Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Batch e streaming sono due semantiche di elaborazione dati usate per carichi di lavoro di progettazione dei dati, tra cui inserimento, trasformazione ed elaborazione in tempo reale.
Lo streaming è comunemente associato a bassa latenza e all'elaborazione continua da bus di messaggi, ad esempio Apache Kafka.
Tuttavia, in Azure Databricks ha una definizione più estesa. Il motore sottostante delle pipeline di Lakeflow (Apache Spark e Structured Streaming) ha un'architettura unificata per l'elaborazione batch e di streaming:
- Il motore può trattare origini come l'archiviazione di oggetti cloud e Delta Lake come origini di streaming per un'elaborazione incrementale efficiente.
- L'elaborazione dei flussi può essere eseguita sia in modalità a richiesta che continua, offrendo la flessibilità necessaria per controllare i compromessi tra costi e prestazioni per i carichi di lavoro di streaming.
Di seguito sono riportate le differenze semantiche fondamentali che distinguono batch e streaming, inclusi i relativi vantaggi e svantaggi e considerazioni per la scelta dei carichi di lavoro.
Semantica di gruppo
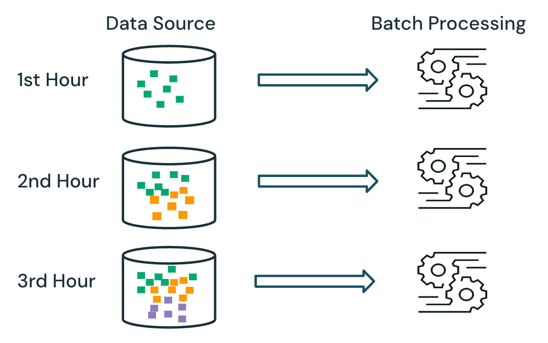
Con l'elaborazione batch, il motore non tiene traccia dei dati già elaborati nell'origine. Tutti i dati attualmente disponibili nell'origine vengono elaborati al momento dell'elaborazione. In pratica, un'origine dati batch viene in genere partizionata logicamente, ad esempio per giorno o area, per limitare la rielaborazione dei dati.
Ad esempio, il calcolo del prezzo medio delle vendite degli articoli, aggregato a una granularità oraria, per un evento di vendita eseguito da una società di e-commerce può essere pianificato come elaborazione batch per calcolare il prezzo medio delle vendite ogni ora. Con il batch, i dati delle ore precedenti vengono rielaborati ogni ora e i risultati calcolati in precedenza vengono sovrascritti per riflettere i risultati più recenti.
Semantica di streaming
Con l'elaborazione dei flussi di dati, il motore tiene traccia dei dati elaborati e elabora solo i nuovi dati nelle esecuzioni successive. Nell'esempio precedente è possibile pianificare l'elaborazione in streaming anziché l'elaborazione batch per calcolare il prezzo medio di vendita ogni ora. Con lo streaming, solo i nuovi dati aggiunti all'origine dall'ultima esecuzione vengono elaborati. I risultati appena calcolati devono essere aggiunti ai risultati calcolati in precedenza per controllare i risultati completi.
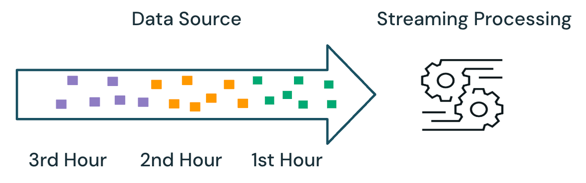
Batch contro streaming
Nell'esempio precedente, lo streaming è migliore dell'elaborazione batch perché non elabora gli stessi dati elaborati nelle esecuzioni precedenti. Tuttavia, l'elaborazione in streaming diventa più complessa con scenari come dati fuori ordine e in ritardo nell'origine.
Un esempio di dati di arrivo in ritardo è se alcuni dati di vendita della prima ora non arrivano all'origine fino alla seconda ora:
- Nell'elaborazione batch, i dati di arrivo in ritardo della prima ora vengono elaborati con i dati della seconda ora e i dati esistenti della prima ora. I risultati precedenti della prima ora vengono sovrascritti e corretti con i dati pervenuti in ritardo.
- Nell'elaborazione in streaming, i dati che arrivano in ritardo dalla prima ora vengono elaborati senza alcuno degli altri dati della prima ora che sono già stati elaborati. La logica di elaborazione deve archiviare le informazioni sulla somma e sul conteggio dei calcoli medi della prima ora per aggiornare correttamente i risultati precedenti.
Queste complessità di streaming vengono in genere introdotte quando l'elaborazione è con mantenimento dello stato, ad esempio join, aggregazioni e deduplicazioni.
Per l'elaborazione in streaming senza stato, come l'aggiunta di nuovi dati dalla sorgente, la gestione dei dati fuori ordine e in ritardo è meno complessa, perché i dati in ritardo possono essere aggiunti ai risultati precedenti man mano che arrivano alla sorgente.
La tabella seguente illustra i vantaggi e i svantaggi dell'elaborazione batch e di streaming e le diverse funzionalità del prodotto che supportano queste due semantiche di elaborazione in Databricks Lakeflow.
| Elaborazione semantica | Vantaggi | Svantaggi | Prodotti di ingegneria dei dati |
|---|---|---|---|
| Gruppo |
|
|
|
| Trasmissione in diretta |
|
|
|
Consigli
La tabella seguente illustra la semantica di elaborazione consigliata in base alle caratteristiche dei carichi di lavoro di elaborazione dati a ogni livello dell'architettura medallion.
| Livello medaglione | Caratteristiche del carico di lavoro | Raccomandazione |
|---|---|---|
| Bronzo |
|
|
| Argento |
|
|
| Oro |
|
|