Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità è in versione beta. Gli amministratori dell'account possono controllare l'accesso a questa funzionalità dalla pagina Anteprime della console dell'account. Consultare Gestisci anteprime Azure Databricks.
Con l'integrazione dell'agente di codifica Azure Databricks, è possibile gestire l'accesso e l'utilizzo per agenti di codifica come Cursor, interfaccia della riga di comando gemini e interfaccia della riga di comando codex. Basato su Unity AI Gateway, offre tabelle di limitazione della velocità, rilevamento dell'utilizzo e inferenza per gli strumenti di codifica.
Funzionalità
- Accesso: accesso diretto a vari strumenti e modelli di codifica, tutti sotto una fattura.
- Osservabilità: un singolo dashboard unificato per tenere traccia dell'utilizzo, della spesa e delle metriche in tutti gli strumenti di codifica.
- Governance unificata: gli amministratori possono gestire le autorizzazioni del modello e i limiti di frequenza direttamente tramite Unity AI Gateway.
Requisiti
- Anteprima del Gateway di Intelligenza Artificiale Unity abilitata per l'account. Consultare Gestisci anteprime Azure Databricks.
- Un'area di lavoro Azure Databricks in un'area Unity AI Gateway supportata.
- Catalogo Unity abilitato per l'area di lavoro. Vedere Abilitare un'area di lavoro per il Catalogo Unity.
Agenti supportati
Gli agenti di codifica seguenti sono supportati e altre integrazioni elencate nell'interfaccia utente del gateway di intelligenza artificiale:
Configurazione
Cursor
Per configurare Cursor per l'uso degli endpoint del Gateway AI di Unity:
Passaggio 1: Configurare l'URL di base e la chiave API
Aprire Cursore e passare a Impostazioni>Impostazioni Cursore>Modelli>Chiavi API.
Abilitare Override OpenAI Base URL (Esegui override dell'URL di base OpenAI) e immettere l'URL:
https://<ai-gateway-url>/cursor/v1Sostituire
<ai-gateway-url>con l'URL dell'endpoint del gateway di intelligenza artificiale Unity.Incollare il token di accesso personale Azure Databricks nel campo OpenAI API Key.
Passaggio 2: Aggiungere modelli personalizzati
- Fare clic su + Aggiungi modello personalizzato in Impostazioni cursore.
- Aggiungere il nome dell'endpoint del gateway di intelligenza artificiale Unity e abilitare l'alternatore.
Annotazioni
Attualmente sono supportati solo gli endpoint del modello di base creati Azure Databricks.
Passaggio 3: Testare l'integrazione
- Aprire la modalità Ask con
Cmd+L(macOS) oCtrl+L(Windows/Linux) e selezionare il modello. - Inviare un messaggio. Tutte le richieste ora instradano attraverso Azure Databricks.
Interfaccia della riga di comando Codex
Passaggio 1: Installare o aggiornare Codex CLI
Installare o aggiornare alla versione 0.118 o successive di Codex CLI:
npm install -g @openai/codex@latest
Passaggio 2: Creare o aggiornare il file di configurazione Codex
Creare o modificare il file di configurazione Codex in ~/.codex/config.toml:
profile = "default"
[profiles.default]
model_provider = "Databricks"
[model_providers.Databricks]
name = "Databricks :re[ai-gateway]"
base_url = "<ai-gateway-url>/codex/v1"
wire_api = "responses"
[model_providers.Databricks.auth]
command = "sh"
args = ["-c", "databricks auth token --host <workspace-url> --output json | jq -r '.access_token'"]
timeout_ms = 5000
refresh_interval_ms = 1800000
Sostituire quanto segue:
-
<ai-gateway-url>inbase_urlcon l'URL dell'endpoint del gateway di Intelligenza Artificiale Unity. -
<workspace-url>nel campoargscon l'URL dell'area di lavoro Azure Databricks.
Passaggio 3: Eseguire l'autenticazione nell'area di lavoro
Annotazioni
È necessario eseguire questa operazione una sola volta. Non è necessario ripetere l'autenticazione ogni volta che si avvia Codex.
Assicurati prima di tutto di avere installato l'interfaccia a riga di comando di Azure Databricks. Per istruzioni, vedere Installare o aggiornare l'interfaccia della riga di comando di Databricks .
Eseguire quindi l'autenticazione:
databricks auth login --host <workspace-url>
Sostituire <workspace-url> con l'URL dell'area di lavoro Azure Databricks.
Passaggio 4: Avviare Codex
codex
Per modificare il modello, usare /model.
Interfaccia della riga di comando gemini
Passaggio 1: Installare la versione più recente dell'interfaccia della riga di comando di Gemini
npm install -g @google/gemini-cli@nightly
Passaggio 2: Configurare le variabili di ambiente
Creare un file ~/.gemini/.env e aggiungere la configurazione seguente. Per altri dettagli, vedere la documentazione sull'autenticazione del CLI Gemini.
GEMINI_MODEL=databricks-gemini-2-5-flash
GOOGLE_GEMINI_BASE_URL=https://<ai-gateway-url>/gemini
GEMINI_API_KEY_AUTH_MECHANISM="bearer"
GEMINI_API_KEY=<databricks_pat_token>
Sostituire <ai-gateway-url> con l'URL dell'endpoint di Unity AI Gateway e <databricks_pat_token> con il token di accesso personale.
Dashboard
Dopo aver rilevato l'utilizzo dell'agente di codifica tramite Unity AI Gateway, è possibile visualizzare e monitorare le metriche nel dashboard esistente.
Per accedere al dashboard, selezionare Visualizza dashboard nella pagina Gateway di intelligenza artificiale. Verrà creato un dashboard preconfigurato con grafici per l'utilizzo dello strumento di codifica.

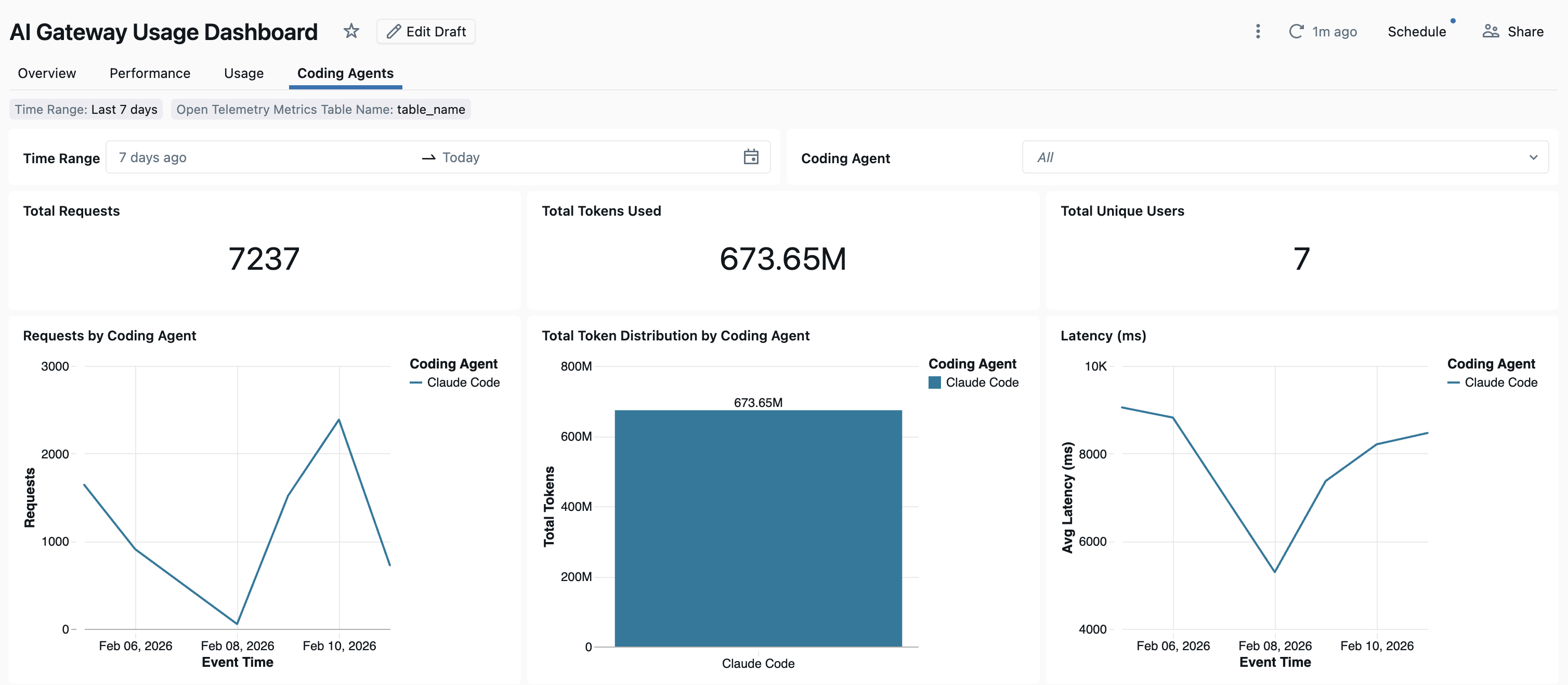
Configurare la raccolta dati OpenTelemetry
Azure Databricks supporta l'esportazione di metriche e log OpenTelemetry dagli agenti di codifica alle tabelle Delta gestite da Unity Catalog. Tutte le metriche sono dati delle serie temporali esportati usando il protocollo di metrica standard OpenTelemetry e i log vengono esportati usando il protocollo di log OpenTelemetry.
Requisiti
- OpenTelemetry in Azure Databricks anteprima abilitata. Consultare Gestisci anteprime Azure Databricks.
Passaggio 1: Creare tabelle OpenTelemetry nel catalogo unity
Creare tabelle gestite da Unity Catalog preconfigurate con gli schemi per metriche e log di OpenTelemetry.
Tabella delle metriche
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_metrics (
name STRING,
description STRING,
unit STRING,
metric_type STRING,
gauge STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
sum STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
value: DOUBLE,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
aggregation_temporality: STRING,
is_monotonic: BOOLEAN
>,
histogram STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
bucket_counts: ARRAY<LONG>,
explicit_bounds: ARRAY<DOUBLE>,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
attributes: MAP<STRING, STRING>,
flags: INT,
min: DOUBLE,
max: DOUBLE,
aggregation_temporality: STRING
>,
exponential_histogram STRUCT<
attributes: MAP<STRING, STRING>,
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
scale: INT,
zero_count: LONG,
positive_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
negative_bucket: STRUCT<
offset: INT,
bucket_counts: ARRAY<LONG>
>,
flags: INT,
exemplars: ARRAY<STRUCT<
time_unix_nano: LONG,
value: DOUBLE,
span_id: STRING,
trace_id: STRING,
filtered_attributes: MAP<STRING, STRING>
>>,
min: DOUBLE,
max: DOUBLE,
zero_threshold: DOUBLE,
aggregation_temporality: STRING
>,
summary STRUCT<
start_time_unix_nano: LONG,
time_unix_nano: LONG,
count: LONG,
sum: DOUBLE,
quantile_values: ARRAY<STRUCT<
quantile: DOUBLE,
value: DOUBLE
>>,
attributes: MAP<STRING, STRING>,
flags: INT
>,
metadata MAP<STRING, STRING>,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
metric_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
Tabella Registri
CREATE TABLE <catalog>.<schema>.<table_prefix>_otel_logs (
event_name STRING,
trace_id STRING,
span_id STRING,
time_unix_nano LONG,
observed_time_unix_nano LONG,
severity_number STRING,
severity_text STRING,
body STRING,
attributes MAP<STRING, STRING>,
dropped_attributes_count INT,
flags INT,
resource STRUCT<
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
resource_schema_url STRING,
instrumentation_scope STRUCT<
name: STRING,
version: STRING,
attributes: MAP<STRING, STRING>,
dropped_attributes_count: INT
>,
log_schema_url STRING
) USING DELTA
TBLPROPERTIES (
'otel.schemaVersion' = 'v1'
)
Passaggio 2: Aggiornare i valori var di env nell'agente di codifica
In qualsiasi agente di codifica con supporto delle metriche OpenTelemetry abilitato, configurare le variabili di ambiente seguenti.
{
"OTEL_METRICS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_METRICS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_METRICS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/metrics",
"OTEL_EXPORTER_OTLP_METRICS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_metrics",
"OTEL_METRIC_EXPORT_INTERVAL": "10000",
"OTEL_LOGS_EXPORTER": "otlp",
"OTEL_EXPORTER_OTLP_LOGS_PROTOCOL": "http/protobuf",
"OTEL_EXPORTER_OTLP_LOGS_ENDPOINT": "https://<workspace-url>/api/2.0/otel/v1/logs",
"OTEL_EXPORTER_OTLP_LOGS_HEADERS": "content-type=application/x-protobuf,Authorization=Bearer <databricks_pat_token>,X-Databricks-UC-Table-Name=<catalog>.<schema>.<table_prefix>_otel_logs",
"OTEL_LOGS_EXPORT_INTERVAL": "5000"
}
Passaggio 3: Eseguire l'agente di codifica.
I dati devono essere propagati alle tabelle di Unity Catalog entro 5 minuti.
Passaggi successivi
- Gateway di intelligenza artificiale Unity per endpoint LLM
- Configurare gli endpoint del gateway di intelligenza artificiale Unity
- Eseguire query sugli endpoint del Gateway di Intelligenza Artificiale Unity
- Monitorare l'utilizzo per gli endpoint del Gateway AI di Unity
- Monitorare i modelli usando le tabelle di inferenza
- Configurare i limiti di frequenza per gli endpoint del Gateway AI di Unity