Creare una connessione dati di Hub eventi per Azure Esplora dati
Azure Esplora dati offre l'inserimento da Hub eventi, una piattaforma di streaming Big Data e un servizio di inserimento eventi. Hub eventi può elaborare milioni di eventi al secondo in tempo quasi reale.
In questo articolo si connette a un hub eventi e si inseriscono dati in Azure Esplora dati. Per una panoramica sull'inserimento da Hub eventi, vedere Hub eventi di Azure connessione dati.
Per informazioni su come creare la connessione usando gli SDK Kusto, vedere Creare una connessione dati di Hub eventi con gli SDK.
Per esempi di codice basati sulle versioni precedenti di SDK, vedere l'articolo archiviato.
Creare una connessione dati dell'hub eventi
In questa sezione viene stabilita una connessione tra l'hub eventi e la tabella di Esplora dati di Azure. Purché questa connessione sia presente, i dati vengono trasmessi dall'hub eventi nella tabella di destinazione. Se l'hub eventi viene spostato in una risorsa o una sottoscrizione diversa, è necessario aggiornare o ricreare la connessione.
- Recuperare i dati
- Portale - Pagina Esplora dati di Azure
- Portale - pagina Hub eventi di Azure
- Modello ARM
Prerequisiti
- Un account Microsoft o un'identità utente di Microsoft Entra. Non è necessaria una sottoscrizione di Azure.
- Un cluster e un database di Esplora dati di Azure. Creare un cluster e un database.
- L'inserimento di streaming deve essere configurato nel cluster di Esplora dati di Azure.
Recuperare i dati
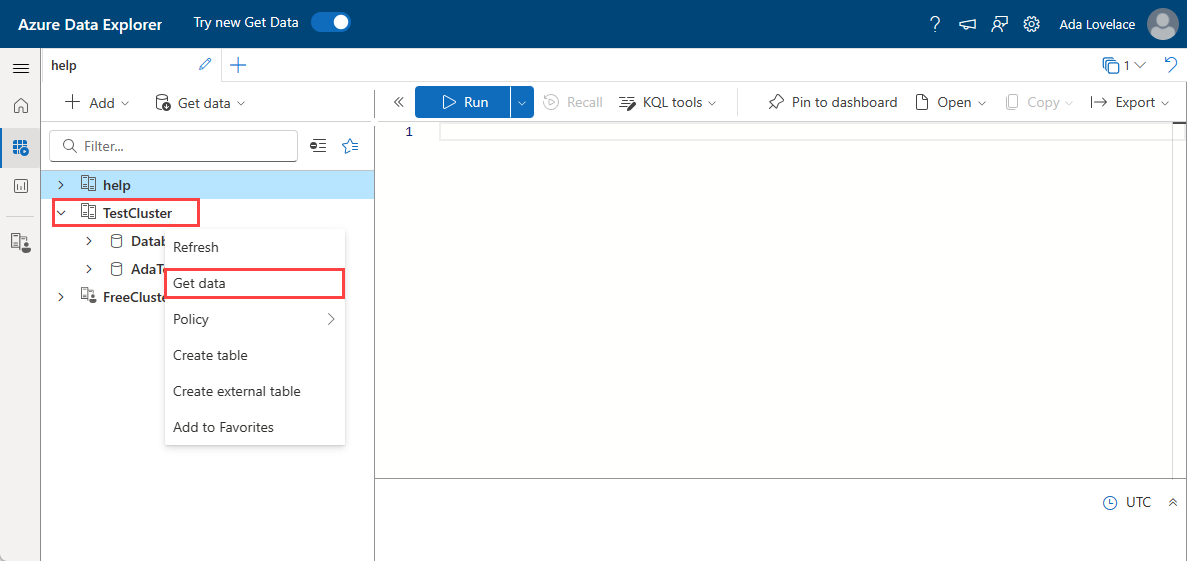
Dal menu a sinistra selezionare Query.
Fare clic con il pulsante destro del mouse sul database in cui si desidera inserire i dati. Selezionare Recupera dati.

Source
Nella finestra Recupera dati selezionare la scheda Origine .
Selezionare l'origine dati dall'elenco disponibile. In questo esempio si inseriscono dati da Hub eventi.

Configurare
Selezionare un database di destinazione e una tabella. Se si desidera inserire dati in una nuova tabella, selezionare + Nuova tabella e immettere un nome di tabella.
Nota
I nomi delle tabelle possono essere fino a 1024 caratteri, inclusi spazi, alfanumerici, trattini e caratteri di sottolineatura. I caratteri speciali non sono supportati.
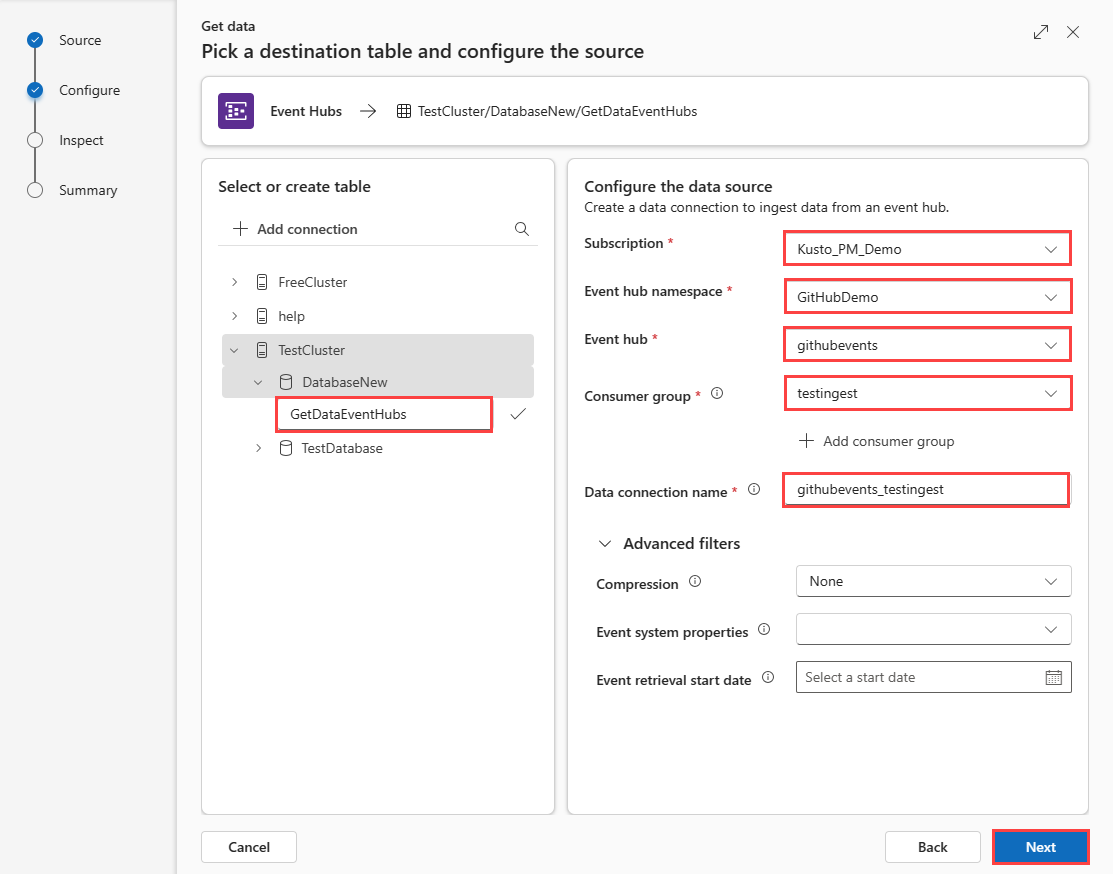
Compilare i campi seguenti:
Impostazione Descrizione campo Subscription ID sottoscrizione in cui si trova la risorsa dell'hub eventi. Spazio dei nomi dell'hub eventi Nome che identifica lo spazio dei nomi. Hub eventi Hub eventi che si desidera Gruppo di consumer Gruppo di consumer definito nell'evento Data connection name (Nome connessione dati) Nome che identifica la connessione dati. Filtri avanzati Compressione Tipo di compressione del payload dei messaggi dell'hub eventi. Proprietà del sistema per gli eventi Proprietà del sistema dell'hub eventi. Se sono presenti più record per ogni messaggio di evento, le proprietà di sistema vengono aggiunte alla prima. Quando si aggiungono proprietà del sistema, creare o aggiornare lo schema e il mapping della tabella per includere le proprietà selezionate. Data di inizio recupero eventi La connessione dati recupera gli eventi di Hub eventi esistenti creati dopo la data di inizio del recupero eventi. È possibile recuperare solo gli eventi conservati dal periodo di conservazione di Hub eventi. Se la data di inizio del recupero eventi non è specificata, l'ora predefinita è l'ora in cui viene creata la connessione dati. Selezionare Avanti

Controllare
Verrà visualizzata la scheda Controlla con un'anteprima dei dati.
Per completare il processo di inserimento, selezionare Fine.

Facoltativamente:
Se i dati visualizzati nella finestra di anteprima non sono completati, potrebbero essere necessari altri dati per creare una tabella con tutti i campi dati necessari. Usare i comandi seguenti per recuperare nuovi dati dall'hub eventi:
Eliminare e recuperare nuovi dati: elimina i dati presentati e cerca nuovi eventi.
Recuperare altri dati: cerca altri eventi oltre agli eventi già trovati.
Nota
Per visualizzare un'anteprima dei dati, l'hub eventi deve inviare eventi.
Selezionare Visualizzatore comandi per visualizzare e copiare i comandi automatici generati dagli input.
Usare l'elenco a discesa File di definizione schema per modificare il file da cui viene dedotto lo schema.
Modificare il formato dati dedotto automaticamente selezionando il formato desiderato dall'elenco a discesa. Per l'inserimento, vedere Formati di dati supportati da Azure Esplora dati.
Esplorare le opzioni avanzate in base al tipo di dati.
Modifica colonne
Nota
- Per i formati tabulari (CSV, TSV, PSV), non è possibile eseguire il mapping di una colonna due volte. Per eseguire il mapping a una colonna esistente, eliminare prima quella nuova.
- Non è possibile modificare un tipo di colonna esistente. Se si tenta di eseguire il mapping a una colonna con un formato diverso, è possibile che si verifichino colonne vuote.
Le modifiche che è possibile apportare in una tabella dipendono dai parametri seguenti:
- Il tipo di tabella è nuovo o esistente
- Il tipo di mapping è nuovo o esistente
| Tipo di tabella. | Tipo di mapping | Modifiche disponibili |
|---|---|---|
| Nuova tabella | Nuovo mapping | Rinominare la colonna, modificare il tipo di dati, modificare l'origine dati, la trasformazione mapping, aggiungere colonna, eliminare la colonna |
| Tabella esistente | Nuovo mapping | Aggiungere colonna (in cui è possibile modificare il tipo di dati, rinominare e aggiornare) |
| Tabella esistente | Mapping esistente | Nessuno |

Trasformazioni del mapping
Alcuni mapping del formato dati (Parquet, JSON e Avro) supportano semplici trasformazioni in fase di inserimento. Per applicare trasformazioni di mapping, creare o aggiornare una colonna nella finestra Modifica colonne .
Le trasformazioni di mapping possono essere eseguite su una colonna di tipo string o datetime, con l'origine con tipo di dati int o long. Le trasformazioni del mapping supportate sono:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opzioni avanzate basate sul tipo di dati
Tabulare (CSV, TSV, PSV):Tabular (CSV, TSV, PSV):Tabular (CSV, TSV, PSV):
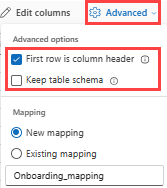
Se si inseriscono formati tabulari in una tabella esistente, è possibile selezionare Avanzate>Mantieni schema di tabella corrente. I dati tabulari non includono necessariamente i nomi di colonna usati per eseguire il mapping dei dati di origine alle colonne esistenti. Quando questa opzione viene selezionata, il mapping viene eseguito in base all'ordine e lo schema della tabella rimane invariato. Se questa opzione è deselezionata, vengono create nuove colonne per i dati in ingresso, indipendentemente dalla struttura dei dati.
Per usare la prima riga come nomi di colonna, selezionare Advanced First row is column header .To use the first row as column names, select Advanced>First row is column header.
JSON:
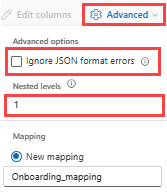
Per determinare la divisione delle colonne dei dati JSON, selezionare Livelliannidati avanzati>, da 1 a 100.
Se si seleziona Ignoraerrori di formato datiavanzati>, i dati vengono inseriti in formato JSON. Se si lascia deselezionata questa casella di controllo, i dati vengono inseriti in formato multijson.
Riepilogo
Nella finestra Preparazione dati tutti e tre i passaggi vengono contrassegnati con segni di spunta verdi al termine dell'inserimento dati. È possibile visualizzare i comandi usati per ogni passaggio oppure selezionare una scheda per eseguire query, visualizzare o eliminare i dati inseriti.



Rimuovere una connessione dati dell'hub eventi
Rimuovere la connessione dati tramite la portale di Azure come illustrato nella scheda portale.
Contenuti correlati
- Controllare la connessione con l'app di messaggio di esempio dell'hub eventi
- Eseguire query sui dati nell'interfaccia utente Web