Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Questa funzionalità è in versione beta. Gli amministratori dell'account possono controllare l'accesso a questa funzionalità dalla pagina Anteprime della console dell'account. Consultare Gestisci anteprime Azure Databricks.
Questa pagina descrive come monitorare l'utilizzo per gli endpoint del gateway di intelligenza artificiale Unity usando la tabella del sistema di rilevamento dell'utilizzo.
La tabella di rilevamento dell'utilizzo acquisisce automaticamente i dettagli della richiesta e della risposta per un endpoint, registrando metriche essenziali come l'utilizzo dei token e la latenza. È possibile usare i dati in questa tabella per monitorare l'utilizzo, tenere traccia dei costi e ottenere informazioni dettagliate sulle prestazioni e sull'utilizzo degli endpoint.
Requisiti
- Anteprima del Gateway di Intelligenza Artificiale Unity abilitata per l'account. Consultare Gestisci anteprime Azure Databricks.
- Un'area di lavoro Azure Databricks in un'area Unity AI Gateway supportata.
- Catalogo Unity abilitato per l'area di lavoro. Vedere Abilitare un'area di lavoro per il Catalogo Unity.
Eseguire una query sulla tabella di utilizzo
Unity AI Gateway registra i dati di utilizzo nella tabella sistema system.ai_gateway.usage. È possibile visualizzare la tabella nell'interfaccia utente oppure eseguire query sulla tabella da Databricks SQL o da un notebook.
Annotazioni
Solo gli amministratori dell'account dispongono dell'autorizzazione per visualizzare o eseguire query sulla system.ai_gateway.usage tabella.
Per visualizzare la tabella nell'interfaccia utente, fare clic sul collegamento tabella di rilevamento dell'utilizzo nella pagina dell'endpoint per aprire la tabella in Esplora cataloghi.
Per eseguire query sulla tabella da Databricks SQL o da un notebook:
SELECT * FROM system.ai_gateway.usage;
Dashboard di utilizzo integrato
Importare il dashboard di utilizzo predefinito
Gli amministratori degli account possono importare un dashboard di utilizzo predefinito del gateway di intelligenza artificiale di Unity facendo clic su Crea dashboard nella pagina Gateway di intelligenza artificiale per monitorare l'utilizzo, tenere traccia dei costi e ottenere informazioni dettagliate sulle prestazioni e sull'utilizzo degli endpoint. Il dashboard viene pubblicato con le autorizzazioni dell'amministratore dell'account, consentendo ai visualizzatori di eseguire query usando le autorizzazioni dell'editore. Per altri dettagli, vedere Pubblicare un dashboard . Gli amministratori dell'account possono anche aggiornare il data warehouse utilizzato per eseguire le query del dashboard, che si applicano a tutte le query successive.

Annotazioni
L'importazione del dashboard è limitata agli amministratori dell'account perché richiede SELECT autorizzazioni per la system.ai_gateway.usage tabella. I dati del dashboard sono soggetti ai usage criteri di conservazione della tabella. Consulta Quali tabelle di sistema sono disponibili?.
Per ricaricare il dashboard dal modello più recente, gli amministratori dell'account possono fare clic su Riimporta dashboard nella pagina Gateway di intelligenza artificiale. In questo modo il dashboard viene aggiornato con eventuali nuove visualizzazioni o miglioramenti del modello mantenendo al tempo stesso la configurazione del warehouse.
Visualizzare il dashboard di utilizzo
Per visualizzare il dashboard, fare clic su Visualizza dashboard nella pagina Gateway di intelligenza artificiale. Il dashboard predefinito offre visibilità completa sull'utilizzo e sulle prestazioni degli endpoint del gateway di intelligenza artificiale unity. Include più pagine che monitora le richieste, il consumo di token, le metriche di latenza, le percentuali di errore e l'attività dell'agente di codifica.

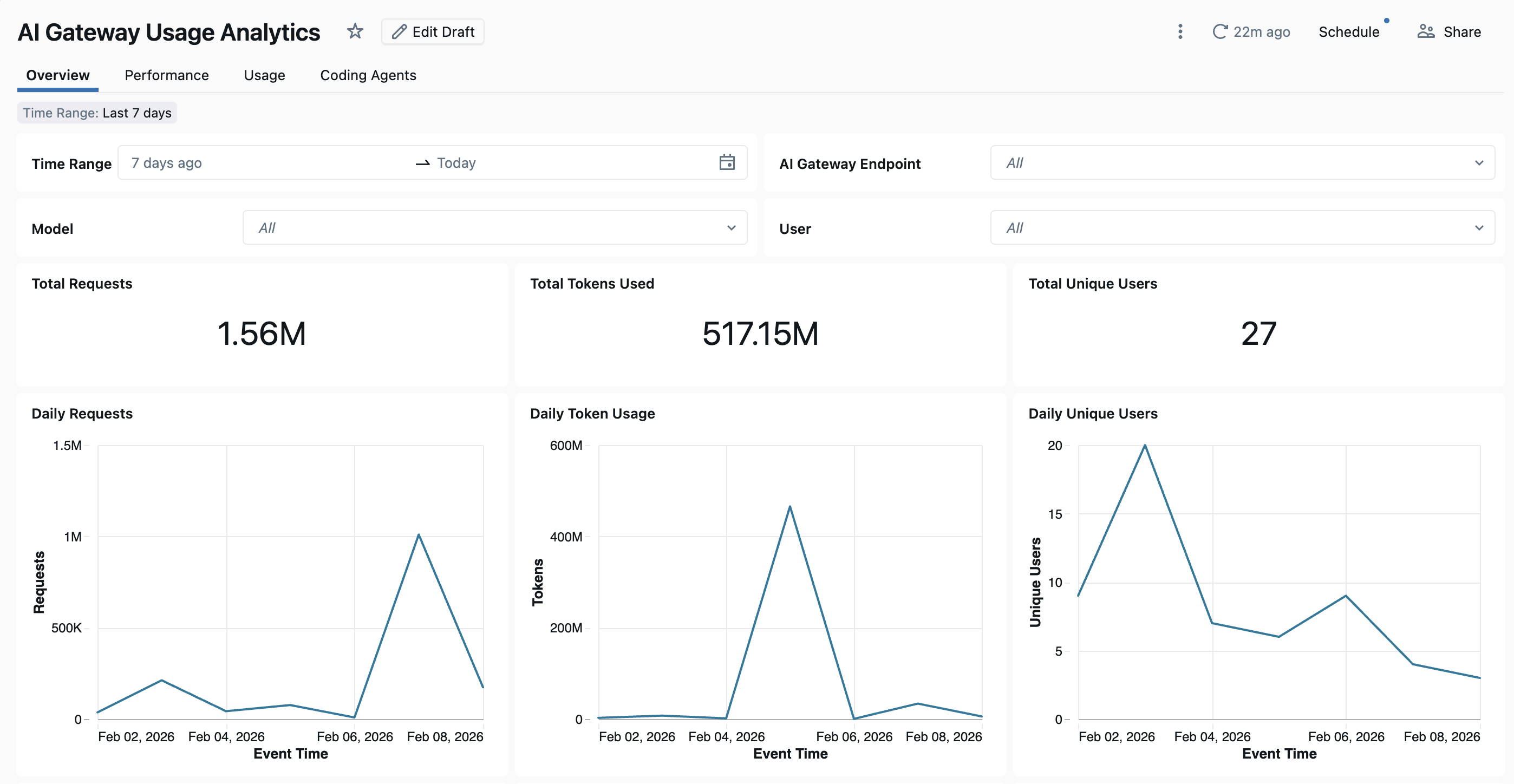
Il dashboard fornisce l'analisi tra aree di lavoro per impostazione predefinita. Tutte le pagine del dashboard possono essere filtrate in base all'intervallo di date e all'ID dell'area di lavoro.
- Scheda Panoramica: mostra le metriche di utilizzo di alto livello, tra cui il volume delle richieste giornaliere, le tendenze di utilizzo dei token nel tempo, i principali utenti per consumo di token e il numero totale di utenti univoci. Usare questa scheda per ottenere uno snapshot rapido dell'attività complessiva di Unity AI Gateway e identificare gli utenti e i modelli più attivi.
- Scheda Prestazioni: tiene traccia delle metriche delle prestazioni chiave, inclusi i percentili di latenza (P50, P90, P95, P99), il tempo per il primo byte, le percentuali di errore e le distribuzioni del codice di stato HTTP. Usare questa scheda per monitorare l'integrità degli endpoint e identificare i colli di bottiglia o i problemi di affidabilità delle prestazioni.
- Scheda Utilizzo: mostra le suddivisioni dettagliate del consumo per endpoint, area di lavoro e richiedente. Questa scheda mostra i modelli di utilizzo dei token, le distribuzioni delle richieste e i rapporti di riscontri nella cache per analizzare e ottimizzare i costi.
- Scheda Codifica agenti: tiene traccia dell'attività degli agenti di codifica integrati, tra cui Cursor, Claude Code, Gemini CLI e Codex CLI. Questa scheda mostra metriche come i giorni attivi, le sessioni di codifica, i commit e le righe di codice aggiunti o rimossi per monitorare l'utilizzo degli strumenti di sviluppo. Per altri dettagli, vedere Dashboard dell'agente di codifica .
Schema della tabella di utilizzo
La system.ai_gateway.usage tabella presenta lo schema seguente:
| Nome della colonna | TIPO | Descrzione | Example |
|---|---|---|---|
account_id |
filo | ID dell'account. | 11d77e21-5e05-4196-af72-423257f74974 |
workspace_id |
filo | L’ID dell’area di lavoro. | 1653573648247579 |
request_id |
filo | Identificatore univoco per la richiesta. | b4a47a30-0e18-4ae3-9a7f-29bcb07e0f00 |
schema_version |
INTEGER | Versione dello schema del record di utilizzo. | 1 |
endpoint_id |
filo | ID univoco dell'endpoint del gateway di Intelligenza Artificiale Unity. | 43addf89-d802-3ca2-bd54-fe4d2a60d58a |
endpoint_name |
filo | Nome dell'endpoint del gateway di intelligenza artificiale Unity. | databricks-gpt-5-2 |
endpoint_tags |
MAP | Tag associati all'endpoint. | {"team": "engineering"} |
endpoint_metadata |
STRUCT | Metadati dell'endpoint, tra cui creator, creation_time, last_updated_time, destinations, inference_table e fallbacks. |
{"creator": "user.name@email.com", "creation_time": "2026-01-06T12:00:00.000Z", ...} |
event_time |
TIMESTAMP | Timestamp in cui è stata ricevuta la richiesta. | 2026-01-20T19:48:08.000+00:00 |
latency_ms |
LONG | Latenza totale in millisecondi. | 300 |
time_to_first_byte_ms |
LONG | Tempo di primo byte in millisecondi. | 300 |
destination_type |
filo | Tipo di destinazione, ad esempio modello esterno o modello di base. | PAY_PER_TOKEN_FOUNDATION_MODEL |
destination_name |
filo | Nome del modello o del provider di destinazione. | databricks-gpt-5-2 |
destination_id |
filo | ID univoco della destinazione. | 507e7456151b3cc89e05ff48161efb87 |
destination_model |
filo | Modello specifico utilizzato per la richiesta. | GPT-5.2 |
requester |
filo | ID dell'utente o dell'entità servizio che ha effettuato la richiesta. | user.name@email.com |
requester_type |
filo | Tipo di richiedente (utente, entità servizio o gruppo di utenti). | USER |
ip_address |
filo | Indirizzo IP del richiedente. | 1.2.3.4 |
url |
filo | URL della richiesta. | https://<ai-gateway-url>/mlflow/v1/chat/completions |
user_agent |
filo | Agente utente del richiedente. | OpenAI/Python 2.13.0 |
api_type |
filo | Tipo di chiamata API (ad esempio, chat, completamenti o incorporamenti). | mlflow/v1/chat/completions |
request_tags |
MAP | Tag associati alla richiesta. | {"team": "engineering"} |
input_tokens |
LONG | Numero di token di input. | 100 |
output_tokens |
LONG | Numero di token in uscita. | 100 |
total_tokens |
LONG | Numero totale di token (input e output). | 200 |
token_details |
STRUCT | Suddivisione dettagliata dei token, tra cui cache_read_input_tokens, cache_creation_input_tokense output_reasoning_tokens. |
{"cache_read_input_tokens": 100, ...} |
response_content_type |
filo | Tipo di contenuto della risposta. | application/json |
status_code |
INT | Il codice di stato HTTP della risposta. | 200 |
routing_information |
STRUCT | Dettagli del routing per i tentativi di fallback . Contiene una attempts matrice con priority, actiondestination, destination_id, status_code, error_codelatency_ms, , , start_time, e end_time per ogni modello provato durante la richiesta. |
{"attempts": [{"priority": "1", ...}]} |
Passaggi successivi
- Gateway di intelligenza artificiale Unity per endpoint LLM
- Configurare gli endpoint del gateway di Unity AI
- Eseguire query sugli endpoint del Gateway di Intelligenza Artificiale Unity
- Integrazione con agenti di codifica
- Monitorare i modelli usando le tabelle di inferenza
- Configurare i limiti di frequenza per gli endpoint del Gateway AI di Unity