Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Azure Data Factory e Synapse Analytics supportano lo sviluppo iterativo e il debug delle pipeline. Queste funzionalità consentono di testare le modifiche prima di creare una richiesta pull o pubblicarle nel servizio.
Per un'introduzione di otto minuti e una dimostrazione di questa funzionalità, guardare il video seguente:
Debug di una pipeline
Quando si lavora con il canvas della pipeline, è possibile testare le attività usando la capacità di Debug. Quando si esegue il test, non è necessario pubblicare le modifiche nel servizio prima di selezionare Debug. Questa funzionalità è utile negli scenari in cui si vuole assicurarsi che le modifiche funzionino come previsto prima di aggiornare il flusso di lavoro.
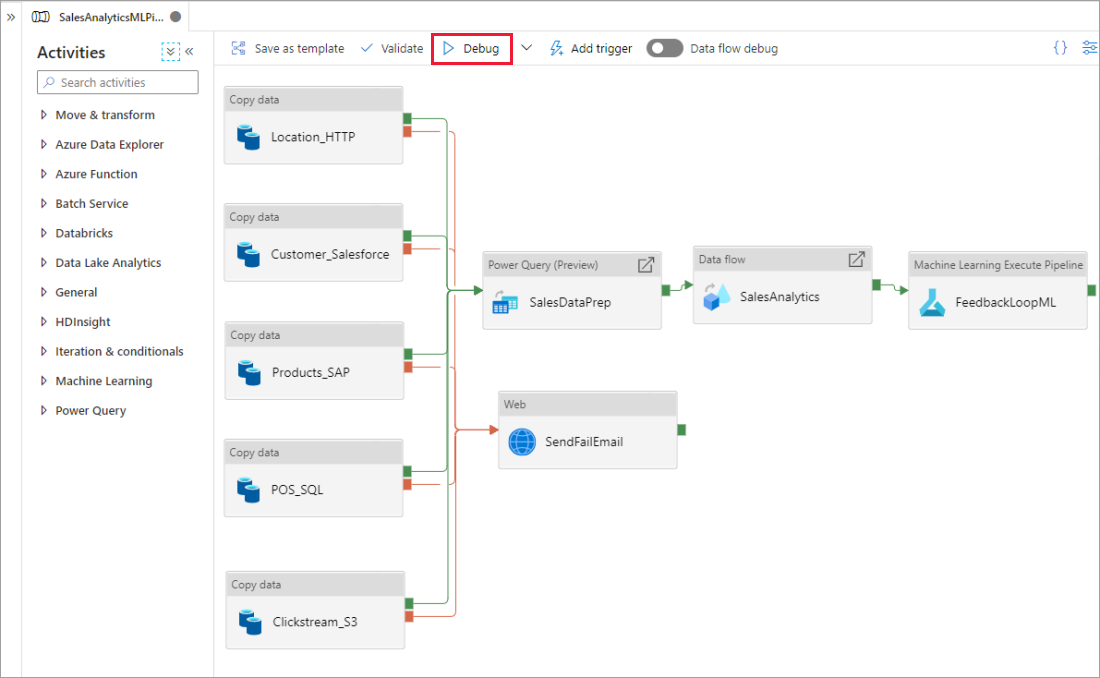
Quando la pipeline è in esecuzione, è possibile visualizzare i risultati di ogni attività nella scheda Output dell'area di disegno della pipeline.
Visualizzare i risultati dell'esecuzione dei test nella finestra Output del canvas della pipeline.
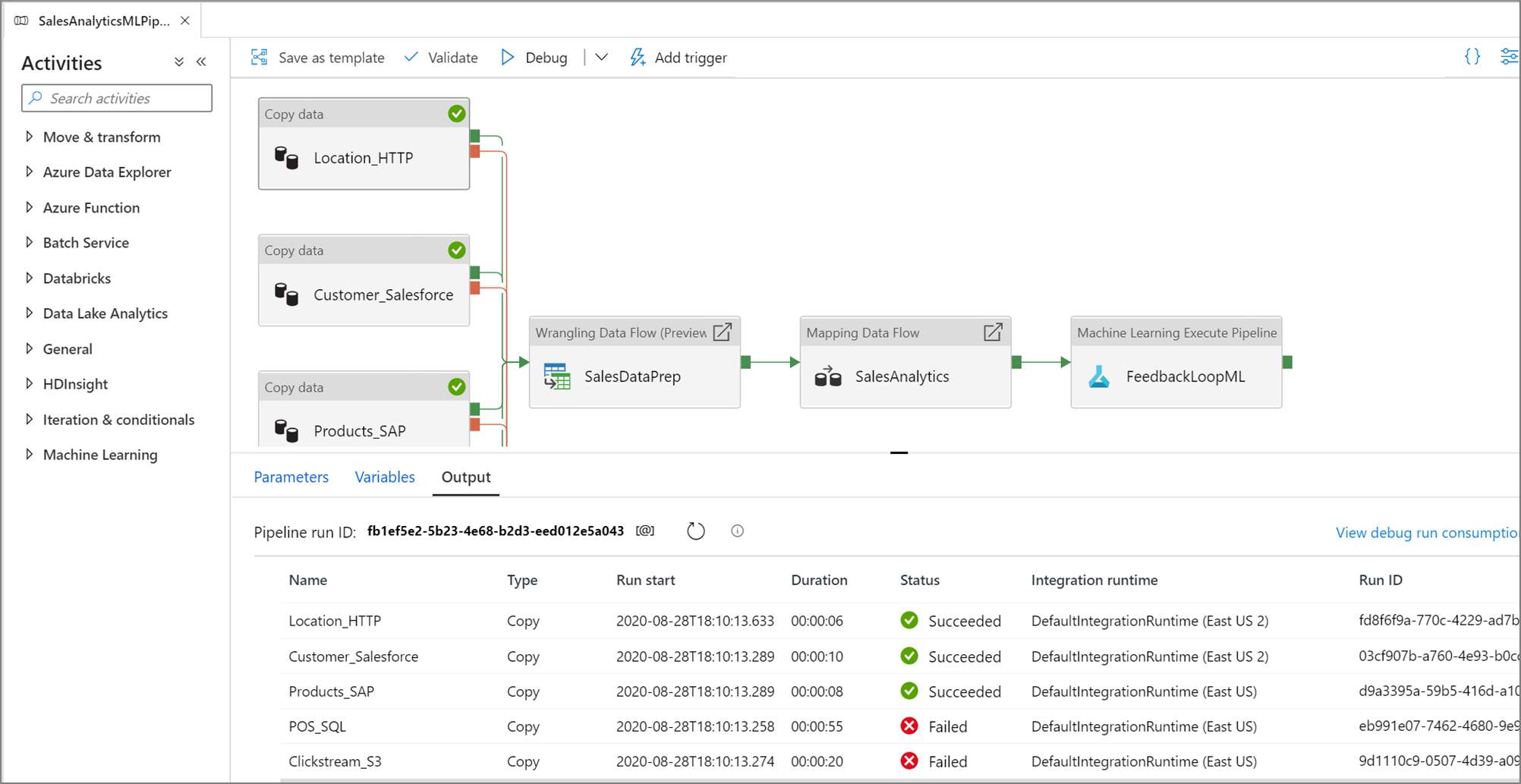
Quando un'esecuzione dei test ha esito positivo, aggiungere altre attività alla pipeline e continuare il debug in modo iterativo. È anche possibile annullare un'esecuzione dei test in corso.
Importante
Selezionando Debug la pipeline viene effettivamente eseguita. Ad esempio, se la pipeline contiene attività di copia, l'esecuzione del test copia i dati dall'origine alla destinazione. Di conseguenza, durante il debug è consigliabile usare cartelle di test nelle attività di copia e in altre attività. Dopo aver eseguito il debug della pipeline, passare alle cartelle che desideri utilizzare nelle operazioni normali.
Impostazione dei punti di interruzione
Il servizio consente di eseguire il debug di una pipeline fino a raggiungere una determinata attività nell'area di disegno della pipeline. Inserire un punto di interruzione nell'attività che si desidera testare e selezionare Debug. Il servizio esegue i test solo fino all'attività con il punto di interruzione nel canvas della pipeline. Questa funzionalità Debug Until è utile quando non vuoi testare l'intera pipeline, ma solo un subset di azioni specifiche nella pipeline.
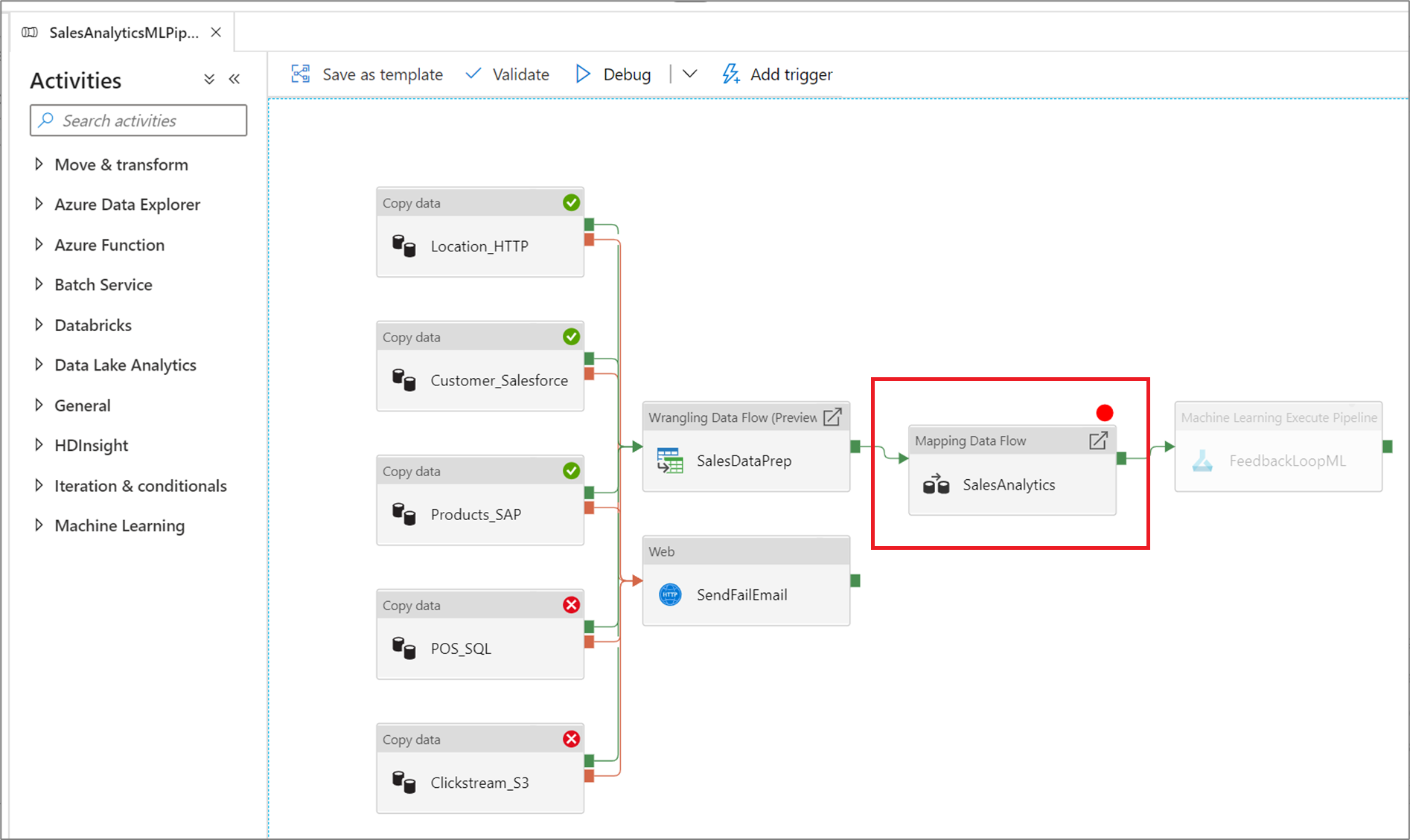
Per impostare un punto di interruzione, selezionare un elemento nel canvas della pipeline. L'opzione Debug fino a viene visualizzata sotto forma di cerchio rosso vuoto nell'angolo in alto a destra dell'elemento.
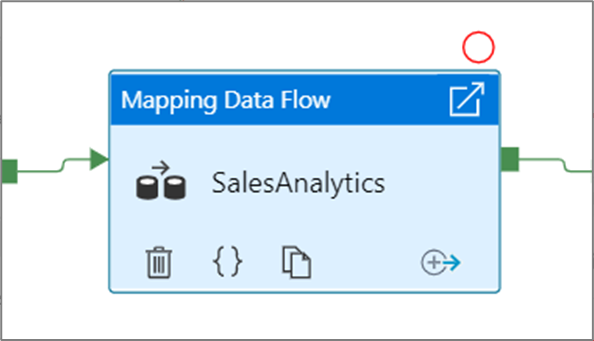
Dopo avere selezionato l'opzione Debug fino a, questa diventa un cerchio rosso pieno per indicare che il punto di interruzione è abilitato.
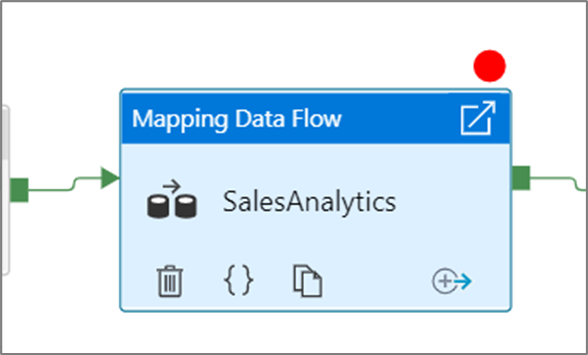
Esegue il monitoraggio delle esecuzioni di debug
Quando si esegue un'esecuzione di debug della pipeline, i risultati verranno visualizzati nella finestra Output dell'area di disegno della pipeline. La scheda di output conterrà solo l'esecuzione più recente che si è verificata durante la sessione del browser corrente.
Per visualizzare una visualizzazione cronologica delle esecuzioni di debug o visualizzare un elenco di tutte le esecuzioni di debug attive, è possibile passare all'esperienza monitoraggio .
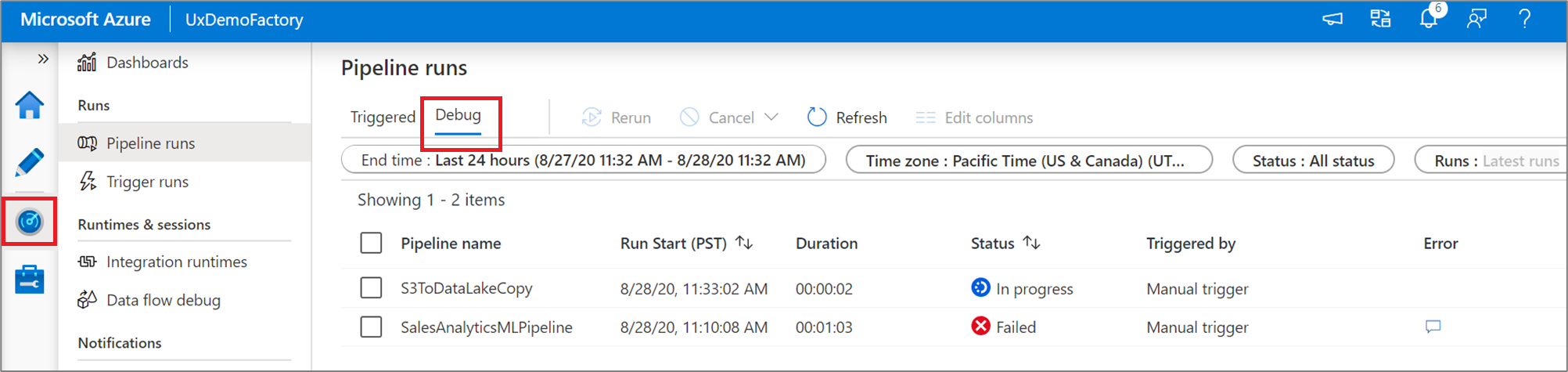
Nota
Il servizio mantiene la cronologia di esecuzione del debug solo per 15 giorni.
Debug dei flussi di dati per mapping
I flussi di dati di mapping consentono di creare una logica di trasformazione dei dati priva di codice che viene eseguita su larga scala. Durante la compilazione della logica, è possibile attivare una sessione di debug per usare in modo interattivo i dati con un cluster Spark attivo. Per altre informazioni, vedere Modalità di debug del flusso di dati per mapping.
È possibile monitorare le sessioni di debug dei flussi di dati attivi nell'esperienza Monitoraggio.
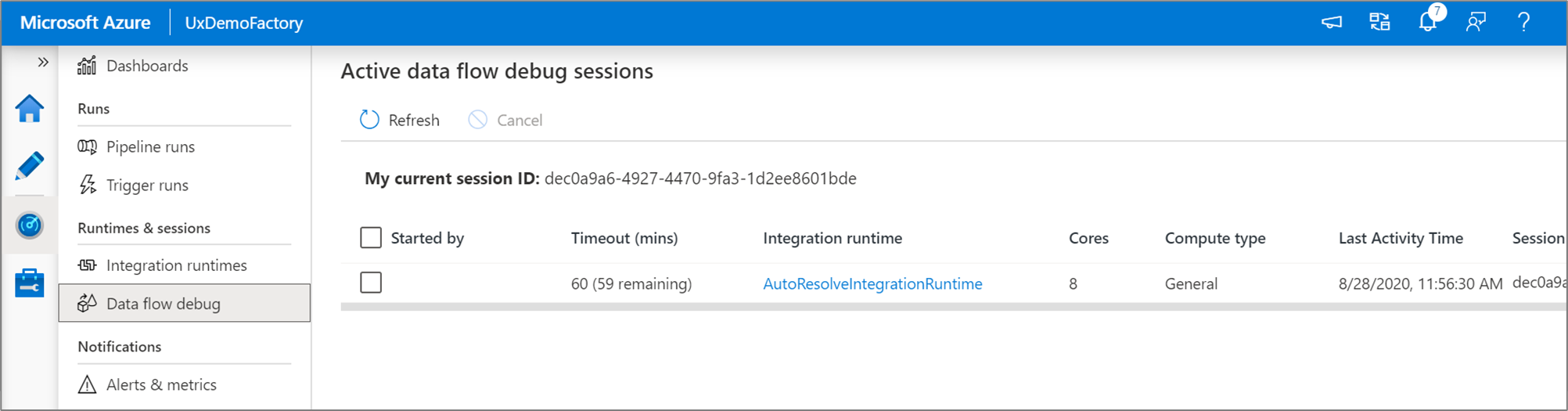
L'anteprima dei dati nella finestra di progettazione del flusso di dati e nel debug della pipeline dei flussi di dati è progettata per funzionare al meglio con piccoli esempi di dati. Tuttavia, se è necessario testare la logica in una pipeline o in un flusso di dati su grandi quantità di dati, aumentare le dimensioni del Azure Integration Runtime in uso nella sessione di debug con più core e un minimo di calcolo per utilizzo generico.
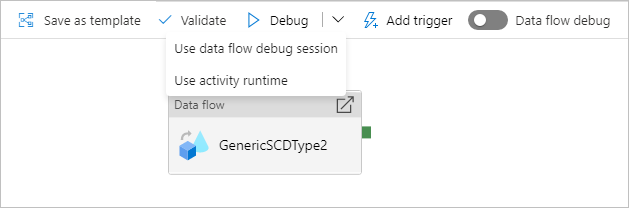
Eseguire il debug di una pipeline con un'attività Flusso di dati
Quando si esegue una pipeline di debug eseguita con un flusso di dati, sono disponibili due opzioni per il calcolo da usare. È possibile usare un cluster di debug esistente o creare un nuovo cluster just-in-time per i flussi di dati.
L'uso di una sessione di debug esistente ridurrà notevolmente il tempo di avvio del flusso di dati perché il cluster è già in esecuzione, ma non è consigliabile per carichi di lavoro complessi o paralleli perché potrebbero non riuscire quando vengono eseguiti più processi contemporaneamente.
L'uso del runtime di attività creerà un nuovo cluster usando le impostazioni specificate nel runtime di integrazione di ogni attività del flusso di dati. In questo modo ogni processo può essere isolato e deve essere usato per carichi di lavoro complessi o test delle prestazioni. È anche possibile controllare la durata (TTL) nel runtime di integrazione di Azure in modo che le risorse del cluster usate per il debug siano ancora disponibili per quel periodo di tempo per gestire richieste di processo aggiuntive.
Nota
Se si dispone di una pipeline con flussi di dati che vengono eseguiti in parallelo o che devono essere testati con set di dati di grandi dimensioni, scegliere "Usa Runtime Attività" in modo che il servizio possa usare il runtime di integrazione selezionato nell'attività di flusso di dati. In questo modo i flussi di dati possono essere eseguiti in più cluster e possono supportare le esecuzioni parallele del flusso di dati.
Contenuto correlato
Dopo aver testato le modifiche, promuoverle ad ambienti più elevati usando l'integrazione e la distribuzione continue.