Procedure consigliate per Il catalogo Unity
Questo documento fornisce consigli per l'uso del catalogo Unity e della condivisione delta per soddisfare le esigenze di governance dei dati.
Unity Catalog è una soluzione di governance con granularità fine per i dati e l'intelligenza artificiale nella piattaforma Databricks. Semplifica la sicurezza e la governance dei dati fornendo una posizione centrale per amministrare e controllare l'accesso ai dati. La condivisione differenziale è una piattaforma di condivisione dei dati sicura che consente di condividere dati in Azure Databricks con utenti esterni all'organizzazione. Usa Unity Catalog per gestire e controllare il comportamento di condivisione.
Blocchi predefiniti per la governance dei dati e l'isolamento dei dati
Per sviluppare un modello di governance dei dati e un piano di isolamento dei dati adatto all'organizzazione, è utile comprendere i blocchi predefiniti principali disponibili quando si crea la soluzione di governance dei dati in Azure Databricks.
Il diagramma seguente illustra la gerarchia dei dati primari in Unity Catalog (alcuni oggetti a protezione diretta sono disattivati per evidenziare la gerarchia di oggetti gestiti in cataloghi).
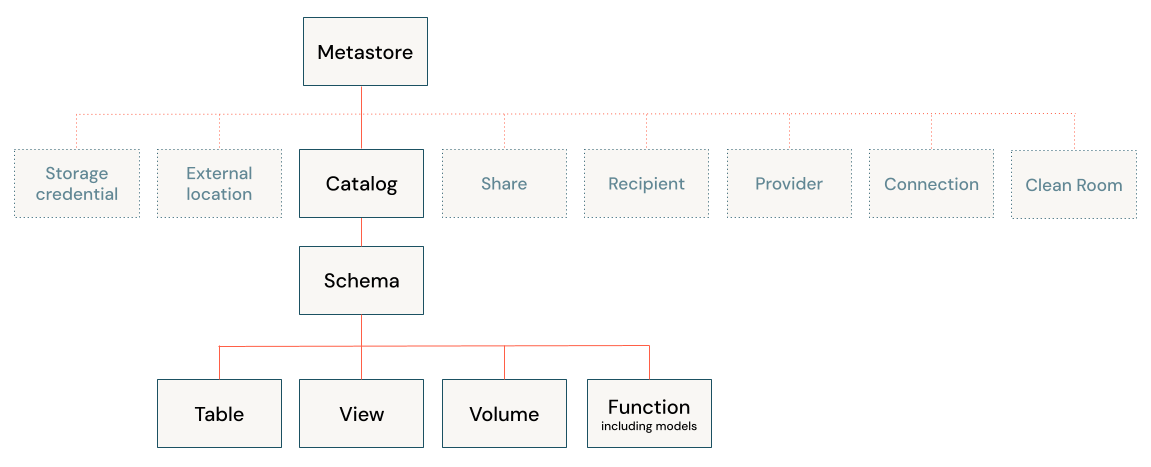
Gli oggetti in tale gerarchia includono quanto segue:
Metastore: un metastore è il contenitore di primo livello degli oggetti nel catalogo unity. I metastore si trovano a livello di account e funzionano come parte superiore della piramide nel modello di governance dei dati di Azure Databricks.
I metastore gestiscono gli asset di dati (tabelle, viste e volumi) e le autorizzazioni che ne regolano l'accesso. Gli amministratori dell'account Azure Databricks possono creare un metastore per ogni area in cui operano e assegnarli a più aree di lavoro di Azure Databricks nella stessa area. Gli amministratori metastore possono gestire tutti gli oggetti nel metastore. Non hanno accesso diretto alle tabelle registrate nel metastore, ma hanno accesso indiretto tramite la possibilità di trasferire la proprietà dell'oggetto dati.
L'archiviazione fisica per qualsiasi metastore specificato è, per impostazione predefinita, isolata dallo spazio di archiviazione per qualsiasi altro metastore nell'account.
I metastore forniscono l'isolamento a livello di area, ma non sono concepiti come unità di isolamento dei dati. L'isolamento dei dati deve iniziare a livello di catalogo.
Catalogo: i cataloghi sono il livello più alto nella gerarchia dei dati (tabella dello schema > del catalogo>, vista/volume) gestito dal metastore del catalogo Unity. Sono concepite come unità primaria di isolamento dei dati in un tipico modello di governance dei dati di Azure Databricks.
I cataloghi rappresentano un raggruppamento logico di schemi, in genere delimitati dai requisiti di accesso ai dati. I cataloghi spesso rispecchiano le unità organizzative o gli ambiti del ciclo di vita dello sviluppo software. È possibile scegliere, ad esempio, di avere un catalogo per i dati di produzione e un catalogo per i dati di sviluppo oppure un catalogo per i dati non dei clienti e uno per i dati sensibili dei clienti.
I cataloghi possono essere archiviati a livello di metastore oppure è possibile configurare un catalogo da archiviare separatamente dal resto del metastore padre. Se l'area di lavoro è stata abilitata automaticamente per Il catalogo Unity, non è disponibile alcuna risorsa di archiviazione a livello di metastore ed è necessario specificare un percorso di archiviazione quando si crea un catalogo.
Se il catalogo è l'unità primaria di isolamento dei dati nel modello di governance dei dati di Azure Databricks, l'area di lavoro è l'ambiente principale per l'uso degli asset di dati. Gli amministratori dei metastore e i proprietari del catalogo possono gestire l'accesso ai cataloghi indipendentemente da aree di lavoro oppure possono associare cataloghi a aree di lavoro specifiche per garantire che determinati tipi di dati vengano elaborati solo in tali aree di lavoro. È possibile che si vogliano separare le aree di lavoro di produzione e sviluppo, ad esempio o un'area di lavoro separata per l'elaborazione dei dati personali.
Per impostazione predefinita, le autorizzazioni di accesso per un oggetto a protezione diretta vengono ereditate dagli elementi figlio di tale oggetto, con cataloghi nella parte superiore della gerarchia. In questo modo è più semplice configurare le regole di accesso predefinite per i dati e specificare regole diverse a ogni livello della gerarchia solo dove sono necessarie.
Schema (database): gli schemi, noti anche come database, sono raggruppamenti logici di dati tabulari (tabelle e viste), dati non tabulari (volumi), funzioni e modelli di Machine Learning. Consentono di organizzare e controllare l'accesso ai dati più granulari rispetto ai cataloghi. In genere rappresentano un singolo caso d'uso, un progetto o una sandbox del team.
Gli schemi possono essere archiviati nella stessa risorsa di archiviazione fisica del catalogo padre oppure è possibile configurare uno schema da archiviare separatamente dal resto del catalogo padre.
Gli amministratori metastore, i proprietari del catalogo padre e i proprietari dello schema possono gestire l'accesso agli schemi.
Tabelle: le tabelle si trovano nel terzo livello dello spazio dei nomi a tre livelli di Unity Catalog. Contengono righe di dati.
Il catalogo unity consente di creare tabelle gestite e tabelle esterne.
Per le tabelle gestite, Il catalogo Unity gestisce completamente il ciclo di vita e il layout dei file. Per impostazione predefinita, le tabelle gestite vengono archiviate nel percorso di archiviazione radice configurato quando si crea un metastore. È invece possibile scegliere di isolare l'archiviazione per le tabelle gestite a livello di catalogo o schema.
Le tabelle esterne sono tabelle il cui ciclo di vita dei dati e il layout dei file vengono gestiti usando il provider di servizi cloud e altre piattaforme dati, non unity catalog. In genere si usano tabelle esterne per registrare grandi quantità di dati esistenti o se è necessario anche l'accesso in scrittura ai dati usando strumenti esterni ai cluster di Azure Databricks e databricks SQL Warehouse. Dopo aver registrato una tabella esterna in un metastore di Unity Catalog, è possibile gestire e controllare l'accesso ad Azure Databricks proprio come è possibile con le tabelle gestite.
I proprietari del catalogo padre e i proprietari dello schema possono gestire l'accesso alle tabelle, in quanto gli amministratori del metastore (indirettamente).
Viste: una vista è un oggetto di sola lettura derivato da una o più tabelle e viste in un metastore.
Righe e colonne: l'accesso a livello di riga e colonna, insieme alla maschera dati, viene concesso usando visualizzazioni dinamiche o filtri di riga e maschere di colonna. Le visualizzazioni dinamiche sono di sola lettura.
Volumi: i volumi risiedono nel terzo livello dello spazio dei nomi a tre livelli di Unity Catalog. Gestiscono dati non tabulari. È possibile usare volumi per archiviare, organizzare e accedere ai file in qualsiasi formato, inclusi dati strutturati, semistrutturati e non strutturati. I file nei volumi non possono essere registrati come tabelle.
Modelli e funzioni: anche se non sono, in senso stretto, asset di dati, modelli registrati e funzioni definite dall'utente possono essere gestiti anche in Unity Catalog e risiedono al livello più basso nella gerarchia degli oggetti. Vedere Gestire il ciclo di vita del modello nel catalogo unity e nelle funzioni definite dall'utente (UDF) nel catalogo unity.
Pianificare il modello di isolamento dei dati
Quando un'organizzazione usa una piattaforma dati come Azure Databricks, spesso è necessario avere limiti di isolamento dei dati tra ambienti (ad esempio sviluppo e produzione) o tra le unità operative dell'organizzazione.
Gli standard di isolamento possono variare per l'organizzazione, ma in genere includono le aspettative seguenti:
- Gli utenti possono accedere solo ai dati in base alle regole di accesso specificate.
- I dati possono essere gestiti solo da persone o team designati.
- I dati sono separati fisicamente nell'archiviazione.
- È possibile accedere ai dati solo in ambienti designati.
La necessità di isolamento dei dati può causare ambienti siloati che possono rendere inutilmente difficile la governance dei dati e la collaborazione. Azure Databricks risolve questo problema usando Unity Catalog, che offre diverse opzioni di isolamento dei dati mantenendo al tempo una piattaforma unificata di governance dei dati. Questa sezione illustra le opzioni di isolamento dei dati disponibili in Azure Databricks e come usarle, indipendentemente dal fatto che si preferisca un modello di governance dei dati centralizzato o uno distribuito.
Gli utenti possono accedere solo ai dati in base alle regole di accesso specificate
La maggior parte delle organizzazioni ha requisiti rigorosi per l'accesso ai dati in base ai requisiti interni o normativi. Esempi tipici di dati che devono essere mantenuti sicuri includono informazioni sullo stipendio dei dipendenti o informazioni di pagamento con carta di credito. L'accesso a questo tipo di informazioni viene in genere controllato e controllato periodicamente. Unity Catalog offre un controllo granulare sugli asset di dati all'interno del catalogo per soddisfare questi standard di settore. Con i controlli forniti da Unity Catalog, gli utenti possono visualizzare ed eseguire query solo sui dati a cui hanno diritto di visualizzare ed eseguire query.
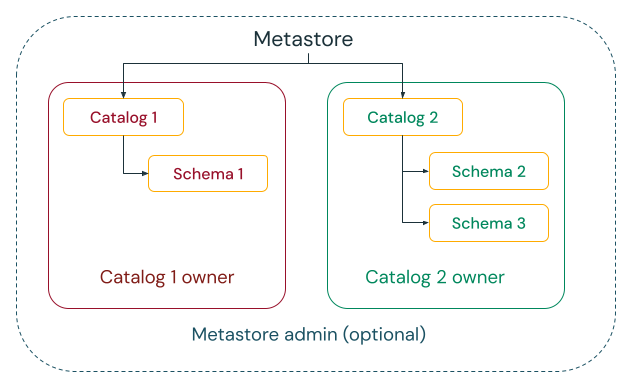
I dati possono essere gestiti solo da persone o team designati
Il catalogo unity offre la possibilità di scegliere tra modelli di governance centralizzati e distribuiti.
Nel modello di governance centralizzato, gli amministratori della governance sono proprietari del metastore e possono assumere la proprietà di qualsiasi oggetto e concedere e revocare le autorizzazioni.
In un modello di governance distribuita, il catalogo o un set di cataloghi è il dominio dati. Il proprietario di tale catalogo può creare e possedere tutti gli asset e gestire la governance all'interno di tale dominio. I proprietari di un determinato dominio possono operare indipendentemente dai proprietari di altri domini.
Indipendentemente dal fatto che si scelga il metastore o i cataloghi come dominio dati, Databricks consiglia vivamente di impostare un gruppo come amministratore del metastore o proprietario del catalogo.
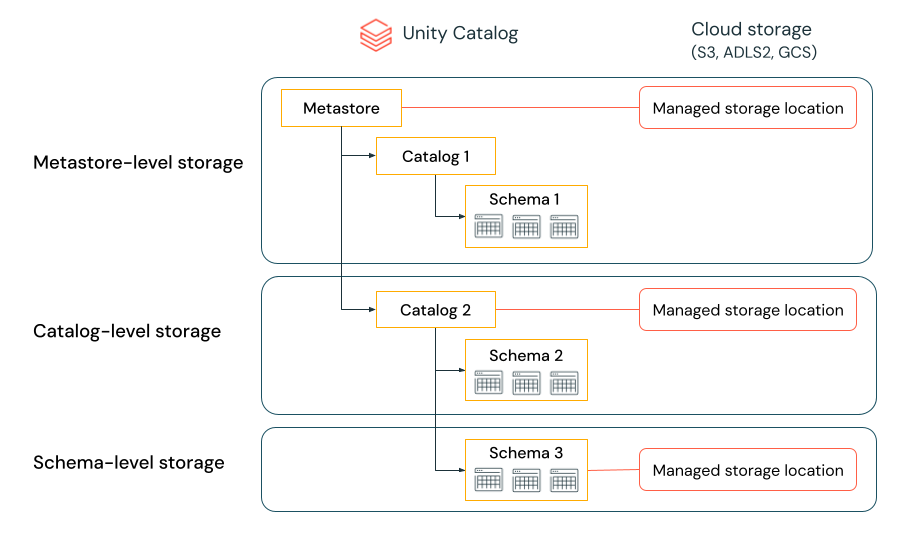
I dati sono separati fisicamente nell'archiviazione
Un'organizzazione può richiedere che i dati di determinati tipi vengano archiviati all'interno di account o bucket specifici nel tenant cloud.
Il catalogo Unity consente di configurare i percorsi di archiviazione a livello di metastore, catalogo o schema per soddisfare tali requisiti.
Si supponga, ad esempio, che l'organizzazione disponga di un criterio di conformità aziendale che richiede che i dati di produzione relativi alle risorse umane risiedano nel contenitore abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net. In Unity Catalog è possibile ottenere questo requisito impostando una posizione a livello di catalogo, creando un catalogo denominato, ad esempio hr_prod, e assegnando il percorso abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Ciò significa che le tabelle gestite o i volumi creati nel hr_prod catalogo (ad esempio, usando CREATE TABLE hr_prod.default.table …) archiviano i dati in abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Facoltativamente, è possibile scegliere di fornire percorsi a livello di schema per organizzare i dati all'interno di hr_prod catalog a un livello più granulare.
Se tale isolamento di archiviazione non è necessario, è possibile impostare una posizione di archiviazione a livello di metastore. Il risultato è che questo percorso funge da percorso predefinito per l'archiviazione di tabelle gestite e volumi tra cataloghi e schemi nel metastore.
Il sistema valuta la gerarchia dei percorsi di archiviazione dallo schema al catalogo al metastore.
Ad esempio, se viene creata una tabella myCatalog.mySchema.myTable in my-region-metastore, il percorso di archiviazione tabelle viene determinato in base alla regola seguente:
- Se è stata specificata una posizione per
mySchema, verrà archiviata in tale posizione. - In caso contrario, e una posizione è stata specificata in
myCatalog, verrà archiviata in tale posizione. - Infine, se non è stata specificata alcuna posizione in
myCatalog, verrà archiviata nel percorso associato all'oggettomy-region-metastore.
È possibile accedere ai dati solo in ambienti designati
I requisiti aziendali e di conformità spesso specificano che si mantengono determinati dati, ad esempio i dati personali, accessibili solo in determinati ambienti. È anche possibile mantenere isolati i dati di produzione dagli ambienti di sviluppo o assicurarsi che determinati set di dati e domini non vengano mai uniti.
In Databricks l'area di lavoro è l'ambiente di elaborazione dati primario e i cataloghi sono il dominio dati primario. Il catalogo unity consente agli amministratori del metastore e ai proprietari del catalogo di assegnare o "associare" cataloghi a aree di lavoro specifiche. Queste associazioni con riconoscimento dell'ambiente consentono di garantire che solo determinati cataloghi siano disponibili all'interno di un'area di lavoro, indipendentemente dai privilegi specifici per gli oggetti dati concessi a un utente.
Si esaminerà ora in modo più approfondito il processo di configurazione del catalogo Unity per soddisfare le proprie esigenze.
Configurare un metastore del catalogo Unity
Un metastore è il contenitore di primo livello degli oggetti nel catalogo unity. I metastore gestiscono gli asset di dati (tabelle, viste e volumi) e altri oggetti a protezione diretta gestiti da Unity Catalog. Per l'elenco completo degli oggetti a protezione diretta, vedere Oggetti a protezione diretta in Unity Catalog.
In questa sezione vengono forniti suggerimenti per la creazione e la configurazione di metastore. Se l'area di lavoro è stata abilitata automaticamente per Unity Catalog, non è necessario creare un metastore, ma le informazioni presentate in questa sezione potrebbero essere comunque utili. Consultare Abilitazione automatica di Unity Catalog.
Suggerimenti per la configurazione dei metastore:
È necessario configurare un metastore per ogni area in cui sono presenti aree di lavoro di Azure Databricks.
Ogni area di lavoro collegata a un singolo metastore a livello di area ha accesso ai dati gestiti dal metastore. Se si desidera condividere i dati tra i metastore, usare La condivisione differenziale.
Ogni metastore può essere configurato con un percorso di archiviazione gestito (detto anche archiviazione radice) nel tenant cloud che può essere usato per archiviare tabelle gestite e volumi gestiti.
Se si sceglie di creare una posizione gestita a livello di metastore, è necessario assicurarsi che nessun utente abbia accesso diretto( ovvero tramite l'account cloud che lo contiene). Concedere l'accesso a questa posizione di archiviazione potrebbe consentire a un utente di ignorare i controlli di accesso in un metastore del catalogo Unity e interrompere il controllo. Per questi motivi, l'archiviazione gestita dal metastore deve essere un contenitore dedicato. Non è consigliabile riutilizzare un contenitore che sia anche il file system radice DBFS o che in precedenza fosse un file system radice DBFS.
È anche possibile definire l'archiviazione gestita a livello di catalogo e schema, sostituendo il percorso di archiviazione radice del metastore. Nella maggior parte degli scenari, Databricks consiglia di archiviare i dati gestiti a livello di catalogo.
È necessario comprendere i privilegi degli amministratori dell'area di lavoro nelle aree di lavoro abilitate per Unity Catalog ed esaminare le assegnazioni di amministratore dell'area di lavoro esistenti.
Gli amministratori dell'area di lavoro possono gestire le operazioni per l'area di lavoro, tra cui l'aggiunta di utenti e entità servizio, la creazione di cluster e la delega di altri utenti come amministratori dell'area di lavoro. Se l'area di lavoro è stata abilitata automaticamente per Unity Catalog, gli amministratori dell'area di lavoro possono creare cataloghi e molti altri oggetti del catalogo Unity per impostazione predefinita. Vedere Privilegi di amministratore dell'area di lavoro quando le aree di lavoro sono abilitate automaticamente per Il catalogo Unity
Gli amministratori dell'area di lavoro hanno anche la possibilità di eseguire attività di gestione dell'area di lavoro, ad esempio la gestione della proprietà dei processi e la visualizzazione dei notebook, che possono concedere l'accesso indiretto ai dati registrati in Unity Catalog. L'amministratore dell'area di lavoro è un ruolo con privilegi da distribuire con attenzione.
Se si usano aree di lavoro per isolare l'accesso ai dati utente, è possibile usare associazioni del catalogo dell'area di lavoro. Le associazioni del catalogo dell'area di lavoro consentono di limitare l'accesso al catalogo in base ai limiti dell'area di lavoro. Ad esempio, è possibile assicurarsi che gli amministratori e gli utenti dell'area di lavoro possano accedere solo ai dati di produzione in
prod_catalogda un ambiente dell'area di lavoro di produzione,prod_workspace. L'impostazione predefinita consiste nel condividere il catalogo con tutte le aree di lavoro collegate al metastore corrente. Vedere Limitare l'accesso al catalogo a aree di lavoro specifiche.Se l'area di lavoro è stata abilitata automaticamente per Unity Catalog, il catalogo delle aree di lavoro con provisioning preliminare è associato all'area di lavoro per impostazione predefinita.
Vedere Creare un metastore del catalogo Unity.
Configurare percorsi esterni e credenziali di archiviazione
Le posizioni esterne consentono a Unity Catalog di leggere e scrivere dati nel tenant cloud per conto degli utenti. Le posizioni esterne vengono definite come percorso per l'archiviazione cloud, combinate con credenziali di archiviazione che possono essere usate per accedere a tale posizione.
È possibile usare percorsi esterni per registrare tabelle esterne e volumi esterni in Unity Catalog. Il contenuto di queste entità si trova fisicamente in un percorso secondario in una posizione esterna a cui viene fatto riferimento quando un utente crea il volume o la tabella.
Una credenziale di archiviazione incapsula una credenziale cloud a lungo termine che fornisce l'accesso all'archiviazione cloud. Può essere un'identità gestita di Azure (fortemente consigliata) o un'entità servizio. L'uso di un'identità gestita di Azure offre i vantaggi seguenti rispetto all'uso di un'entità servizio:
- Le identità gestite non richiedono la gestione delle credenziali o la rotazione dei segreti.
- Se l'area di lavoro di Azure Databricks viene distribuita nella propria rete virtuale (nota anche come inserimento reti virtuali), è possibile connettersi a un account Azure Data Lake Storage Gen2 protetto da un firewall di archiviazione.
Per aumentare l'isolamento dei dati, è possibile associare le credenziali di archiviazione e le posizioni esterne a aree di lavoro specifiche. Vedere (Facoltativo) Assegnare una posizione esterna a aree di lavoro specifiche e (facoltativo) Assegnare credenziali di archiviazione a aree di lavoro specifiche.
Suggerimento
Le posizioni esterne, combinando credenziali di archiviazione e percorsi di archiviazione, offrono un controllo sicuro e la controllabilità dell'accesso alle risorse di archiviazione. Per impedire agli utenti di ignorare il controllo di accesso fornito da Unity Catalog, è necessario assicurarsi di limitare il numero di utenti con accesso diretto a qualsiasi contenitore usato come posizione esterna. Per lo stesso motivo, non è consigliabile montare gli account di archiviazione in DBFS se vengono usati anche come percorsi esterni. Databricks consiglia di eseguire la migrazione dei montaggi nelle posizioni di archiviazione cloud in posizioni esterne in Unity Catalog usando Esplora cataloghi.
Per un elenco delle procedure consigliate per la gestione di posizioni esterne, vedere Gestire posizioni esterne, tabelle esterne e volumi esterni. Vedere anche Creare una posizione esterna per connettere l'archiviazione cloud ad Azure Databricks.
Organizzare i dati
Databricks consiglia di usare i cataloghi per fornire la separazione nell'architettura delle informazioni dell'organizzazione. Spesso questo significa che i cataloghi corrispondono a un ambito di ambiente di sviluppo software, team o business unit. Se si usano le aree di lavoro come strumento di isolamento dei dati, ad esempio usando aree di lavoro diverse per ambienti di produzione e sviluppo o un'area di lavoro specifica per l'uso di dati altamente sensibili, è anche possibile associare un catalogo a aree di lavoro specifiche. In questo modo si garantisce che tutta l'elaborazione dei dati specificati venga gestita nell'area di lavoro appropriata. Vedere Limitare l'accesso al catalogo a aree di lavoro specifiche.
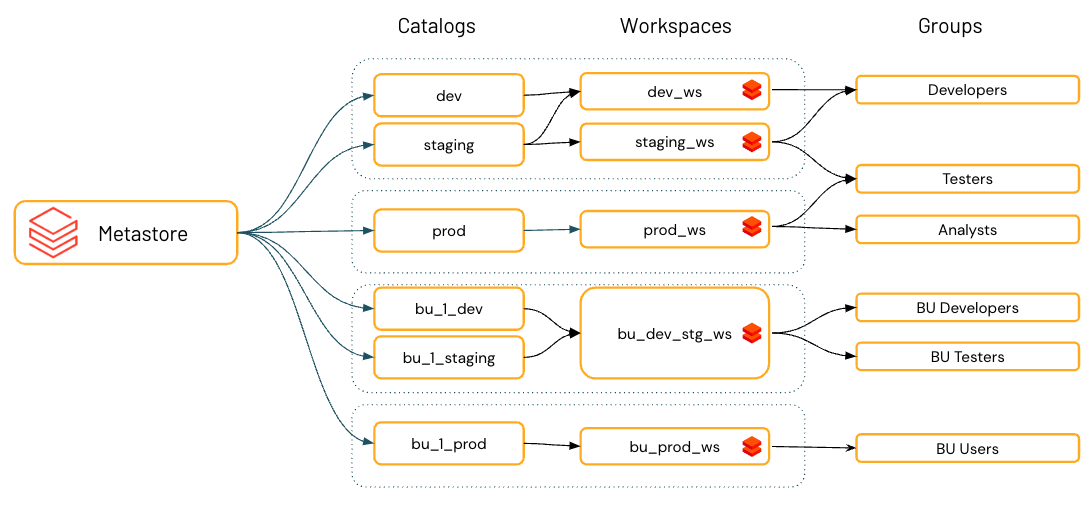
Uno schema (detto anche database) è il secondo livello dello spazio dei nomi a tre livelli di Unity Catalog e organizza tabelle, viste e volumi. È possibile usare gli schemi per organizzare e definire le autorizzazioni per gli asset.
Gli oggetti regolati da Unity Catalog possono essere gestiti o esterni:
Gli oggetti gestiti rappresentano il modo predefinito per creare oggetti dati in Unity Catalog.
Unity Catalog gestisce il ciclo di vita e il layout dei file per queste entità a protezione diretta. Non è consigliabile usare strumenti esterni ad Azure Databricks per modificare direttamente i file in tabelle o volumi gestiti.
Le tabelle gestite e i volumi vengono archiviati nell'archiviazione gestita, che può esistere a livello di metastore, catalogo o schema per qualsiasi tabella o volume specificato. Vedere Dati separati fisicamente nell'archiviazione.
Le tabelle gestite e i volumi sono una soluzione pratica quando si vuole effettuare il provisioning di una posizione regolamentata per il contenuto senza il sovraccarico di creazione e gestione di percorsi esterni e credenziali di archiviazione.
Le tabelle gestite usano sempre il formato di tabella Delta .
Gli oggetti esterni sono entità a protezione diretta il cui ciclo di vita dei dati e il layout dei file non sono gestiti da Unity Catalog.
I volumi esterni e le tabelle vengono registrati in un percorso esterno per fornire l'accesso a un numero elevato di file già esistenti nell'archiviazione cloud senza richiedere l'attività di copia dei dati. Usare oggetti esterni quando si hanno file prodotti da altri sistemi e si vuole che vengano gestiti per l'accesso dall'interno di Azure Databricks o quando gli strumenti all'esterno di Azure Databricks richiedono l'accesso diretto a questi file.
Le tabelle esterne supportano Delta Lake e molti altri formati di dati, tra cui Parquet, JSON e CSV. I volumi gestiti ed esterni possono essere usati per accedere e archiviare file di formati arbitrari: i dati possono essere strutturati, semistrutturati o non strutturati.
Per altre informazioni sulla creazione di tabelle e volumi, vedere Che cos'è una tabella? e Che cosa sono i volumi del catalogo Unity?.
Gestire percorsi esterni, tabelle esterne e volumi esterni
Il diagramma seguente rappresenta la gerarchia del file system di un singolo contenitore di archiviazione cloud, con quattro percorsi esterni che condividono una credenziale di archiviazione.
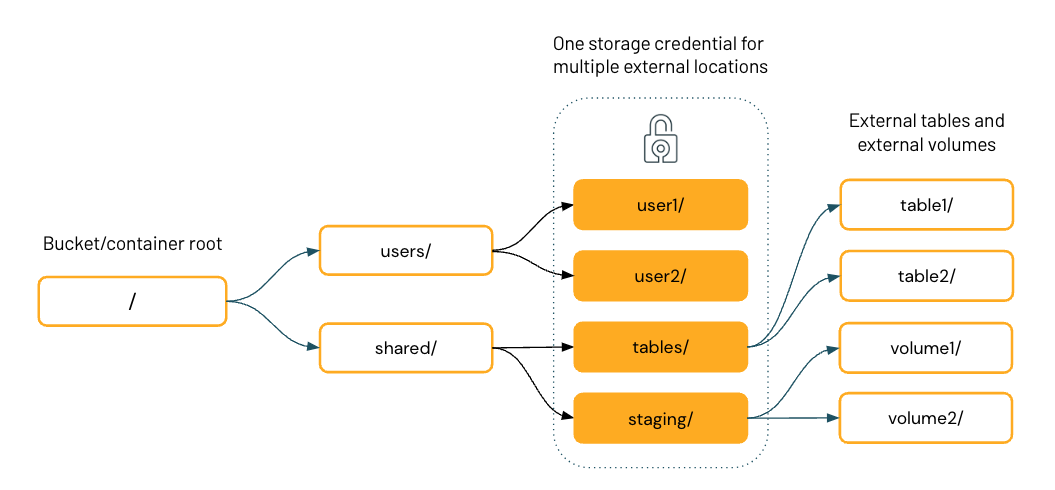
Dopo aver configurato percorsi esterni in Unity Catalog, è possibile creare tabelle e volumi esterni nelle directory all'interno delle posizioni esterne. È quindi possibile usare Unity Catalog per gestire l'accesso utente e gruppo a queste tabelle e volumi. In questo modo è possibile fornire a utenti o gruppi specifici l'accesso a directory e file specifici nel contenitore di archiviazione cloud.
Nota
Quando si definisce un volume, l'accesso URI cloud ai dati nel percorso del volume è regolato dalle autorizzazioni del volume.
Raccomandazioni per l'uso di posizioni esterne
Raccomandazioni per la concessione di autorizzazioni in posizioni esterne:
Concedere la possibilità di creare posizioni esterne solo a un amministratore a cui viene richiesto di configurare le connessioni tra il catalogo unity e l'archiviazione cloud o ai data engineer attendibili.
Le posizioni esterne forniscono l'accesso dal catalogo Unity a una posizione ampiamente compresa nell'archiviazione cloud, ad esempio un intero bucket o un contenitore (abfss://my-container@storage-account.dfs.core.windows.net) o un sottopercorso ampio (abfss://my-container@storage-account.dfs.core.windows.net/path/to/subdirectory). L'intenzione è che un amministratore del cloud possa essere coinvolto nella configurazione di alcune posizioni esterne e quindi delegare la responsabilità di gestire tali posizioni a un amministratore di Azure Databricks nell'organizzazione. L'amministratore di Azure Databricks può quindi organizzare ulteriormente la posizione esterna in aree con autorizzazioni più granulari registrando volumi esterni o tabelle esterne in prefissi specifici nella posizione esterna.
Poiché le posizioni esterne sono così includono, Databricks consiglia di concedere l'autorizzazione
CREATE EXTERNAL LOCATIONsolo a un amministratore a cui viene richiesto di configurare le connessioni tra Il catalogo Unity e l'archiviazione cloud o a data engineer attendibili. Per fornire ad altri utenti un accesso più granulare, Databricks consiglia di registrare tabelle o volumi esterni in posizioni esterne e concedere agli utenti l'accesso ai dati usando volumi o tabelle. Poiché le tabelle e i volumi sono elementi figlio di un catalogo e di uno schema, gli amministratori del catalogo o dello schema hanno il controllo finale sulle autorizzazioni di accesso.È anche possibile controllare l'accesso a una posizione esterna associandolo a aree di lavoro specifiche. Vedere (Facoltativo) Assegnare una posizione esterna a aree di lavoro specifiche.
Non concedere autorizzazioni generali
READ FILESoWRITE FILESper posizioni esterne agli utenti finali.Con la disponibilità dei volumi, gli utenti non devono usare percorsi esterni per nulla, ma creare tabelle, volumi o percorsi gestiti. Non devono usare percorsi esterni per l'accesso basato sul percorso per l'analisi scientifica dei dati o altri casi d'uso di dati non tabulari.
I volumi forniscono supporto per l'uso di file usando comandi SQL, dbutils, API Spark, API REST, Terraform e un'interfaccia utente per l'esplorazione, il caricamento e il download di file. Inoltre, i volumi offrono un montaggio FUSE accessibile nel file system locale in
/Volumes/<catalog_name>/<schema_name>/<volume_name>/. Il montaggio FUSE consente ai data scientist e ai tecnici ml di accedere ai file come se fossero in un file system locale, come richiesto da molte librerie di Machine Learning o del sistema operativo.Se è necessario concedere l'accesso diretto ai file in un percorso esterno (per esplorare i file nell'archiviazione cloud prima che un utente crei una tabella o un volume esterno, ad esempio), è possibile concedere
READ FILES. I casi d'uso per la concessioneWRITE FILESsono rari.
È consigliabile usare percorsi esterni per eseguire le operazioni seguenti:
- Registrare tabelle e volumi esterni usando i
CREATE EXTERNAL VOLUMEcomandi oCREATE TABLE. - Esplorare i file esistenti nell'archiviazione cloud prima di creare una tabella o un volume esterno con un prefisso specifico. Il
READ FILESprivilegio è una precondizione. - Registrare una posizione come risorsa di archiviazione gestita per cataloghi e schemi invece del bucket radice del metastore. Il
CREATE MANAGED STORAGEprivilegio è una precondizione.
Altre raccomandazioni per l'uso di percorsi esterni:
Evitare conflitti di sovrapposizione del percorso: non creare mai volumi o tabelle esterni nella radice di una posizione esterna.
Se si creano volumi o tabelle esterni nella radice della posizione esterna, non è possibile creare volumi o tabelle esterni aggiuntivi nella posizione esterna. Creare invece volumi o tabelle esterni in una sottodirectory all'interno del percorso esterno.
Raccomandazioni per l'uso di volumi esterni
È consigliabile usare volumi esterni per eseguire le operazioni seguenti:
- Registrare le aree di destinazione per i dati non elaborati prodotti da sistemi esterni per supportare l'elaborazione nelle prime fasi delle pipeline ETL e di altre attività di ingegneria dei dati.
- Registrare i percorsi di staging per l'inserimento, ad esempio usando istruzioni Auto Loader,
COPY INTOo CTAS (CREATE TABLE AS). - Fornire percorsi di archiviazione dei file per data scientist, analisti dei dati e ingegneri di Machine Learning da usare come parti dell'analisi esplorativa dei dati e di altre attività di data science, quando i volumi gestiti non sono un'opzione.
- Concedere agli utenti di Azure Databricks l'accesso a file arbitrari prodotti e memorizzati nell'archiviazione cloud da altri sistemi, ad esempio grandi raccolte di dati non strutturati (ad esempio file immagine, audio, video e PDF) acquisiti da sistemi di sorveglianza o dispositivi IoT o file di libreria (file con rotellina JAR e Python) esportati da pipeline di gestione delle dipendenze locali o CI/CD.
- Archiviare i dati operativi, ad esempio la registrazione o il checkpoint dei file, quando i volumi gestiti non sono un'opzione.
Altre raccomandazioni per l'uso di volumi esterni:
- Databricks consiglia di creare volumi esterni da un percorso esterno all'interno di uno schema.
Suggerimento
Per i casi d'uso di inserimento in cui i dati vengono copiati in un'altra posizione, ad esempio usando il caricatore automatico o COPY INTO, usare volumi esterni. Usare tabelle esterne quando si desidera eseguire query sui dati come tabella, senza alcuna copia interessata.
Raccomandazioni per l'uso di tabelle esterne
È consigliabile usare tabelle esterne per supportare i normali modelli di query sui dati archiviati nell'archiviazione cloud, quando si creano tabelle gestite non è un'opzione.
Altre raccomandazioni per l'uso di tabelle esterne:
- Databricks consiglia di creare tabelle esterne usando un percorso esterno per schema.
- Databricks consiglia vivamente di non registrare una tabella come tabella esterna in più metastore a causa del rischio di problemi di coerenza. Ad esempio, una modifica allo schema in un metastore non verrà registrata nel secondo metastore. Usare la condivisione differenziale per condividere i dati tra i metastore. Vedere Condividere i dati in modo sicuro usando la condivisione delta.
Configurare il controllo di accesso
Ogni oggetto a protezione diretta in Unity Catalog ha un proprietario. L'entità che crea un oggetto diventa il proprietario iniziale. Il proprietario di un oggetto dispone di tutti i privilegi per l'oggetto, ad esempio SELECT e MODIFY in una tabella, nonché l'autorizzazione per concedere privilegi all'oggetto a protezione diretta ad altre entità. Solo i proprietari di un oggetto a protezione diretta dispongono dell'autorizzazione per concedere privilegi per tale oggetto ad altre entità. Pertanto, è consigliabile configurare la proprietà su tutti gli oggetti del gruppo responsabile dell'amministrazione delle concessioni nell'oggetto . Sia il proprietario che gli amministratori del metastore possono trasferire la proprietà di un oggetto a protezione diretta a un gruppo. Inoltre, se l'oggetto è contenuto all'interno di un catalogo ,ad esempio una tabella o una vista, il catalogo e il proprietario dello schema possono modificare la proprietà dell'oggetto.
Gli oggetti a protezione diretta nel Catalogo Unity sono gerarchici e i privilegi vengono ereditati verso il basso. Ciò significa che la concessione di un privilegio per un catalogo o uno schema concede automaticamente il privilegio a tutti gli oggetti correnti e futuri all'interno del catalogo o dello schema. Per altre informazioni, vedere Modello di ereditarietà.
Per leggere i dati da una tabella o una vista, un utente deve disporre dei privilegi seguenti:
SELECTnella tabella o nella vistaUSE SCHEMAnello schema proprietario della tabellaUSE CATALOGnel catalogo proprietario dello schema
USE CATALOG consente all'utente autorizzato di attraversare il catalogo per accedere ai relativi oggetti figlio e USE SCHEMA consente all'utente autorizzato di attraversare lo schema per accedere ai relativi oggetti figlio. Ad esempio, per selezionare i dati da una tabella, gli utenti devono avere il SELECT privilegio per tale tabella e il USE CATALOG privilegio per il relativo catalogo padre, insieme al privilegio per lo USE SCHEMA schema padre. Pertanto, è possibile usare questo privilegio per limitare l'accesso alle sezioni dello spazio dei nomi dei dati a gruppi specifici. Uno scenario comune consiste nel configurare uno schema per ogni team in cui solo il team ha USE SCHEMA e CREATE nello schema. Ciò significa che tutte le tabelle prodotte dai membri del team possono essere condivise solo all'interno del team.
È possibile proteggere l'accesso a una tabella usando la sintassi SQL seguente:
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
È possibile proteggere l'accesso alle colonne usando una visualizzazione dinamica in uno schema secondario, come illustrato nella sintassi SQL seguente:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
id,
CASE WHEN is_account_group_member(< group_name >) THEN email ELSE 'REDACTED' END AS email,
country,
product,
total
FROM
< catalog_name >.< schema_name >.< table_name >;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
È possibile proteggere l'accesso alle righe usando una visualizzazione dinamica in uno schema secondario, come illustrato nella sintassi SQL seguente:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
*
FROM
< catalog_name >.< schema_name >.< table_name >
WHERE
CASE WHEN is_account_group_member(managers) THEN TRUE ELSE total <= 1000000 END;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
È anche possibile concedere agli utenti l'accesso sicuro alle tabelle usando filtri di riga e maschere di colonne. Per altre informazioni, vedere Filtrare i dati delle tabelle sensibili usando filtri di riga e maschere di colonna.
Per altre informazioni su tutti i privilegi in Unity Catalog, vedere Gestire i privilegi nel catalogo unity.
Gestire le configurazioni del cluster
Databricks consiglia di usare i criteri del cluster per limitare la possibilità di configurare i cluster in base a un set di regole. I criteri del cluster consentono di limitare l'accesso solo per creare cluster abilitati per Unity Catalog. L'uso dei criteri del cluster riduce le scelte disponibili, semplificando notevolmente il processo di creazione del cluster per gli utenti e assicurandosi che siano in grado di accedere facilmente ai dati. I criteri del cluster consentono anche di controllare i costi limitando il costo massimo per cluster.
Per garantire l'integrità dei controlli di accesso e applicare garanzie di isolamento avanzate, Il catalogo di Unity impone i requisiti di sicurezza per le risorse di calcolo. Per questo motivo, Unity Catalog introduce il concetto di modalità di accesso di un cluster. Il catalogo unity è sicuro per impostazione predefinita; se un cluster non è configurato con una modalità di accesso appropriata, il cluster non può accedere ai dati in Unity Catalog. Vedere Requisiti di calcolo.
Databricks consiglia di usare la modalità di accesso condiviso quando si condivide un cluster e la modalità di accesso utente singolo per i processi automatizzati e i carichi di lavoro di Machine Learning.
Il codice JSON seguente fornisce una definizione di criteri per un cluster con la modalità di accesso condiviso:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9]*\\.x-scala.*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "USER_ISOLATION",
"hidden": true
}
}
Il codice JSON seguente fornisce una definizione di criteri per un cluster di processi automatizzato con la modalità di accesso utente singolo:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9].*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "SINGLE_USER",
"hidden": true
},
"single_user_name": {
"type": "regex",
"pattern": ".*",
"hidden": true
}
}
Controllare l'accesso
Una soluzione completa di governance dei dati richiede il controllo dell'accesso ai dati e fornisce funzionalità di avviso e monitoraggio. Unity Catalog acquisisce un log di controllo delle azioni eseguite sul metastore e questi log vengono recapitati come parte dei log di controllo di Azure Databricks.
È possibile accedere ai log di controllo dell'account usando le tabelle di sistema. Per altre informazioni sulla tabella di sistema del log di controllo, vedere Informazioni di riferimento sulla tabella di sistema del log di controllo.
Per informazioni dettagliate su come ottenere visibilità completa sugli eventi critici relativi alla piattaforma databricks data intelligence, vedere Monitoraggio della piattaforma data intelligence di Databricks con i log di controllo.
Condividere i dati in modo sicuro tramite la condivisione Delta
La condivisione differenziale è un protocollo aperto sviluppato da Databricks per la condivisione sicura dei dati con altre organizzazioni o altri reparti all'interno dell'organizzazione, indipendentemente dalle piattaforme di elaborazione usate. Quando la condivisione delta è abilitata in un metastore, Il catalogo Unity esegue un server di condivisione differenziale.
Per condividere i dati tra metastore, è possibile sfruttare la condivisione delta di Databricks-to-Databricks. In questo modo è possibile registrare tabelle da metastore in aree diverse. Queste tabelle verranno visualizzate come oggetti di sola lettura nel metastore che utilizza. A queste tabelle è possibile concedere l'accesso come qualsiasi altro oggetto all'interno di Unity Catalog.
Quando si usa la condivisione delta da Databricks a Databricks per condividere tra metastore, tenere presente che il controllo di accesso è limitato a un metastore. Se un oggetto a protezione diretta, come una tabella, dispone di concessioni su di esso e tale risorsa viene condivisa in un metastore all'interno dell'account, le concessioni dall'origine non verranno applicate alla condivisione di destinazione. La condivisione di destinazione dovrà impostare le proprie concessioni.
Altre informazioni
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per