Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come iniziare a usare Databricks Connect per Scala usando IntelliJ IDEA e il plug-in Scala.
In questa esercitazione creerai un progetto in IntelliJ IDEA, installerai Databricks Connect per Databricks Runtime 13.3 LTS e versioni successive ed eseguirai codice semplice sul sistema di calcolo nel workspace Databricks da IntelliJ IDEA.
Suggerimento
Per informazioni su come usare i bundle di automazione dichiarativa per creare un progetto Scala che esegue codice nel calcolo serverless, vedere Creare un file JAR scala usando bundle di automazione dichiarativa.
Requisiti
Per completare questa esercitazione, è necessario soddisfare i requisiti seguenti:
L'area di lavoro, l'ambiente locale e il calcolo soddisfano i requisiti per Databricks Connect per Scala. Vedere Requisiti di utilizzo di Databricks Connect.
È necessario avere a disposizione il proprio ID del cluster. Per ottenere l'ID cluster, nell'area di lavoro fare clic su Calcolo sulla barra laterale e quindi sul nome del cluster. Nella barra degli indirizzi del Web browser copiare la stringa di caratteri tra
clusterseconfigurationnell'URL.Nel computer di sviluppo è installato Java Development Kit (JDK). Per informazioni sulla versione da installare, vedere matrice di supporto della versione.
Annotazioni
Se non è installato un JDK o se sono presenti più installazioni JDK nel computer di sviluppo, è possibile installare o scegliere un JDK specifico più avanti nel passaggio 1. La scelta di un'installazione JDK sottostante o successiva alla versione JDK nel cluster potrebbe produrre risultati imprevisti oppure il codice potrebbe non essere eseguito affatto.
È installato IntelliJ IDEA. Questa esercitazione è stata testata con IntelliJ IDEA Community Edition 2023.3.6. Se si usa una versione o un'edizione diversa di IntelliJ IDEA, le istruzioni seguenti possono variare.
Hai installato il plug-in Scala per IntelliJ IDEA.
Passaggio 1: Configurare l'autenticazione di Azure Databricks
In questo tutorial viene utilizzata l'autenticazione OAuth da utente a macchina (U2M) di Azure Databricks e un profilo di configurazione di Azure Databricks per l'autenticazione con l'area di lavoro di Azure Databricks. Per usare invece un tipo di autenticazione diverso, vedere Configurare le proprietà di connessione.
La configurazione dell'autenticazione U2M OAuth richiede l'interfaccia della riga di comando di Databricks, come indicato di seguito:
Installare l'interfaccia della riga di comando di Databricks:
Linux, macOS
Usare Homebrew per installare l'interfaccia della riga di comando di Databricks eseguendo i comandi seguenti:
brew tap databricks/tap brew trust databricks/tap brew install databricksIl
brew trustcomando è obbligatorio a partire da Homebrew 6.0.0.Windows
È possibile usare winget, Chocolatey o sottosistema Windows per Linux (WSL) per installare l'interfaccia della riga di comando di Databricks. Se non puoi usare
winget, Chocolatey o WSL, dovresti ignorare questa procedura e usare il prompt dei comandi o PowerShell per installare il Databricks CLI dal codice sorgente.Annotazioni
L'installazione dell'interfaccia a riga di comando di Databricks tramite Chocolatey è sperimentale.
Per usare
wingetper installare l'interfaccia della riga di comando di Databricks, eseguire i due comandi seguenti e quindi riavviare il prompt dei comandi:winget search databricks winget install Databricks.DatabricksCLIPer usare Chocolatey per installare l'interfaccia della riga di comando di Databricks, eseguire il comando seguente:
choco install databricks-cliPer usare WSL per installare l'interfaccia della riga di comando di Databricks:
Installare
curleziptramite WSL. Per altre informazioni, vedere la documentazione del sistema operativo.Usare WSL per installare l'interfaccia della riga di comando di Databricks eseguendo il comando seguente:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Verificare che l'interfaccia della riga di comando di Databricks sia installata eseguendo il comando seguente, che visualizza la versione corrente dell'interfaccia della riga di comando di Databricks installata. Questa versione deve essere 0.205.0 o successiva:
databricks -v
Avviare l'autenticazione U2M OAuth, come indicato di seguito:
Usare il Databricks CLI per avviare la gestione dei token OAuth in locale eseguendo il seguente comando per ogni area di lavoro di destinazione.
Nel seguente comando, sostituire
<workspace-url>con l’URL per l'area di lavoro di Azure Databricks, per esempiohttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Il Databricks CLI richiede di salvare le informazioni immesse come profilo di configurazione di Azure Databricks. Premere
Enterper accettare il nome del profilo suggerito oppure immettere il nome di un profilo nuovo o esistente. Qualsiasi profilo esistente con lo stesso nome viene sovrascritto con le informazioni immesse. È possibile usare i profili per cambiare rapidamente il contesto di autenticazione tra più aree di lavoro.Per ottenere un elenco di tutti i profili esistenti, in un terminale o un prompt dei comandi separato, usare il Databricks CLI per eseguire il comando
databricks auth profiles. Per visualizzare le impostazioni esistenti di un profilo specifico, eseguire il comandodatabricks auth env --profile <profile-name>.Nel Web browser completare le istruzioni visualizzate per accedere all'area di lavoro di Azure Databricks.
Nell'elenco dei cluster disponibili visualizzati nel terminale o nel prompt dei comandi usare i tasti freccia su e freccia giù per selezionare il cluster Azure Databricks di destinazione nell'area di lavoro e quindi premere
Enter. È anche possibile digitare qualsiasi parte del nome visualizzato del cluster per filtrare l'elenco dei cluster disponibili.Per visualizzare il valore corrente del token OAuth di un profilo e il timestamp di scadenza imminente del token, eseguire uno dei comandi seguenti:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se si dispone di più profili con lo stesso valore
--host, potrebbe essere necessario specificare insieme le opzioni--hoste-pper consentire al Databricks CLI di trovare le informazioni corrette corrispondenti sul token OAuth.
Step 2: Creare il progetto
Avvia IntelliJ IDEA.
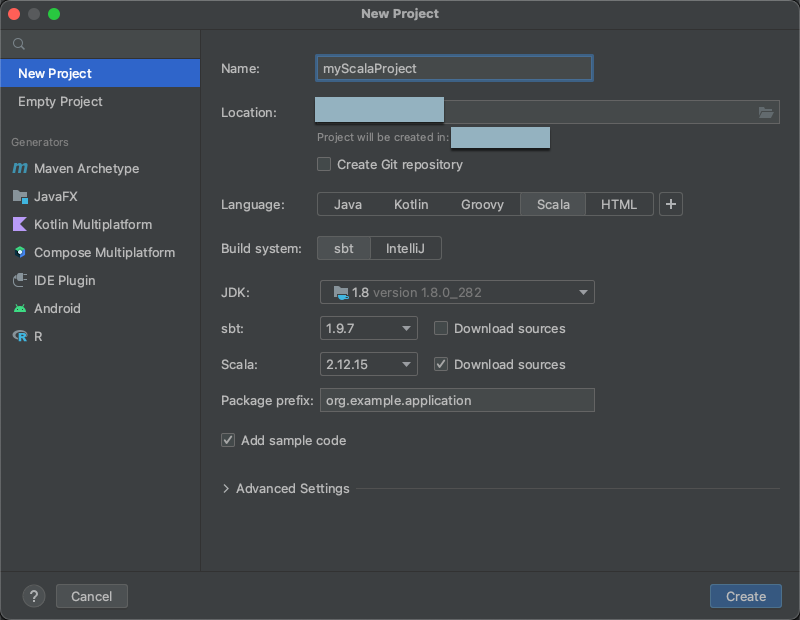
Scegliere File > Nuovo > progetto dal menu principale.
Assegnare al progetto un nome significativo.
Per la Posizione , fare clic sull'icona della cartella e completare le istruzioni sullo schermo per specificare il percorso del tuo nuovo progetto Scala.
Nella sezione Lingua fare clic su Scala.
In Sistema di compilazione, fare clic su sbt.
Nell'elenco a discesa JDK, selezionare un'installazione esistente del JDK sul computer di sviluppo che corrisponde alla versione del JDK nel cluster, oppure selezionare Scarica JDK e seguire le istruzioni visualizzate per scaricare un JDK che corrisponde alla versione del JDK nel cluster. Vedere Requisiti.
Annotazioni
La scelta di un'installazione JDK precedente o successiva alla versione JDK nel cluster potrebbe produrre risultati imprevisti oppure il codice potrebbe non essere eseguito affatto.
Nell'elenco a discesa sbt selezionare la versione più recente.
Nell'elenco a discesa Scala, selezionare la versione di Scala corrispondente alla versione di Scala nel cluster. Vedere Requisiti.
Annotazioni
La scelta di una versione Scala sottostante o superiore alla versione scala nel cluster potrebbe produrre risultati imprevisti oppure il codice potrebbe non essere eseguito affatto.
Assicurarsi che la casella Scarica origini accanto a Scala sia selezionata.
Per Prefisso pacchetto immettere un valore di prefisso del pacchetto per le origini del progetto, ad esempio
org.example.application.Assicurarsi che la casella Aggiungi codice di esempio sia selezionata.
Clicca su Crea.
Passaggio 3: Aggiungere il pacchetto Databricks Connect
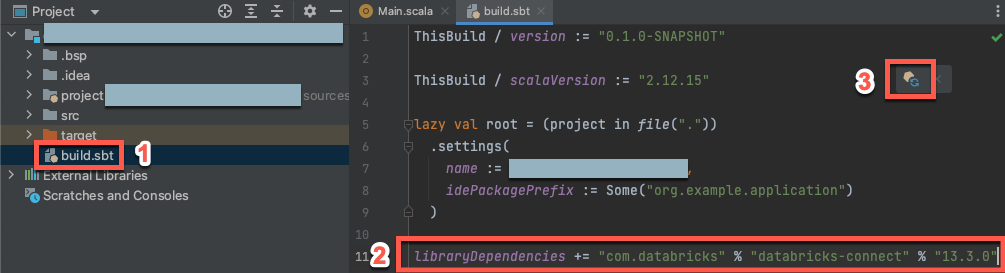
Con il nuovo progetto Scala aperto, nella finestra degli strumenti Project (Visualizza > Strumenti > Project), apri il file denominato
build.sbtin project-name> target.Aggiungere il codice seguente alla fine del
build.sbtfile, che dichiara la dipendenza del progetto da una versione specifica della libreria Databricks Connect per Scala, compatibile con la versione di Databricks Runtime del cluster:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"Sostituire
17.3con la versione della libreria Databricks Connect corrispondente alla versione di Databricks Runtime nel cluster. Ad esempio, Databricks Connect 17.3.+ corrisponde a Databricks Runtime 17.3 LTS. È possibile trovare i numeri di versione della libreria Databricks Connect nel repository centrale Maven (per Databricks Runtime 16.4 LTS e versioni successive) o nel repository centrale Maven (per Databricks Runtime 17.0 e versioni successive) .Annotazioni
Quando si utilizza Databricks Connect, non includere artefatti di Apache Spark, ad esempio
org.apache.spark:spark-core, nel progetto. Compilare invece direttamente in Databricks Connect.Fare clic sull'icona di notifica Carica modifiche sbt per aggiornare il progetto Scala con il nuovo percorso della libreria e le nuove dipendenze.
Attendere che l'indicatore di stato
sbtnella parte inferiore dell'IDE scompaia. Il completamento delsbtprocesso di caricamento potrebbe richiedere alcuni minuti.
Passaggio 4: Aggiungere codice
Nella finestra dello strumento Project, aprire il file denominato
Main.scala, in project-name> src > main > scala.Sostituire qualsiasi codice esistente nel file con il codice seguente e quindi salvare il file, a seconda del nome del profilo di configurazione.
Se il profilo di configurazione del passaggio 1 è denominato
DEFAULT, sostituire qualsiasi codice esistente nel file con il codice seguente e quindi salvare il file:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Se il profilo di configurazione del passaggio 1 non è denominato
DEFAULT, sostituire invece qualsiasi codice esistente nel file con il codice seguente. Sostituire il segnaposto<profile-name>con il nome del profilo di configurazione del passaggio 1 e quindi salvare il file:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Passaggio 5: Configurare le opzioni della macchina virtuale
Importa la directory corrente in IntelliJ dove si trova
build.sbt.Scegliere Java 17 in IntelliJ. Passare a File>Struttura del progetto>SDK.
Apri
src/main/scala/com/examples/Main.scala.Passare alla configurazione per Main per aggiungere le opzioni della macchina virtuale:
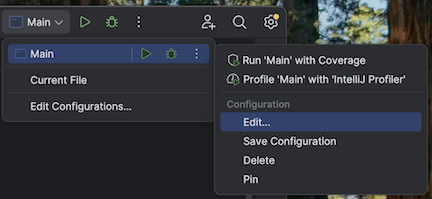
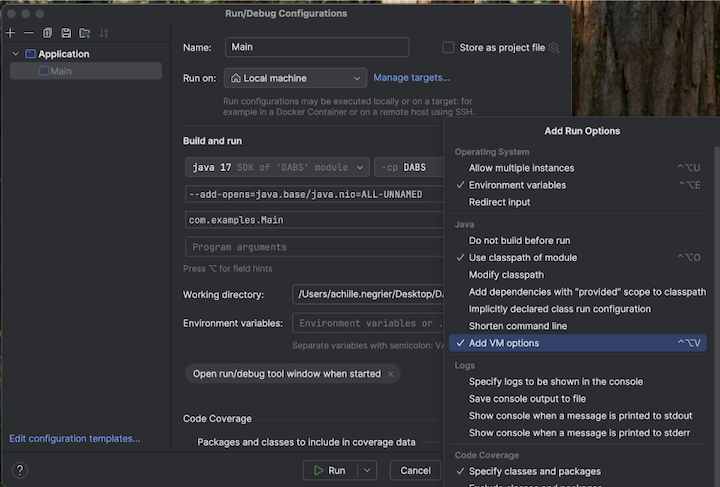
Aggiungere quanto segue alle opzioni della macchina virtuale:
--add-opens=java.base/java.nio=ALL-UNNAMED
Suggerimento
In alternativa, o se si usa Visual Studio Code, aggiungere quanto segue al file di compilazione sbt:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Eseguire quindi l'applicazione dal terminale:
sbt run
Passaggio 6: Eseguire il codice
- Avviare il cluster di destinazione nell'area di lavoro remota di Azure Databricks.
- Dopo l'avvio del cluster, nel menu principale fare clic su Esegui > Esegui 'Main'.
- Nella finestra dello strumento Esegui (Visualizza > Strumenti > Esegui), nella scheda Principale, vengono visualizzate le prime 5 righe della tabella
samples.nyctaxi.trips.
Passaggio 7: Eseguire il debug del codice
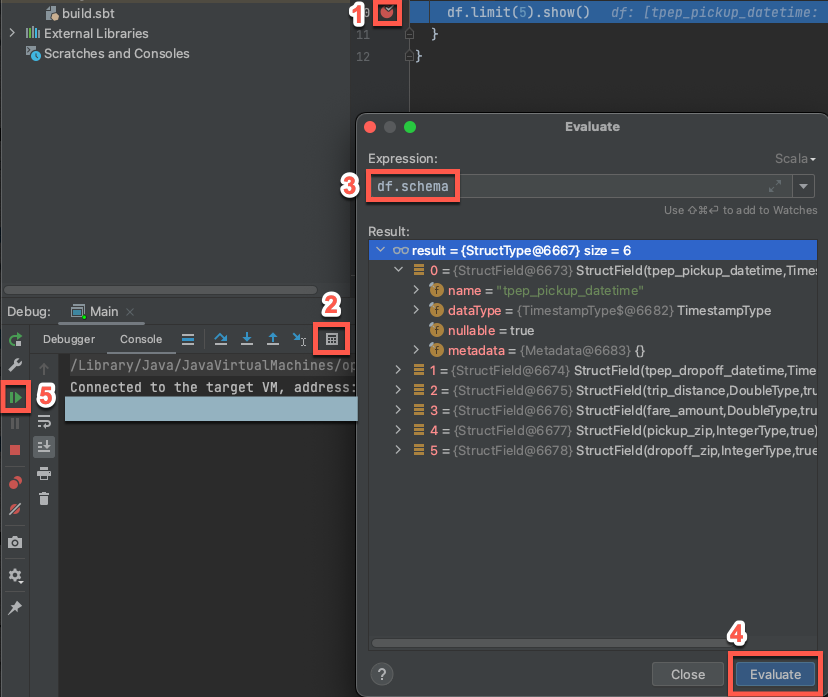
Con il cluster di destinazione ancora in esecuzione, nel codice precedente cliccare sulla barra accanto a
df.limit(5).show()per impostare un punto di interruzione.Nel menu principale fare clic su Esegui > Debug 'Main'. Nella finestra Strumento Debug (Visualizza > Finestre > degli strumenti Debug), nella scheda Console, fare clic sull'icona della calcolatrice (Valuta espressione).
Immettere l'espressione
df.schema.Fare clic su Valuta per visualizzare lo schema del dataframe.
Nella barra laterale della finestra dello strumento di debug fare clic sulla freccia verde (Riprendi programma). Le prime 5 righe della
samples.nyctaxi.tripstabella vengono visualizzate nel riquadro Console .