Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo descrive un modello di soluzione che è possibile usare per estrarre dati da un'origine PDF usando Azure Data Factory e Azure AI Document Intelligence.
Informazioni sul modello di soluzione
Questo modello analizza i dati da un'origine URL PDF usando due chiamate di Intelligence per i documenti di Intelligenza artificiale di Azure. Trasforma quindi l'output in tabelle leggibili in un flusso di dati e restituisce i dati in un sink di archiviazione.
Questo modello contiene due attività:
- Attività Web per chiamare l'API modello di lettura predefinita di Document Intelligence per intelligenza artificiale di Azure
- Flusso di dati per trasformare i dati estratti da PDF
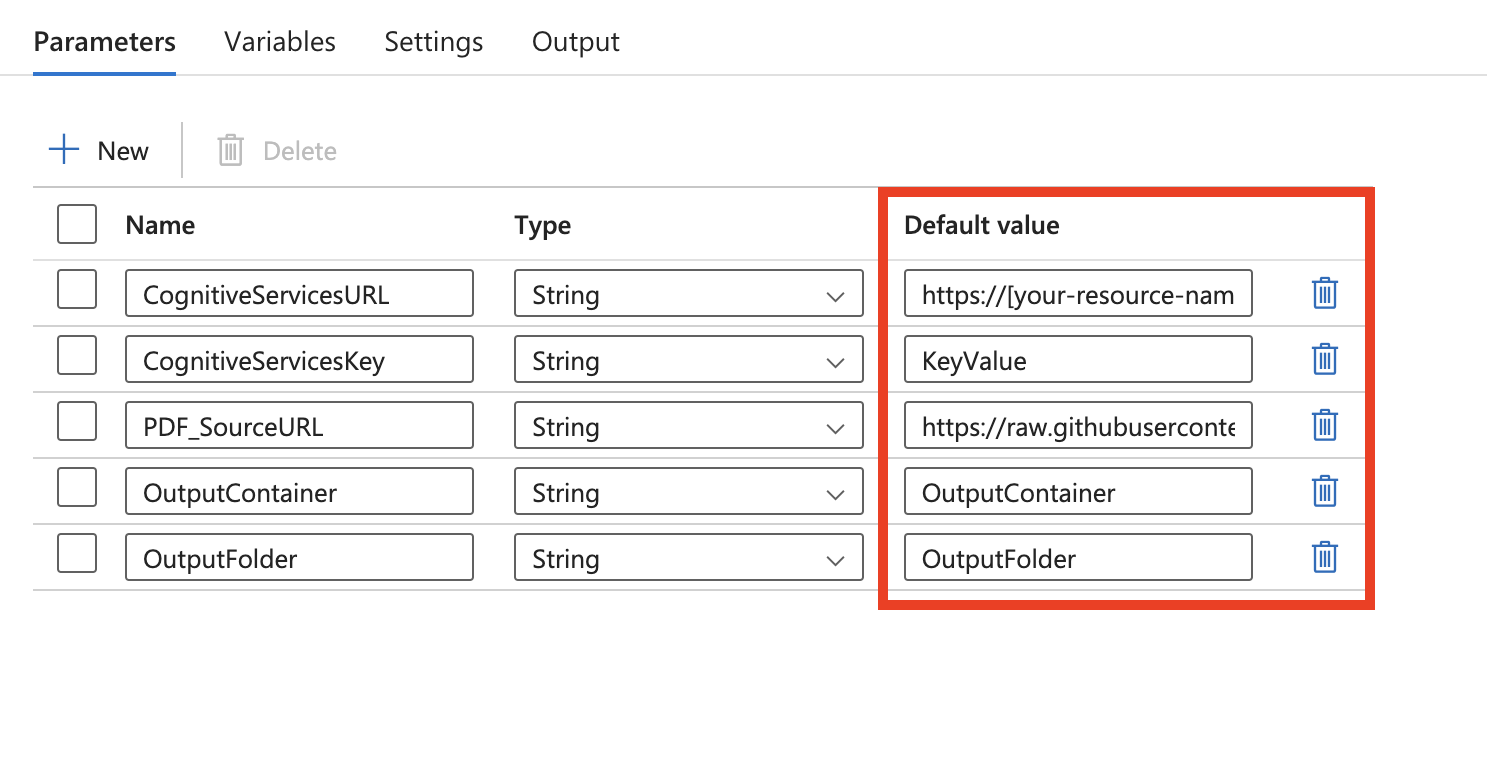
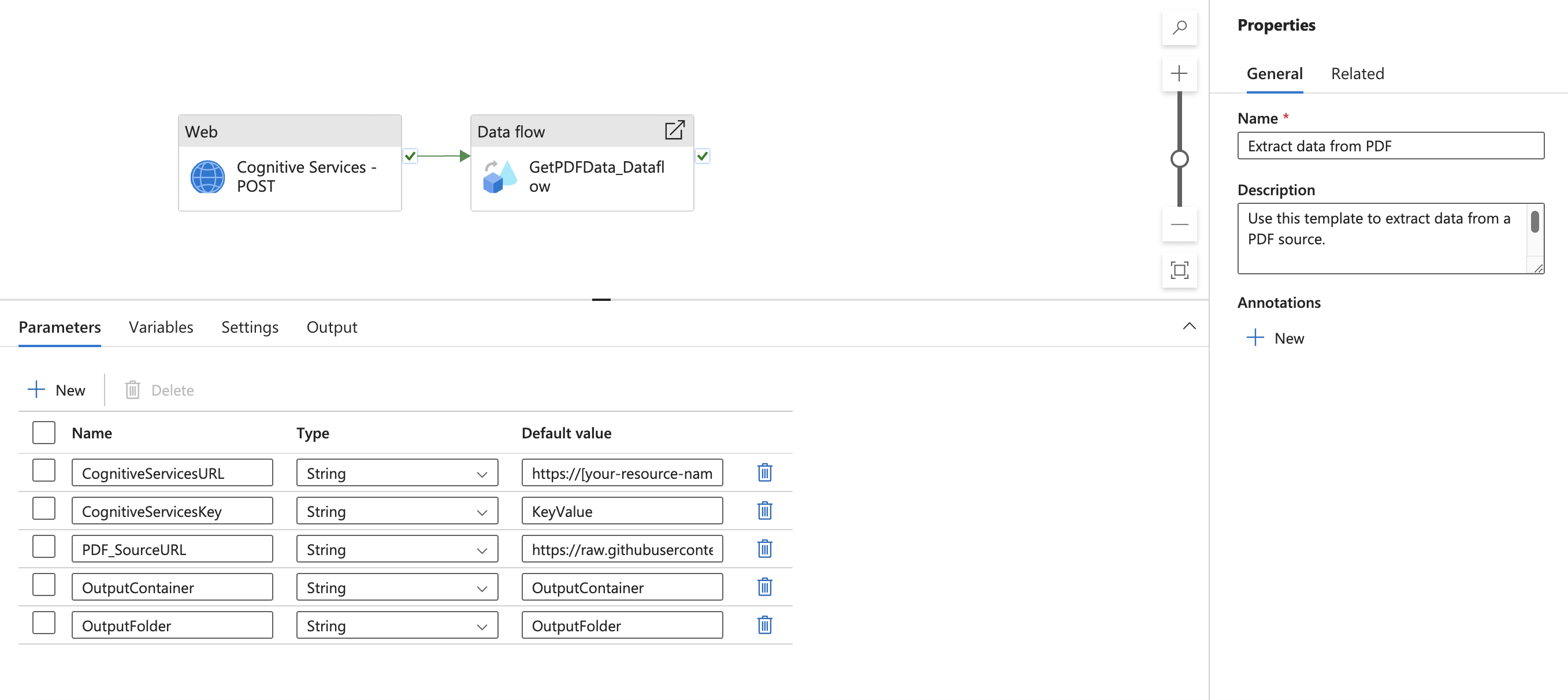
Questo modello definisce cinque parametri:
- CognitiveServicesURL è l'URL di Intelligence sui documenti di Intelligenza artificiale di Azure ("https://{endpoint}/formrecognizer/v2.1/layout/analyze"). Sostituire {endpoint} con l'endpoint ottenuto con la sottoscrizione di Document Intelligence per intelligenza artificiale di Azure. È necessario sostituire il valore predefinito con il proprio URL.
- CognitiveServicesKey è la chiave di sottoscrizione di Document Intelligence per intelligenza artificiale di Azure. È necessario sostituire il valore predefinito con la propria chiave di sottoscrizione.
- PDF_SourceURL è l'URL dell'origine PDF. È necessario sostituire il valore predefinito con il proprio URL.
- OutputContainer è il nome del percorso del contenitore in cui si desidera che i file si trovino nell'archivio di destinazione. È necessario sostituire il valore predefinito con il proprio contenitore.
- OutputFolder è il nome del percorso della cartella in cui si desidera che i file si trovino nell'archivio di destinazione. È necessario sostituire il valore predefinito con il percorso della cartella.
Prerequisiti
- URL e chiave dell'endpoint delle risorse di Intelligence per intelligenza artificiale di Azure (creare una nuova risorsa qui)
Come usare questo modello di soluzione
Passare al modello Estrai dati da PDF. Creare una nuova connessione alla risorsa di Document Intelligence per intelligenza artificiale di Azure o scegliere una connessione esistente.
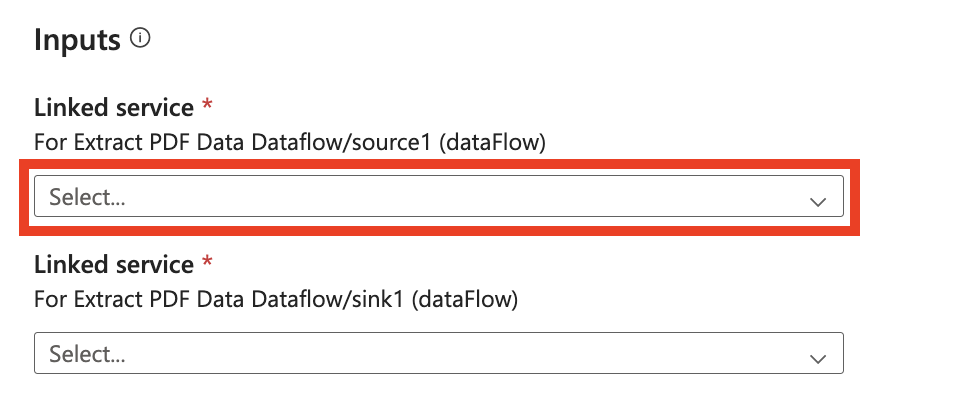
Nella connessione ad Azure AI Document Intelligence assicurarsi di aggiungere un parametro del servizio collegato. È necessario usare questo parametro URL come URL di base dinamico. Sarà anche necessario aggiungere una nuova intestazione di autenticazione nelle intestazioni di autenticazione. Il nome deve essere Ocp-Apim-Subscription-Key e il valore deve essere il valore della chiave trovato dalla risorsa di Azure.
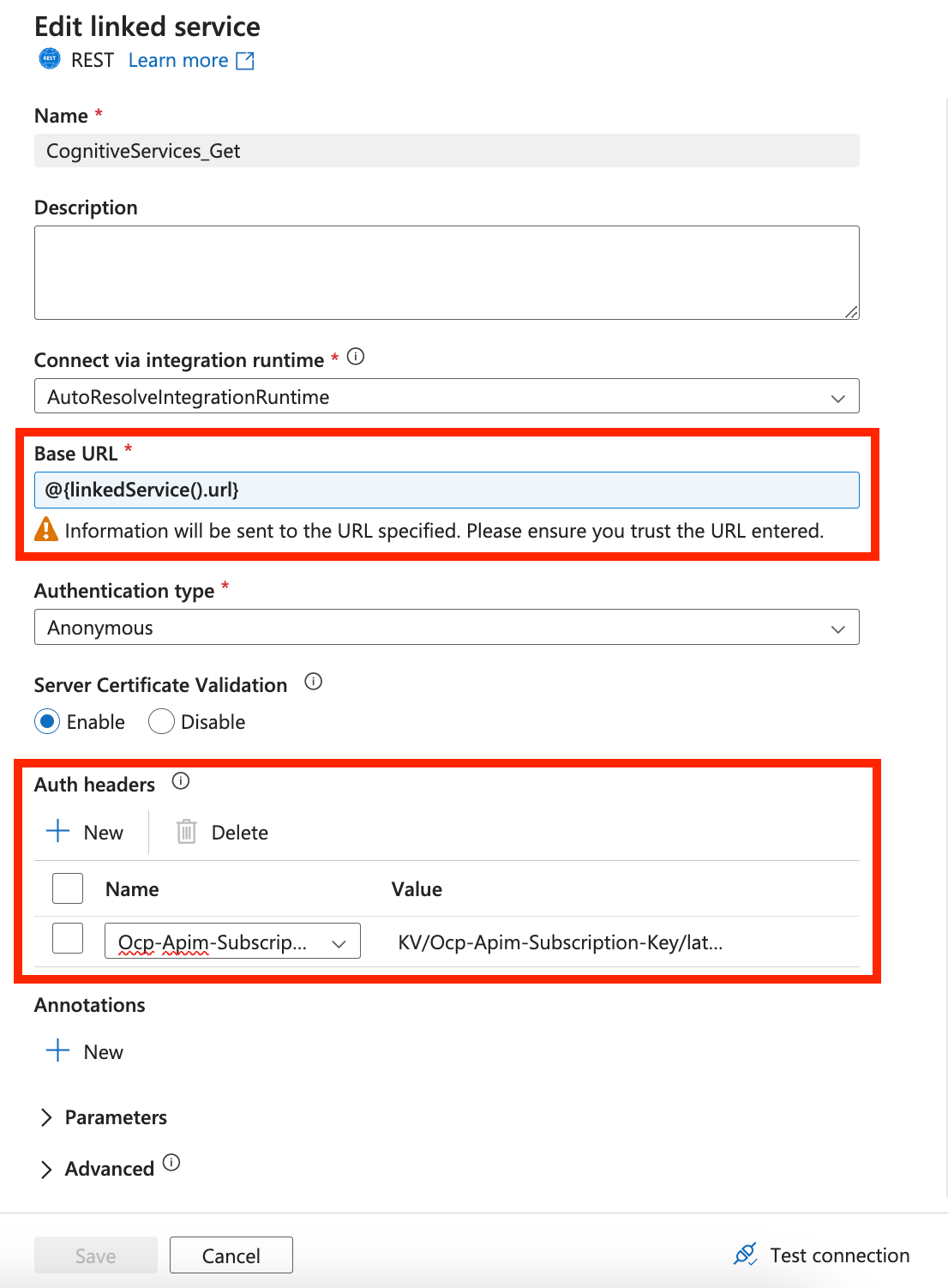
Creare una nuova connessione all'archivio di archiviazione di destinazione o scegliere una connessione esistente. La destinazione scelta è la posizione in cui vengono archiviati i dati PDF estratti.

Selezionare Usa questo modello.
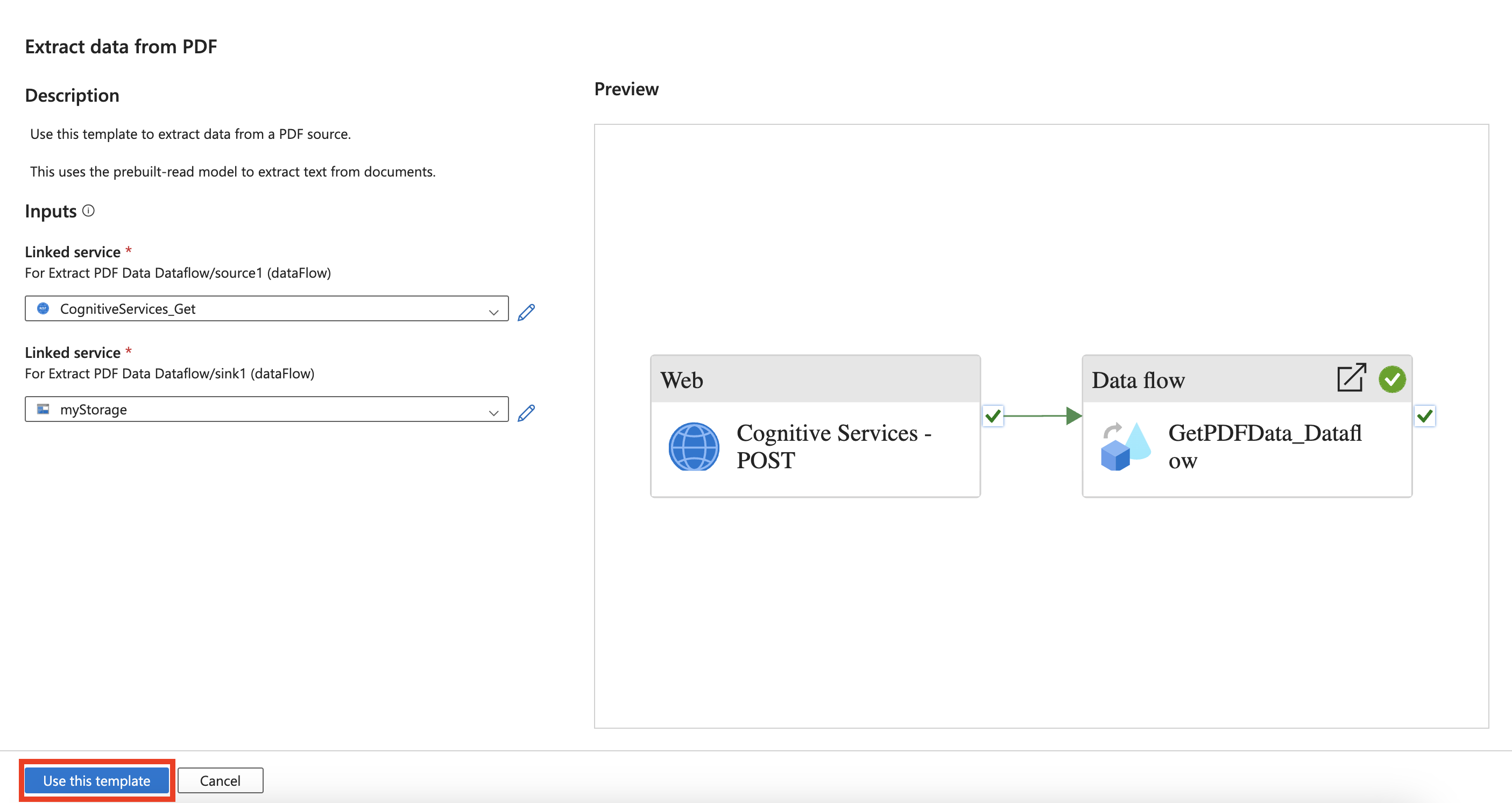
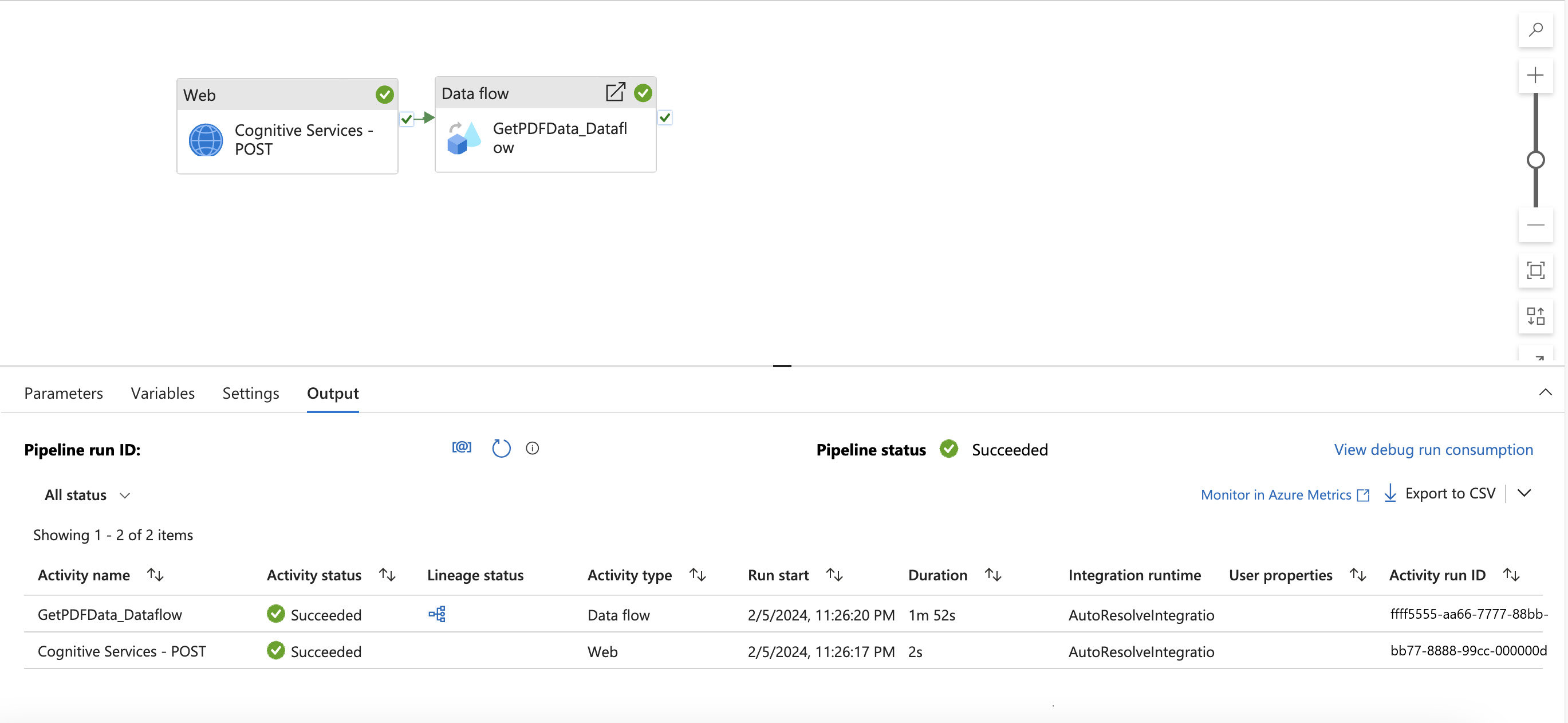
Verrà visualizzata la pipeline seguente.
Passare all'attività Flusso di dati e trovare Impostazioni. Qui è necessario aggiungere contenuto dinamico per il parametro url del servizio collegato. Dopo aver fatto clic su Aggiungi contenuto dinamico, verrà aperto il generatore di espressioni pipeline. Selezionare Servizi cognitivi - Output attività POST. Digitare o copiare e incollare ".output. ADFWebActivityResponseHeaders['Operation-Location']." Nel generatore di espressioni dovrebbe essere visualizzata l'espressione seguente.
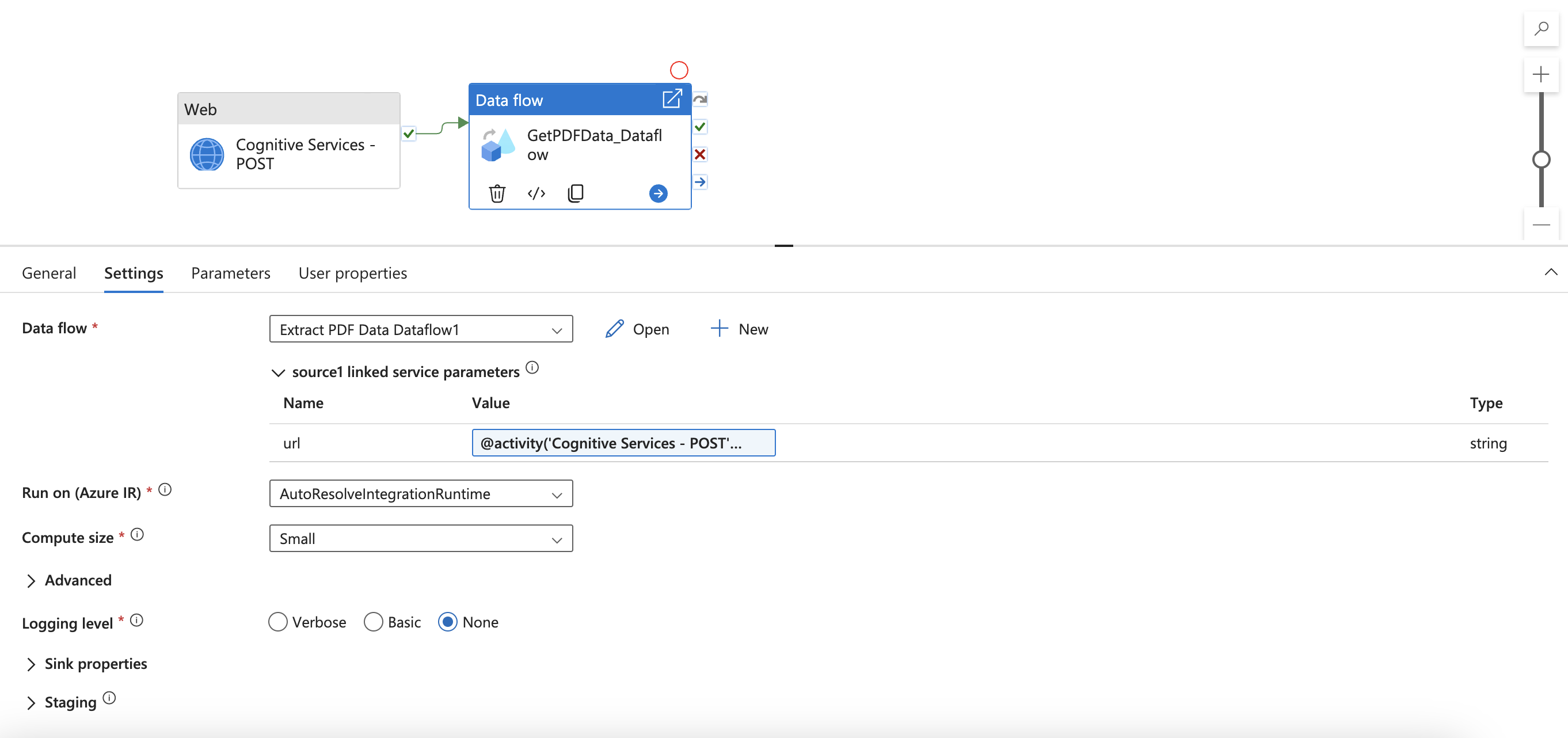
Fare clic su OK per tornare alla pipeline.
Selezionare quindi Debug.
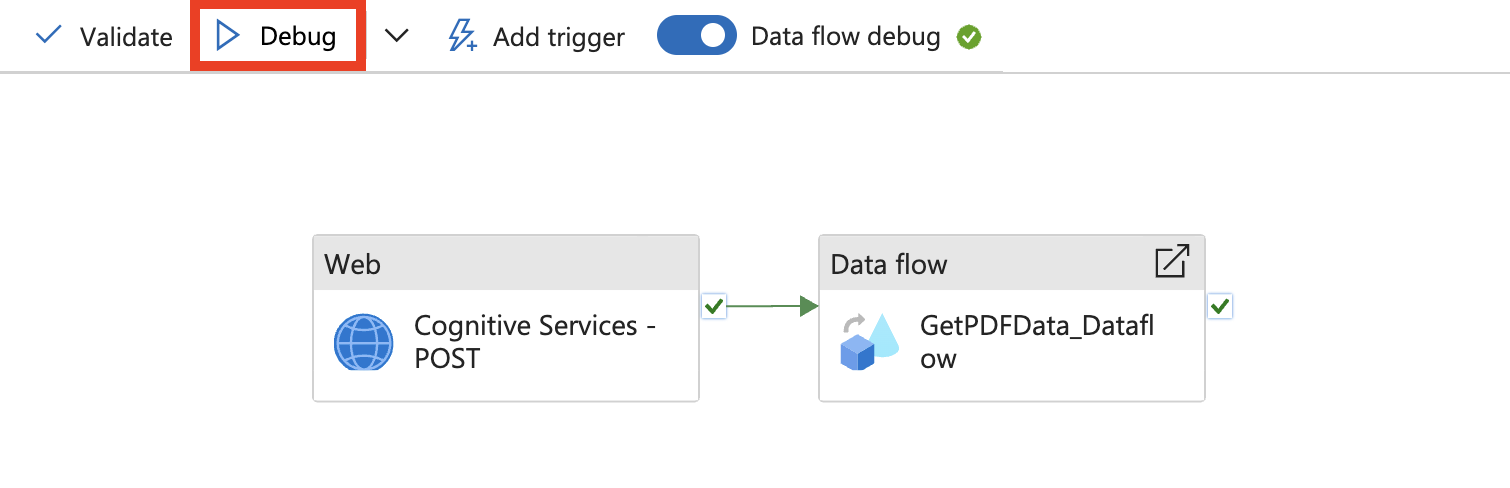
Immettere i valori dei parametri, esaminare i risultati e pubblicare.