Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Unity Catalog è una soluzione unificata per la governance dei dati e dell'intelligenza artificiale integrata direttamente nella piattaforma Azure Databricks. Questa è una panoramica dei concetti chiave in Unity Catalog e di come usare Unity Catalog per gestire i dati.
I pilastri chiave del catalogo Unity includono quanto segue:
- Controllo di accesso unificato: Il catalogo unity offre un'unica posizione per gestire le autorizzazioni per tabelle, file, modelli e altri oggetti da una singola interfaccia.
- Individuazione dati: Unity Catalog consente agli utenti di trovare e comprendere gli asset di dati tramite un'interfaccia ricercabile arricchita con tag, descrizioni e metadati.
- Rilevamento automatico della derivazione: Tenere traccia automaticamente del flusso di dati e del modo in cui vengono trasformati dall'origine alle visualizzazioni finali e ai dashboard.
- Controllo: Mantenere un record completo di tutti gli accessi ai dati e delle attività di sistema per soddisfare i requisiti di sicurezza e la conformità alle normative.
- Monitoraggio della qualità dei dati: Tenere traccia proattiva dell'integrità degli asset di dati con profilatura predefinita e avvisi che rilevano anomalie prima di raggiungere i consumer downstream.
- Condivisione sicura dei dati: Scambiare in modo sicuro i dati in tempo reale tra organizzazioni e cloud usando il protocollo open Delta Sharing, eliminando la necessità di ETL o copia dei dati complessi.
Unity Catalog è anche disponibile come implementazione open-source. Consulta il blog dell'annuncio e il pubblico repository GitHub del catalogo di Unity.
Modello a oggetti del catalogo Unity
In Unity Catalog ogni asset gestito viene modellato come oggetto . In particolare, questi oggetti sono chiamati oggetti securabili in Unity Catalog. È possibile usare i criteri di controllo di accesso e i metadati, ad esempio i tag, per gestire questi oggetti a protezione diretta.
Gli oggetti a protezione diretta si trovano all'interno della gerarchia del modello a oggetti del catalogo Unity, radicati in un oggetto speciale denominato metastore. In esso, gli asset di dati, ad esempio tabelle, viste, volumi, funzioni e modelli seguono uno spazio dei nomi a tre livelli (catalog.schema.object). Altri oggetti, ad esempio credenziali di archiviazione, posizioni esterne, connessioni e condivisioni, si trovano direttamente nel metastore.
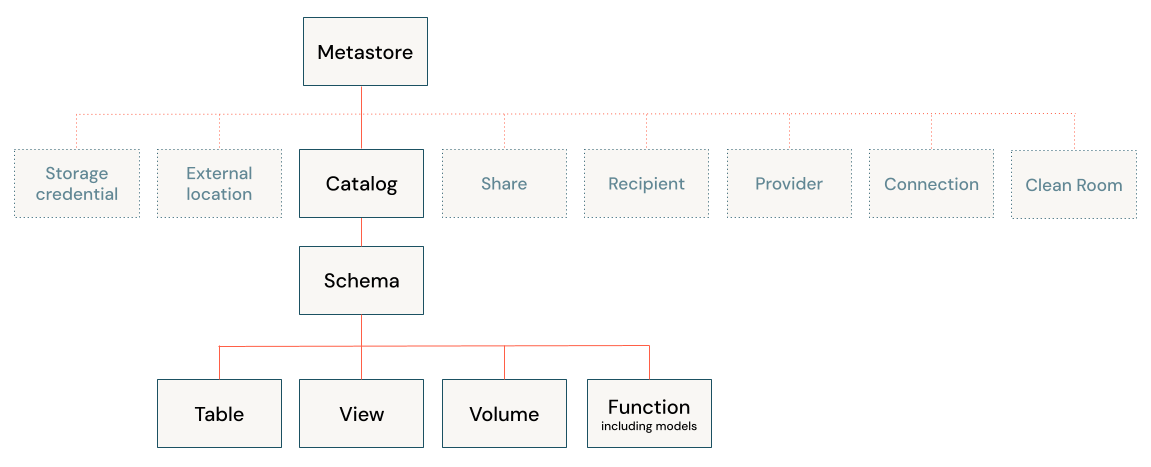
Questa gerarchia è la base del modo in cui Il catalogo di Unity organizza gli asset e applica la governance. Per comprendere il modello a oggetti di Unity Catalog e ogni oggetto a protezione diretta in modo più dettagliato, vedere Informazioni di riferimento sugli oggetti a protezione diretta di Unity Catalog. Per comprendere il funzionamento del modello di autorizzazioni nel contesto del modello a oggetti del catalogo Unity, vedere Concetti relativi al modello di autorizzazioni del catalogo Unity.
Ruoli di amministratore
Gli amministratori sono responsabili della supervisione della governance nella gestione di Unity Catalog. Di seguito sono riportati i diversi livelli di ruoli di amministratore e i relativi privilegi predefiniti:
- Gli amministratori dell'account possono creare metastore, collegare aree di lavoro ai metastore, aggiungere utenti e assegnare privilegi ai metastore.
- Gli amministratori dell'area di lavoro possono aggiungere utenti a un'area di lavoro e gestire molti oggetti specifici dell'area di lavoro, ad esempio processi e notebook. A seconda dell'area di lavoro, gli amministratori dell'area di lavoro possono avere anche molti privilegi per il metastore collegato all'area di lavoro.
- Gli amministratori metastore sono ruoli facoltativi che possono gestire l'archiviazione di tabelle e volumi a livello di metastore. È anche utile se si vogliono gestire i dati centralmente in più aree di lavoro in un'area.
Per altre informazioni, vedere Privilegi di amministratore in Unity Catalog.
Concessione e revoca dell'accesso a oggetti sicurizzabili
Gli utenti con privilegi possono concedere e revocare l'accesso a oggetti proteggibili a qualsiasi livello della gerarchia, incluso il metastore stesso. L'accesso a un oggetto concede implicitamente lo stesso accesso a tutti i figli di quell'oggetto, a meno che l'accesso non venga revocato.
È possibile usare i comandi SQL ANSI tipici per concedere e revocare l'accesso agli oggetti nel catalogo unity. Per esempio:
GRANT CREATE TABLE ON SCHEMA mycatalog.myschema TO `finance-team`;
È anche possibile usare Esplora cataloghi, l'interfaccia della riga di comando di Databricks e le API REST per gestire le autorizzazioni degli oggetti.
Gli amministratori del metastore, i proprietari di un oggetto e gli utenti con MANAGE privilege su un oggetto possono concedere e revocare l'accesso. Per informazioni su come gestire i privilegi nel catalogo unity, vedere Gestire i privilegi nel catalogo unity.
Accesso predefinito agli oggetti del database in Unity Catalog
Unity Catalog opera sul principio del minimo privilegio, dove gli utenti hanno accesso solo alle risorse necessarie per svolgere i compiti richiesti. Quando viene creata un'area di lavoro, gli utenti non amministratori hanno accesso solo al catalogo dell'area di lavoro con provisioning automatico. Questo rende il catalogo un luogo conveniente per gli utenti per sperimentare il processo di creazione e accesso agli oggetti di database in Unity Catalog. Vedere Privilegi del catalogo dell'area di lavoro.
Tabelle e volumi gestiti versus tabelle e volumi esterni
Le tabelle e i volumi possono essere gestiti o esterni.
- Le tabelle gestite sono completamente gestite da Unity Catalog, il che significa che Unity Catalog gestisce sia la governance che i file di dati sottostanti per ogni tabella gestita. Le tabelle gestite sono memorizzate in una posizione gestita da Unity Catalog nel tuo storage cloud. Le tabelle gestite utilizzano sempre il formato Delta Lake. È possibile memorizzare tabelle gestite a livello di metastore, catalogo o schema.
- Le tabelle esterne sono tabelle il cui accesso da Azure Databricks è gestito da Unity Catalog, ma il cui ciclo di vita dei dati e il layout dei file vengono gestiti usando il provider di servizi cloud e altre piattaforme dati. Tipicamente si utilizzano tabelle esterne per registrare grandi quantità dei propri dati esistenti in Azure Databricks o se è necessario anche l'accesso in scrittura ai dati utilizzando strumenti al di fuori di Azure Databricks. Le tabelle esterne sono supportate in più formati di dati. Dopo aver registrato una tabella esterna in un metastore di Unity Catalog, è possibile gestire e controllare l'accesso a tale tabella tramite Azure Databricks--- e usarla---proprio come è possibile usare le tabelle gestite.
- I volumi gestiti sono completamente gestiti da Unity Catalog, il che significa che Unity Catalog gestisce l'accesso alla posizione di archiviazione del volume nell'account del provider di servizi cloud. Quando si crea un volume gestito, questo viene archiviato automaticamente nel percorso di archiviazione gestito assegnato allo schema contenitore.
- I volumi esterni rappresentano i dati esistenti nei percorsi di archiviazione gestiti all'esterno di Azure Databricks, ma registrati in Unity Catalog per controllare e controllare l'accesso da Azure Databricks. Quando si crea un volume esterno in Azure Databricks, è necessario specificarne la posizione, che deve trovarsi in un percorso definito in una posizione esterna del catalogo Unity.
Databricks consiglia tabelle e volumi gestiti per la maggior parte dei casi d'uso, perché consentono di sfruttare appieno le funzionalità di governance e le ottimizzazioni delle prestazioni di Unity Catalog. Per informazioni sui casi d'uso tipici per tabelle e volumi esterni, vedere Tabelle gestite ed esterne e Volumi gestiti ed esterni.
Vedere anche:
- Tabelle gestite di Unity Catalog in Azure Databricks per Delta Lake e Apache Iceberg
- Usare tabelle esterne
- Volumi gestiti e esterni.
Archiviazione cloud e isolamento dei dati
Il catalogo unity usa l'archiviazione cloud in due modi principali:
- Archiviazione gestita: percorsi predefiniti per tabelle gestite e volumi gestiti (dati non strutturati e non tabulari) creati in Azure Databricks. Questi percorsi di archiviazione gestiti possono essere definiti a livello di metastore, catalogo o schema. È possibile creare posizioni di archiviazione gestite nel provider di servizi cloud, ma il loro ciclo di vita è completamente gestito dal catalogo unity.
- Sedi di archiviazione dove sono archiviati tabelle e volumi esterni. Si tratta di tabelle e volumi il cui accesso da Azure Databricks è gestito da Unity Catalog, ma il cui ciclo di vita dei dati e il layout dei file vengono gestiti usando il provider di servizi cloud e altre piattaforme dati. In genere si usano tabelle o volumi esterni per registrare grandi quantità di dati esistenti in Azure Databricks o se è necessario anche l'accesso in scrittura ai dati usando strumenti esterni ad Azure Databricks.
Governo dell'accesso all'archiviazione cloud utilizzando posizioni esterne
Sia i percorsi di archiviazione gestiti, sia quelli in cui sono archiviate tabelle e volumi esterni usano oggetti di sicurezza di localizzazione esterna per gestire l'accesso da Azure Databricks. Gli oggetti posizione esterna fanno riferimento a un percorso di archiviazione cloud e alle credenziali di archiviazione necessarie per accedervi. Le credenziali di archiviazione sono stessi oggetti a protezione diretta di Unity Catalog che registrano le credenziali necessarie per accedere a un percorso di archiviazione specifico. Insieme, questi oggetti protetti assicurano che l'accesso all'archiviazione sia controllato e monitorato da Unity Catalog.
Il diagramma seguente mostra in che modo le posizioni esterne fanno riferimento alle credenziali di archiviazione e alle posizioni di archiviazione cloud.
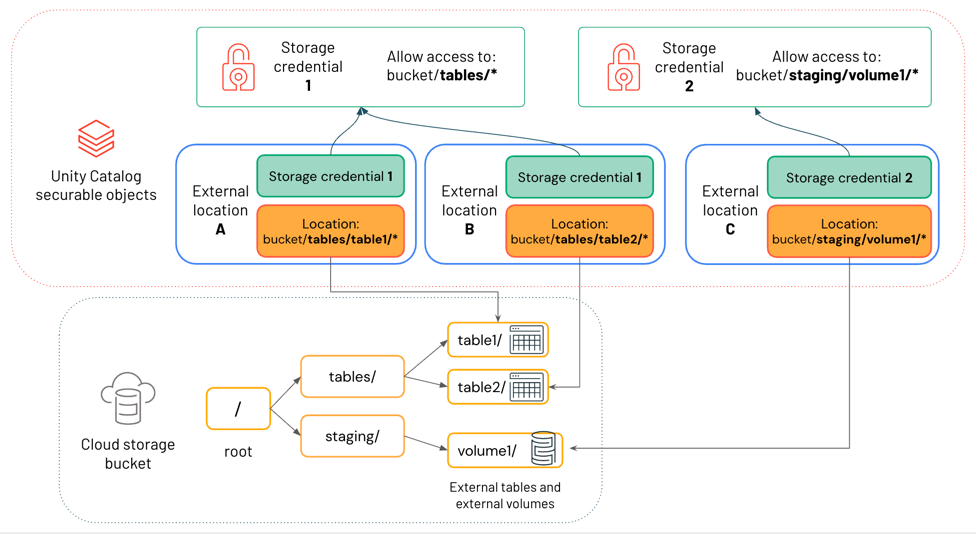
In questo diagramma:
- Ogni posizione esterna fa riferimento a credenziali di archiviazione e a una posizione di archiviazione cloud.
- Più posizioni esterne possono fare riferimento alle stesse credenziali di archiviazione.
Le credenziali di archiviazione 1 concedono l'accesso a tutti gli elementi nel percorso
bucket/tables/*, quindi sia la posizione esterna A che la posizione esterna B vi fanno riferimento.
Per ulteriori informazioni, vedere Come fa Unity Catalog a governare l'accesso allo storage su cloud?.
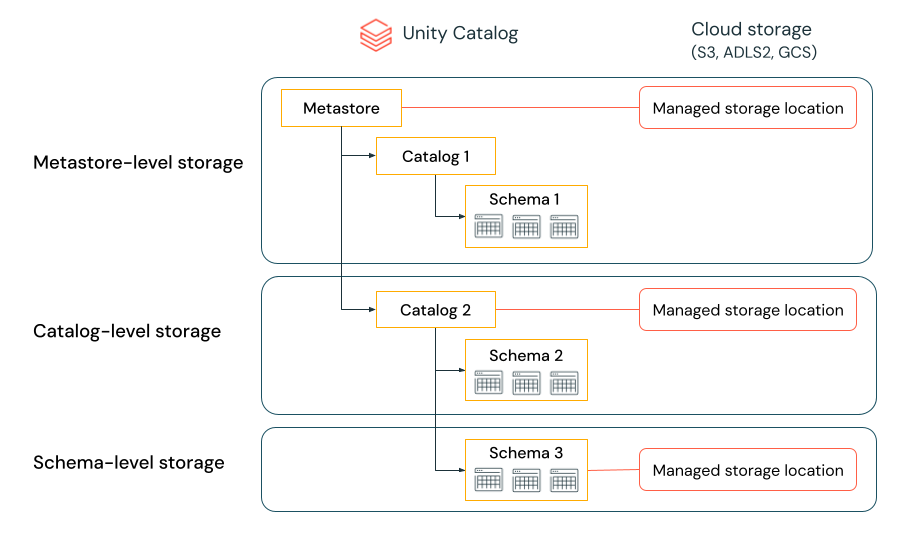
Gerarchia della posizione di archiviazione gestita
Il livello a cui si definisce l'archiviazione gestita in Unity Catalog dipende dal modello di isolamento dei dati preferito. L'organizzazione potrebbe richiedere che determinati tipi di dati vengano archiviati all'interno di account o bucket specifici nel tenant cloud.
Il catalogo unity offre la possibilità di configurare percorsi di archiviazione gestiti a livello di metastore, catalogo o schema per soddisfare tali requisiti.
Si supponga, ad esempio, che l'organizzazione disponga di un criterio di conformità aziendale che richiede che i dati di produzione relativi alle risorse umane risiedano nel contenitore abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net. In Unity Catalog è possibile ottenere questo requisito impostando una posizione a livello di catalogo, creando un catalogo denominato, ad esempio hr_prode assegnando la posizione abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Ciò significa che tabelle o volumi gestiti creati nel catalogo di hr_prod (ad esempio, usando CREATE TABLE hr_prod.default.table …) archiviano i dati in abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Facoltativamente, è possibile scegliere di fornire posizioni a livello di schema per organizzare i dati all'interno del hr_prod catalog a un livello più dettagliato.
Se l'isolamento dello storage non è richiesto per alcuni cataloghi, è possibile impostare facoltativamente una posizione di storage a livello di metastore. Questo percorso funge da percorso predefinito per tabelle gestite e volumi in cataloghi e schemi che non hanno assegnato spazio di archiviazione. Di norma, tuttavia, Databricks consiglia di assegnare posizioni di archiviazione gestite separate per ciascun catalogo.
Il sistema valuta la gerarchia dei luoghi di archiviazione dal schema al catalogo al metastore.
Ad esempio, se viene creata una tabella myCatalog.mySchema.myTable in my-region-metastore, il percorso di archiviazione tabelle viene determinato in base alla regola seguente:
- Se è stata specificata una posizione per
mySchema, verrà archiviata in tale posizione. - In caso contrario, e una posizione è stata specificata in
myCatalog, verrà archiviata in tale posizione. - Infine, se non è stata specificata alcuna posizione in
myCatalog, verrà archiviata nel percorso associato all'oggettomy-region-metastore.
Per ulteriori informazioni, vedere Specificare un percorso di archiviazione gestito nel Catalogo Unity.
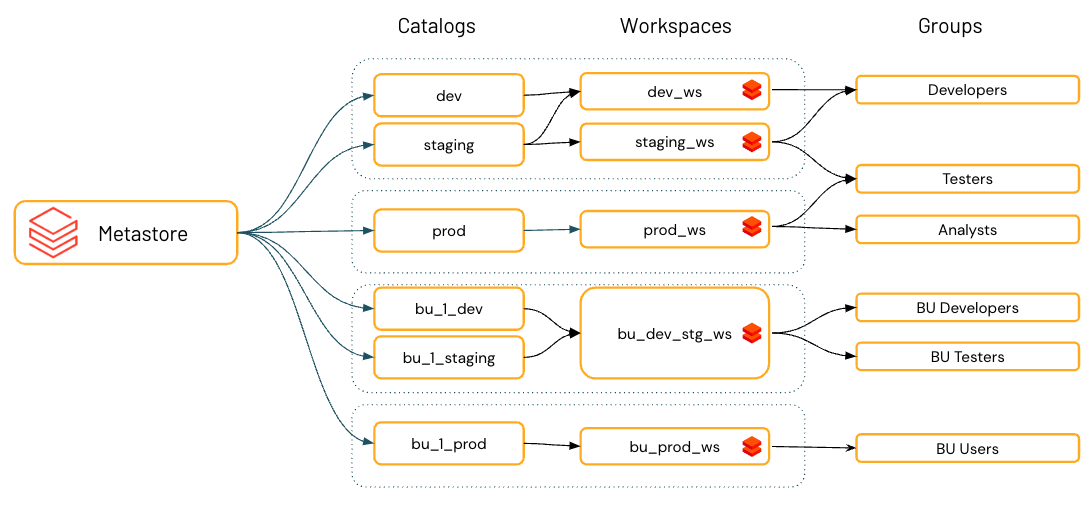
Isolamento dell'ambiente tramite l'associazione tra area di lavoro e catalogo
Per impostazione predefinita, i proprietari del catalogo (e gli amministratori del metastore, se sono definiti per l'account) possono rendere un catalogo accessibile agli utenti in più aree di lavoro collegate allo stesso metastore di Unity Catalog.
I requisiti aziendali e di conformità spesso specificano che si mantengono determinati dati, ad esempio i dati personali, accessibili solo in determinati ambienti. È anche possibile mantenere isolati i dati di produzione dagli ambienti di sviluppo o assicurarsi che determinati set di dati e domini non vengano mai uniti.
In Azure Databricks l'area di lavoro è l'ambiente di elaborazione dati primario e i cataloghi sono il dominio dati primario. Il catalogo Unity consente agli amministratori del metastore, ai proprietari del catalogo e agli utenti con l'autorizzazione MANAGE di assegnare o "associare" cataloghi a aree di lavoro specifiche. Queste associazioni con riconoscimento dell'ambiente consentono di garantire che solo determinati cataloghi siano disponibili all'interno di un'area di lavoro, indipendentemente dai privilegi specifici per gli oggetti dati concessi a un utente. Se usi gli spazi di lavoro per isolare l'accesso ai dati degli utenti, potresti voler limitare l'accesso al catalogo a specifici spazi di lavoro nel tuo account, per garantire che alcuni tipi di dati vengano elaborati solo in quegli spazi di lavoro. Potresti volere spazi di lavoro separati per la produzione e lo sviluppo, ad esempio, oppure un spazio di lavoro separato per l'elaborazione dei dati personali. Questa operazione è nota come associazione catalogo-area di lavoro. Vedere Limitare l'accesso al catalogo a aree di lavoro specifiche.
Annotazioni
Per un maggiore isolamento dei dati, puoi anche vincolare l'accesso all'archiviazione cloud e l'accesso ai servizi cloud a specifici spazi di lavoro. Vedere (Facoltativo) Assegnare credenziali di archiviazione a aree di lavoro specifiche, (Facoltativo) Assegnare una posizione esterna a aree di lavoro specifiche e (Facoltativo) Assegnare credenziali del servizio a aree di lavoro specifiche.
Come si configura Unity Catalog per l'organizzazione?
Per utilizzare Unity Catalog, il tuo spazio di lavoro Azure Databricks deve essere abilitato per Unity Catalog, il che significa che lo spazio di lavoro è collegato a un metastore di Unity Catalog.
Come viene collegato uno spazio di lavoro a un metastore? Dipende dall'account e dallo spazio di lavoro
- Tipicamente, quando si crea uno spazio di lavoro Azure Databricks in una regione per la prima volta, il metastore viene creato automaticamente e collegato allo spazio di lavoro.
- Per alcuni account meno recenti, un amministratore dell'account deve creare il metastore e assegnare le aree di lavoro di quella regione al metastore. Per le istruzioni, vedere Creare un metastore del catalogo Unity.
- Se un account ha già un metastore assegnato per una regione, un amministratore dell'account può decidere se collegare automaticamente il metastore a tutti i nuovi ambienti di lavoro in quella regione. Vedere Abilitare un metastore per l'assegnazione automatica alle nuove aree di lavoro.
Indipendentemente dal fatto che l'area di lavoro sia stata abilitata automaticamente per Il catalogo unity, per iniziare a usare il catalogo Unity sono necessari anche i passaggi seguenti:
- Creare cataloghi e schemi per contenere oggetti di database come tabelle e volumi.
- Crea posizioni di archiviazione gestite per memorizzare le tabelle e i volumi gestiti in questi cataloghi e schemi.
- Concedere all'utente l'accesso a cataloghi, schemi e oggetti di database.
Le aree di lavoro abilitate automaticamente per Unity Catalog eseguono il provisioning di un catalogo di aree di lavoro con privilegi generali concessi a tutti gli utenti dell'area di lavoro. Questo catalogo è un punto di partenza comodo per provare Unity Catalog.
Per istruzioni dettagliate sulla configurazione, vedere Introduzione al catalogo unity.
Aggiornamento di un'area di lavoro esistente a Unity Catalog
Per informazioni su come aggiornare un'area di lavoro non Unity Catalog a Unity Catalog, vedere Aggiornare un'area di lavoro di Azure Databricks a Unity Catalog.
Requisiti e restrizioni di Unity Catalog
Unity Catalog richiede specifici tipi di calcolo e formati di file, descritti di seguito. Di seguito sono elencate anche alcune funzionalità di Azure Databricks non completamente supportate in Unity Catalog in tutte le versioni di Databricks Runtime.
Supporto per l'area
Tutte le regioni supportano Unity Catalog. Per informazioni dettagliate, vedere Aree di Azure Databricks.
Requisiti di calcolo
Unity Catalog è supportato su cluster che eseguono Databricks Runtime 11.3 LTS o versioni successive. Il catalogo unity è supportato per impostazione predefinita in tutte le versioni di calcolo di SQL Warehouse .
I cluster che eseguono versioni precedenti di Databricks Runtime non supportano tutte le funzionalità del Unity Catalog GA.
Per accedere ai dati in Unity Catalog, i cluster devono essere configurati con la modalità di accesso corretta. Il catalogo unity è sicuro per impostazione predefinita. Se un cluster non è configurato con la modalità di accesso standard o dedicata, il cluster non può accedere ai dati in Unity Catalog. Vedere Modalità di accesso.
Per informazioni dettagliate sulle modifiche alle funzionalità di Unity Catalog in ogni versione di Databricks Runtime, vedere le note sulla versione.
Supporto del formato di file
Il catalogo unity supporta i formati di tabella seguenti:
-
Le tabelle gestite devono usare il formato di
deltatabella oiceberg. -
Le tabelle esterne possono usare
delta,CSV,JSONavro,parquet, ,ORCotext.
Limitazioni
Unity Catalog presenta le limitazioni seguenti. Alcuni di questi sono specifici per le versioni precedenti di Databricks Runtime e per le modalità di accesso al calcolo.
I carichi di lavoro Structured Streaming presentano limitazioni aggiuntive, a seconda del runtime di Databricks e della modalità di accesso. Vedere Requisiti di calcolo standard e limitazioni e requisiti di calcolo dedicati e limitazioni.
Databricks rilascia regolarmente nuove funzionalità che riducono l'elenco.
I gruppi che sono stati precedentemente creati in un'area di lavoro (ovvero, gruppi a livello di area di lavoro) non possono essere utilizzati nelle istruzioni di Unity Catalog
GRANT. Questo serve a garantire una visione coerente dei gruppi che possono estendersi attraverso diversi spazi di lavoro. Per usare i gruppi nelleGRANTistruzioni, creare i gruppi a livello di account e aggiornare qualsiasi automazione per la gestione del principale o del gruppo, ad esempio i connettori SCIM, Okta e Microsoft Entra ID e Terraform, per fare riferimento agli endpoint dell'account anziché agli endpoint dell'area di lavoro. Consulta Fonti del gruppo.I carichi di lavoro in R non supportano l'uso di viste dinamiche per la sicurezza a livello di riga o colonna sul calcolo che esegue Databricks Runtime 15.3 e versioni inferiori.
- Utilizzare una risorsa di calcolo dedicata che esegue Databricks Runtime 15.4 LTS o versioni successive per i carichi di lavoro in R che interrogano viste dinamiche. Tali carichi di lavoro richiedono anche uno spazio di lavoro abilitato per il calcolo senza server. Per informazioni dettagliate, vedere Controllo di accesso granulare sul calcolo dedicato.
Una tabella gestita può essere clonata superficialmente in un'altra tabella gestita su Databricks Runtime 13.3 LTS e versioni successive. Una tabella esterna può essere clonata superficialmente in un'altra tabella esterna su Databricks Runtime 14.2 e versioni successive. Una tabella gestita non può essere clonata in modo superficiale in una tabella esterna. Inoltre, una tabella esterna non può essere clonata superficialmente in una tabella gestita. Per ulteriori informazioni, vedere Clone leggero per le tabelle di Unity Catalog.
Il bucketing non è supportato per le tabelle del catalogo Unity. Se esegui comandi che tentano di creare una tabella suddivisa nel catalogo Unity, verrà lanciata un'eccezione.
Scrivere nello stesso percorso o nella stessa tabella Delta Lake da aree di lavoro situate in regioni diverse può causare prestazioni inaffidabili se alcuni cluster accedono a Unity Catalog e altri no.
La manipolazione delle partizioni per le tabelle esterne tramite comandi come
ALTER TABLE ADD PARTITIONrichiede che la registrazione dei metadati delle partizioni sia abilitata. Vedere Individuazione delle partizioni per tabelle esterne.Quando si usa la modalità di sovrascrittura per le tabelle non in formato Delta, l'utente deve disporre del privilegio CREATE TABLE sullo schema padre e deve essere il proprietario dell'oggetto esistente OPPURE avere il privilegio MODIFY per l'oggetto .
Le funzioni definite dall'utente Python non sono supportate in Databricks Runtime 12.2 LTS e versioni precedenti. Sono incluse le Funzioni Aggregate Definite dall'Utente (UDAFs), le Funzioni Tabulari Definite dall'Utente (UDTFs) e Pandas su Spark (
applyInPandasemapInPandas). Le UDF scalari di Python sono supportate in Databricks Runtime 13.3 LTS e versioni successive.Le UDF Scala non sono supportate in Databricks Runtime 14.1 e versioni precedenti su calcolo con modalità di accesso standard. Le funzioni scalari definite dall'utente sono supportate in Databricks Runtime 14.2 e versioni successive nell'ambiente di calcolo con modalità di accesso standard.
I pool di thread Scala standard non sono supportati. Usare invece i pool di thread speciali in
org.apache.spark.util.ThreadUtils, ad esempioorg.apache.spark.util.ThreadUtils.newDaemonFixedThreadPool. Tuttavia, i seguenti pool di thread inThreadUtilsnon sono supportati:ThreadUtils.newForkJoinPoole qualsiasi pool di threadScheduledExecutorService.
- I log di diagnostica di Azure registrano solo gli eventi di Unity Catalog a livello di area di lavoro. Per visualizzare le azioni a livello di account, è necessario usare la tabella di sistema del registro di audit. Consultare la tabella di sistema del registro di controllo .
I modelli registrati in Unity Catalog presentano limitazioni aggiuntive. Vedere Limitazioni.
Quote delle risorse
Unity Catalog impone limiti alle risorse su tutti gli oggetti sicurabili. Queste quote sono elencate in Limiti delle risorse. Se si prevede di superare questi limiti di risorse, contattare il team dell'account Azure Databricks.
È possibile monitorare l'utilizzo delle quote usando le API delle quote delle risorse di Unity Catalog. Consulta Monitorare le quote di utilizzo delle risorse di Unity Catalog.