Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Questo articolo descrive quali servizi collegati sono, come vengono definiti in formato JSON e come vengono usati in Azure Data Factory e Azure Synapse Analytics.
Per altre informazioni, vedere l'articolo introduttivo per Azure Data Factory o Azure Synapse.
Overview
Azure Data Factory e Azure Synapse Analytics possono avere una o più pipeline. Una pipeline è un raggruppamento logico di attività che insieme eseguono un compito. Le attività in una pipeline definiscono le azioni da eseguire sui dati. Ad esempio, è possibile usare un'attività di copia per copiare dati da SQL Server all'archiviazione BLOB di Azure. È quindi possibile usare un'attività Hive che esegue uno script Hive in un cluster Azure HDInsight per elaborare i dati dall'archivio BLOB per produrre dati di output. Infine, è possibile usare una seconda attività di copia per trasferire i dati di output in Azure Synapse Analytics, su cui si basano le soluzioni di reporting di Business Intelligence (BI). Per altre informazioni su pipeline e attività, vedere Pipeline e attività.
Un set di dati è una visualizzazione dati denominata che punta o fa riferimento ai dati usati come input e output nelle attività.
Prima di creare un set di dati, è necessario creare un servizio collegato per collegare l'archivio dati al Data Factory o Workspace Synapse. I servizi collegati sono molto simili a stringhe di connessione e definiscono le informazioni necessarie per la connessione del servizio a risorse esterne. In altre parole, il set di dati rappresenta la struttura dei dati all'interno degli archivi dati collegati e il servizio collegato definisce la connessione all'origine dati. Ad esempio, un servizio collegato Azure Storage collega un account di archiviazione al servizio. Un insieme di dati Blob di Azure rappresenta il contenitore blob e la cartella all'interno di quell'account Azure Storage che contiene i blob di input destinati all'elaborazione.
Di seguito è riportato uno scenario di esempio. Per copiare dati dall'archivio BLOB a un database SQL, creare due servizi collegati: Azure Storage e Azure SQL Database. Creare quindi due set di dati: Azure set di dati BLOB (che fa riferimento al servizio collegato Azure Storage) e Azure SQL set di dati Table (che fa riferimento al servizio collegato Azure SQL Database). I servizi collegati Azure Storage e Azure SQL Database contengono le stringhe di connessione usate dal servizio in fase di esecuzione per connettersi rispettivamente al Azure Storage e al Azure SQL Database. Il set di dati BLOB di Azure specifica il contenitore e una cartella BLOB che contengono i BLOB di input presenti nell'archiviazione BLOB di Azure. Il dataset Azure SQL Table specifica la tabella SQL nel tuo database SQL a cui i dati devono essere copiati.
Nel diagramma seguente viene illustrata la relazione tra pipeline, attività, set di dati e il servizio collegato nel servizio:
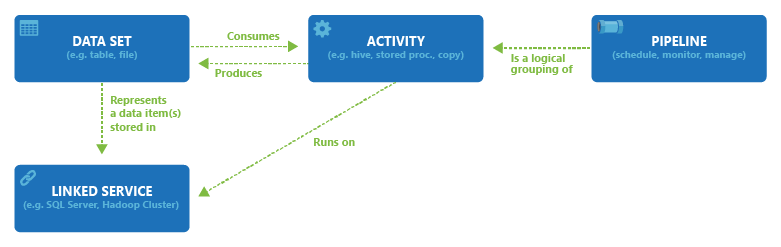
Servizio collegato con l'interfaccia utente
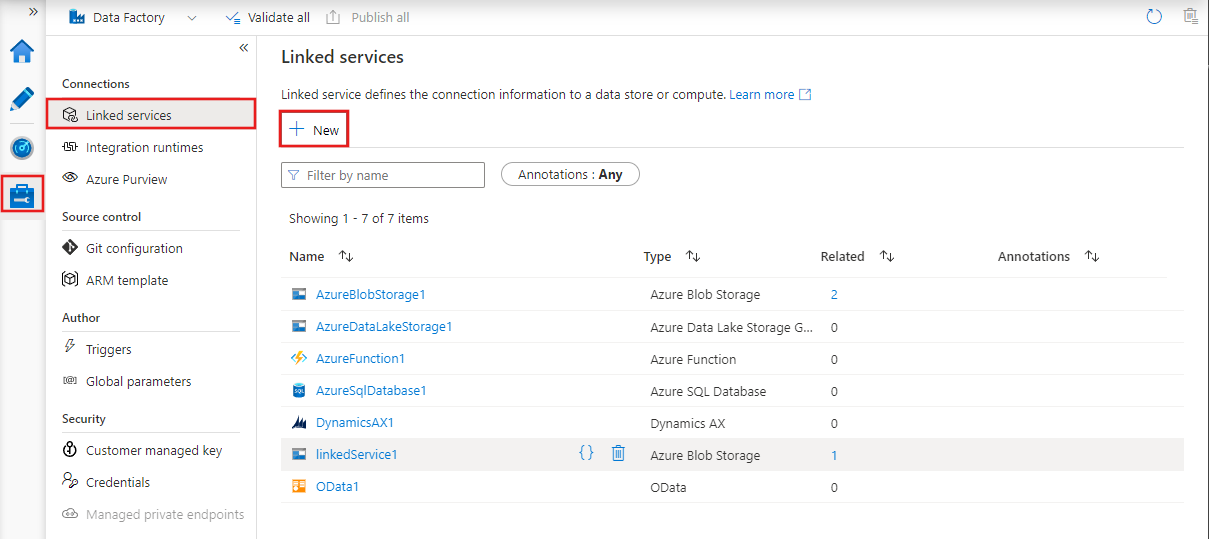
Per creare un nuovo servizio collegato in Azure Data Factory Studio, selezionare la scheda Manage e quindi servizi collegati, in cui è possibile visualizzare tutti i servizi collegati esistenti definiti. Selezionare + Nuovo per creare un nuovo servizio collegato.
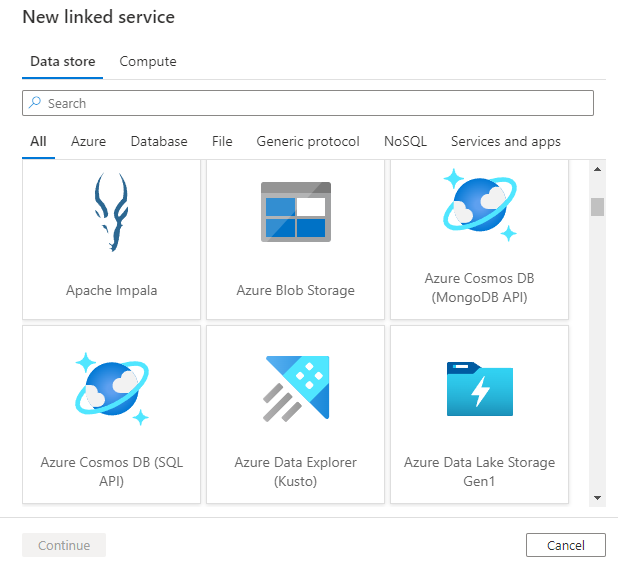
Dopo aver selezionato + Nuovo per creare un nuovo servizio collegato, è possibile scegliere uno dei connettori supportati e configurarne i dettagli di conseguenza. Successivamente, è possibile usare il servizio collegato in qualsiasi pipeline creata.
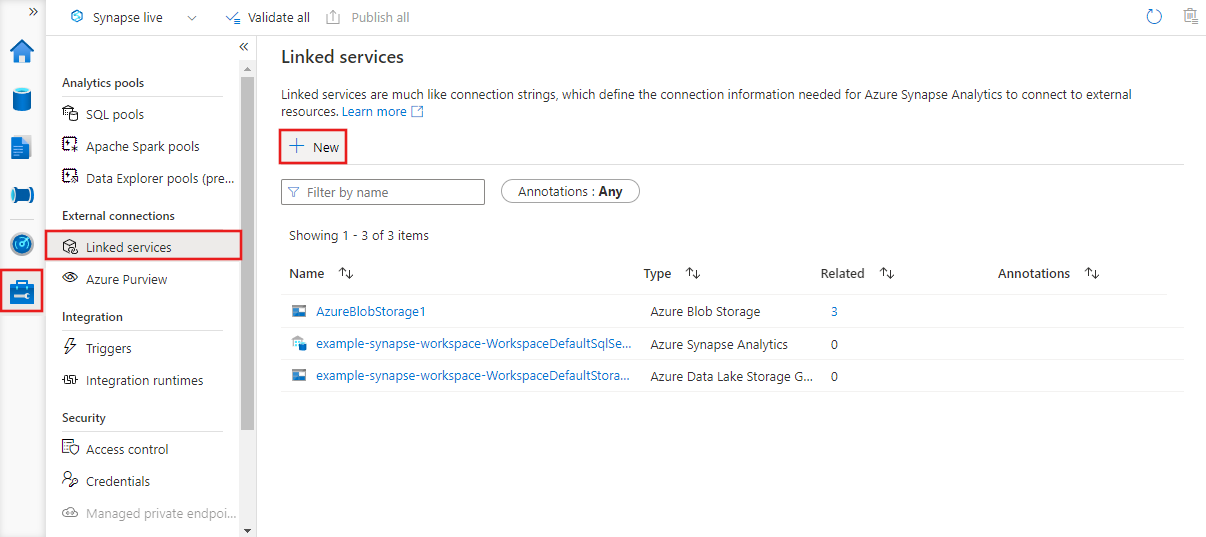
Servizio collegato JSON
Un servizio collegato viene definito in formato JSON come segue:
{
"name": "<Name of the linked service>",
"properties": {
"type": "<Type of the linked service>",
"typeProperties": {
"<data store or compute-specific type properties>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
La tabella seguente descrive le proprietà nel codice JSON precedente:
| Property | Description | Required |
|---|---|---|
| name | Nome del servizio collegato. Consulta Regole di denominazione. | Yes |
| type | Tipo di servizio collegato. Ad esempio: AzureBlobStorage (archivio dati) o AzureBatch (calcolo). Vedere la descrizione di typeProperties. | Yes |
| typeProperties | Le proprietà del tipo sono diverse per ogni archivio dati o calcolo. Per i tipi di archivio dati supportati e le relative proprietà del tipo, vedere l'articolo Panoramica sui connettori. Vai all'articolo sul connettore dell'archivio dati per conoscere le proprietà specifiche di un tipo di archivio dati. Per i tipi di calcolo supportati e le relative proprietà del tipo, vedere Servizi collegati di calcolo. |
Yes |
| connectVia | Integration Runtime da usare per connettersi all'archivio dati. È possibile usare Azure Integration Runtime o Integration Runtime self-hosted (se l'archivio dati si trova in una rete privata). Se non specificato, usa il Azure Integration Runtime predefinito. | No |
Esempio di servizio collegato
Il seguente servizio collegato è un servizio collegato di archiviazione BLOB di Azure. Si noti che il valore type è impostato su Archiviazione BLOB di Azure. Le proprietà del tipo per il servizio collegato di archiviazione BLOB di Azure includono una stringa di connessione. Il servizio usa questa connection string per connettersi all'archivio dati in fase di esecuzione.
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Creare servizi collegati
I servizi collegati possono essere creati nell'esperienza utente Azure Data Factory tramite l'hub management e qualsiasi attività, set di dati o flussi di dati che vi fanno riferimento.
È possibile creare servizi collegati usando uno di questi strumenti o SDK: .NET APIPowerShell, APIREST, Azure Resource Manager Template e Azure portal.
Quando si crea un servizio collegato, l'utente deve disporre dell'autorizzazione appropriata per il servizio designato. Se non viene concesso un accesso sufficiente, l'utente non può visualizzare le risorse disponibili e deve usare l'opzione di immissione manuale.
Servizi collegati al data store
È possibile trovare l'elenco degli archivi dati supportati nell'articolo di Panoramica sui connettori. Selezionare un archivio dati per informazioni sulle proprietà di connessione supportate.
Servizi collegati di calcolo
Per informazioni dettagliate sui diversi ambienti di calcolo a cui è possibile connettersi dal servizio e le diverse configurazioni, fare riferimento agli ambienti di calcolo supportati.
Contenuti correlati
Vedere le esercitazioni seguenti per istruzioni dettagliate sulla creazione di pipeline e set di dati tramite uno di questi strumenti o SDK.