Che cos'è un data lakehouse?
Un data lakehouse è un sistema di gestione dei dati che combina i vantaggi dei data lake e dei data warehouse. Questo articolo descrive il modello architettonico lakehouse e le operazioni che è possibile eseguire in Azure Databricks.
Che cos'è un data lakehouse usato per?
Un data lakehouse offre funzionalità di archiviazione ed elaborazione scalabili per le organizzazioni moderne che vogliono evitare sistemi isolati per l'elaborazione di carichi di lavoro diversi, ad esempio Machine Learning (ML) e Business Intelligence (BI). Un data lakehouse può aiutare a stabilire una singola fonte di verità, eliminare i costi ridondanti e garantire l'aggiornamento dei dati.
I data lakehouse usano spesso un modello di progettazione dei dati che migliora, arricchisce e affina i dati man mano che si spostano attraverso livelli di staging e trasformazione. Ogni livello della lakehouse può includere uno o più strati. Questo modello viene spesso definito architettura medallion. Per altre informazioni, vedere Che cos'è l'architettura del lago medallion?
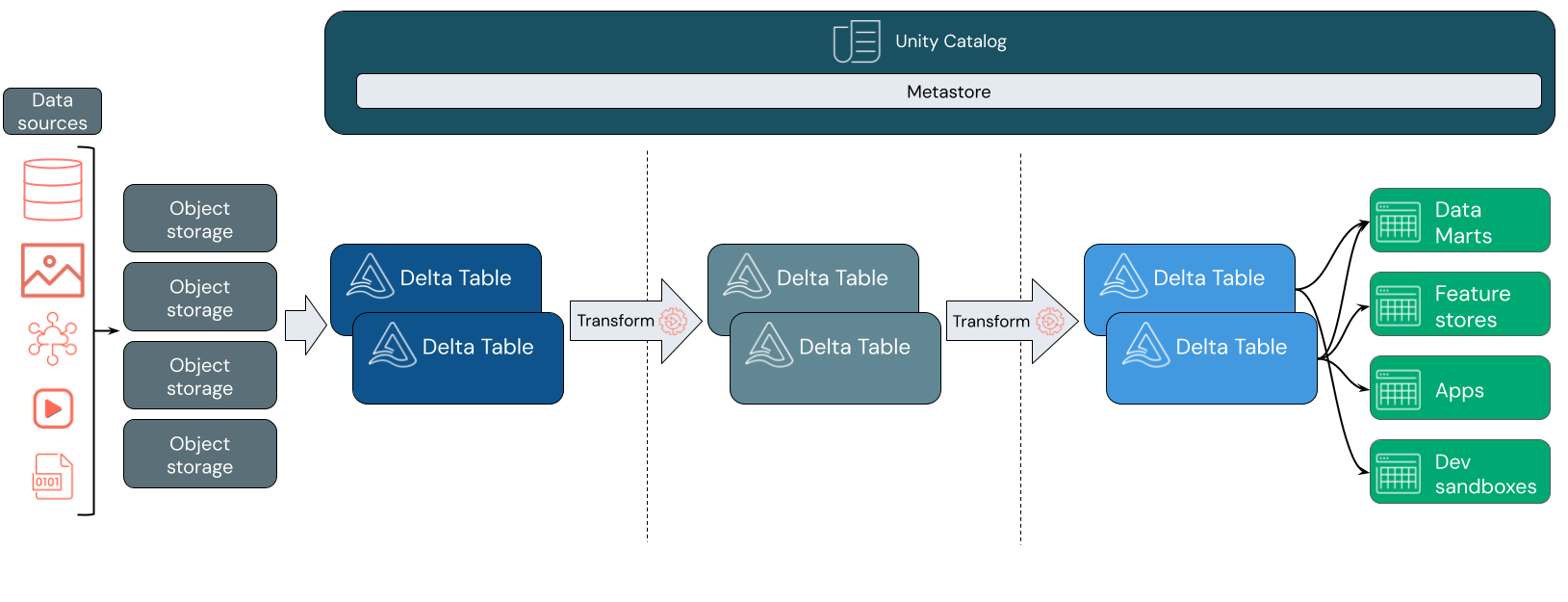
Come funziona databricks lakehouse?
Databricks è basato su Apache Spark. Apache Spark abilita un motore scalabile enormemente scalabile che viene eseguito su risorse di calcolo separate dall'archiviazione. Per altre informazioni, vedere Apache Spark in Azure Databricks
Databricks lakehouse usa due tecnologie chiave aggiuntive:
- Delta Lake: un livello di archiviazione ottimizzato che supporta transazioni ACID e imposizione dello schema.
- Catalogo unity: una soluzione di governance unificata e granulare per i dati e l'intelligenza artificiale.
Inserimento dati
A livello di inserimento, i dati batch o di streaming arrivano da un'ampia gamma di origini e in un'ampia gamma di formati. Questo primo livello logico fornisce una posizione in cui i dati vengono inseriti nel formato non elaborato. Durante la conversione di tali file in tabelle Delta, è possibile usare le funzionalità di imposizione dello schema di Delta Lake per verificare la presenza di dati mancanti o imprevisti. È possibile usare Unity Catalog per registrare le tabelle in base al modello di governance dei dati e ai limiti di isolamento dei dati necessari. Unity Catalog consente di tenere traccia della derivazione dei dati man mano che vengono trasformati e perfezionati, nonché di applicare un modello di governance unificato per mantenere i dati sensibili privati e sicuri.
Elaborazione, cura e integrazione dei dati
Dopo la verifica, è possibile iniziare a curare e perfezionare i dati. I data scientist e i professionisti di Machine Learning lavorano spesso con i dati in questa fase per iniziare a combinare o creare nuove funzionalità e completare la pulizia dei dati. Una volta che i dati sono stati puliti accuratamente, possono essere integrati e riorganizzati in tabelle progettate per soddisfare le esigenze aziendali specifiche.
Un approccio schema-on-write, combinato con le funzionalità di evoluzione dello schema Delta, significa che è possibile apportare modifiche a questo livello senza dover riscrivere necessariamente la logica downstream che serve i dati agli utenti finali.
Gestione dei dati
Il livello finale serve dati puliti e arricchiti agli utenti finali. Le tabelle finali devono essere progettate per gestire i dati per tutti i casi d'uso. Un modello di governance unificato consente di tenere traccia della derivazione dei dati nell'unica fonte di verità. I layout dei dati, ottimizzati per diverse attività, consentono agli utenti finali di accedere ai dati per applicazioni di Machine Learning, progettazione dei dati e business intelligence e creazione di report.
Per altre informazioni su Delta Lake, vedere Che cos'è Delta Lake? Per altre informazioni sul catalogo unity, vedere Che cos'è il catalogo unity?
Funzionalità di una databricks lakehouse
Una lakehouse basata su Databricks sostituisce la dipendenza corrente dai data lake e dai data warehouse per le aziende di dati moderne. Alcune attività chiave che è possibile eseguire includono:
- Elaborazione dei dati in tempo reale: elaborare i dati in streaming in tempo reale per l'analisi e l'azione immediate.
- Integrazione dei dati: unificare i dati in un unico sistema per consentire la collaborazione e stabilire una singola fonte di verità per l'organizzazione.
- Evoluzione dello schema: modificare lo schema dei dati nel tempo per adattarsi alle esigenze aziendali mutevoli senza interrompere le pipeline di dati esistenti.
- Trasformazioni dei dati: l'uso di Apache Spark e Delta Lake offre velocità, scalabilità e affidabilità ai dati.
- Analisi e creazione di report dei dati: eseguire query analitiche complesse con un motore ottimizzato per i carichi di lavoro di data warehousing.
- Machine Learning e intelligenza artificiale: applicare tecniche di analisi avanzate a tutti i dati. Usare ML per arricchire i dati e supportare altri carichi di lavoro.
- Controllo delle versioni dei dati e derivazione: mantenere la cronologia delle versioni per i set di dati e tenere traccia della derivazione per garantire la provenienza e la tracciabilità dei dati.
- Governance dei dati: usare un unico sistema unificato per controllare l'accesso ai dati ed eseguire controlli.
- Condivisione dei dati: facilitare la collaborazione consentendo la condivisione di set di dati, report e informazioni dettagliate curati tra i team.
- Analisi operativa: monitorare le metriche della qualità dei dati, le metriche di qualità del modello e la deriva applicando Machine Learning ai dati di monitoraggio lakehouse.
Lakehouse vs Data Lake vs Data Warehouse
I data warehouse hanno basato decisioni di business intelligence (BI) per circa 30 anni, che si sono sviluppate come un set di linee guida di progettazione per i sistemi che controllano il flusso di dati. I data warehouse aziendali ottimizzano le query per i report bi, ma possono richiedere minuti o persino ore per generare i risultati. Progettato per i dati che probabilmente cambiano con una frequenza elevata, i data warehouse cercano di evitare conflitti tra query in esecuzione simultanea. Molti data warehouse si basano su formati proprietari, che spesso limitano il supporto per l'apprendimento automatico. Il data warehousing in Azure Databricks sfrutta le funzionalità di databricks lakehouse e Databricks SQL. Per altre informazioni, vedere Che cos'è il data warehousing in Azure Databricks?.
Grazie ai progressi tecnologici nell'archiviazione dei dati e in base all'aumento esponenziale dei tipi e del volume dei dati, i data lake sono entrati in uso nell'ultimo decennio. Data Lake archivia ed elabora i dati in modo economico ed efficiente. I data lake sono spesso definiti in opposizione ai data warehouse: un data warehouse fornisce dati puliti e strutturati per l'analisi bi, mentre un data lake archivia in modo permanente e economico i dati di qualsiasi natura in qualsiasi formato. Molte organizzazioni usano data lake per l'analisi scientifica dei dati e l'apprendimento automatico, ma non per la creazione di report bi a causa della sua natura non convalidata.
Data lakehouse combina i vantaggi dei data lake e dei data warehouse e offre:
- Accesso diretto e aperto ai dati archiviati in formati di dati standard.
- Protocolli di indicizzazione ottimizzati per l'apprendimento automatico e l'analisi scientifica dei dati.
- Bassa latenza delle query e affidabilità elevata per bi intelligence e analisi avanzata.
Combinando un livello di metadati ottimizzato con i dati convalidati archiviati in formati standard nell'archiviazione di oggetti cloud, data lakehouse consente ai data scientist e ai tecnici ml di creare modelli dagli stessi report bi basati sui dati.
Passaggio successivo
Per altre informazioni sui principi e sulle procedure consigliate per l'implementazione e l'esecuzione di un lakehouse con Databricks, vedere Introduzione al data lakehouse ben progettato