Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'estensione Databricks per Visual Studio Code offre funzionalità aggiuntive all'interno di Visual Studio Code che consentono di definire, distribuire ed eseguire bundle di automazione dichiarativa per applicare le procedure consigliate ci/CD ai processi Lakeflow, alle pipeline dichiarative di Lakeflow Spark e agli stack MLOps. Vedere Che cosa sono i bundle di automazione dichiarativa?.
Per installare l'estensione Databricks per Visual Studio Code, vedere Installare l'estensione Databricks per Visual Studio Code.
Supporto di bundle di automazione dichiarativa nei progetti
L'estensione Databricks per Visual Studio Code aggiunge le funzionalità seguenti per i progetti bundle di automazione dichiarativa:
- Autenticazione e configurazione semplificate dei bundle di automazione dichiarativa tramite l'interfaccia utente di Visual Studio Code, inclusa la selezione del profilo AuthType . Vedere Configurare l'autorizzazione per l'estensione Databricks per Visual Studio Code.
- Selettore Target nel pannello dell'estensione Databricks per passare rapidamente fra ambienti target del bundle. Vedi Modificare l'area di lavoro di distribuzione di destinazione.
- L'opzione Override Jobs cluster in bundle nel pannello dell'estensione per un facile override del cluster.
- Visualizzazione Bundle Resource Explorer, che consente di esplorare le risorse del bundle utilizzando l'interfaccia utente di Visual Studio Code, distribuire le risorse del Databricks Asset Bundle locali nell'area di lavoro remota di Azure Databricks con un solo clic e accedere direttamente alle risorse distribuite nell'area di lavoro da Visual Studio Code. Vedere Bundle Resource Explorer.
- Una visualizzazione Bundle Variabili, che consente di esplorare e modificare le variabili del bundle usando l'interfaccia utente di Visual Studio Code. Vedere Visualizzazione delle Variabili di Bundle.
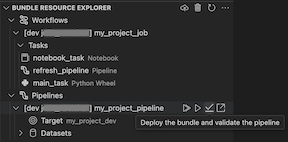
Esplora risorse bundle
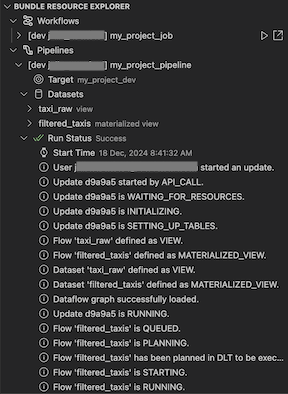
La vista Esplora risorse bundle nell'estensione Databricks per Visual Studio Code usa le definizioni delle risorse nella configurazione del bundle del progetto per visualizzare le risorse, inclusi anche i set di dati delle pipeline e i relativi schemi. Consente anche di distribuire ed eseguire risorse, convalidare ed eseguire aggiornamenti parziali delle pipeline, visualizzare gli eventi di esecuzione della pipeline e la diagnostica e passare alle risorse nell'area di lavoro remota di Azure Databricks. Per informazioni sulle risorse di configurazione del bundle, vedere Risorse.
Ad esempio, data una definizione di lavoro semplice:
resources:
jobs:
my-notebook-job:
name: 'My Notebook Job'
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
La vista Bundle Resource Explorer nell'estensione visualizza la risorsa del job del notebook.
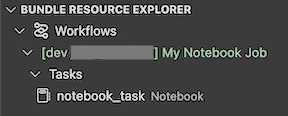
Distribuire ed eseguire un'attività
Per distribuire il bundle, fare clic sull'icona cloud (Distribuisci bundle).
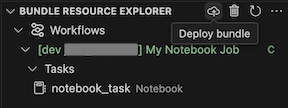
Per eseguire il processo, nella visualizzazione Bundle Resource Explorer selezionare il nome del processo, ovvero My Notebook Job in questo esempio. Fare quindi clic sull'icona play (Distribuire il bundle ed eseguire la risorsa).
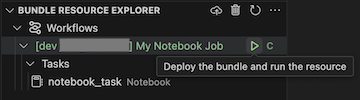
Per visualizzare il processo in esecuzione, nella visualizzazione Esplora risorse Bundle espandere il nome del processo, fare clic su Stato di esecuzione e quindi fare clic sull'icona del collegamento (Apri il collegamento esternamente).
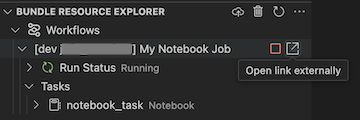
Validare e diagnosticare i problemi della pipeline
Per una pipeline, è possibile attivare la convalida e un aggiornamento parziale selezionando la pipeline, quindi l'icona di verifica (Distribuire il bundle e convalidare la pipeline). Gli eventi dell'esecuzione vengono visualizzati ed eventuali errori possono essere diagnosticati all'interno del pannello PROBLEMI di Visual Studio Code.
Visualizzazione variabili bundle
La visualizzazione Variabili del Bundle nell'estensione di Databricks per Visual Studio Code visualizza le variabili personalizzate e le impostazioni associate definite nella configurazione del bundle. È anche possibile definire le variabili direttamente usando la Visualizzazione Variabili dei Bundle. Questi valori sostituiscono quelli impostati nei file di configurazione del bundle. Per informazioni sulle variabili personalizzate, vedere Variabili personalizzate.
Ad esempio, la Visualizzazione variabili bundle nell'estensione visualizzerebbe quanto segue:

Per la variabile my_custom_var definita in questa configurazione del bundle:
variables:
my_custom_var:
description: 'Max workers'
default: '4'
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}