Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Panoramica
Azure Data Factory e la modalità di debug del flusso di dati di mapping di Synapse Analytics consentono di controllare in modo interattivo la trasformazione della forma di dati durante la compilazione e il debug dei flussi di dati. La sessione di debug può essere usata sia nelle sessioni di progettazione Flusso di dati che durante l'esecuzione del debug della pipeline dei flussi di dati. Per attivare la modalità di debug, utilizzare il pulsante Flusso di dati Debug nella barra superiore dell'area di lavoro del flusso di dati o dell'area di lavoro della pipeline quando sono presenti attività di flusso di dati.
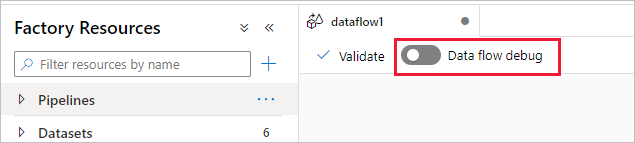

Dopo aver attivato il cursore, verrà richiesto di selezionare la configurazione del runtime di integrazione da usare. Se si seleziona AutoResolveIntegrationRuntime, verrà generato un cluster con otto core di calcolo generale con tempo predefinito di 60 minuti. Se si vuole consentire più team inattivi prima del timeout della sessione, è possibile scegliere un'impostazione TTL superiore. Per altre informazioni sui runtime di integrazione del flusso di dati, vedere prestazioni del runtime di integrazione.
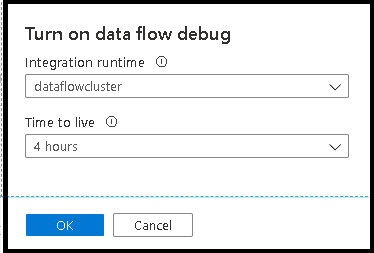
Quando la modalità debug è attivata, si creerà in modo interattivo il flusso di dati con un cluster Spark attivo. La sessione viene chiusa una volta disattivato il debug. È necessario tenere presenti gli addebiti orari sostenuti da Data Factory durante il tempo in cui è attivata la sessione di debug.
Nella maggior parte dei casi, è consigliabile compilare i Flusso di dati in modalità di debug in modo da poter convalidare la logica di business e visualizzare le trasformazioni dei dati prima di pubblicare il lavoro. Usare il pulsante "Debug" nel pannello della pipeline per testare il flusso di dati in una pipeline.
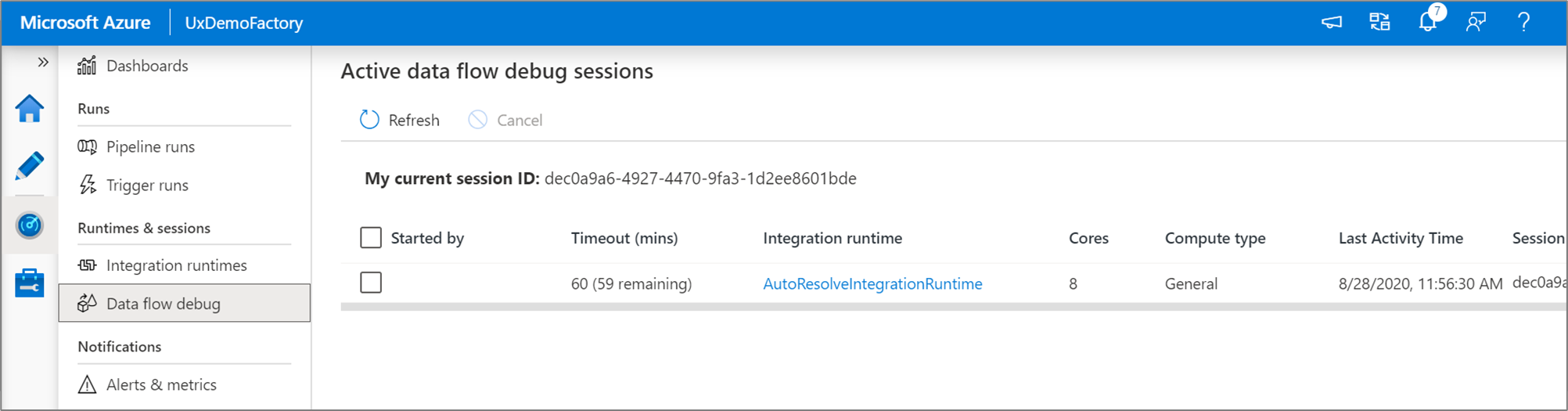
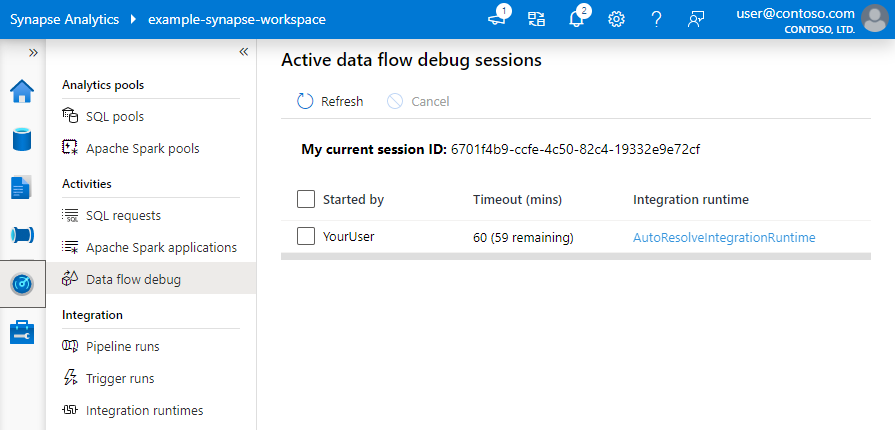
Nota
Ogni sessione di debug avviata dall'interfaccia utente del browser è una nuova sessione con il proprio cluster Spark. È possibile usare la visualizzazione di monitoraggio per le sessioni di debug visualizzate nelle immagini precedenti per visualizzare e gestire le sessioni di debug. Ti viene addebitato un costo per ogni ora in cui viene eseguita una sessione di debug, incluso il tempo di TTL.
Questo clip video illustra suggerimenti, consigli e procedure consigliate per la modalità di debug del flusso di dati.
Stato del cluster
L'indicatore di stato del cluster nella parte superiore dell'area di progettazione diventa verde quando il cluster è pronto per il debug. Se il cluster è già caldo, l'indicatore verde viene visualizzato quasi immediatamente. Se il cluster non era già in esecuzione quando è stata attivata la modalità di debug, il cluster Spark esegue un avvio a freddo. L'indicatore ruota fino a quando l'ambiente non è pronto per il debug interattivo.
Al termine del debug, disattivare l'opzione Debug in modo che il cluster Spark possa terminare e non verrà più addebitato alcun costo per l'attività di debug.
Impostazioni di debug
Dopo aver attivato la modalità di debug, è possibile modificare la modalità di anteprima dei dati di un flusso di dati. È possibile modificare le impostazioni di debug facendo clic su "Impostazioni di debug" sulla barra degli strumenti Flusso di dati canvas. È possibile selezionare il limite di riga o l'origine file da usare per ognuna delle trasformazioni di origine qui. I limiti di riga in questa impostazione sono solo per la sessione di debug corrente. È anche possibile selezionare il servizio collegato di staging da utilizzare con un'origine di Azure Synapse Analytics.
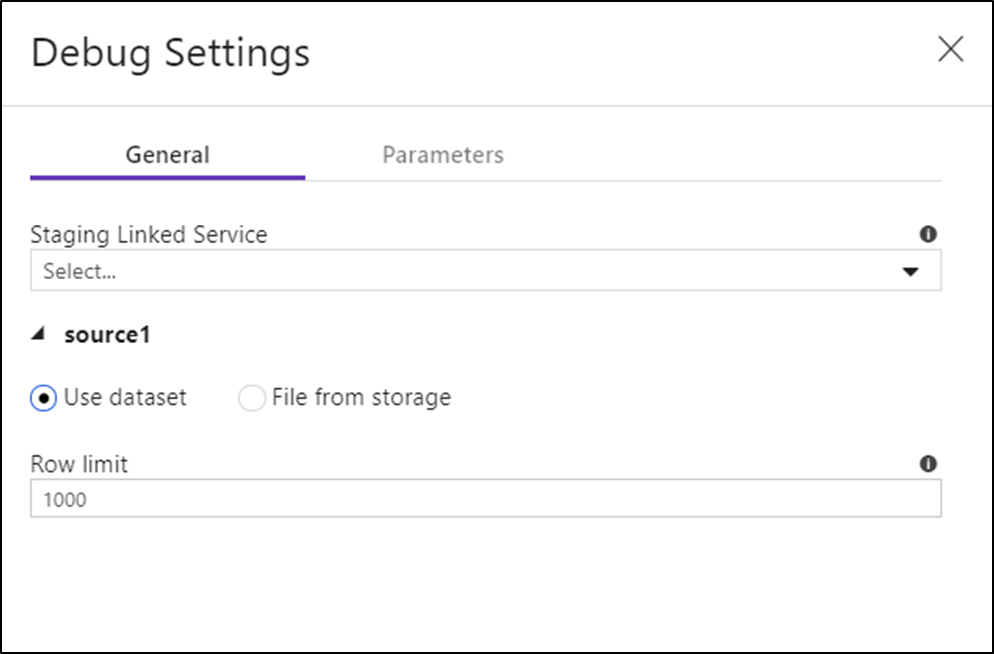
Se sono presenti parametri nel Flusso di dati o in uno dei relativi set di dati a cui si fa riferimento, è possibile specificare i valori da usare durante il debug selezionando la scheda Parameters.
Usare le impostazioni di campionamento qui per puntare a file di esempio o tabelle di dati di esempio in modo da non dover modificare i set di dati di origine. Usando un file o una tabella di esempio, è possibile gestire le stesse impostazioni di logica e proprietà nel flusso di dati durante il test su un subset di dati.
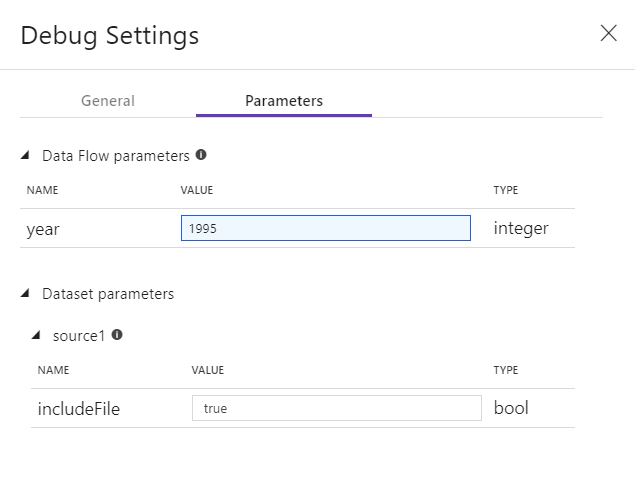
Il runtime di integrazione (IR) predefinito usato per la modalità di debug nei flussi di dati consiste in un piccolo nodo di lavoro singolo a 4 core e un nodo driver singolo a 4 core. Questa operazione funziona correttamente con campioni di dati più piccoli durante il test della logica del flusso di dati. Se si espandono i limiti di riga nelle impostazioni di debug durante l'anteprima dei dati o si imposta un numero maggiore di righe campionate nell'origine durante il debug della pipeline, è consigliabile impostare un ambiente di calcolo di dimensioni maggiori in un nuovo Azure Integration Runtime. È quindi possibile riavviare la sessione di debug usando l'ambiente di calcolo più ampio.
Anteprima dati
Con il debug attivato, la scheda Anteprima dati si accende nel pannello inferiore. Senza la modalità di debug attivata, Flusso di dati mostra solo i metadati correnti all'interno e all'esterno di ognuna delle trasformazioni nella scheda Ispeziona. L'anteprima dei dati eseguirà una query solo sul numero di righe impostate come limite nelle impostazioni di debug. Selezionare Aggiorna per aggiornare l'anteprima dei dati in base alle trasformazioni correnti. Se i dati di origine sono stati modificati, selezionare l'opzione Aggiorna > Ricarica dall'origine.
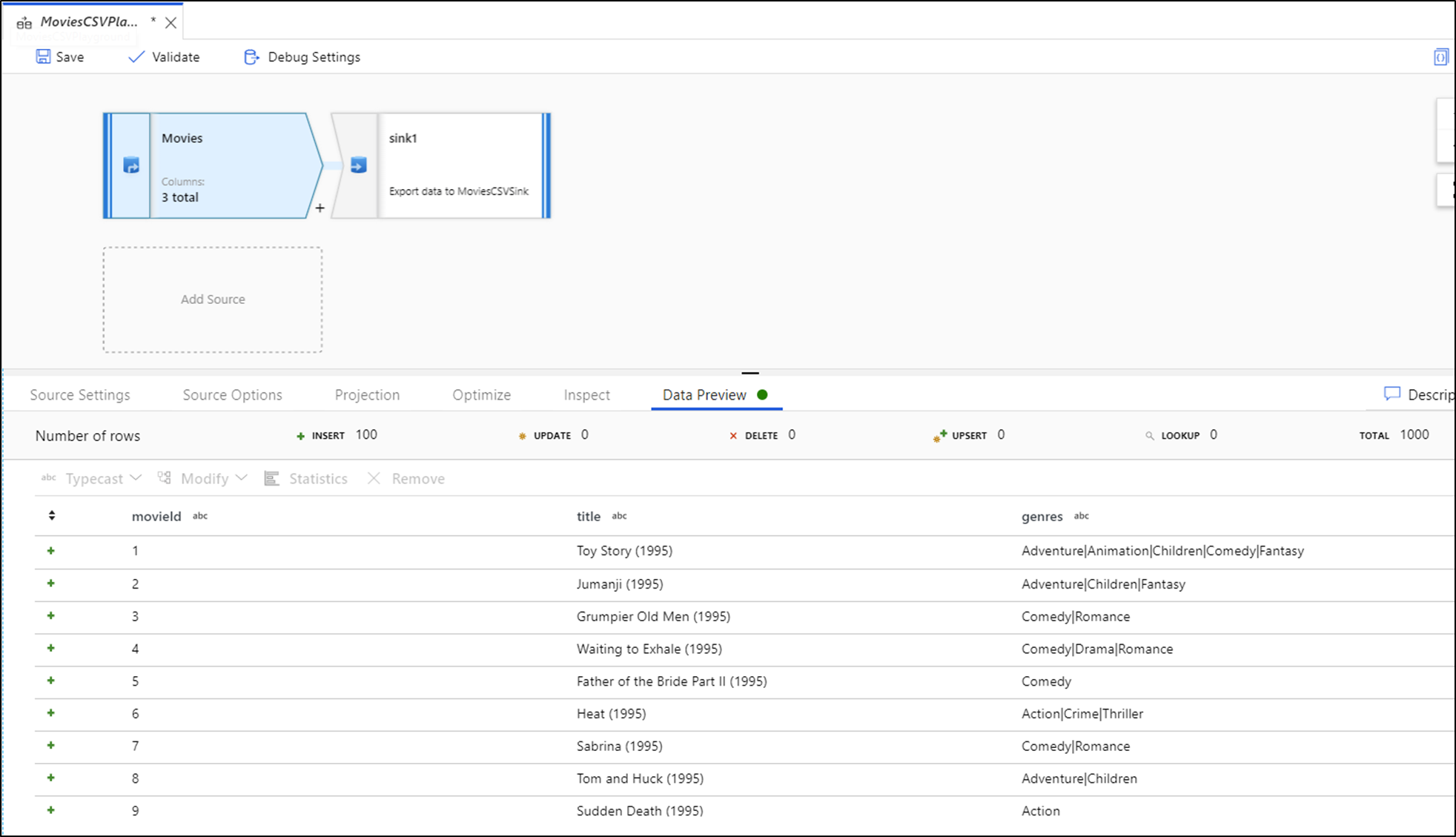
È possibile ordinare le colonne nell'anteprima dei dati e ridisporre le colonne tramite trascinamento. È anche disponibile un pulsante di esportazione nella parte superiore del pannello di anteprima dei dati che è possibile usare per esportare i dati di anteprima in un file CSV per l'esplorazione dei dati offline. È possibile usare questa funzionalità per esportare fino a 1.000 righe di dati di anteprima.
Nota
Le fonti di file limitano solo le righe visualizzate, non le righe lette. Per i set di dati molto grandi, è consigliabile prendere una piccola parte di tale file e usarla per i test. È possibile selezionare un file temporaneo in Impostazioni di debug per ogni origine che è un tipo di set di dati di file.
Quando si esegue Flusso di dati in modalità debug, i dati non verranno scritti nella trasformazione Sink. Una sessione di debug è destinata a fungere da test harness per le trasformazioni. I sink non sono necessari durante il debug e vengono ignorati nel flusso di dati. Se si vuole testare la scrittura di dati nel sink, eseguire il flusso di dati da una pipeline e usare l'esecuzione di debug dalla pipeline.
L'anteprima dei dati è un'istantanea dei dati trasformati usando limiti di riga e campionamento dei dati dai data frame nella memoria di Spark. Pertanto, i driver sink non vengono utilizzati né testati in questo scenario.
Nota
Anteprima dati visualizza l'ora in base alle impostazioni locali del browser.
Test delle condizioni di join
Durante il test unitario di trasformazioni Join, Exists o Lookup, assicurati di utilizzare un piccolo insieme di dati noti per il proprio test. È possibile usare l'opzione Impostazioni di debug descritta in precedenza per impostare un file temporaneo da usare per il test. Ciò è necessario perché quando si limitano o si campionano righe da un set di dati di grandi dimensioni, non è possibile stimare quali righe e quali chiavi vengono lette nel flusso per il test. Il risultato è non deterministico, vale a dire che le condizioni di unione potrebbero fallire.
Azioni rapide
Dopo aver visualizzato l'anteprima dei dati, è possibile generare una trasformazione rapida per typecast, rimuovere o eseguire una modifica in una colonna. Selezionare l'intestazione di colonna e quindi selezionare una delle opzioni nella barra degli strumenti dell'anteprima dei dati.
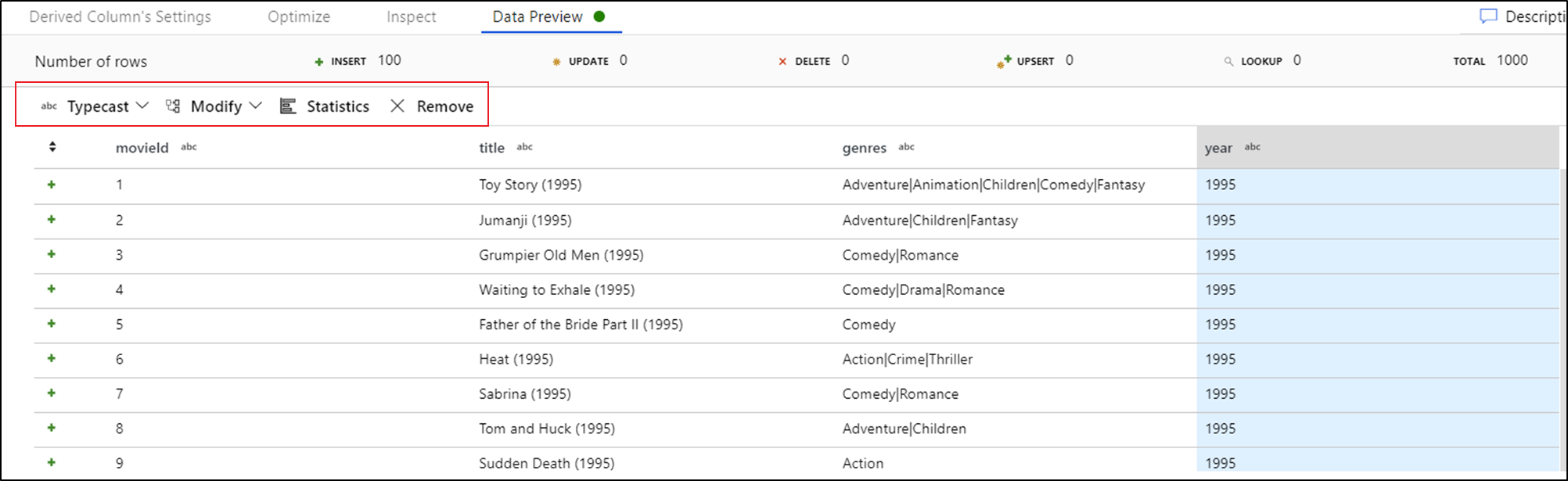
Dopo aver selezionato una modifica, l'anteprima dei dati verrà immediatamente aggiornata. Selezionare Conferma nell'angolo superiore destro per generare una nuova trasformazione.
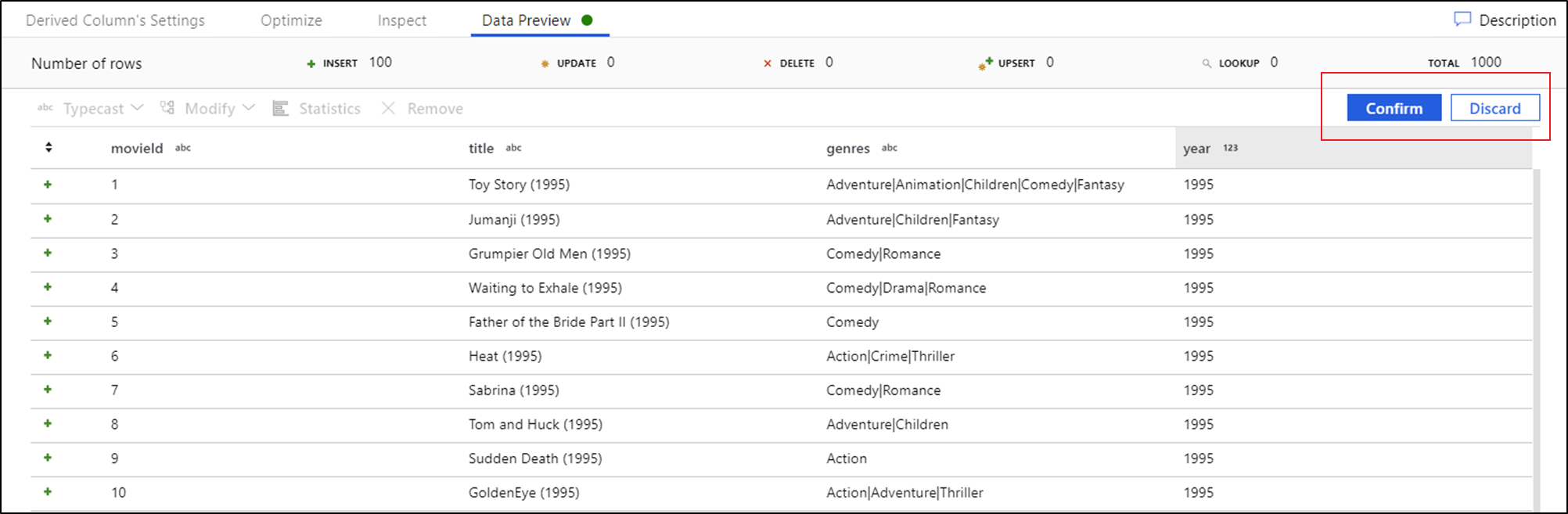
Typecast e Modify genera una trasformazione Colonna derivata e Rimuovi genera una trasformazione Select.
Nota
Se si modifica il Flusso di dati, è necessario recuperare nuovamente l'anteprima dei dati prima di aggiungere una trasformazione rapida.
Profiling dei dati
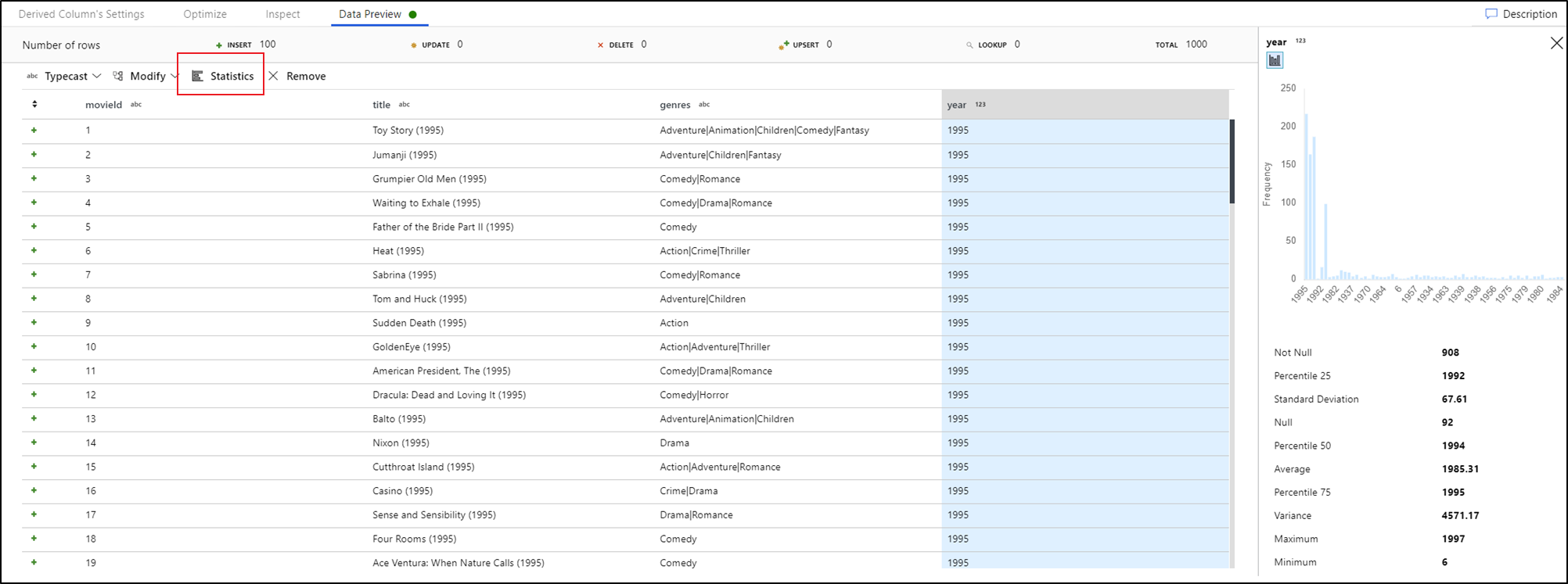
Selezionando una colonna nella scheda anteprima dei dati e facendo clic su Statistiche nella barra degli strumenti dell'anteprima dei dati viene visualizzato un grafico all'estrema destra della griglia dati con statistiche dettagliate su ogni campo. Il servizio esegue una determinazione in base al campionamento dei dati di quale tipo di grafico visualizzare. Per impostazione predefinita, i campi con cardinalità elevata sono grafici NULL/NOT NULL, mentre i dati categorici e numerici con cardinalità bassa visualizzano grafici a barre che mostrano la frequenza dei valori dei dati. Viene inoltre visualizzata la lunghezza massima/len dei campi stringa, i valori min/max nei campi numerici, lo sviluppo standard, i percentili, i conteggi e la media.
Contenuto correlato
- Al termine della compilazione e del debug del flusso di dati, eseguilo da una pipeline.
- Quando si testa una pipeline con un flusso di dati, usare l'opzione di esecuzione Debug della pipeline .