Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Applicabile a: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
I flussi di dati sono disponibili sia nelle pipeline Azure Data Factory che nelle pipeline di Azure Synapse Analytics. Questo articolo si applica ai flussi di dati per mapping. Se non si ha familiarità con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando flussi di dati di mapping.
La trasformazione exists è una trasformazione di filtro delle righe che controlla se i dati esistono in un'altra origine o flusso. Il flusso di output include tutte le righe nel flusso di sinistra esistenti o che non esistono nel flusso di destra. La trasformazione exists è simile a SQL WHERE EXISTS e SQL WHERE NOT EXISTS.
Impostazione
- Scegliere il flusso di dati che si sta verificando nell'elenco a discesa Flusso destro .
- Specificare se si desidera che i dati esistano o non esistano nell'impostazione Tipo esistente .
- Selezionare se si vuole o meno un'espressione personalizzata.
- Scegliere le colonne chiave da confrontare in base alle condizioni esistenti. Per impostazione predefinita, il flusso di dati cerca l'uguaglianza tra una colonna per ogni flusso. Per eseguire il confronto tramite un valore calcolato, passare il puntatore del mouse sull'elenco a discesa della colonna e selezionare Colonna calcolata.
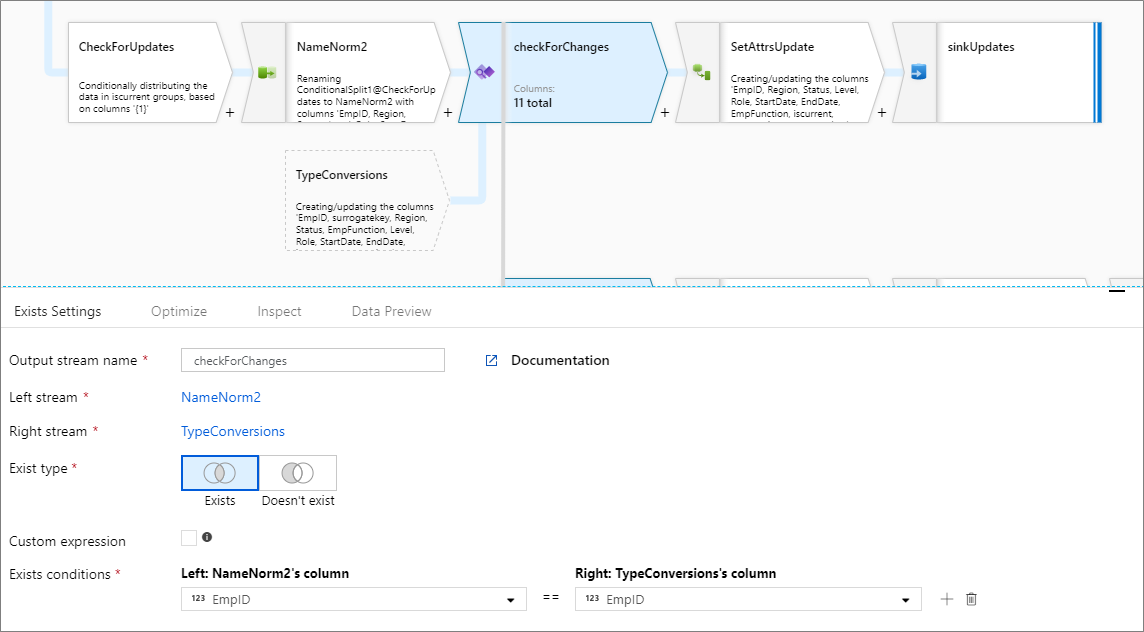
Più condizioni esistono
Per confrontare più colonne da ogni flusso, aggiungere una nuova condizione esistente facendo clic sull'icona con il segno più accanto a una riga esistente. Ogni condizione aggiuntiva viene unita da un'istruzione "and". Il confronto di due colonne è identico a quello dell'espressione seguente:
source1@column1 == source2@column1 && source1@column2 == source2@column2
Espressione personalizzata
Per creare un'espressione in formato libero contenente operatori diversi da "and" e "uguale a", selezionare il campo Espressione personalizzata . Immettere un'espressione personalizzata tramite il generatore di espressioni del flusso di dati facendo clic sulla casella blu.
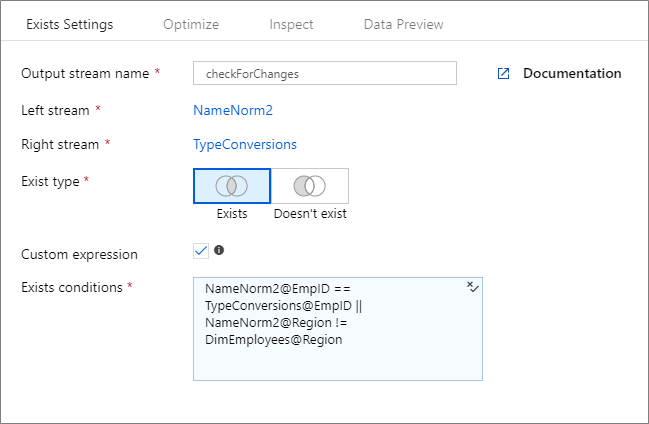
Se si creano modelli dinamici nei flussi di dati usando il "binding tardivo" delle colonne tramite deviazione dello schema, è possibile usare la funzione di espressione per usare la byName() trasformazione exists senza hardcoding (ad esempio l'associazione anticipata) i nomi delle colonne. Esempio: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
Ottimizzazione della trasmissione
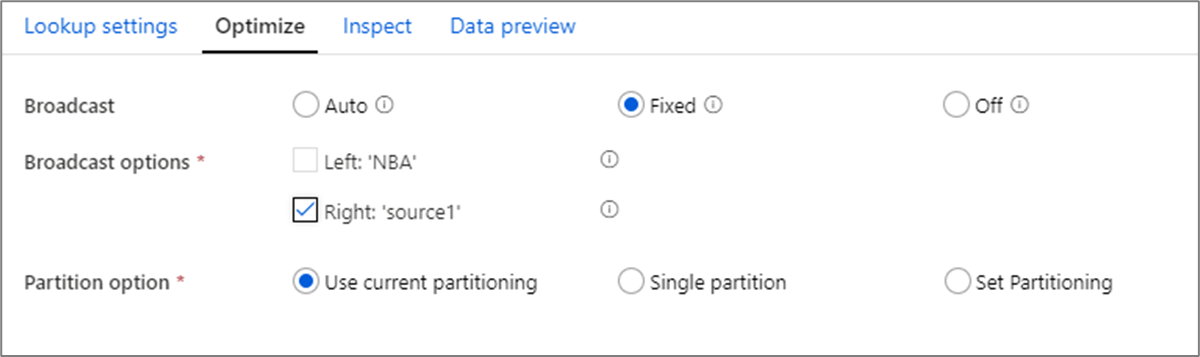
Nella trasformazione di join, ricerche ed exists, se uno o entrambi i flussi di dati rientrano nella memoria del nodo di lavoro, è possibile ottimizzare le prestazioni abilitando la trasmissione. Per impostazione predefinita, il motore Spark deciderà automaticamente se trasmettere o meno un lato. Per scegliere manualmente il lato da trasmettere, selezionare Fisso.
Non è consigliabile disabilitare la trasmissione tramite l'opzione Off a meno che i join non siano in errore di timeout.
Script del flusso di dati
Sintassi
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
Esempio
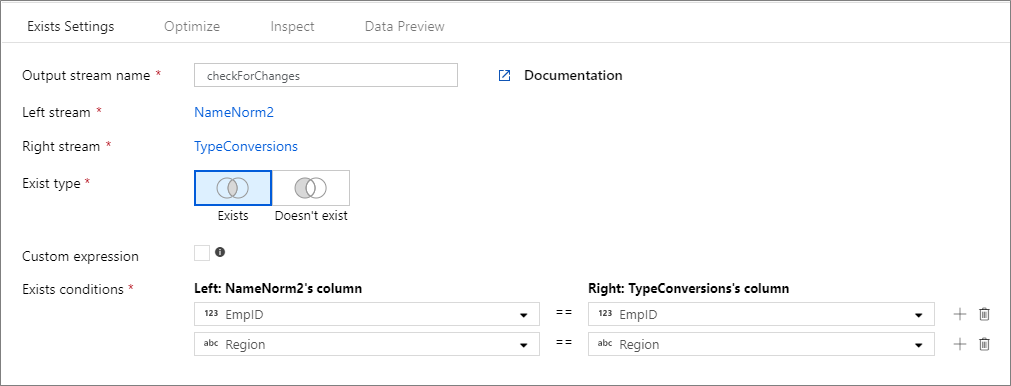
L'esempio seguente è una trasformazione esistente denominata checkForChanges che accetta flusso sinistro NameNorm2 e flusso TypeConversionsdestro. La condizione exists è l'espressione NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region che restituisce true se entrambe le EMPID colonne e Region in ogni flusso corrispondono. Mentre stiamo controllando l'esistenza, negate è false. Non è possibile abilitare alcuna trasmissione nella scheda Ottimizza, quindi broadcast ha valore 'none'.
Nell'esperienza dell'interfaccia utente questa trasformazione è simile all'immagine seguente:
Lo script del flusso di dati per questa trasformazione si trova nel frammento di codice seguente:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges