Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Un'esecuzione di pipeline in Azure Data Factory e Azure Synapse definisce un'istanza di un'esecuzione di pipeline. Ad esempio, supponiamo di avere una pipeline che si esegue alle 8:00, alle 9:00 e alle 10:00. In questo caso si hanno tre esecuzioni di pipeline separate, ognuna con un ID di esecuzione pipeline univoco. Un ID di esecuzione è un GUID che definisce in modo univoco la specifica esecuzione della pipeline.
Le istanze delle esecuzioni di pipeline vengono in genere create passando argomenti ai parametri definiti nelle pipeline. È possibile eseguire una pipeline manualmente o tramite un trigger. Questo articolo fornisce informazioni dettagliate su entrambe le modalità di esecuzione di una pipeline.
Creare trigger con interfaccia utente
Per attivare manualmente una pipeline o per configurare un nuovo trigger periodico, di archiviazione o di evento personalizzato, selezionare Aggiungi trigger nella parte superiore dell'editor della pipeline.
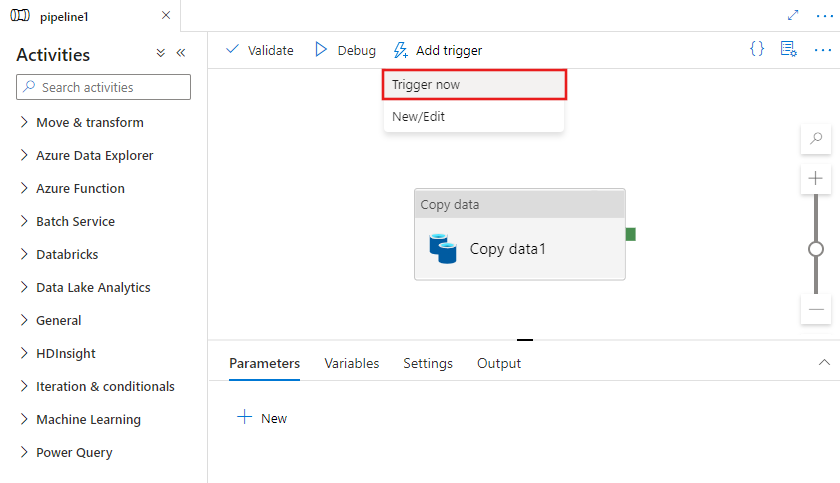
Se si sceglie di attivare manualmente la pipeline, sarà eseguita immediatamente. Se invece si sceglie Nuovo/Modifica, verrà visualizzata una richiesta nella finestra Aggiungi trigger, per scegliere un trigger esistente da modificare o per creare un nuovo trigger.
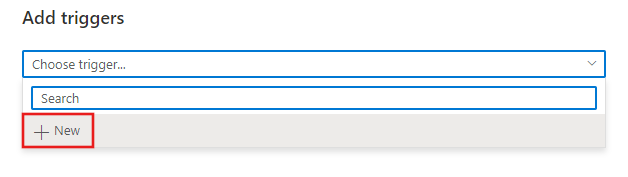
Verrà visualizzata la finestra di configurazione del trigger, che consente di sceglierne il tipo.
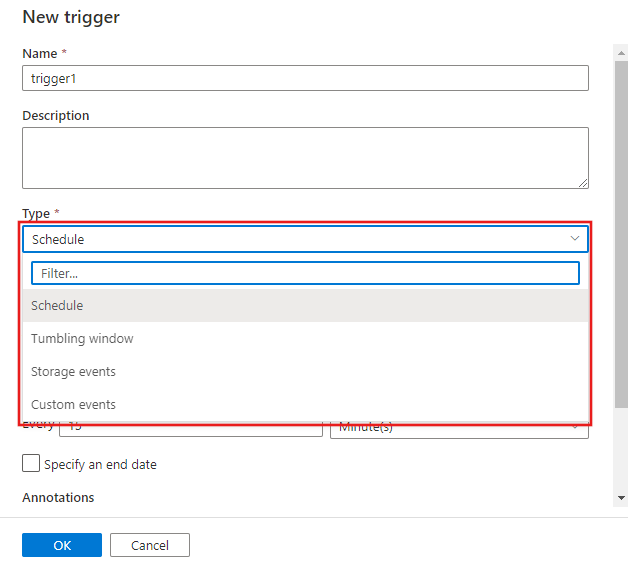
Di seguito sono disponibili altre informazioni sui trigger pianificati, periodici, di evento di archiviazione e di evento personalizzato.
Esecuzione manuale
L'esecuzione manuale di una pipeline è detta anche esecuzione su richiesta.
Si supponga ad esempio che sia disponibile una pipeline denominata copyPipeline che si vuole eseguire. La pipeline ha una singola attività che esegue una copia da una cartella di origine in Azure Blob storage a una cartella di destinazione nello stesso storage. La definizione JSON seguente illustra questa pipeline di esempio:
{
"name": "copyPipeline",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
},
"name": "CopyBlobtoBlob",
"inputs": [
{
"referenceName": "sourceBlobDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "sinkBlobDataset",
"type": "DatasetReference"
}
]
}
],
"parameters": {
"sourceBlobContainer": {
"type": "String"
},
"sinkBlobContainer": {
"type": "String"
}
}
}
}
Nella definizione JSON la pipeline accetta due parametri: sourceBlobContainer e sinkBlobContainer. Passare valori a questi parametri in fase di esecuzione.
Esecuzione manuale con altre API/SDK
È possibile eseguire manualmente la pipeline usando uno dei metodi seguenti:
- .NET SDK
- Modulo di Azure PowerShell
- REST API (Interfaccia di Programmazione delle Applicazioni REST)
- Python SDK
.NET SDK
La chiamata di esempio seguente illustra come eseguire la pipeline usando .NET SDK manualmente:
client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, parameters)
Per un esempio completo, vedere Guida introduttiva: Creare una data factory e una pipeline con .NET SDK.
Nota
È possibile usare .NET SDK per richiamare le pipeline da Funzioni di Azure, dai propri servizi Web e così via.
Azure PowerShell
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Il comando di esempio seguente illustra come eseguire manualmente la pipeline usando Azure PowerShell:
Invoke-AzDataFactoryV2Pipeline -DataFactory $df -PipelineName "Adfv2QuickStartPipeline" -ParameterFile .\PipelineParameters.json -ResourceGroupName "myResourceGroup"
I parametri vengono passati nel corpo del payload della richiesta. Nel .NET SDK, in Azure PowerShell e nel Python SDK, si passa i valori in un dizionario che viene passato come argomento alla chiamata:
{
"sourceBlobContainer": "MySourceFolder",
"sinkBlobContainer": "MySinkFolder"
}
Il payload di risposta è un ID univoco dell'esecuzione della pipeline:
{
"runId": "0448d45a-a0bd-23f3-90a5-bfeea9264aed"
}
Per un esempio completo, vedere Guida introduttiva: Creare una data factory con Azure PowerShell.
Python SDK
Per un esempio completo, vedere Avvio rapido: Creare una data factory e una pipeline con Python
REST API (Interfaccia di Programmazione delle Applicazioni REST)
Il comando di esempio seguente illustra come eseguire la pipeline usando l'API REST manualmente:
POST
https://management.azure.com/subscriptions/mySubId/resourceGroups/myResourceGroup/providers/Microsoft.DataFactory/factories/myDataFactory/pipelines/copyPipeline/createRun?api-version=2017-03-01-preview
Per un esempio completo, vedere Guida introduttiva: Creare una data factory usando l'API REST.
Tipi di trigger
I trigger rappresentano una modalità alternativa per attivare una esecuzione di pipeline. I trigger rappresentano un'unità di elaborazione che determina quando deve essere avviata l'esecuzione di una pipeline. Attualmente, il servizio supporta tre tipi di trigger:
Trigger di pianificazione: un trigger che richiama una pipeline con una pianificazione basata sul tempo reale.
Trigger di finestra a cascata: un trigger che viene attivato a intervalli periodici, mantenendo al tempo stesso lo stato.
Trigger basato su eventi: un trigger che risponde a un evento.
Le pipeline e i trigger hanno una relazione molti-a-molti (ad eccezione del trigger periodico). Più trigger possono avviare una singola pipeline e un singolo trigger può avviare più pipeline. Nella definizione di trigger seguente la proprietà pipelines fa riferimento a un elenco di pipeline attivate dal trigger specifico. La definizione della proprietà include i valori dei parametri della pipeline.
Definizione del trigger di base
{
"properties": {
"name": "MyTrigger",
"type": "<type of trigger>",
"typeProperties": {...},
"pipelines": [
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "<Name of your pipeline>"
},
"parameters": {
"<parameter 1 Name>": {
"type": "Expression",
"value": "<parameter 1 Value>"
},
"<parameter 2 Name>": "<parameter 2 Value>"
}
}
]
}
}
Trigger di pianificazione
Un trigger di pianificazione esegue le pipeline con una pianificazione basata sul tempo reale. Questo trigger supporta opzioni di calendario periodiche e avanzate. Il trigger supporta, ad esempio, intervalli come "settimanale" o "Lunedì alle 17:00 e giovedì alle 21:00". Il trigger di pianificazione è flessibile perché il criterio del set di dati è indipendente e il trigger non distingue tra dati di serie temporali e non temporali.
Per altre informazioni ed esempi sui trigger pianificati vedere Creare un trigger che esegue una pipeline in base a una pianificazione.
Definizione del trigger di pianificazione
Quando si crea un trigger di pianificazione, si specificano la pianificazione e la ricorrenza usando una definizione JSON.
Per fare in modo che il trigger di pianificazione attivi l'esecuzione di una pipeline, includere un riferimento di pipeline della pipeline specifica nella definizione del trigger. Pipeline e trigger hanno una relazione molti-a-molti. Più trigger possono attivare una singola pipeline. Un singolo trigger può attivare più pipeline.
{
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": <<Minute, Hour, Day, Week>>,
"interval": <<int>>, // How often to fire
"startTime": <<datetime>>,
"endTime": <<datetime>>,
"timeZone": "UTC",
"schedule": { // Optional (advanced scheduling specifics)
"hours": [<<0-24>>],
"weekDays": [<<Monday-Sunday>>],
"minutes": [<<0-60>>],
"monthDays": [<<1-31>>],
"monthlyOccurrences": [
{
"day": <<Monday-Sunday>>,
"occurrence": <<1-5>>
}
]
}
}
},
"pipelines": [
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "<Name of your pipeline>"
},
"parameters": {
"<parameter 1 Name>": {
"type": "Expression",
"value": "<parameter 1 Value>"
},
"<parameter 2 Name>": "<parameter 2 Value>"
}
}
]}
}
Importante
La proprietà parameters è una proprietà obbligatoria dell'elemento pipelines. Se la pipeline non accetta parametri, è necessario includere una definizione JSON vuota per la proprietà parameters.
Panoramica dello schema
La tabella seguente fornisce una panoramica generale degli elementi dello schema principali correlati alla ricorrenza e alla pianificazione di un trigger:
| Proprietà JSON | Descrizione |
|---|---|
| startTime | Valore data-ora. Per le pianificazioni di base, il valore della proprietà startTime si applica alla prima occorrenza. Per le pianificazioni complesse, il trigger viene attivato non prima del valore startTime specificato. |
| endTime | Data e ora di fine per il trigger. Il trigger non viene eseguito dopo la data e l'ora di fine specificate. Il valore della proprietà non può essere nel passato. |
| Fuso orario | Fuso orario. Per un elenco dei fusi orari supportati, vedere Creare un trigger che esegue una pipeline in base a una pianificazione. |
| ricorrenza | Oggetto di ricorrenza che specifica le regole della ricorrenza per il trigger. L'oggetto recurrence supporta gli elementi frequency, interval, endTime, count e schedule. Quando viene definito un oggetto recurrence, l'elemento frequency è obbligatorio. Gli altri elementi dell'oggetto recurrence sono facoltativi. |
| frequenza | Unità di frequenza con cui il trigger si ripete. I valori supportati includono "minute", "hour", "day", "week" e "month". |
| intervallo | Numero intero positivo indicante l'intervallo per il valore frequency. Il valore frequency determina la frequenza con cui viene eseguito il trigger. Se, ad esempio, interval è 3 e frequency è "week", il trigger si ripete ogni tre settimane. |
| Programma | Pianificazione della ricorrenza per il trigger. Un attivatore con un valore di frequenza specificato modifica la sua ricorrenza secondo un programma di ricorrenza. La proprietà schedule contiene modifiche per la ricorrenza basate su minuti, ore, giorni della settimana, giorni del mese e numero della settimana. |
Nota
Per i fusi orari che osservano l'ora legale, l'ora di attivazione viene modificata automaticamente due volte all'anno, se la ricorrenza è impostata su Giorni o superiore. Per rifiutare esplicitamente la modifica dell'ora legale, selezionare un fuso orario che non osserva l'ora legale, ad esempio UTC.
La regolazione dell'ora legale si verifica solo per un trigger con la ricorrenza impostata su Giorni o superiore. Se il trigger è impostato su una frequenza di Ore o Minuti, continua a essere attivato a intervalli regolari.
Esempio di trigger di pianificazione
{
"properties": {
"name": "MyTrigger",
"type": "ScheduleTrigger",
"typeProperties": {
"recurrence": {
"frequency": "Hour",
"interval": 1,
"startTime": "2017-11-01T09:00:00-08:00",
"endTime": "2017-11-02T22:00:00-08:00"
}
},
"pipelines": [{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "SQLServerToBlobPipeline"
},
"parameters": {}
},
{
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "SQLServerToAzureSQLPipeline"
},
"parameters": {}
}
]
}
}
Impostazioni predefinite dello schema, limiti ed esempi
| Proprietà JSON | TIPO | Obbligatorio | Valore predefinito | Valori validi | Esempio |
|---|---|---|---|---|---|
| startTime | corda | Sì | Nessuno | Date-ore ISO 8601 | "startTime" : "2013-01-09T09:30:00-08:00" |
| ricorrenza | oggetto | Sì | Nessuno | Oggetto recurrence | "recurrence" : { "frequency" : "monthly", "interval" : 1 } |
| intervallo | numero | NO | 1 | Da 1 a 1000 | "interval":10 |
| endTime | corda | Sì | Nessuno | Valore di data e ora che fa riferimento a un momento nel futuro | "endTime" : "2013-02-09T09:30:00-08:00" |
| Programma | oggetto | NO | Nessuno | Oggetto schedule | "schedule" : { "minute" : [30], "hour" : [8,17] } |
Proprietà startTime
La tabella seguente illustra come la proprietà startTime controlla l'esecuzione di un trigger:
| Valore startTime | Ricorrenza senza pianificazione | Ricorrenza con pianificazione |
|---|---|---|
| L'ora di inizio è nel passato | Calcola l'ora della prima esecuzione futura dopo l'ora di inizio e avvia l'esecuzione in corrispondenza di tale ora. Avvia le esecuzioni successive calcolate a partire dall'ora dell'ultima esecuzione. Vedere l'esempio sotto a questa tabella. |
Il trigger viene avviato non prima dell'ora di inizio specificata. La prima occorrenza è basata sulla pianificazione, calcolata a partire dall'ora di inizio. Avvia le esecuzioni successive in base alla pianificazione di ricorrenza. |
| L'ora di inizio è nel futuro o nel presente | Avvia l'esecuzione una sola volta all'ora di inizio specificata. Avvia le esecuzioni successive calcolate a partire dall'ora dell'ultima esecuzione. |
Il trigger viene avviato non prima dell'ora di inizio specificata. La prima occorrenza è basata sulla pianificazione, calcolata a partire dall'ora di inizio. Avvia le esecuzioni successive in base alla pianificazione di ricorrenza. |
È possibile esaminare uno scenario in cui l'ora di inizio è nel passato, con una ricorrenza, ma nessuna pianificazione. Si supponga che l'ora corrente sia le 13:00 del 08/04/2017, l'ora di inizio sia le 14:00 del 07/04/2017 e la ricorrenza sia ogni due giorni. Il valore recurrence viene definito impostando la proprietà frequency su "day" e la proprietà interval su 2. Si noti che il valore startTime è nel passato e si verifica prima dell'ora corrente.
In queste condizioni, la prima esecuzione avviene il 9 aprile 2017 alle 14:00. Il motore dell'utilità di pianificazione calcola le occorrenze dall'ora di inizio dell'esecuzione. Tutte le istanze precedenti vengono rimosse. Il motore utilizza l'istanza successiva che si verifica in futuro. In questo scenario l'ora di inizio corrisponde alle 14:00 del 07/04/2017. L'istanza successiva viene eseguita due giorni dopo tale orario, ovvero alle 14:00 del 09/04/2017.
Si noti che la prima esecuzione sarebbe la stessa anche se startTime fosse alle 14:00 del 05/04/2017 o alle 14:00 del 01/04/2017. Dopo la prima esecuzione, le esecuzioni successive vengono calcolate in base alla pianificazione. Le esecuzioni successive saranno alle 14:00 dell'11/04/2017, quindi alle 14:00 del 13/04/2017, alle 14:00 del 15/04/2017 e così via.
Infine, quando le ore o i minuti non sono impostati nella pianificazione di un trigger, le ore o i minuti della prima esecuzione vengono usati come impostazioni predefinite.
Proprietà schedule
È possibile usare schedule per limitare il numero di esecuzioni del trigger. Se ad esempio la pianificazione di un trigger con frequenza mensile prevede l'esecuzione solo il giorno 31, il trigger viene eseguito solo nei mesi che includono trentuno giorni.
È anche possibile usare schedule per espandere il numero di esecuzioni del trigger. Ad esempio, un trigger con una frequenza mensile la cui esecuzione è pianificata per i giorni 1 e 2 del mese viene eseguito il primo e il secondo giorno del mese, invece che una volta al mese.
Se vengono specificati più elementi di pianificazione, la valutazione viene eseguita a partire dall'impostazione più grande della pianificazione fino a quella più piccola, ovvero, numero della settimana, giorno del mese, giorno della settimana, ora e minuto.
La tabella seguente illustra in modo dettagliato gli elementi schedule:
| Elemento JSON | Descrizione | Valori validi |
|---|---|---|
| minuti | Minuti dell'ora in cui verrà eseguito il trigger. | - Numero intero - Matrice di numeri interi |
| ore | Ore del giorno in cui verrà eseguito il trigger. | - Numero intero - Matrice di numeri interi |
| giorni della settimana | Giorni della settimana in cui verrà eseguito il trigger. Il valore può essere specificato solo con una frequenza settimanale. | - Lunedì - Martedì - Mercoledì - Giovedì - Venerdì - Sabato - Domenica - Matrice di valori relativi ai giorni (la dimensione massima della matrice è 7) Per i valori del giorno non esiste la distinzione maiuscole/minuscole |
| mensileOccorrenze | Giorni del mese in cui verrà eseguito il trigger. Il valore può essere specificato solo con una frequenza mensile. | - Matrice di oggetti monthlyOccurrence: { "day": day, "occurrence": occurrence }- L'attributo day è il giorno della settimana in cui il trigger si esegue. Ad esempio, una proprietà monthlyOccurrences con un valore day uguale a {Sunday} indica ogni domenica del mese. L'attributo day è obbligatorio.- L'attributo occurrence indica l'occorrenza dell'attributo day specificato durante il mese. Ad esempio, una proprietà monthlyOccurrences con i valori day e occurrence uguali a {Sunday, -1} indica l'ultima domenica del mese. L'attributo occurrence è facoltativo. |
| meseGiorni | Giorno del mese in cui verrà eseguito il trigger. Il valore può essere specificato solo con una frequenza mensile. | - Qualsiasi valore <= -1 e >= -31 - Qualsiasi valore >= 1 e <= 31 - Matrice di valori |
Trigger periodico
I trigger di finestra a cascata vengono attivati in base a un intervallo di tempo periodico a partire da un'ora di inizio specificata, mantenendo al tempo stesso lo stato. Le finestre a caduta sono una serie di intervalli temporali di dimensioni fisse, contigui e non sovrapposti.
Per ulteriori informazioni ed esempi sui trigger di finestra a scorrimento, vedere Creare un trigger di finestra a scorrimento.
Esempi di pianificazioni di ricorrenza del trigger
Questa sezione fornisce esempi di pianificazioni di ricorrenza. È incentrata sull'oggetto schedule e sui rispettivi elementi.
Gli esempi presumono che il valore di intervallo sia 1 e che il valore frequenza sia corretto in base alla definizione della pianificazione. Non è ad esempio possibile avere un valore frequency uguale a "day" e anche una modifica monthDays nell'oggetto schedule. Questi tipi di restrizioni vengono descritti nella tabella disponibile nella sezione precedente.
| Esempio | Descrizione |
|---|---|
{"hours":[5]} |
Viene eseguito alle 5:00 ogni giorno. |
{"minutes":[15], "hours":[5]} |
Corri alle 5:15 ogni giorno. |
{"minutes":[15], "hours":[5,17]} |
Viene eseguito alle 5:15 del mattino e alle 5:15 del pomeriggio ogni giorno. |
{"minutes":[15,45], "hours":[5,17]} |
Viene eseguito alle 05:15, alle 05:45, alle 17:15 e alle 17:45 ogni giorno. |
{"minutes":[0,15,30,45]} |
Viene eseguito ogni 15 minuti. |
{hours":[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]} |
Viene eseguito ogni ora. Il trigger si attiva ogni ora. I minuti vengono controllati dal valore startTime, se specificato. Se non è specificato un valore, i minuti vengono controllati dall'ora di creazione. Se ad esempio l'ora di inizio o l'ora di creazione (qualunque delle due si applichi) è 12:25, il trigger viene eseguito alle 00:25, 01:25, 02:25, ..., 23:25. Questa pianificazione equivale a un trigger con un valore frequency pari a "hour", un valore interval di 1 e nessun oggetto schedule. Questa pianificazione può essere usata con valori diversi per frequency e interval per creare altri trigger. Quando ad esempio il valore frequency è "month", la pianificazione viene eseguita solo una volta al mese, invece che ogni giorno, quando il valore frequency è "day". |
{"minutes":[0]} |
Viene eseguito ogni ora all'inizio dell'ora. Questo trigger viene eseguito ogni ora con l'ora che inizia alle 00:00, 01:00, 02:00 e così via. Questa pianificazione equivale a un trigger con un valore frequency pari a "ora" e un valore startTime di zero minuti, senza schedule ma con un valore di frequency pari a "giorno". Se il valore frequency è "week" o "month", la pianificazione viene eseguita rispettivamente solo una volta alla settimana o una volta al giorno. |
{"minutes":[15]} |
Viene eseguito 15 minuti dopo l'inizio di ogni ora. Questo trigger viene eseguito ogni ora, 15 minuti dopo l'inizio dell'ora a partire dalle 00:15, 01:15, 02:15 e così via e terminando alle 23:15. |
{"hours":[17], "weekDays":["saturday"]} |
Viene eseguito alle 17:00 di ogni sabato. |
{"hours":[17], "weekDays":["monday", "wednesday", "friday"]} |
Viene eseguito alle 17:00 di ogni lunedì, mercoledì e venerdì. |
{"minutes":[15,45], "hours":[17], "weekDays":["monday", "wednesday", "friday"]} |
Viene eseguito alle 17:15 e alle 17:45 di ogni lunedì, mercoledì e venerdì. |
{"minutes":[0,15,30,45], "weekDays":["monday", "tuesday", "wednesday", "thursday", "friday"]} |
Viene eseguito ogni 15 minuti nei giorni feriali. |
{"minutes":[0,15,30,45], "hours": [9, 10, 11, 12, 13, 14, 15, 16] "weekDays":["monday", "tuesday", "wednesday", "thursday", "friday"]} |
Viene eseguito ogni 15 minuti nei giorni feriali tra le 09:00 e le 16:45. |
{"weekDays":["tuesday", "thursday"]} |
Viene eseguito ogni martedì e giovedì all'ora di inizio specificata. |
{"minutes":[0], "hours":[6], "monthDays":[28]} |
Viene eseguito alle 6:00 del ventottesimo giorno di ogni mese, supponendo che il valore di frequency sia "month". |
{"minutes":[0], "hours":[6], "monthDays":[-1]} |
Viene eseguito alle 06:00 dell'ultimo giorno di ogni mese. Per eseguire un trigger l'ultimo giorno del mese, usare -1 invece del giorno 28, 29, 30 o 31. |
{"minutes":[0], "hours":[6], "monthDays":[1,-1]} |
Viene eseguito alle 06:00 il primo e l'ultimo giorno di ogni mese. |
{monthDays":[1,14]} |
Viene eseguito il primo e il quattordicesimo giorno di ogni mese all'ora di inizio. |
{"minutes":[0], "hours":[5], "monthlyOccurrences":[{"day":"friday", "occurrence":1}]} |
Viene eseguito il primo venerdì di ogni mese alle 05:00. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":1}]} |
Viene eseguito il primo venerdì di ogni mese all'ora di inizio specificata. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":-3}]} |
Viene eseguito il terzultimo venerdì di ogni mese, all'ora di inizio specificata. |
{"minutes":[15], "hours":[5], "monthlyOccurrences":[{"day":"friday", "occurrence":1},{"day":"friday", "occurrence":-1}]} |
Viene eseguito il primo e l'ultimo venerdì di ogni mese alle 05:15. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":1},{"day":"friday", "occurrence":-1}]} |
Viene eseguito il primo e l'ultimo venerdì di ogni mese all'ora di inizio specificata. |
{"monthlyOccurrences":[{"day":"friday", "occurrence":5}]} |
Viene eseguito il quinto venerdì di ogni mese all'ora di inizio specificata. Quando in un mese non sono inclusi cinque venerdì, la pipeline non viene eseguita. È consigliabile usare -1 invece di 5 per il valore occurrence per eseguire il trigger l'ultimo venerdì del mese. |
{"minutes":[0,15,30,45], "monthlyOccurrences":[{"day":"friday", "occurrence":-1}]} |
Viene eseguito ogni 15 minuti l'ultimo venerdì del mese. |
{"minutes":[15,45], "hours":[5,17], "monthlyOccurrences":[{"day":"wednesday", "occurrence":3}]} |
Viene eseguito alle 05:15 di mattina, 05:45 di mattina, 17:15 di sera e 17:45 di sera il terzo mercoledì di ogni mese. |
Trigger basato su eventi
Un trigger basato su evento esegue pipeline in risposta a un evento. Dal punto di vista del comportamento, se si arresta e si avvia un trigger basato su eventi, riprende il modello di trigger precedente che può causare un trigger indesiderato della pipeline. In questo caso, è necessario eliminare e creare un nuovo trigger basato su eventi. Il nuovo grilletto riparte da capo senza storia. Esistono due tipi di trigger basati su evento.
- Trigger di evento di archiviazione esegue una pipeline sugli eventi che si verificano in un account di archiviazione, ad esempio l'arrivo di un file o l'eliminazione di un file nell'account di Archiviazione BLOB di Azure.
- Trigger di evento personalizzato elabora e gestisce gli articoli personalizzati nella Griglia di eventi
Per altre informazioni sui trigger basati su evento, vedere Trigger di evento di archiviazione e Trigger di evento personalizzato.
Confronto dei tipi di trigger
Il trigger di finestra a cascata e il trigger di pianificazione funzionano entrambi in base agli heartbeat temporali, Quali sono le differenze?
Nota
L'esecuzione del trigger periodico attende che l'esecuzione della pipeline attivata sia terminata. Il relativo stato di esecuzione riflette lo stato dell'esecuzione della pipeline attivata. Ad esempio, se un'esecuzione di pipeline attivata viene annullata, l'esecuzione del trigger periodico corrispondente viene contrassegnata come annullata. Questo comportamento è diverso dal comportamento "fire and forget" del trigger pianificato, che viene contrassegnato come riuscito all'avvio dell'esecuzione della pipeline.
La tabella seguente contiene un confronto del trigger di finestra a cascata e del trigger di pianificazione:
| Elemento | Trigger periodico | Trigger di pianificazione |
|---|---|---|
| Scenari di recupero delle informazioni | Supportato. Si possono pianificare esecuzioni della pipeline per finestre nel passato. | Non supportato. Le esecuzioni della pipeline possono essere eseguite solo in periodi di tempo compresi tra il momento corrente e il futuro. |
| Affidabilità | 100% di affidabilità. Le esecuzioni della pipeline possono essere pianificate per tutte le finestre da una data di inizio specificata senza intervalli. | Meno affidabile. |
| Funzionalità di ripetizione dei tentativi | Supportato. Le esecuzioni non riuscite delle pipeline hanno un criterio di ripetizione predefinito pari a 0 oppure un criterio specificato dall'utente nella definizione di un trigger. Esegue automaticamente un nuovo tentativo quando le esecuzioni della pipeline non riescono a causa di limiti di concorrenza/server/limitazione delle richieste (codici di stato 400: Errore utente, 429: Troppe richieste e 500: Errore interno del server). | Non supportato. |
| Concorrenza | Supportato. Gli utenti possono impostare in modo esplicito i limiti di concorrenza per il trigger. Consente un numero di esecuzioni di pipeline simultanee attivate compreso tra 1 e 50. | Non supportato. |
| Variabili di sistema | Insieme a @trigger().scheduledTime e @trigger().startTime, supporta anche l'uso delle variabili di sistema WindowStart e WindowEnd. Gli utenti possono accedere a trigger().outputs.windowStartTime e a trigger().outputs.windowEndTime come variabile di sistema del trigger nella definizione del trigger. I valori vengono usati rispettivamente come ora di inizio della finestra e ora di fine della finestra. Ad esempio, per un trigger di finestra a cascata che viene eseguito ogni ora, per la finestra compresa tra la 01:00 e le 02:00, la definizione è trigger().outputs.windowStartTime = 2017-09-01T01:00:00Z e trigger().outputs.windowEndTime = 2017-09-01T02:00:00Z. |
Supporta solo le variabili predefinite @trigger().scheduledTime e @trigger().startTime. |
| Relazione tra pipeline e trigger | Supporta una relazione uno a uno. Può essere attivata una sola pipeline. | Supporta relazioni molti a molti. Più trigger possono attivare una singola pipeline. Un singolo trigger può attivare più pipeline. |
Contenuto correlato
Vedere le esercitazioni seguenti: