Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'API Lakebase Data è un'interfaccia RESTful compatibile con PostgREST che consente di interagire direttamente con il database Postgres di Lakebase usando metodi HTTP standard. Offre endpoint API derivati dallo schema del database, consentendo operazioni CRUD sicure (Create, Read, Update, Delete) sui dati senza la necessità di sviluppo back-end personalizzato.
Panoramica
L'API Dati genera automaticamente endpoint RESTful in base allo schema del database. Ogni tabella nel database diventa accessibile tramite richieste HTTP, consentendo di:
- Eseguire query sui dati usando richieste HTTP GET con filtraggio flessibile, ordinamento e paginazione
- Inserire record usando richieste HTTP POST
- Aggiornare i record usando le richieste HTTP PATCH o PUT
- Eliminare record usando richieste HTTP DELETE
- Eseguire funzioni come RPC tramite richieste HTTP POST
Questo approccio elimina la necessità di scrivere e gestire codice API personalizzato, consentendo di concentrarsi sulla logica dell'applicazione e sullo schema del database.
Compatibilità PostgREST
L'API Lakebase Data è compatibile con la specifica PostgREST . È possibile:
- Usare le librerie client e gli strumenti postgREST esistenti
- Seguire le convenzioni PostgREST per filtrare, ordinare e impaginazione
- Adatta la documentazione e gli esempi dalla comunità PostgREST
Annotazioni
L'API Lakebase Data è l'implementazione di Azure Databricks progettata per essere compatibile con la specifica PostgREST. Poiché l'API Dati è un'implementazione indipendente, alcune funzionalità postgREST non applicabili all'ambiente Lakebase non sono incluse. Per informazioni dettagliate sulla compatibilità delle funzionalità, vedere Informazioni di riferimento sulla compatibilità delle funzionalità.
Per informazioni dettagliate sulle funzionalità dell'API, sui parametri di query e sulle funzionalità, vedere le informazioni di riferimento sull'API PostgREST.
Casi d'uso
L'API Lakebase Data è ideale per:
- Applicazioni Web: creare front-end che interagiscono direttamente con il database tramite richieste HTTP
- Microservizi: creare servizi leggeri che accedono alle risorse del database tramite le API REST
- Architetture serverless: integrazione con funzioni serverless e piattaforme di elaborazione perimetrale
- Applicazioni per dispositivi mobili: fornire alle app per dispositivi mobili l'accesso diretto al database tramite un'interfaccia RESTful
- Integrazioni di terze parti: abilitare sistemi esterni per leggere e scrivere i dati in modo sicuro
Configurare l'API dati
Questa sezione illustra come configurare l'API Dati, dalla creazione dei ruoli necessari all'esecuzione della prima richiesta API.
Prerequisiti
L'API Dati richiede un progetto di database di scalabilità automatica di Lakebase Postgres. Se non ne hai uno, vedere Introduzione ai progetti di database.
Suggerimento
Se sono necessarie tabelle di esempio per testare l'API Dati, crearle prima di abilitare l'API Dati. Vedere Schema di esempio per uno schema di esempio completo.
Abilitare l'API dati
L'API Dati consente l'accesso a tutti i database tramite un singolo ruolo Postgres denominato authenticator, che non richiede autorizzazioni ad eccezione dell'accesso. Quando si abilita l'API Dati tramite l'app Lakebase, questo ruolo e l'infrastruttura necessaria vengono creati automaticamente.
Per abilitare l'API dati:
- Passare alla pagina API dati nel progetto.
- Fare clic su Abilita API dati.
In questo modo vengono eseguiti automaticamente tutti i passaggi di installazione, inclusa la creazione del authenticator ruolo, la configurazione dello pgrst schema e l'esposizione dello public schema tramite l'API.
Annotazioni
Se è necessario esporre schemi aggiuntivi (oltre public), è possibile modificare gli schemi esposti nelle impostazioni avanzate dell'API Dati.
Dopo aver abilitato l'API dati
Dopo aver abilitato l'API Dati, l'app Lakebase visualizza la pagina API dati con due schede: API e impostazioni.
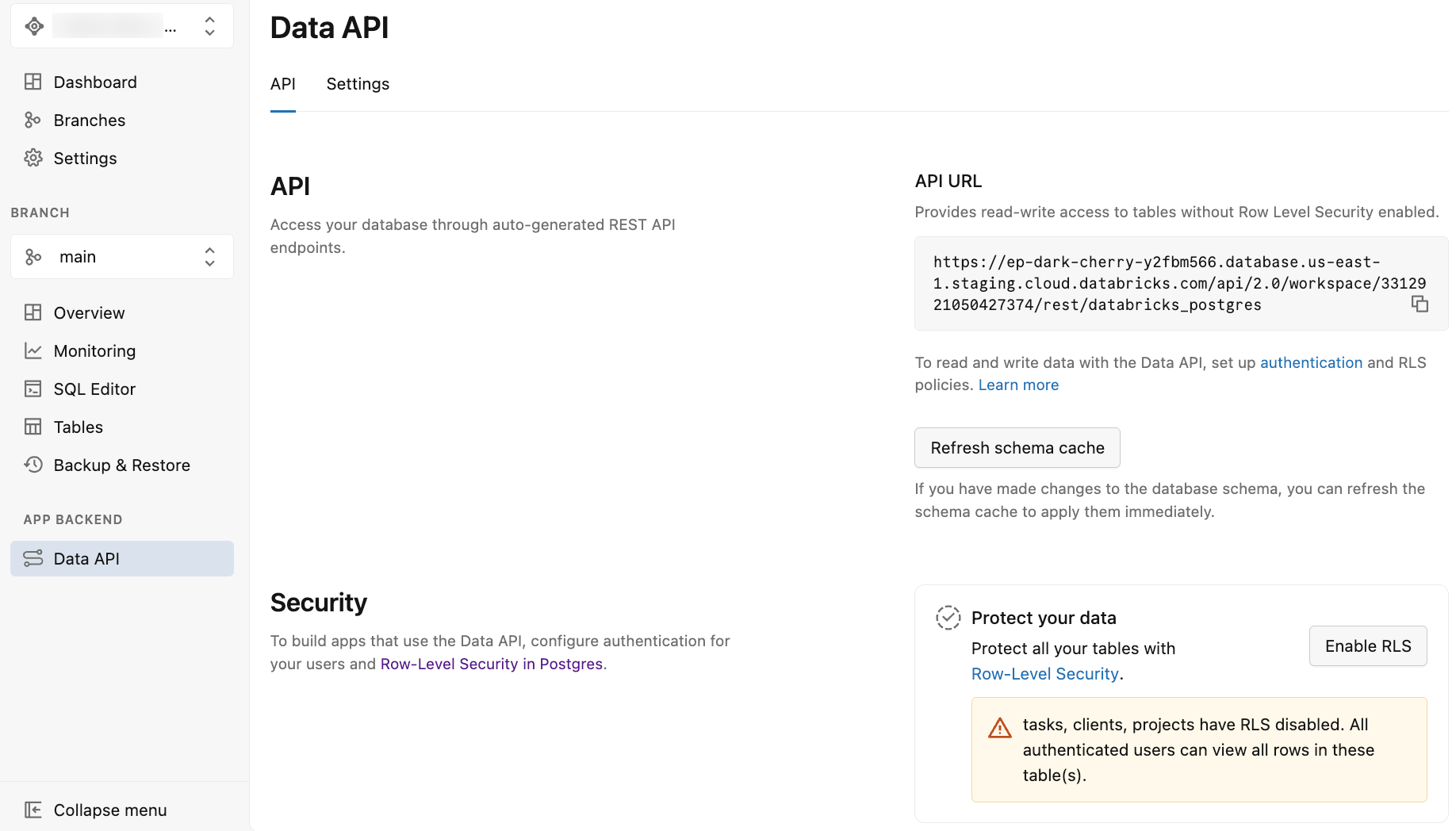
La scheda API fornisce:
-
URL API: URL dell'endpoint REST da usare nel codice dell'applicazione e nelle richieste API. L'URL visualizzato non include lo schema, quindi è necessario aggiungere il nome dello schema (ad esempio,
/public) all'URL durante l'esecuzione di richieste API. - Aggiorna cache dello schema: pulsante per aggiornare la cache dello schema dell'API dopo aver apportato modifiche allo schema del database. Vedere Aggiornare la cache dello schema.
- Proteggere i dati: opzioni per abilitare la sicurezza a livello di riga di Postgres per le tabelle. Vedere Abilitare la sicurezza a livello di riga.
La scheda Impostazioni offre opzioni per configurare il comportamento dell'API, ad esempio schemi esposti, righe massime, impostazioni CORS e altro ancora. Vedere Impostazioni avanzate dell'API dati.
Schema di esempio (facoltativo)
Gli esempi in questa documentazione usano lo schema seguente. È possibile creare tabelle personalizzate o usare questo schema di esempio per il test. Eseguire queste istruzioni SQL usando l'editor SQL di Lakebase o qualsiasi client SQL:
-- Create clients table
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
company TEXT,
phone TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create projects table with foreign key to clients
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
client_id INTEGER NOT NULL REFERENCES clients(id) ON DELETE CASCADE,
status TEXT DEFAULT 'active',
start_date DATE,
end_date DATE,
budget DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create tasks table with foreign key to projects
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT,
project_id INTEGER NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
status TEXT DEFAULT 'pending',
priority TEXT DEFAULT 'medium',
assigned_to TEXT,
due_date DATE,
estimated_hours DECIMAL(5,2),
actual_hours DECIMAL(5,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO clients (name, email, company, phone) VALUES
('Acme Corp', 'contact@acme.com', 'Acme Corporation', '+1-555-0101'),
('TechStart Inc', 'hello@techstart.com', 'TechStart Inc', '+1-555-0102'),
('Global Solutions', 'info@globalsolutions.com', 'Global Solutions Ltd', '+1-555-0103');
INSERT INTO projects (name, description, client_id, status, start_date, end_date, budget) VALUES
('Website Redesign', 'Complete overhaul of company website with modern design', 1, 'active', '2024-01-15', '2024-06-30', 25000.00),
('Mobile App Development', 'iOS and Android app for customer management', 1, 'planning', '2024-07-01', '2024-12-31', 50000.00),
('Database Migration', 'Migrate legacy system to cloud database', 2, 'active', '2024-02-01', '2024-05-31', 15000.00),
('API Integration', 'Integrate third-party services with existing platform', 3, 'completed', '2023-11-01', '2024-01-31', 20000.00);
INSERT INTO tasks (title, description, project_id, status, priority, assigned_to, due_date, estimated_hours, actual_hours) VALUES
('Design Homepage', 'Create wireframes and mockups for homepage', 1, 'in_progress', 'high', 'Sarah Johnson', '2024-03-15', 16.00, 8.00),
('Setup Development Environment', 'Configure local development setup', 1, 'completed', 'medium', 'Mike Chen', '2024-02-01', 4.00, 3.50),
('Database Schema Design', 'Design new database structure', 3, 'completed', 'high', 'Alex Rodriguez', '2024-02-15', 20.00, 18.00),
('API Authentication', 'Implement OAuth2 authentication flow', 4, 'completed', 'high', 'Lisa Wang', '2024-01-15', 12.00, 10.50),
('User Testing', 'Conduct usability testing with target users', 1, 'pending', 'medium', 'Sarah Johnson', '2024-04-01', 8.00, NULL),
('Performance Optimization', 'Optimize database queries and caching', 3, 'in_progress', 'medium', 'Alex Rodriguez', '2024-04-30', 24.00, 12.00);
Configurare le autorizzazioni utente
È necessario autenticare tutte le richieste api dati usando Azure Databricks token di connessione OAuth, che vengono inviati tramite l'intestazione Authorization. L'API Dati limita l'accesso alle identità Azure Databricks autenticate, con Postgres che controlla le autorizzazioni sottostanti.
Il authenticator ruolo presuppone l'identità dell'utente richiedente durante l'elaborazione delle richieste API. A tale scopo, ogni identità Azure Databricks che accede all'API dati deve avere un ruolo Postgres corrispondente nel database. Se è prima necessario aggiungere utenti all'account Azure Databricks, vedere Aggiungi utenti all'account.
Aggiungere ruoli Postgres
Importante
Non usare l'account proprietario del database (l'identità Azure Databricks che ha creato il progetto Lakebase) per accedere all'API Dati. Il authenticator ruolo richiede la possibilità di assumere il ruolo e tale autorizzazione non può essere concessa per gli account con privilegi elevati. Usare invece un service principal (opzione consigliata) o un altro account utente di Azure Databricks.
Se si tenta di usare l'account proprietario del database, viene visualizzato questo errore quando si concede il ruolo a authenticator:
ERROR: permission denied to grant role "db_owner_user@databricks.com"
DETAIL: Only roles with the ADMIN option on role "db_owner_user@databricks.com" may grant this role.
Creare un ruolo Postgres per ogni identità Azure Databricks che richiede l'accesso all'API dati:
INTERFACCIA UTENTE
- Nella scheda Ruoli e database>Aggiungi ruolo>OAuth selezionare l'utente, l'entità servizio o il gruppo a cui concedere l'accesso al database.
- Dopo aver creato il ruolo, passare a Concedi autorizzazioni agli utenti.
SQL
Creare l'estensione
databricks_auth. Ogni database Postgres deve avere una propria estensione.CREATE EXTENSION IF NOT EXISTS databricks_auth;Usare
databricks_create_roleper aggiungere un ruolo Postgres per l'identità Azure Databricks:Per un utente:
SELECT databricks_create_role('user@databricks.com', 'USER');Per un principale del servizio, usare l'ID dell'applicazione (UUID) come nome dell'identità. Trovarlo nell'area di lavoro Azure Databricks in Impostazioni > Identità e accesso > Entità del servizio:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');
PYTHON SDK
Impostare identity_type su USER, SERVICE_PRINCIPAL o GROUP. Impostare postgres_role rispettivamente sull'indirizzo email dell'identità, sull'ID dell'applicazione (UUID) o sul nome visualizzato del gruppo. Questo valore diventa il nome del ruolo Postgres usato nelle GRANT istruzioni.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleIdentityType, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
identity_type=RoleIdentityType.USER,
postgres_role="user@example.com"
)
)
)
role = operation.wait()
curva
Impostare identity_type su USER, SERVICE_PRINCIPAL o GROUP. Impostare postgres_role rispettivamente sull'indirizzo email dell'identità, sull'ID dell'applicazione (UUID) o sul nome visualizzato del gruppo.
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"identity_type": "USER",
"postgres_role": "user@example.com"
}
}' | jq
Concedere autorizzazioni agli utenti
Dopo aver creato i ruoli Postgres corrispondenti per le identità Azure Databricks, è necessario concedere le autorizzazioni a tali ruoli Postgres. Queste autorizzazioni controllano gli oggetti di database (schemi, tabelle, sequenze, funzioni) con cui ogni utente può interagire tramite richieste API.
Concedere le autorizzazioni usando istruzioni SQL GRANT standard. In questo esempio viene usato lo public schema. Se si espone uno schema diverso, sostituire public con il nome dello schema:
-- Allow authenticator to assume the identity of the user
GRANT "user@databricks.com" TO authenticator;
-- Allow user@databricks.com to access everything in public schema
GRANT USAGE ON SCHEMA public TO "user@databricks.com";
GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO "user@databricks.com";
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO "user@databricks.com";
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO "user@databricks.com";
In questo esempio viene concesso l'accesso completo allo schema public per l'identità user@databricks.com. Sostituire questa opzione con l'identità Azure Databricks effettiva e modificare le autorizzazioni in base ai requisiti. Per le entità servizio, usare l'ID dell'applicazione (UUID) come nome del ruolo Postgres nelle istruzioni GRANT anziché come indirizzo di posta elettronica.
Importante
Implementare la sicurezza a livello di riga: le autorizzazioni precedenti concedono l'accesso a livello di tabella, ma la maggior parte dei casi d'uso dell'API richiede restrizioni a livello di riga. Ad esempio, nelle applicazioni multi-tenant, gli utenti devono visualizzare solo i propri dati o i dati dell'organizzazione. Usare i criteri di sicurezza a livello di riga (RLS) di PostgreSQL per applicare il controllo di accesso con granularità fine a livello di database. Vedere Implementare la sicurezza a livello di riga.
Autenticazione
Per accedere all'API Dati, è necessario fornire un token OAuth Azure Databricks nell'intestazione Authorization della richiesta HTTP. L'identità Azure Databricks autenticata deve avere un ruolo Postgres corrispondente (creato nei passaggi precedenti) che ne definisce le autorizzazioni di database.
Ottenere un token OAuth
Connettiti alla workspace come l'identità di Azure Databricks per la quale hai creato un ruolo Postgres nei passaggi precedenti e ottieni un token OAuth. Per istruzioni, vedere Autenticazione .
Effettuare una richiesta
Con il token OAuth e l'URL dell'API (disponibile nella scheda API nell'app Lakebase), è possibile effettuare richieste API usando curl o qualsiasi client HTTP. Ricordarsi di aggiungere il nome dello schema ( ad esempio , /public) all'URL dell'API. Gli esempi seguenti presuppongono che siano state esportate le DBX_OAUTH_TOKEN variabili di ambiente e REST_ENDPOINT .
Di seguito è riportato un esempio di chiamata con l'output previsto (usando lo schema client/progetti/attività di esempio):
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Risposta di esempio:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Per altri esempi e informazioni dettagliate sulle operazioni API, vedere la sezione informazioni di riferimento sulle API . Per informazioni dettagliate sui parametri di query e sulle funzionalità api, vedere le informazioni di riferimento sull'API PostgREST. Per informazioni sulla compatibilità specifiche di Lakebase, vedere Compatibilità postgREST.
Prima di usare ampiamente l'API, configurare la sicurezza a livello di riga per proteggere i dati.
Gestire l'API dati
Dopo aver abilitato l'API Dati, è possibile gestire le modifiche dello schema e le impostazioni di sicurezza tramite l'app Lakebase.
Aggiornare la cache dello schema
Quando si apportano modifiche allo schema del database (aggiunta di tabelle, colonne o altri oggetti dello schema), è necessario aggiornare la cache dello schema. In questo modo le modifiche vengono immediatamente disponibili tramite l'API Dati.
Per aggiornare la cache dello schema:
- Vai a Data API nella sezione Backend dell'app del progetto.
- Fare clic su Aggiorna cache dello schema.
L'API Dati riflette ora le modifiche dello schema più recenti.
Abilitare la sicurezza a livello di riga
L'app Lakebase offre un modo rapido per abilitare la sicurezza a livello di riga per le tabelle nel database. Quando sono presenti tabelle nello schema, nella scheda API viene visualizzata una sezione Proteggi i dati che mostra:
- Tabelle con sicurezza a livello di riga abilitate
- Tabelle con la sicurezza a livello di riga (RLS) disabilitata (con avvisi)
- Pulsante Abilita RLS per abilitare RLS per tutte le tabelle
Importante
L'abilitazione di RLS tramite l'app Lakebase attiva la sicurezza a livello di riga per le tabelle. Quando la sicurezza a livello di riga è abilitata, tutte le righe diventano inaccessibili agli utenti per impostazione predefinita (ad eccezione dei proprietari delle tabelle, dei ruoli con l'attributo BYPASSRLS e degli utenti con privilegi avanzati, anche se gli utenti con privilegi avanzati non sono supportati in Lakebase). È necessario creare criteri RLS (sicurezza a livello di riga) per concedere l'accesso a righe specifiche in base ai requisiti di sicurezza. Per informazioni sulla creazione di criteri, vedere Sicurezza a livello di riga .
Per abilitare la Row-Level Security (RLS) per le tabelle:
- Vai a Data API nella sezione Backend dell'app del progetto.
- Nella sezione Proteggi i dati esaminare le tabelle in cui RLS non è abilitato.
- Fare clic su Abilita RLS per abilitare la sicurezza a livello di riga per tutte le tabelle.
È anche possibile abilitare RLS (sicurezza a livello di riga) per singole tabelle usando SQL. Per informazioni dettagliate, vedere Sicurezza a livello di riga .
Impostazioni avanzate dell'API dati
La sezione Impostazioni avanzate nella scheda API nell'app Lakebase controlla la sicurezza, le prestazioni e il comportamento dell'endpoint dell'API dati.
Schemi esposti
Predefinito:public
Definiscono gli schemi PostgreSQL esposti come endpoint dell'API REST. Per impostazione predefinita, solo lo public schema è accessibile. Se utilizzi altri schemi (ad esempio, api, v1), selezionali dall'elenco a tendina per aggiungerli.
Annotazioni
Le autorizzazioni si applicano: L'aggiunta di uno schema espone gli endpoint, ma il ruolo del database usato dall'API deve comunque disporre USAGE dei privilegi per lo schema e SELECT i privilegi per le tabelle.
Numero massimo di righe
Default: Nessun contenuto
Applica un limite rigido al numero di righe da restituire in una singola risposta API. Ciò impedisce una riduzione accidentale delle prestazioni da query di grandi dimensioni. I client devono usare limiti di impaginazione per recuperare i dati entro questa soglia. Ciò impedisce anche costi in uscita imprevisti da trasferimenti di dati di grandi dimensioni.
Origini consentite di CORS
Predefinito: Vuoto (consente tutte le origini)
Controlla quali domini Web possono recuperare dati dall'API usando un browser.
-
Vuoto: Consente
*(qualsiasi dominio). Utile per lo sviluppo. -
Produzione: Elencare i domini specifici ( ad esempio ,
https://myapp.com) per impedire che siti Web non autorizzati eseseguono query nell'API.
Specifica OpenAPI
Default: Disattivato
Controlla se uno schema OpenAPI 3 generato automaticamente è disponibile in /openapi.json. Questo schema descrive le tabelle, le colonne e gli endpoint REST. Se abilitata, è possibile usarla per:
- Generare la documentazione dell'API (interfaccia utente di Swagger, Redoc)
- Compilare librerie client tipate (TypeScript, Python, Go)
- Importare l'API in Postman
- Eseguire l'integrazione con gateway API e altri strumenti basati su OpenAPI
Intestazioni dei tempi del server
Default: Disattivato
Se abilitata, l'API Dati include Server-Timing intestazioni in ogni risposta. Queste intestazioni mostrano quanto tempo ha impiegato l'elaborazione di diverse parti della richiesta, come ad esempio il tempo di esecuzione del database e il tempo di elaborazione interno. È possibile usare queste informazioni per eseguire il debug di query lente, misurare le prestazioni e risolvere i problemi di latenza nell'applicazione.
Annotazioni
Dopo aver apportato modifiche alle impostazioni avanzate, fare clic su Salva per applicarle.
Sicurezza a livello di riga
I criteri di sicurezza a livello di riga forniscono un controllo di accesso con granularità fine limitando le righe a cui gli utenti possono accedere in una tabella.
Funzionamento di RLS con l'API Dati: Quando un utente effettua una richiesta API, il authenticator ruolo assumerà l'identità di quell'utente. Tutti i criteri RLS definiti per il ruolo dell'utente vengono applicati automaticamente da PostgreSQL, filtrando i dati a cui l'utente può accedere. Ciò si verifica a livello di database, quindi anche se il codice dell'applicazione tenta di eseguire query su tutte le righe, il database restituisce solo le righe che l'utente può visualizzare. In questo modo si garantisce una sicurezza avanzata senza richiedere la logica di filtro nel codice dell'applicazione.
Perché la sicurezza a livello di riga è fondamentale per le API: a differenza di una connessione diretta al database in cui si ha il controllo sul contesto di connessione, le API HTTP espongono il database a più utenti tramite un unico endpoint. Le autorizzazioni a livello di tabella indicano che se un utente può accedere alla clients tabella, può accedere a tutti i record client, a meno che non si implementi il filtro. I criteri di sicurezza a livello di riga assicurano che ogni utente visualizzi automaticamente solo i dati autorizzati.
RLS (La sicurezza a livello di riga) è essenziale per:
- Applicazioni multi-tenant: isolare i dati tra clienti o organizzazioni diversi
- Dati di proprietà dell'utente: assicurarsi che gli utenti accevano solo ai propri record
- Accesso basato sul team: limitare la visibilità ai membri del team o a gruppi specifici
- Requisiti di conformità: applicare restrizioni di accesso ai dati a livello di database
RLS e viste: i criteri RLS vengono applicati a livello di tabella. Non è possibile definire un criterio RLS direttamente in una vista. Per impostazione predefinita, quando un utente interroga una vista, Postgres valuta i criteri RLS rispetto al proprietario della vista, non rispetto all'utente che la interroga. Ciò significa che, se il proprietario della vista è il proprietario della tabella o un superutente, la RLS sulla tabella sottostante viene di fatto aggirata per chiunque possa SELECT sulla vista.
Per applicare i criteri RLS nei confronti dell'utente che esegue effettivamente la query, creare la vista con security_invoker = true:
CREATE VIEW my_view WITH (security_invoker = true) AS
SELECT * FROM clients;
In alternativa, aggiornare una visualizzazione esistente:
ALTER VIEW my_view SET (security_invoker = true);
In alternativa, usa FORCE ROW LEVEL SECURITY sulla tabella di base in modo che RLS si applichi anche al proprietario della tabella:
ALTER TABLE clients FORCE ROW LEVEL SECURITY;
Per limitare l'accesso alla vista stessa (stabilendo chi può interrogarla), usa le autorizzazioni dei ruoli di Postgres (GRANT/REVOKE) anziché i criteri RLS.
Abilitare RLS (sicurezza a livello di riga)
È possibile abilitare RLS (sicurezza a livello di riga) tramite l'app Lakebase o usando istruzioni SQL. Per istruzioni sull'uso dell'app Lakebase, vedere Abilitare la sicurezza a livello di riga.
Avvertimento
Se hai tabelle senza RLS abilitato, nella scheda API nell'app Lakebase compare un avviso che gli utenti autenticati possono visualizzare tutte le righe di quelle tabelle. L'API Dati interagisce direttamente con lo schema Postgres e, poiché l'API è accessibile tramite Internet, è fondamentale applicare la sicurezza a livello di database usando la sicurezza a livello di riga di PostgreSQL.
Per abilitare la sicurezza a livello di riga usando SQL, eseguire il comando seguente:
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Creare criteri di sicurezza a livello di riga
Dopo aver abilitato la sicurezza a livello di riga in una tabella, è necessario creare politiche che definiscono le regole di accesso. Senza criteri, gli utenti non possono accedere ad alcuna riga (tutte le righe sono nascoste per impostazione predefinita).
Funzionamento dei criteri: Quando la Row-Level Security (RLS) è abilitata su una tabella, gli utenti possono visualizzare solo le righe che corrispondono ad almeno un criterio. Tutte le altre righe vengono filtrate. I proprietari delle tabelle, i ruoli con l'attributo BYPASSRLS e gli utenti con privilegi avanzati possono ignorare il sistema di sicurezza delle righe (anche se gli utenti con privilegi avanzati non sono supportati in Lakebase).
Annotazioni
In Lakebase restituisce current_user l'indirizzo di posta elettronica dell'utente autenticato, ad esempio user@databricks.com. Utilizzalo nei criteri RLS per identificare quale utente sta effettuando la richiesta.
Sintassi dei criteri di base:
CREATE POLICY policy_name ON table_name
[TO role_name]
USING (condition);
- policy_name: nome descrittivo per il criterio
- table_name: tabella a cui applicare i criteri
- TO role_name: facoltativo. Specifica il ruolo per questa politica. Omettere questa clausola per applicare il criterio a tutti i ruoli.
- USING (condizione):condizione che determina quali righe sono visibili
Esercitazione RLS
L'esercitazione seguente usa lo schema di esempio di questa documentazione (client, progetti, tabelle delle attività) per illustrare come implementare la sicurezza a livello di riga.
Scenario: si hanno più utenti che devono visualizzare solo i client assegnati e i progetti correlati. Limitare l'accesso in modo che:
-
alice@databricks.compuò visualizzare solo i client con ID 1 e 2 -
bob@databricks.compuò visualizzare solo i client con ID 2 e 3
Passaggio 1: Abilitare RLS nella tabella dei clienti
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Passaggio 2: Creare un criterio per Alice
CREATE POLICY alice_clients ON clients
TO "alice@databricks.com"
USING (id IN (1, 2));
Passaggio 3: Creare un criterio per Bob
CREATE POLICY bob_clients ON clients
TO "bob@databricks.com"
USING (id IN (2, 3));
Passaggio 4: Testare i criteri
Quando Alice effettua una richiesta API:
# Alice's token in the Authorization header
curl -H "Authorization: Bearer $ALICE_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Risposta (Alice vede solo i clienti 1 e 2):
[
{ "id": 1, "name": "Acme Corp" },
{ "id": 2, "name": "TechStart Inc" }
]
Quando Bob effettua una richiesta API:
# Bob's token in the Authorization header
curl -H "Authorization: Bearer $BOB_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Risposta (Bob vede solo i clienti 2 e 3):
[
{ "id": 2, "name": "TechStart Inc" },
{ "id": 3, "name": "Global Solutions" }
]
Modelli comuni di RLS
Questi modelli coprono i requisiti di sicurezza tipici per l'API Dati:
Proprietà utente : limita le righe all'utente autenticato:
CREATE POLICY user_owned_data ON tasks
USING (assigned_to = current_user);
Isolamento del tenant - vincola le righe all'organizzazione dell'utente
CREATE POLICY tenant_data ON clients
USING (tenant_id = (
SELECT tenant_id
FROM user_tenants
WHERE user_email = current_user
));
Appartenenza al team : limita le righe ai team dell'utente:
CREATE POLICY team_projects ON projects
USING (client_id IN (
SELECT client_id
FROM team_clients
WHERE team_id IN (
SELECT team_id
FROM user_teams
WHERE user_email = current_user
)
));
Accesso in base al ruolo : limita le righe in base all'appartenenza al ruolo:
CREATE POLICY manager_access ON tasks
USING (
status = 'pending' OR
pg_has_role(current_user, 'managers', 'member')
);
Sola lettura per ruoli specifici : criteri diversi per operazioni diverse:
-- Allow all users to read their assigned tasks
CREATE POLICY read_assigned_tasks ON tasks
FOR SELECT
USING (assigned_to = current_user);
-- Only managers can update tasks
CREATE POLICY update_tasks ON tasks
FOR UPDATE
TO "managers"
USING (true);
Risorse aggiuntive
Per informazioni complete sull'implementazione della sicurezza a livello di riga, inclusi i tipi di criteri, le procedure consigliate per la sicurezza e i modelli avanzati, vedere la documentazione relativa ai criteri di sicurezza delle righe postgreSQL.
Per altre informazioni sulle autorizzazioni, vedere Gestire le autorizzazioni.
Informazioni di riferimento sulle API
Questa sezione presuppone che siano stati completati i passaggi di installazione, le autorizzazioni configurate e la sicurezza a livello di riga implementata. Le sezioni seguenti forniscono informazioni di riferimento per l'uso dell'API Dati, incluse operazioni comuni, funzionalità avanzate, considerazioni sulla sicurezza e dettagli sulla compatibilità.
Operazioni di base
Registri di interrogazione
Recuperare i record da una tabella usando HTTP GET:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients"
Risposta di esempio:
[
{ "id": 1, "name": "Acme Corp", "email": "contact@acme.com", "company": "Acme Corporation", "phone": "+1-555-0101" },
{
"id": 2,
"name": "TechStart Inc",
"email": "hello@techstart.com",
"company": "TechStart Inc",
"phone": "+1-555-0102"
}
]
Filtrare i risultati
Usare i parametri di query per filtrare i risultati. In questo esempio vengono recuperati i client con id valori maggiori o uguali a 2:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=gte.2"
Risposta di esempio:
[
{ "id": 2, "name": "TechStart Inc", "email": "hello@techstart.com" },
{ "id": 3, "name": "Global Solutions", "email": "info@globalsolutions.com" }
]
Selezionare colonne specifiche e unire le tabelle
Usare il select parametro per recuperare colonne specifiche e unire tabelle correlate:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Risposta di esempio:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Inserire record
Creare nuovi record usando HTTP POST:
curl -X POST \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "New Client",
"email": "newclient@example.com",
"company": "New Company Inc",
"phone": "+1-555-0104"
}' \
"$REST_ENDPOINT/public/clients"
Aggiorna record
Aggiornare i record esistenti usando HTTP PATCH:
curl -X PATCH \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{"phone": "+1-555-0199"}' \
"$REST_ENDPOINT/public/clients?id=eq.1"
Eliminazione di record
Eliminare record tramite HTTP DELETE:
curl -X DELETE \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=eq.5"
Funzionalità avanzate
Impaginazione
Controllare il numero di record restituiti usando i limit parametri e offset :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?limit=10&offset=0"
Ordinamento
Ordinare i risultati usando il order parametro :
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?order=due_date.desc"
Filtro complesso
Combinare più condizioni di filtro:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?status=eq.in_progress&priority=eq.high"
Operatori di filtro comuni:
-
eq- uguale -
gte- maggiore o uguale a -
lte- minore o uguale -
neq- non uguale -
like- corrispondenza di modelli -
in- corrisponde a qualsiasi valore nell'elenco
Per altre informazioni sui parametri di query e sulle funzionalità api supportate, vedere le informazioni di riferimento sull'API PostgREST. Per informazioni sulla compatibilità specifiche di Lakebase, vedere Compatibilità postgREST.
Informazioni di riferimento sulla compatibilità delle funzionalità
L'API Lakebase Data è completamente compatibile con la specifica PostgREST, tra cui incorporamento delle risorse (chiave esterna e relazioni calcolate, hint di join interno/sinistro), formati di risposta (JSON, CSV, GeoJSON, tipi di supporti personalizzati), filtro, impaginazione, modalità di conteggio (exact, planned, estimated), preferenze di richiesta (handling, timezone, ), txesposizione del piano di query e funzionalità RPC.
Le funzionalità PostgREST seguenti non sono applicabili o non sono disponibili nell'ambiente Lakebase:
Autenticazione
| Caratteristica / Funzionalità | stato | Dettagli |
|---|---|---|
| Configurazione JWT | Non applicabile | L'API Lakebase Data usa Azure Databricks token OAuth anziché l'autenticazione JWT. Le opzioni di configurazione specifiche di JWT (segreti personalizzati, chiavi RS256, convalida del gruppo di destinatari) non sono disponibili. |
Configurazione avanzata
| Caratteristica / Funzionalità | stato | Dettagli |
|---|---|---|
| Impostazioni dell'applicazione (GUC) | Non supportato | Il passaggio di valori di configurazione personalizzati alle funzioni di database tramite guC PostgreSQL non è supportato. |
| Funzione di pre-richiesta | Non supportato | Configurazione db-pre-request che consente di specificare una funzione di database da eseguire prima che ogni richiesta non sia supportata. |
Observability
| Caratteristica / Funzionalità | stato | Dettagli |
|---|---|---|
| Propagazione dell'intestazione di traccia | Non applicabile | Lakebase implementa le proprie funzionalità di osservabilità invece di quelle di PostgREST: l'X-Request-Id e la propagazione dell'intestazione di traccia personalizzata. |
Per altre informazioni sulle funzionalità postgREST, vedere la documentazione di PostgREST.
Considerazioni sulla sicurezza
L'API Dati applica il modello di sicurezza del database a più livelli:
- Autenticazione: tutte le richieste richiedono l'autenticazione del token OAuth valida
- Accesso in base al ruolo: le autorizzazioni a livello di database controllano le tabelle e le operazioni a cui gli utenti possono accedere
- Sicurezza a livello di riga: i criteri di sicurezza a livello di riga applicano il controllo di accesso con granularità fine, limitando quali righe specifiche gli utenti possono visualizzare o modificare
- Contesto utente: l'API presuppone l'identità dell'utente autenticato, assicurando che le autorizzazioni e i criteri del database vengano applicati correttamente
Procedure di sicurezza consigliate
Per le distribuzioni di produzione:
- Implementare la sicurezza a livello di riga: usare i criteri di sicurezza a livello di riga per limitare l'accesso ai dati a livello di riga. Ciò è particolarmente importante per le applicazioni multi-tenant e i dati di proprietà dell'utente. Consultare Sicurezza a livello di riga.
-
Concedere autorizzazioni minime: concedere solo agli utenti le autorizzazioni necessarie (
SELECT,INSERT,UPDATE,DELETE) in tabelle specifiche anziché concedere l'accesso generale. - Usare ruoli separati per applicazione: creare ruoli dedicati per applicazioni o servizi diversi anziché condividere un singolo ruolo.
- Controllare regolarmente l'accesso: esaminare periodicamente le autorizzazioni concesse e le politiche RLS per assicurarsi che corrispondano ai requisiti di sicurezza.
Per informazioni sulla gestione di ruoli e autorizzazioni, vedere: