Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come usare un notebook di Azure Databricks per eseguire query sui dati di esempio archiviati in Unity Catalog usando SQL, Python, Scala e R e quindi visualizzare i risultati della query nel notebook.
Suggerimento
Indicare a Genie Code (modalità agente) di eseguire questa operazione:
Create a new notebook that queries @samples.nyctaxi.trips and displays a bar chart showing the average fare amount by trip distance, grouped by the pickup zip code.
Requisiti
Per completare queste attività, è necessario soddisfare i requisiti seguenti:
- L'area di lavoro deve avere il Catalogo Unity abilitato. Per informazioni su come iniziare a usare Il catalogo unity, vedere Introduzione al catalogo unity.
- È necessario disporre dell'autorizzazione per usare una risorsa di calcolo esistente o creare una nuova risorsa di calcolo. Consulta Calcolo o il tuo amministratore Databricks.
Passaggio 1: Creare un nuovo notebook
Per creare un Notebook nell'area di lavoro, fare clic su ![]() Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Nuovo nella barra laterale e quindi su Notebook. Viene aperto un Notebook vuoto nell'area di lavoro.
Per altre informazioni sulla creazione e la gestione dei notebook, vedere Gestire i notebook di Databricks.
Passaggio 2: Eseguire query su una tabella
Eseguire una query sulla tabella samples.nyctaxi.trips in Unity Catalog usando il linguaggio preferito. Questa tabella è uno dei set di dati di esempio inclusi nel samples catalogo.
Copiare e incollare il codice seguente nella nuova cella vuota del Notebook. Questo codice visualizza i risultati della query sulla tabella
samples.nyctaxi.tripsin Unity Catalog.SQL
SELECT * FROM samples.nyctaxi.tripsPitone
display(spark.read.table("samples.nyctaxi.trips"))Linguaggio di programmazione Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Premere
Shift+Enterper eseguire la cella e poi passare alla cella successiva.I risultati della query vengono visualizzati nel notebook.
Passaggio 3: Visualizzare i dati
Visualizzare l'importo medio della tariffa in base alla distanza della corsa, raggruppata in base al codice postale del ritiro.
Accanto alla scheda Tabella, fare clic su + e quindi su Visualizzazione.
Viene visualizzato l'editor di visualizzazione.
Nell'elenco a discesa Tipo di visualizzazione verificare che sia selezionata l'opzione Barra.
Selezionare
fare_amountper la colonna X.Selezionare
trip_distanceper la colonna Y.Selezionare
Averagecome tipo di aggregazione.Selezionare
pickup_zipcome colonna Raggruppa per.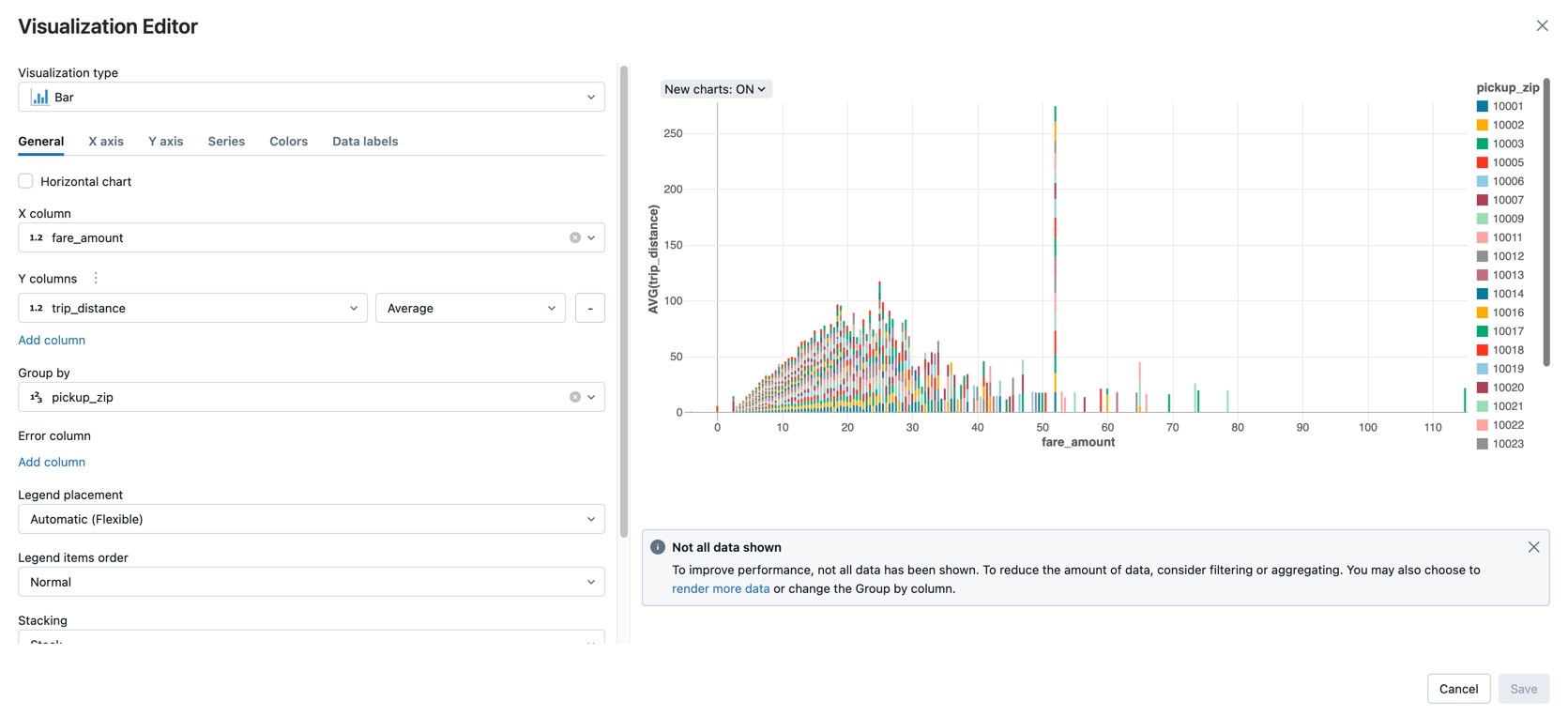
Fare clic su Salva.
Passaggi successivi
- Per informazioni sull'aggiunta di dati da un file CSV a Unity Catalog e sulla visualizzazione dei dati, vedere Esercitazione: Importare e visualizzare i dati CSV da un notebook.
- Per informazioni su come caricare dati in Databricks con Apache Spark, vedere Esercitazione: Caricare e trasformare i dati con dataframe Apache Spark.
- Per altre informazioni sull'inserimento di dati in Databricks, vedere Connettori Standard in Lakeflow Connect.
- Per altre informazioni sull'esecuzione di query sui dati con Databricks, vedere Eseguire query sui dati.
- Per altre informazioni sulle visualizzazioni, vedere Visualizzazioni nei notebook di Databricks e nell'editor SQL.
- Per altre informazioni sulle tecniche di analisi esplorativa dei dati (EDA), vedere Tutorial: EDA techniques using Databricks notebooks.