "<dataset name>",
"table": "<table name>"
}
}
}
Proprietà dell'attività di copia
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere l'articolo sulle pipeline. Questa sezione presenta un elenco delle proprietà supportate dal tipo di origine Google BigQuery.
GoogleBigQuerySource come tipo di origine
Per copiare dati da Google BigQuery, impostare il tipo di origine nell'attività di copia su GoogleBigQueryV2Source. Nella sezione source dell'attività di copia sono supportate le proprietà seguenti.
| Proprietà | Descrizione | Obbligatoria |
|---|---|---|
| tipo | La proprietà type dell'origine dell'attività di copia deve essere impostata su GoogleBigQueryV2Source. | Sì |
| quesito | Usare la query SQL personalizzata per leggere i dati. Un esempio è "SELECT * FROM MyTable". Per altre informazioni, vedere Sintassi di query. |
No (se sono specificati "dataset" e "table" nel set di dati) |
Esempio:
"activities":[
{
"name": "CopyFromGoogleBigQuery",
"type": "Copy",
"inputs": [
{
"referenceName": "<Google BigQuery input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "GoogleBigQueryV2Source",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mapping dei tipi di dati per Google BigQuery V2
Quando si copiano dati da Google BigQuery, vengono usati i seguenti mapping dai tipi di dati di Google BigQuery ai tipi di dati provvisori all'interno del servizio. Per informazioni su come l'attività di copia esegue il mapping dello schema di origine e del tipo di dati al sink, vedere Mapping dello schema e del tipo di dati.
| Tipo di dati Google BigQuery | Tipo di dati provvisorio del servizio |
|---|---|
| JSON | String |
| STRING | String |
| BYTES | Matrice di byte |
| INTEGER | Int64 |
| FLOAT | Double |
| NUMERICO | Decimal |
| BIGNUMERIC | String |
| BOOLEAN | Boolean |
| TIMESTAMP | DateTimeOffset |
| DATTERO | Data e ora |
| TEMPO | TimeSpan |
| DATETIME | DateTimeOffset |
| GEOGRAFIA | String |
| RECORD/STRUCT | String |
| ARRAY | String |
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Ciclo di vita e aggiornamento del connettore Google BigQuery
La tabella seguente illustra la fase di rilascio e i log delle modifiche per versioni diverse del connettore Google BigQuery:
| Versione | Fase di rilascio | Log delle modifiche |
|---|---|---|
| Google BigQuery V1 | Removed | Non applicabile. |
| Google BigQuery V2 (versione 1.0) | Versione GA disponibile | • L'autenticazione del servizio è supportata dal runtime di integrazione Azure e dal runtime di integrazione self-hosted. Le proprietà trustedCertPath, useSystemTrustStoreemail e keyFilePath non sono supportate perché sono disponibili solo nel runtime di integrazione self-hosted. • requestGoogleDriveScope non è supportato. È inoltre necessario applicare l'autorizzazione nel servizio Google BigQuery facendo riferimento a Scegliere ambiti dell'API Google Drive e Dati di Query Drive. • additionalProjects non è supportato. In alternativa, eseguire una query su un set di dati pubblico con la console di Google Cloud.• NUMBER viene letto come tipo di dati Decimal. • Timestamp e Datetime vengono letti come tipo di dati DateTimeOffset. |
| Google BigQuery V2 (versione 1.1) | Versione GA disponibile | • Correzione di un bug: quando si eseguono più istruzioni, l'oggetto query restituisce ora i risultati della prima istruzione dopo l'esclusione delle istruzioni di valutazione, anziché restituire sempre il risultato della prima istruzione. |
Aggiornare il connettore Google BigQuery
Per aggiornare il connettore Google BigQuery:
Da V1 a V2:
Creare un nuovo servizio collegato Google BigQuery e configurarlo facendo riferimento alle proprietà del servizio collegato.Dalla versione V2 1.0 alla versione 1.1:
Nella pagina Modifica servizio collegato selezionare 1.1 per la versione. Per altre informazioni, vedere Proprietà del servizio collegato.
Contenuti correlati
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.