Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
I flussi di dati sono disponibili sia nelle pipeline Azure Data Factory che nelle pipeline di Azure Synapse Analytics. Questo articolo si applica ai flussi di dati di mapping. Se non si ha familiarità con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando flussi di dati di mapping.
Suggerimento
Per la trasformazione equivalente (Merge queries) in Dataflow Gen2, vedere Guida a Dataflow Gen2 per gli utenti del flusso dati di mapping.
Utilizzare la trasformazione di ricerca per fare riferimento ai dati da un'altra origine in un flusso di dati. La trasformazione della ricerca aggiunge le colonne dai dati corrispondenti ai dati di origine.
Una trasformazione della ricerca è simile a una left outer join. Tutte le righe del flusso primario sono presenti nel flusso di output con colonne aggiuntive del flusso di ricerca.
Impostazione
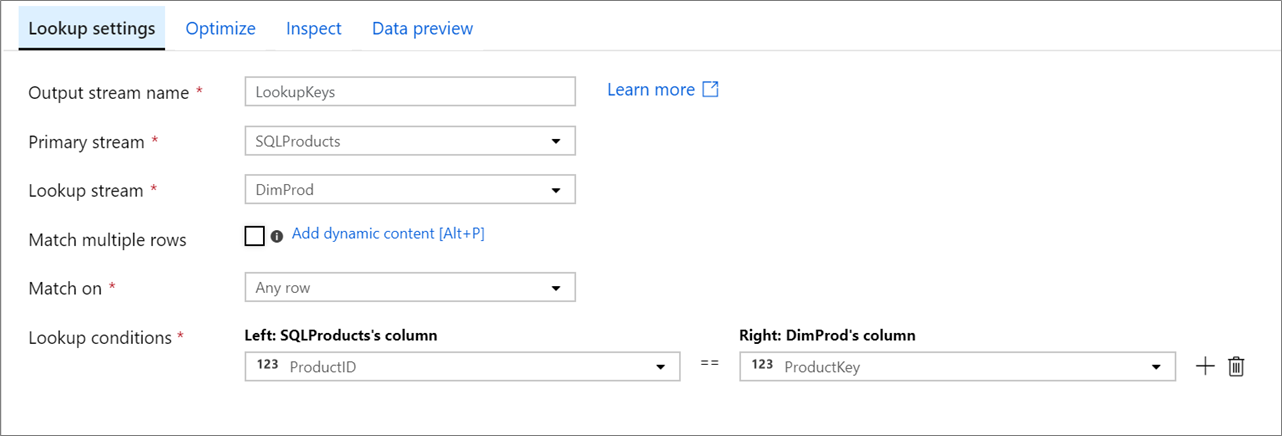
Flusso primario: flusso in ingresso di dati. Questo flusso è equivalente al lato sinistro di un join.
Flusso di ricerca: dati accodati al flusso principale. I dati aggiunti vengono determinati in base alle condizioni di ricerca. Questo flusso è equivalente al lato destro di un join.
Corrispondenza con righe multiple: Se abilitata, una riga con più corrispondenze nel flusso primario restituirà più righe. In caso contrario, verrà restituita una sola riga in base alla condizione "Corrispondenza".
Corrispondenza su: visibile solo se non è selezionata l'opzione "Trova più righe". Scegliere se trovare la corrispondenza con qualsiasi riga, la prima corrispondenza o l'ultima corrispondenza. Qualsiasi riga è consigliata poiché viene eseguita più velocemente. Se viene selezionata la prima riga o l'ultima riga, sarà necessario specificare le condizioni di ordinamento.
Condizioni di ricerca: scegliere le colonne su cui trovare la corrispondenza. Se viene soddisfatta la condizione di uguaglianza, le righe verranno considerate corrispondenti. Passare il puntatore del mouse e selezionare "Colonna calcolata" per estrarre un valore usando il linguaggio delle espressioni del flusso di dati.
Tutte le colonne di entrambi i flussi sono incluse nei dati di output. Per rilasciare colonne duplicate o indesiderate, aggiungere una trasformazione della selezione dopo la trasformazione della ricerca. Le colonne possono anche essere rilasciate o rinominate in una trasformazione sink.
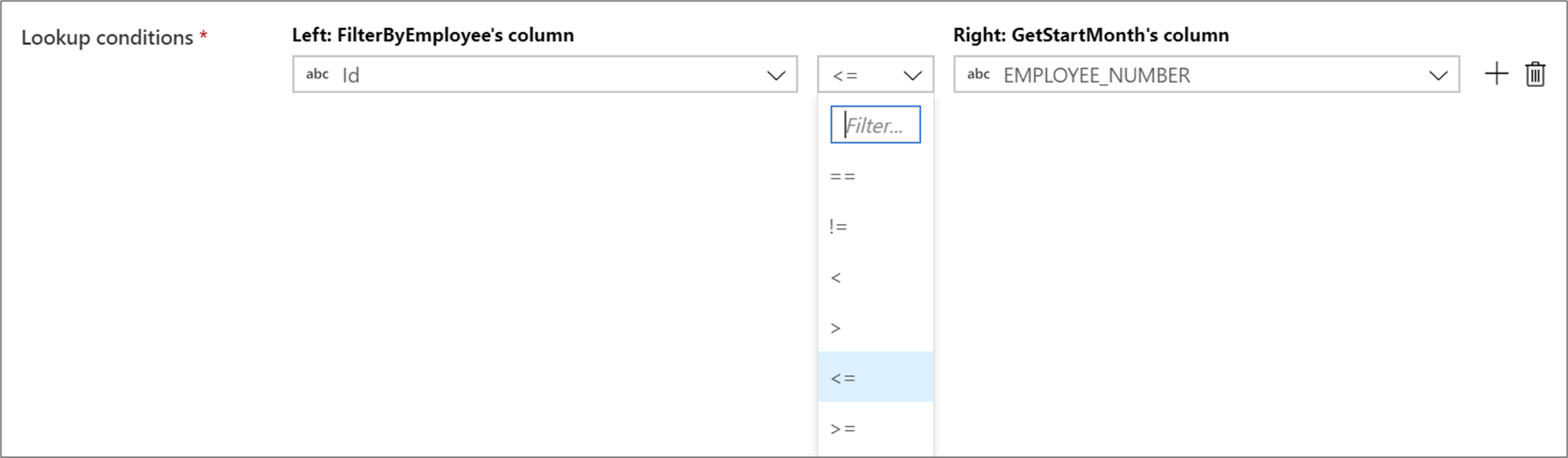
Join non uguali
Per usare un operatore condizionale come non uguale (! =) o maggiore di (>) nelle condizioni di ricerca, modificare l'elenco a discesa operatore tra le due colonne. Per i join non uguali è necessario che almeno uno dei due flussi venga trasmesso usando la broadcast fissa nella scheda Ottimizza.
Analisi delle righe corrispondenti
Dopo la trasformazione della ricerca, è possibile usare la funzione isMatch() per verificare se la ricerca corrisponde a singole righe.
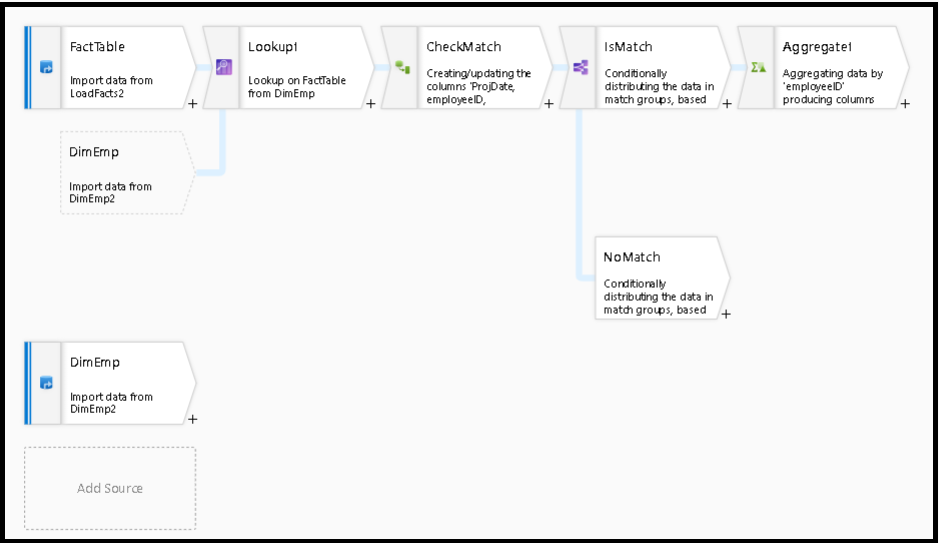
Un esempio di questo modello consiste nell'usare la trasformazione della suddivisione condizionale per suddividere la funzione isMatch(). Nell'esempio precedente, le righe corrispondenti passano attraverso il flusso superiore, mentre il flusso delle righe non corrispondenti passa attraverso il flusso NoMatch.
Verifica delle condizioni di ricerca
Quando si testa la trasformazione di ricerca con anteprima dei dati in modalità di debug, usare un piccolo set di dati noti. Quando si campionano righe da un set di dati di grandi dimensioni, non è possibile prevedere quali righe e chiavi verranno lette per il test. Il risultato è non deterministico, vale a dire che le condizioni di join potrebbero non restituire corrispondenze.
Ottimizzazione della trasmissione
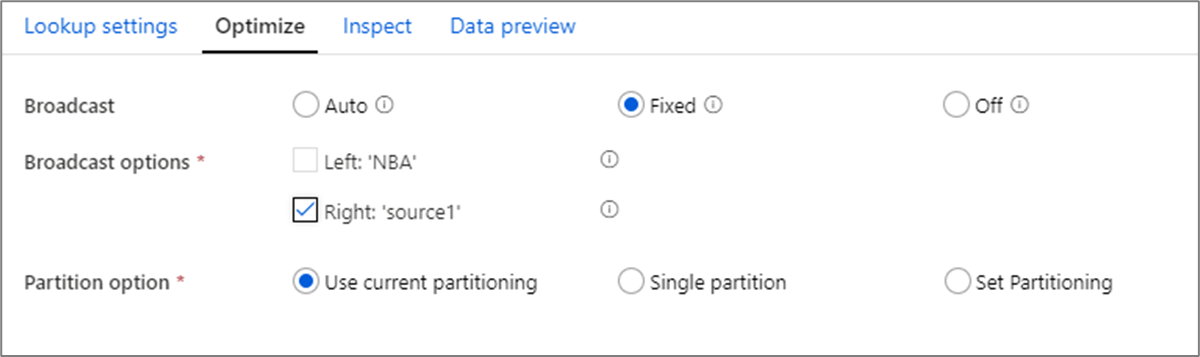
Nella trasformazione di join, ricerche ed exists, se uno o entrambi i flussi di dati rientrano nella memoria del nodo di lavoro, è possibile ottimizzare le prestazioni abilitando la trasmissione. Per impostazione predefinita, il motore Spark deciderà automaticamente se trasmettere o meno un lato. Per scegliere manualmente il lato da trasmettere, selezionare Fisso.
Non è consigliabile disabilitare la trasmissione tramite l'opzione Off a meno che i join non siano in errore di timeout.
Ricerca memorizzata nella cache
Se si eseguono diverse ricerche di dimensioni ridotte sulla stessa origine, un sink con cache e una ricerca potrebbero rappresentare un caso d'uso migliore rispetto alla trasformazione di ricerca. Esempi comuni in cui l'uso di un cache sink può rivelarsi più vantaggioso sono la ricerca del valore massimo in un archivio dati e l'abbinamento dei codici di errore a un database di messaggi di errore. Per altre informazioni, vedere sink della cache e ricerche memorizzate nella cache.
Script del flusso di dati
Sintassi
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Esempio
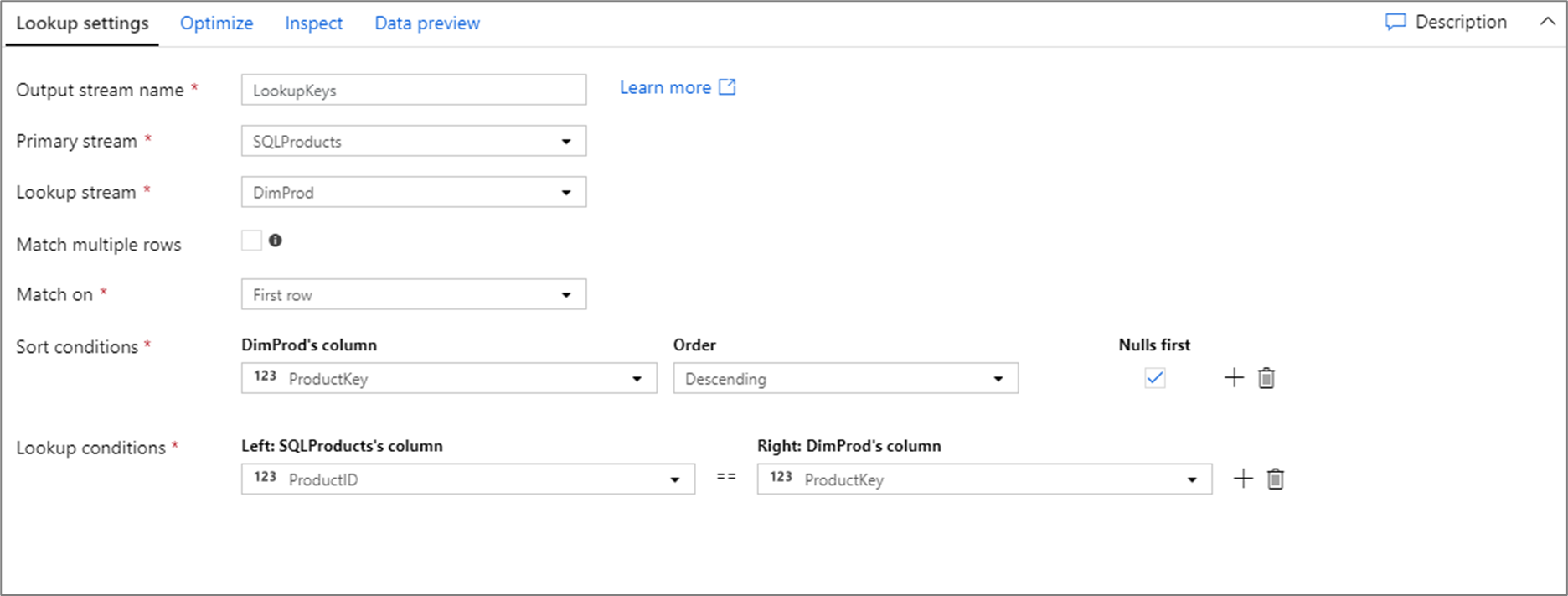
Lo script del flusso di dati per la configurazione di ricerca precedente si trova nel frammento di codice riportato di seguito.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Contenuto correlato
- Le trasformazioni di join ed exists accettano entrambe più input di flusso
- Usare una trasformazione condizionale con
isMatch()per suddividere le righe su valori corrispondenti e non corrispondenti