Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
L'attività di streaming di HDInsight in una pipeline di Azure Data Factory o Synapse Analytics esegue i programmi in un cluster HDInsightdell'utente oppure on demand. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate.
Per altre informazioni, leggere gli articoli introduttivi per Azure Data Factory e Synapse Analytics ed eseguire Tutorial: transform data prima di leggere questo articolo.
Aggiungere un'attività Streaming di HDInsight a una pipeline tramite interfaccia utente
Per usare un'attività di streaming HDInsight in una pipeline, completare la procedura seguente:
Cerca Streaming nel riquadro delle attività della pipeline e trascina un'attività di Streaming nell'area di disegno della pipeline.
Selezionare la nuova attività Streaming nell'area di disegno, se non è già selezionata.
Selezionare la scheda Cluster HDI per selezionare o creare un nuovo servizio collegato in un cluster HDInsight che verrà usato per eseguire l'attività di streaming.
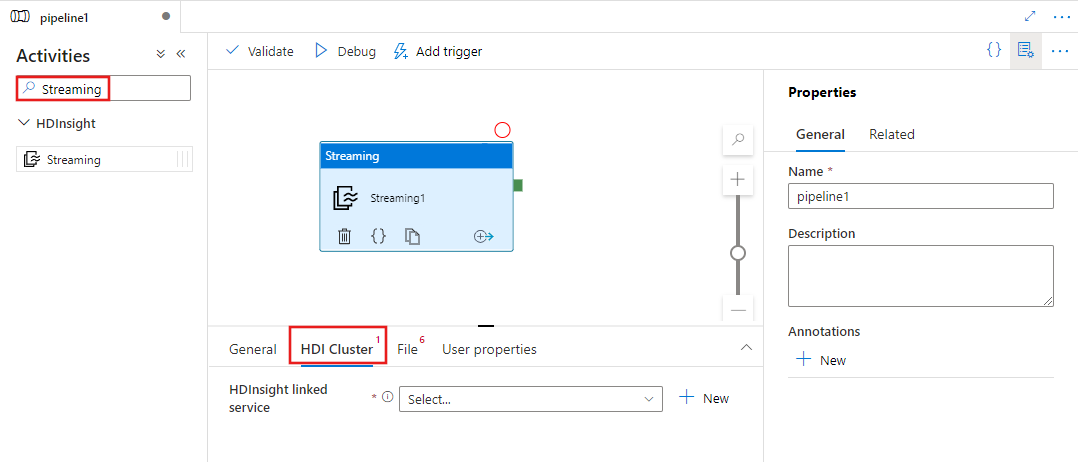
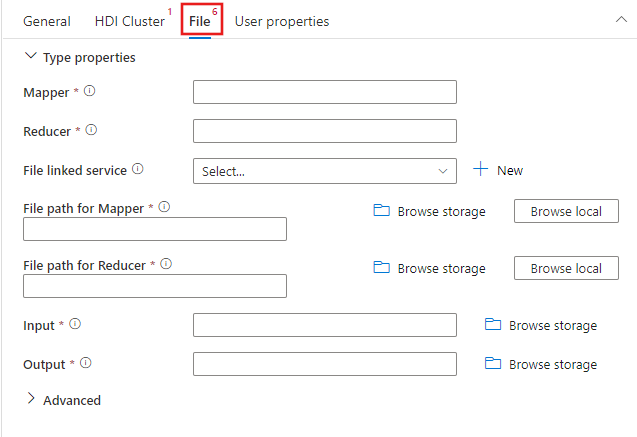
Selezionare la scheda File per specificare i nomi del mapper e del riduttore per il job di streaming e selezionare o creare un nuovo servizio collegato a un account di archiviazione di Azure che ospiterà i file del mapper, del riduttore, dell'input e dell'output per il job. È anche possibile configurare dettagli avanzati, tra cui la configurazione di debug, gli argomenti e i parametri da passare al processo.
Esempio di JSON
{
"name": "Streaming Activity",
"description": "Description",
"type": "HDInsightStreaming",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mapper": "MyMapper.exe",
"reducer": "MyReducer.exe",
"combiner": "MyCombiner.exe",
"fileLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"filePaths": [
"<containername>/example/apps/MyMapper.exe",
"<containername>/example/apps/MyReducer.exe",
"<containername>/example/apps/MyCombiner.exe"
],
"input": "wasb://<containername>@<accountname>.blob.core.windows.net/example/input/MapperInput.txt",
"output": "wasb://<containername>@<accountname>.blob.core.windows.net/example/output/ReducerOutput.txt",
"commandEnvironment": [
"CmdEnvVarName=CmdEnvVarValue"
],
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Dettagli sintassi
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| nome | Nome dell'attività | Sì |
| descrizione | Testo che descrive l'uso dell'attività | No |
| tipo | Per l'attività di streaming di Hadoop, il tipo di attività è HDInsightStreaming | Sì |
| nomeServizioCollegato | Riferimento al cluster HDInsight registrato come servizio collegato. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| mapper | Specifica il nome del mapper eseguibile | Sì |
| reducer | Specifica il nome del reducer eseguibile | Sì |
| combinatore | Specifica il nome del combiner eseguibile | No |
| fileLinkedService | Riferimento a un servizio collegato Azure Storage usato per archiviare i programmi Mapper, Combiner e Reducer da eseguire. Sono supportati solo Azure Blob Storage e ADLS Gen2. Se non si specifica questo servizio collegato, viene usato il servizio collegato Azure Storage definito nel servizio collegato HDInsight. | No |
| percorso del file | Specificare una matrice di percorsi per i programmi Mapper, Combiner e Reducer archiviati nella Azure Storage a cui fa riferimento fileLinkedService. Per il percorso viene applicata la distinzione tra maiuscole e minuscole. | Sì |
| input | Specifica il percorso WASB al file di input per il Mapper. | Sì |
| risultato | Specifica il percorso WASB del file di output per il reducer. | Sì |
| getDebugInfo | Specifica quando i file di log vengono copiati nel Azure Storage usato dal cluster HDInsight (o) specificato da scriptLinkedService. Valori consentiti: Nessuno, Sempre o Errore. Valore predefinito: None. | No |
| argomenti | Specifica una matrice di argomenti per un processo Hadoop. Gli argomenti vengono passati a ogni attività come argomenti della riga di comando. | No |
| definisce | Specificare i parametri come coppie chiave/valore per fare riferimento a essi nello script Hive. | No |
Contenuto correlato
Vedere gli articoli seguenti, che illustrano altre modalità di trasformazione dei dati: