Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questa guida di avvio rapido descrive come usare .NET SDK per creare un'istanza di Azure Data Factory. La pipeline creata in questa data factory copia dati da una cartella a un'altra in un archivio BLOB di Azure. Per un'esercitazione su come trasformare i dati usando Azure Data Factory, vedere Esercitazione: Trasformare dati usando Spark.
Prerequisiti
Sottoscrizione di Azure
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Ruoli di Azure
Per creare istanze di Data Factory, l'account utente usato per accedere ad Azure deve essere un membro del ruolo collaboratore o proprietario oppure un amministratore della sottoscrizione di Azure. Per visualizzare le autorizzazioni disponibili nella sottoscrizione, passare al portale di Azure, selezionare il nome utente nell'angolo in alto a destra, selezionare l'icona ... per visualizzare altre opzioni e quindi selezionare Autorizzazioni personali. Se si accede a più sottoscrizioni, selezionare quella appropriata.
Per creare e gestire le risorse figlio per Data Factory, inclusi i set di dati, i servizi collegati, le pipeline, i trigger e i runtime di integrazione, sono applicabili i requisiti seguenti:
- Per creare e gestire le risorse figlio nel portale di Azure, è necessario appartenere al ruolo Collaboratore Data Factory a livello di gruppo di risorse o superiore.
- Per creare e gestire le risorse figlio con PowerShell o l'SDK, è sufficiente il ruolo di collaboratore a livello di risorsa o superiore.
Per istruzioni di esempio su come aggiungere un utente a un ruolo, vedere l'articolo Aggiungere i ruoli.
Per altre informazioni, vedere gli articoli seguenti:
account di archiviazione di Azure
In questa guida di avvio rapido si usa un account di archiviazione di Azure per utilizzo generico (nello specifico, un account di archiviazione BLOB) come archivio dati sia di origine che di destinazione. Se non si ha un account di archiviazione di Azure per utilizzo generico, vedere Creare un account di archiviazione per informazioni su come crearne uno.
Ottenere il nome dell'account di archiviazione
Il nome dell'account di archiviazione di Azure è necessario per questa guida di avvio rapido. La procedura seguente illustra i passaggi per recuperare il nome dell'account di archiviazione:
- In un Web browser passare al portale di Azure e accedere usando il nome utente e la password di Azure.
- Dal menu del portale di Azure scegliere Tutti i servizi, quindi selezionare Archiviazione>Account di archiviazione. È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
- Nella pagina Account di archiviazione filtrare gli account di archiviazione, se necessario, quindi selezionare il proprio account di archiviazione.
È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
Creare un contenitore BLOB
In questa sezione viene creato un contenitore BLOB denominato adftutorial nell'archivio BLOB di Azure.
Dalla pagina dell'account di archiviazione, selezionare Panoramica>Contenitori.
<Nella barra degli strumenti della pagina Nome> - account Contenitori selezionare Contenitore.
Nella finestra di dialogo Nuovo contenitore immettere adftutorial come nome e quindi fare clic su OK. La <account viene aggiornata per includere > nell'elenco dei contenitori.
Aggiungere una cartella di input e un file per il contenitore BLOB
In questa sezione viene creata una cartella denominata input nel contenitore creato, in cui verrà caricato un file di esempio. Prima di iniziare, aprire un editor di testo come il Blocco note e creare un file denominato emp.txt con il contenuto seguente:
John, Doe
Jane, Doe
Salvare il file nella cartella C:\ADFv2QuickStartPSH. Se la cartella non esiste già, crearla. Tornare quindi alla portale di Azure e seguire questa procedura:
< >account in cui è stata interrotta selezionare adftutorial dall'elenco aggiornato dei contenitori.
- Se la finestra è stata chiusa o è passata a un'altra pagina, accedere nuovamente al portale di Azure.
- Dal menu del portale di Azure scegliere Tutti i servizi, quindi selezionare Archiviazione>Account di archiviazione. È anche possibile cercare e selezionare Account di archiviazione in qualsiasi pagina.
- Selezionare l'account di archiviazione, quindi Contenitori>adftutorial.
Nella barra degli strumenti della pagina del contenitore adftutorial selezionare Carica.
Nella pagina Carica BLOB selezionare la casella File, quindi individuare e selezionare il file emp.txt.
Espandere l'intestazione Avanzate. La pagina viene ora visualizzata come illustrato di seguito:
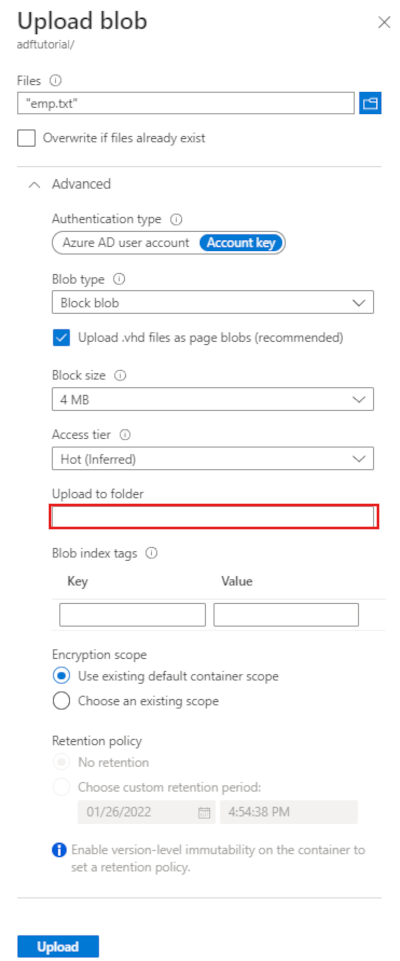
Nella casella Carica nella cartella immettere input.
Seleziona il pulsante Carica. Verranno visualizzati il file emp.txt e lo stato del caricamento nell'elenco.
Selezionare l'icona Chiudi (una X) per chiudere la pagina Carica BLOB.
Lasciare aperta la pagina del contenitore adftutorial. perché verrà usata per verificare l'output alla fine di questa guida introduttiva.
Visual Studio
Nella procedura guidata illustrata in questo articolo viene usato Visual Studio 2019. Le procedure per Visual Studio 2013, 2015 o 2017 sono leggermente diverse.
Creare un'applicazione in Microsoft Entra ID
Nelle sezioni descritte in Procedura: Usare il portale per creare un'applicazione Microsoft Entra e un'entità servizio in grado di accedere alle risorse, seguire le istruzioni per eseguire queste attività:
- In Creare un'applicazione Microsoft Entra creare un'applicazione che rappresenta l'applicazione .NET creata in questa esercitazione. Come URL di accesso è possibile specificare un URL fittizio, come illustrato nell'articolo (
https://contoso.org/exampleapp). - In Ottenere i valori per l'accesso ottenere l'ID dell'applicazione e l'ID del tenant, quindi prendere nota di questi valori che verranno usati più avanti in questa esercitazione.
- In Certificati e segreti ottenere la chiave di autenticazione e prendere nota di questo valore che verrà usato più avanti in questa esercitazione.
- In Assegnare l'applicazione a un ruolo assegnare l'applicazione al ruolo Collaboratore a livello di sottoscrizione, in modo che l'applicazione possa creare le data factory nella sottoscrizione.
Creare un progetto di Visual Studio
Creare quindi un'applicazione console C# .NET in Visual Studio:
- Avviare Visual Studio.
- Nella finestra di avvio selezionare Crea un nuovo progetto>App console (.NET Framework). È necessario .NET versione 4.5.2 o successiva.
- In Nome progetto immettere ADFv2QuickStart.
- Selezionare Crea per creare il progetto.
Installare i pacchetti NuGet
Fare clic su Strumenti>Gestione Pacchetti NuGet>Console di Gestione pacchetti.
Nel riquadro Console di Gestione pacchetti eseguire questi comandi per installare i pacchetti. Per altre informazioni, vedere il pacchetto NuGet Azure.ResourceManager.DataFactory .
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Creare una data factory
Aprire Program.cs e includere le istruzioni seguenti per aggiungere riferimenti agli spazi dei nomi.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Aggiungere il codice seguente al metodo Main per impostare le variabili. Sostituire i segnaposto con i valori personalizzati. Per un elenco di aree di Azure in cui Data Factory è attualmente disponibile, selezionare le aree di interesse nella pagina seguente, quindi espandere Analytics per individuare Data Factory: Prodotti disponibili in base all'area. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e altri) e le risorse di calcolo (HDInsight e altre) usati dalla data factory possono trovarsi in altre aree.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Aggiungere il codice seguente al metodo Main per creare una data factory.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Creare un servizio collegato
Aggiungere il codice seguente al metodo Main per creare un servizio collegato di Archiviazione di Azure.
Si creano servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa guida introduttiva è necessario creare un solo servizio collegato Archiviazione BLOB di Azure per l'origine di copia e l'archivio sink, denominato "AzureBlobStorageLinkedService" nell'esempio.
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Creare un set di dati
Aggiungere il codice seguente al metodo Main che crea un set di dati di testo delimitato.
È necessario definire un set di dati che rappresenta i dati da copiare da un'origine a un sink. In questo esempio questo set di dati di testo delimitato fa riferimento al servizio collegato Archiviazione BLOB di Azure creato nel passaggio precedente. Il set di dati accetta due parametri il cui valore è impostato in un'attività che utilizza il set di dati. I parametri vengono usati per costruire il "contenitore" e "folderPath" che puntano alla posizione in cui risiedono i dati/vengono archiviati.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Creare una pipeline
Aggiungere il codice seguente al metodo Main per creare una pipeline con un'attività di copia.
In questo esempio questa pipeline contiene un'attività e accetta quattro parametri: il contenitore BLOB di input e il percorso e il contenitore BLOB di output e il percorso. I valori per questi parametri vengono impostati all'esecuzione/attivazione della pipeline. L'attività di copia fa riferimento allo stesso set di dati del BLOB creato nel passaggio precedente come input e output. Quando il set di dati viene usato come set di dati di input, vengono specificati il contenitore di input e il percorso. Inoltre, quando il set di dati viene usato come set di dati di output, vengono specificati il contenitore di output e il percorso.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Creare un'esecuzione della pipeline
Aggiungere il codice seguente al metodo Main per attivare un'esecuzione della pipeline.
Questo codice imposta anche i valori dei parametri inputContainer, inputPath, outputContainer e outputPath specificati nella pipeline con i valori effettivi dei percorsi blob di origine e sink.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Monitorare un'esecuzione della pipeline
Aggiungere il codice seguente al metodo Main per controllare continuamente lo stato fino al termine della copia dei dati.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Aggiungere il codice seguente al metodo Main per recuperare i dettagli dell'esecuzione dell'attività di copia, ad esempio le dimensioni dei dati letti o scritti.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Eseguire il codice
Compilare e avviare l'applicazione, quindi verificare l'esecuzione della pipeline.
La console stampa lo stato di creazione della data factory, del servizio collegato, dei set di dati, della pipeline e dell'esecuzione della pipeline. Controlla quindi lo stato di esecuzione della pipeline. Attendere fino a visualizzare i dettagli dell'esecuzione dell'attività di copia con le dimensioni dei dati di lettura/scrittura. Usare quindi strumenti come Azure Storage Explorer per verificare che i BLOB siano stati copiati da "inputBlobPath" a "outputBlobPath", come specificato nelle variabili.
Output di esempio
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Verificare l'output
La pipeline crea automaticamente la cartella di output nel contenitore BLOB adftutorial, quindi copia il file emp.txt dalla cartella di input a quella di output.
- Nel portale di Azure, nella pagina del contenitore adftutorial in cui si è rimasti dalla sezione precedente Aggiungere una cartella di input e un file per il contenitore BLOB selezionare Aggiorna per visualizzare la cartella di output.
- Nell'elenco delle cartelle selezionare output.
- Verificare che emp.txt venga copiato nella cartella di output.
Pulire le risorse
Per eliminare una data factory a livello di codice, aggiungere al programma le righe di codice seguenti:
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Passaggi successivi
La pipeline in questo esempio copia i dati da una posizione a un'altra in un archivio BLOB di Azure. Per informazioni sull'uso di Data Factory in più scenari, fare riferimento alle esercitazioni.