Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come creare e distribuire una pipeline ETL (estrazione, trasformazione e caricamento) con Change Data Capture (CDC) usando le pipeline dichiarative di Lakeflow per l'orchestrazione dei dati e il caricatore automatico. Una pipeline ETL implementa i passaggi per leggere i dati dai sistemi di origine, trasformare tali dati in base ai requisiti, ad esempio i controlli della qualità dei dati e registrare la deduplicazione dei dati e scrivere i dati in un sistema di destinazione, ad esempio un data warehouse o un data lake.
In questa esercitazione si useranno i dati di una customers tabella in un database MySQL per:
- Estrarre le modifiche da un database transazionale usando Debezium o qualsiasi altro strumento e salvarle in un archivio oggetti cloud (cartella S3, ADLS, GCS). Si eviterà la configurazione di un sistema CDC esterno per semplificare il tutorial.
- Usare il caricatore automatico per caricare in modo incrementale i messaggi dall'archiviazione di oggetti cloud e archiviare i messaggi non elaborati nella
customers_cdctabella. Il caricatore automatico dedurrà lo schema e gestirà l'evoluzione dello schema. - Aggiungere una visualizzazione
customers_cdc_cleanper controllare la qualità dei dati usando le aspettative. Ad esempio, ilidnon dovrebbe mai esserenullpoiché lo utilizzerai per eseguire le operazioni di upsert. - Eseguire
AUTO CDC ... INTO(eseguendo gli upsert) sui dati CDC puliti per applicare le modifiche alla tabella finalecustomers - Mostrare in che modo Le pipeline dichiarative di Lakeflow possono creare una dimensione a modifica lenta (SCD2) di tipo 2 per tenere traccia di tutte le modifiche.
L'obiettivo è inserire i dati non elaborati quasi in tempo reale e creare una tabella per il team analista garantendo al tempo stesso la qualità dei dati.
L'esercitazione utilizza l'architettura medallion Lakehouse, in cui ingestisce i dati grezzi tramite il livello bronzo, pulisce e convalida i dati con il livello argento e applica la modellazione e l'aggregazione dimensionali mediante il livello oro. Per ulteriori informazioni, vedere Che cos'è l'architettura del lakehouse medallion?
Il flusso che verrà implementato sarà simile al seguente:
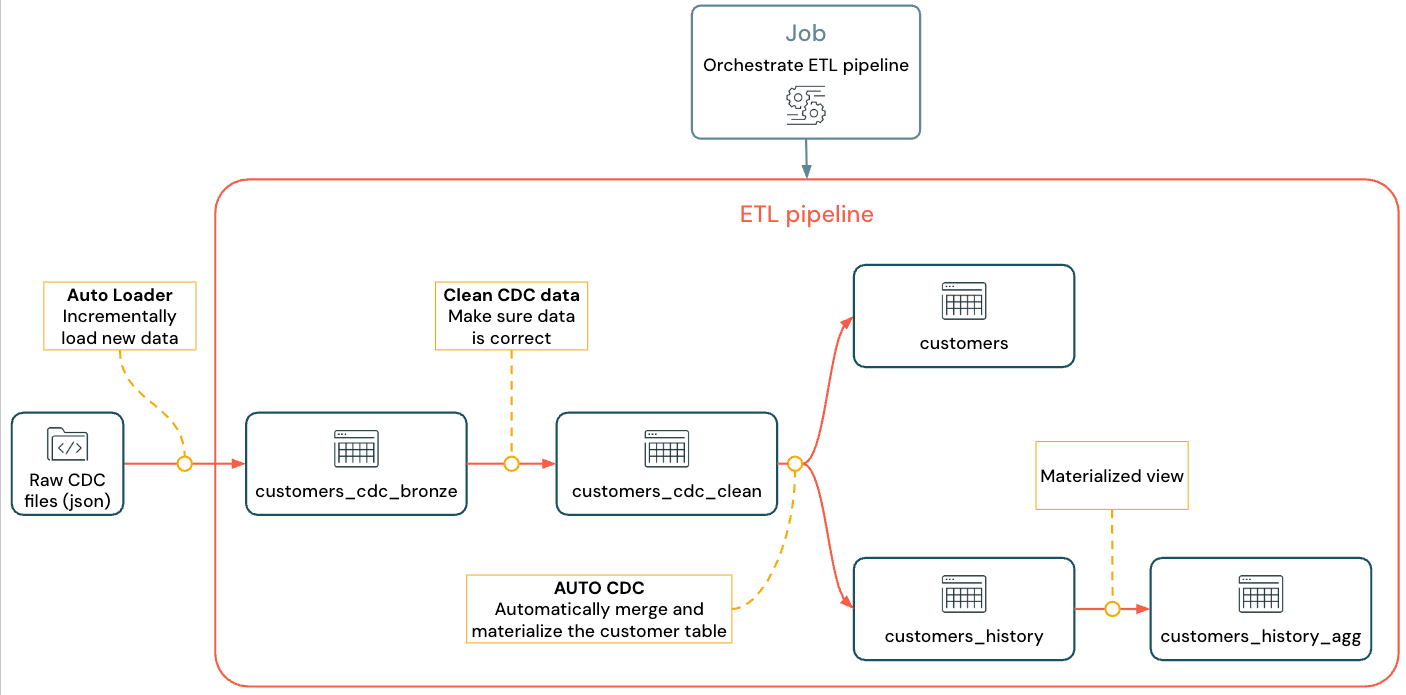
Per altre informazioni sulle pipeline dichiarative di Lakeflow, sul caricatore automatico e su CDC, vedere Pipeline dichiarative di Lakeflow, Che cos'è il caricatore automatico?e Che cos'è Change Data Capture (CDC)?
Requisiti
Per completare questa esercitazione, è necessario soddisfare i requisiti seguenti:
- Accedere a un'area di lavoro di Azure Databricks.
- Assicurati che Unity Catalog sia abilitato per la tua area di lavoro.
- Avere il calcolo serverless abilitato per il tuo account. Le pipeline dichiarative di Serverless Lakeflow non sono disponibili in tutte le regioni dell'area di lavoro. Vedere Funzionalità con disponibilità a livello di area limitata per le aree disponibili.
- Disporre dell'autorizzazione per creare una risorsa di calcolo o accedere a una risorsa di calcolo.
- Disporre delle autorizzazioni per creare un nuovo schema in un catalogo. Le autorizzazioni necessarie sono
ALL PRIVILEGESoUSE CATALOGeCREATE SCHEMA. - Disporre delle autorizzazioni per creare un nuovo volume in uno schema esistente. Le autorizzazioni necessarie sono
ALL PRIVILEGESoUSE SCHEMAeCREATE VOLUME.
Acquisizione delle Modifiche dei Dati in una pipeline ETL
Change Data Capture (CDC) è il processo che acquisisce le modifiche apportate ai record apportati a un database transazionale (ad esempio, MySQL o PostgreSQL) o a un data warehouse. CDC acquisisce operazioni come l'eliminazione, l'aggiunta e l'aggiornamento dei dati, in genere come flusso per ri materializzare la tabella in sistemi esterni. CDC consente il caricamento incrementale eliminando la necessità di aggiornamento di caricamenti bulk.
Nota
Per semplificare il tutorial, saltare la configurazione di un sistema CDC esterno. È possibile considerarlo in esecuzione e salvare i dati CDC come file JSON in un archivio BLOB (S3, ADLS, GCS).
Acquisizione di CDC
Sono disponibili diversi strumenti CDC. Una delle soluzioni leader open source è Debezium, ma altre implementazioni che semplificano l'origine dati esistono, ad esempio Fivetran, Qlik Replicate, Streamset, Talend, Oracle GoldenGate e AWS DMS.
In questa esercitazione si usano dati CDC da un sistema esterno, ad esempio Debezium o DMS. Debezium acquisisce ogni riga modificata. In genere invia la cronologia delle modifiche dei dati ai log Kafka o li salva come file.
Devi acquisire le informazioni CDC dalla tabella customers (formato JSON), verificare che siano corrette e quindi materializzare la tabella cliente in Lakehouse.
Input CDC da Debezium
Per ogni modifica, si riceverà un messaggio JSON contenente tutti i campi della riga da aggiornare (id, firstname, lastnameemail, , address). Inoltre, si avranno informazioni aggiuntive sui metadati, tra cui:
-
operation: codice dell'operazione, in genere (DELETE,APPEND,UPDATE). -
operation_date: La data e il timestamp per il record di ogni azione operativa.
Gli strumenti come Debezium possono produrre output più avanzati, ad esempio il valore di riga prima della modifica, ma questa esercitazione li omette per semplicità.
Passaggio 0: Configurazione dei dati del tutorial
Prima di tutto, è necessario creare un nuovo notebook e installare i file demo usati in questa esercitazione nell'area di lavoro.
Fare clic su Nuovo nell'angolo superiore sinistro.
Clicca Notebook.
Modificare il titolo del notebook da Notebook senza titolo< data e ora> a Impostazione dell'esercitazione Pipelines.
Accanto al titolo del notebook nella parte superiore, impostare il linguaggio predefinito del notebook su Python.
Per generare il set di dati usato nell'esercitazione, immettere il codice seguente nella prima cella e digitare MAIUSC + INVIO per eseguire il codice:
# You can change the catalog, schema, dbName, and db. If you do so, you must also # change the names in the rest of the tutorial. catalog = "main" schema = dbName = db = "dbdemos_dlt_cdc" volume_name = "raw_data" spark.sql(f'CREATE CATALOG IF NOT EXISTS `{catalog}`') spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'CREATE SCHEMA IF NOT EXISTS `{catalog}`.`{schema}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{schema}`.`{volume_name}`') volume_folder = f"/Volumes/{catalog}/{db}/{volume_name}" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exists, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Per visualizzare in anteprima i dati usati in questa esercitazione, immettere il codice nella cella successiva e digitare MAIUSC + INVIO per eseguire il codice:
display(spark.read.json("/Volumes/main/dbdemos_dlt_cdc/raw_data/customers"))
Passaggio 1: Creare una pipeline
Per prima cosa, si creerà una pipeline ETL in Lakeflow Declarative Pipelines. Lakeflow Declarative Pipelines crea pipeline risolvendo le dipendenze definite nei notebook o nei file (denominati codice sorgente) usando la sintassi delle pipeline dichiarative di Lakeflow. Ogni file di codice sorgente può contenere una sola lingua, ma è possibile aggiungere più notebook o file specifici della lingua nella pipeline. Per altre informazioni, vedere Pipeline dichiarative di Lakeflow
Importante
Lasciare vuoto il campo Codice sorgente per creare e configurare automaticamente un notebook per la creazione del codice sorgente.
Questo tutorial usa il calcolo serverless e Unity Catalog. Per tutte le opzioni di configurazione non specificate, usare le impostazioni predefinite. Se l'ambiente di calcolo serverless non è abilitato o supportato nell'area di lavoro, è possibile completare l'esercitazione come scritto usando le impostazioni di calcolo predefinite. Se si usano le impostazioni di calcolo predefinite, è necessario selezionare manualmente Il catalogo Unity in Opzioni di archiviazione nella sezione Destinazione dell'interfaccia utente crea pipeline .
Per creare una nuova pipeline ETL in Pipeline Dichiarative di Lakeflow, seguire questi passaggi:
- Nell'area di lavoro fare clic
 Processi e pipeline nella barra laterale.
Processi e pipeline nella barra laterale. - In Nuovo fare clic su Pipeline ETL.
- In il nome pipeline, digita un nome di pipeline univoco.
- Selezionare la casella di controllo Serverless.
- Selezionare Attivato in modalità pipeline. Verranno eseguiti i flussi di streaming usando il trigger AvailableNow, che elabora tutti i dati esistenti e quindi arresta il flusso.
- In Destinazione, per configurare un percorso del catalogo Unity in cui vengono pubblicate le tabelle, selezionare un catalogo esistente e scrivere un nuovo nome in Schema per creare un nuovo schema nel catalogo.
- Fare clic su Crea.
Viene visualizzata l'interfaccia utente della pipeline per la nuova pipeline.
Un notebook di codice sorgente vuoto viene creato e configurato automaticamente per la pipeline. Il notebook viene creato in una nuova directory nella tua directory utente. Il nome della nuova directory e quello del file corrispondono al nome della pipeline. Ad esempio, /Users/someone@example.com/my_pipeline/my_pipeline.
- Un collegamento per accedere a questo notebook si trova nel campo codice sorgente nel pannello dettagli del pipeline. Fare clic sul collegamento per aprire il notebook prima di procedere al passaggio successivo.
- Fare clic su Connect in alto a destra per aprire il menu di configurazione del calcolo.
- Passare il puntatore del mouse sul nome della pipeline creata nel passaggio 1.
- Fare clic su Connetti.
- Accanto al titolo del notebook nella parte superiore selezionare il linguaggio predefinito del notebook (Python o SQL).
Importante
I notebook possono contenere solo un singolo linguaggio di programmazione. Non mischiare il codice Python e SQL nei notebook del codice sorgente della pipeline.
Quando si sviluppano pipeline dichiarative di Lakeflow, è possibile scegliere Python o SQL. Questa esercitazione include esempi per entrambe le lingue. In base alla lingua scelta, verificare di selezionare la lingua predefinita del notebook.
Per altre informazioni sul supporto dei notebook per lo sviluppo di codice di Pipeline dichiarative di Lakeflow, vedere Sviluppare ed eseguire il debug di pipeline ETL con un notebook in Pipeline dichiarative di Lakeflow.
Passaggio 2: Inserire dati in modo incrementale con il caricatore automatico
Il primo passaggio consiste nell'inserire i dati non elaborati provenienti dall'archiviazione cloud in un livello *bronze*.
Questo può essere difficile per diversi motivi, perché è necessario:
- Operare su larga scala, potenzialmente inglobando milioni di piccoli file.
- Dedurre lo schema e il tipo JSON.
- Gestire record non validi con uno schema JSON non corretto.
- Prestare attenzione all'evoluzione dello schema, ad esempio una nuova colonna nella tabella cliente.
Il caricatore automatico semplifica questo inserimento, inclusa l'inferenza dello schema e l'evoluzione dello schema, e scalare per gestire milioni di file in ingresso. Il caricatore automatico è disponibile in Python usando e in SQL usando cloudFilesSELECT * FROM STREAM read_files(...) e può essere usato con un'ampia gamma di formati (JSON, CSV, Apache Avro e così via):
La definizione della tabella come tabella di streaming garantisce il consumo di nuovi dati in ingresso. Se non la definisci come tabella di streaming, verranno analizzati e inseriti tutti i dati disponibili. Per altre informazioni, vedere Tabelle di streaming .
Per inserire i dati in ingresso usando il caricatore automatico, copiare e incollare il codice seguente nella prima cella del notebook. È possibile usare Python o SQL, a seconda del linguaggio predefinito del notebook scelto nel passaggio precedente.
Pitone
from dlt import * from pyspark.sql.functions import * # Create the target bronze table dlt.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load("/Volumes/main/dbdemos_dlt_cdc/raw_data/customers") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( "/Volumes/main/dbdemos_dlt_cdc/raw_data/customers", format => "json", inferColumnTypes => "true" )Fare clic su Start per avviare un aggiornamento per la pipeline connessa.
Passaggio 3: Pulizia e aspettative per tenere traccia della qualità dei dati
Dopo aver definito il livello bronzo, si creeranno i livelli silver aggiungendo aspettative per controllare la qualità dei dati controllando le condizioni seguenti:
- L'ID non deve mai essere
null. - Il tipo di operazione CDC deve essere valido.
- Il
jsondeve essere stato letto in modo adeguato dall'Auto Loader.
La riga verrà eliminata se una di queste condizioni non viene rispettata.
Per altre informazioni, vedere Gestire la qualità dei dati con le aspettative della pipeline .
Fare clic su Modifica e Inserisci cella di seguito per inserire una nuova cella vuota.
Per creare uno strato argento con una tabella ripulita e imporre vincoli, copiate e incollate il codice seguente nella nuova cella del notebook.
Pitone
dlt.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( dlt.read_stream("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Fare clic su Start per avviare un aggiornamento per la pipeline connessa.
Passaggio 4: Materializzazione della tabella clienti con un flusso AUTO CDC
La customers tabella conterrà la vista più up-to-date e sarà una replica della tabella originale.
Implementare manualmente non è un compito banale. È necessario considerare elementi come la deduplicazione dei dati per mantenere la riga più recente.
Tuttavia, Le pipeline dichiarative di Lakeflow risolvono queste sfide con l'operazione AUTO CDC .
Fare clic su Modifica e Inserisci cella di seguito per inserire una nuova cella vuota.
Per elaborare i dati CDC usando
AUTO CDCin Lakeflow Declarative Pipelines, copiare e incollare il codice seguente nella nuova cella del notebook.Pitone
dlt.create_streaming_table(name="customers", comment="Clean, materialized customers") dlt.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Fare clic su Start per avviare un aggiornamento per la pipeline connessa.
Passaggio 5: Dimensione a modifica lenta di tipo 2 (SCD2)
Spesso è necessario creare una tabella che monitora tutte le modifiche risultanti da APPEND, UPDATEe DELETE:
- Cronologia: si vuole mantenere una cronologia di tutte le modifiche apportate alla tabella.
- Tracciabilità: si vuole vedere quale operazione si è verificata.
SCD2 con le pipeline dichiarative di Lakeflow
Delta supporta il flusso di dati delle modifiche (CDF) e table_change può eseguire query sulle modifiche delle tabelle in SQL e Python. Tuttavia, il caso d'uso principale di CDF consiste nell'acquisire le modifiche in una pipeline e non creare una visualizzazione completa delle modifiche della tabella dall'inizio.
Le cose sono particolarmente complesse da implementare se si dispone di eventi non ordinati. Se è necessario sequenziare le modifiche in base a un timestamp e ricevere una modifica apportata in passato, è necessario aggiungere una nuova voce nella tabella scD e aggiornare le voci precedenti.
Lakeflow Declarative Pipelines rimuove questa complessità e consente di creare una tabella separata contenente tutte le modifiche dall'inizio del tempo. Questa tabella può quindi essere usata su larga scala, con partizioni/colonne zorder specifiche, se necessario. I campi non in ordine verranno gestiti automaticamente in base al _sequence_by
Per creare una tabella SCD2, è necessario usare l'opzione : STORED AS SCD TYPE 2 in SQL o stored_as_scd_type="2" in Python.
Nota
È anche possibile limitare quali colonne la funzionalità traccia tramite l'opzione: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Fare clic su Modifica e Inserisci cella di seguito per inserire una nuova cella vuota.
Copiare e incollare il codice seguente nella nuova cella del notebook.
Pitone
# create the table dlt.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dlt.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW cusotmers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Fare clic su Start per avviare un aggiornamento per la pipeline connessa.
Passaggio 6: Creare una vista materializzata che tiene traccia di chi ha modificato le proprie informazioni di più.
La tabella customers_history contiene tutte le modifiche cronologiche apportate da un utente alle relative informazioni. A questo punto si creerà una visualizzazione materializzata semplice nel livello oro che tiene traccia di chi ha modificato maggiormente le proprie informazioni. Questo può essere usato per l'analisi del rilevamento delle frodi o le raccomandazioni degli utenti in uno scenario reale. Inoltre, l'applicazione di modifiche con SCD2 ha già rimosso duplicati per noi, in modo da poter contare direttamente le righe per ID utente.
Fare clic su Modifica e Inserisci cella di seguito per inserire una nuova cella vuota.
Copiare e incollare il codice seguente nella nuova cella del notebook.
Pitone
@dlt.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( dlt.read("customers_history") .groupBy("id") .agg( count("address").alias("address_count"), count("email").alias("email_count"), count("firstname").alias("firstname_count"), count("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count("address") as address_count, count("email") AS email_count, count("firstname") AS firstname_count, count("lastname") AS lastname_count FROM customers_history GROUP BY idFare clic su Start per avviare un aggiornamento per la pipeline connessa.
Passaggio 7: Creare un processo per eseguire la pipeline ETL
Creare quindi un flusso di lavoro per automatizzare i passaggi di inserimento, elaborazione e analisi dei dati usando un processo di Databricks.
- Nell'area di lavoro fare clic Processi e pipeline nella barra laterale.
- In Nuovo fare clic su Lavoro.
- Nella casella del titolo attività sostituire Nuovo lavoro <data e ora> con il nome del tuo lavoro. Ad esempio,
CDC customers workflow. - In Nome attività immettere un nome per la prima attività, ad esempio
ETL_customers_data. - In Tipo selezionare Pipeline.
- In Pipeline selezionare la pipeline creata nel passaggio 1.
- Fare clic su Crea.
- Per eseguire il flusso di lavoro, fare clic su Esegui ora. Per visualizzare i dettagli dell'esecuzione, fare clic sulla scheda Esecuzioni. Fare clic sul compito per visualizzare i dettagli dell'esecuzione del compito.
- Per visualizzare i risultati al termine del flusso di lavoro, fare clic su Vai all'ultima esecuzione riuscita o all'ora di inizio per l'esecuzione del processo. Viene visualizzata la pagina Output con i risultati della query.
Vedere Monitoraggio e osservabilità per i processi Lakeflow per ulteriori informazioni sulle esecuzioni dei processi.
Passaggio 8: Pianificare il processo
Per eseguire la pipeline ETL in base a una pianificazione, seguire questa procedura:
- Fare clic Processi e pipeline nella barra laterale.
- Opzionalmente, selezionare i filtri Attività e Di mia proprietà.
- Nella colonna Nome, fare clic sul nome del lavoro. Il pannello laterale viene visualizzato come i dettagli dell'attività.
- Fare clic su Aggiungi trigger nel pannello Pianificazioni e trigger e selezionare Pianificato in Tipo di trigger.
- Specificare il periodo, l'ora di inizio e il fuso orario.
- Fare clic su Salva.