Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa esercitazione illustra come usare lo streaming strutturato di Apache Spark per leggere e scrivere dati con Apache Kafka in Azure HDInsight.
Spark Structured Streaming è un motore di elaborazione del flusso basato su Spark SQL. Consente di esprimere i calcoli di streaming come il calcolo di batch in dati statici.
In questa esercitazione apprenderai a:
- Usare un modello di Azure Resource Manager per creare i cluster
- Usare Spark Structured Streaming con Kafka
Al termine della procedura descritta in questo documento, eliminare i cluster per evitare costi supplementari.
Prerequisiti
jq, un processore JSON da riga di comando. Vedere https://stedolan.github.io/jq/.
Familiarità nell'uso di Jupyter Notebook con Spark in HDInsight. Per altre informazioni, vedere il documento Esercitazione: Caricare i dati ed eseguire query in un cluster Apache Spark in Azure HDInsight.
Familiarità con il linguaggio di programmazione Scala. Il codice usato in questa esercitazione è scritto in Scala.
Familiarità con la creazione di argomenti Kafka. Per altre informazioni, vedere il documento Creare un cluster Apache Kafka in HDInsight.
Importante
La procedura descritta in questo documento richiede che venga creato un gruppo di risorse di Azure che contenga sia un cluster Spark in HDInsight che un cluster Kafka in HDInsight. Entrambi questi cluster si trovano all'interno di una rete virtuale di Azure, che consente al cluster Spark di comunicare direttamente con il cluster Kafka.
Per comodità, questo documento si collega a un modello in grado di creare tutte le risorse di Azure necessarie.
Per altre informazioni sull'uso di HDInsight in una rete virtuale, vedere il documento Pianificare una rete virtuale per HDInsight.
Streaming strutturato con Apache Kafka
Lo streaming strutturato Spark è un motore di elaborazione del flusso basato sul motore SQL di Spark. Quando si usa lo streaming strutturato, è possibile scrivere query di streaming nello stesso modo in cui si scrivono le query batch.
I frammenti di codice seguenti illustrano la lettura da Kafka e l'archiviazione in file. La prima è un'operazione batch, mentre la seconda è un'operazione di flusso:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
In entrambi i frammenti di codice, i dati vengono letti da Kafka e scritti nel file. Le differenze tra gli esempi sono:
| Batch | Streaming |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
L'operazione di streaming usa anche awaitTermination(30000), che arresta il flusso dopo 30.000 ms.
Per usare lo streaming strutturato con Kafka, il progetto deve avere una dipendenza sul pacchetto org.apache.spark : spark-sql-kafka-0-10_2.11. La versione di questo pacchetto deve corrispondere alla versione di Spark in HDInsight. Per Spark 2.4 (disponibile in HDInsight 4.0), è possibile trovare le informazioni sulle dipendenze per i diversi tipi di progetto in https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Per Jupyter Notebook usato con questa esercitazione, la cella seguente carica questa dipendenza dal pacchetto:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Creare i cluster
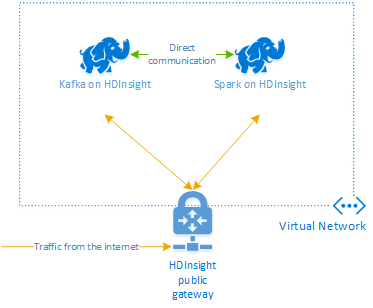
Apache Kafka in HDInsight non fornisce l'accesso ai broker Kafka tramite Internet pubblico. Qualunque elemento che usa Kafka deve trovarsi nella stessa rete virtuale di Azure. In questa esercitazione i cluster Kafka e Spark si trovano nella stessa rete virtuale di Azure.
Il diagramma seguente illustra il flusso delle comunicazioni tra Spark e Kafka:
Nota
Il servizio Kafka è limitato alle comunicazioni all'interno della rete virtuale. Altri servizi nel cluster, ad esempio SSH e Ambari, sono accessibili tramite Internet. Per altre informazioni sulle porte pubbliche disponibili con HDInsight, vedere Porte e URI usati da HDInsight.
Per creare una Rete virtuale di Microsoft Azure e quindi crearvi i cluster Kafka e Spark, seguire questa procedura:
Usare il pulsante seguente per accedere ad Azure e aprire il modello nel portale di Azure.

Il modello di Azure Resource Manager è disponibile in https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Questo modello crea le risorse seguenti:
Un cluster Kafka in HDInsight 4.0 o 5.0.
Un cluster Spark 2.4 o 3.1 in HDInsight 4.0 o 5.0.
Una rete virtuale Azure contenente i cluster HDInsight.
Importante
Il notebook di streaming strutturato usato in questa esercitazione richiede Spark 2.4 o 3.1 in HDInsight 4.0 o 5.0. Se si usa una versione precedente di Spark in HDInsight, si ricevono errori durante l'uso del notebook.
Usare le informazioni seguenti per popolare le voci nella sezione Modello personalizzato:
Impostazione Valore Subscription la propria sottoscrizione di Azure Gruppo di risorse Gruppo di risorse che contiene le risorse. Ufficio Area di Azure in cui vengono create le risorse. Nome del cluster Spark Nome del cluster Spark. I primi sei caratteri devono essere diversi dal nome di cluster Kafka. Nome del cluster Kafka Nome del cluster Kafka. I primi sei caratteri devono essere diversi dal nome di cluster Spark. Nome utente dell'account di accesso del cluster Nome utente dell'amministratore per i cluster. Password di accesso al cluster Password dell'utente amministratore per i cluster. Nome utente SSH Utente SSH da creare per i cluster. Password SSH Password per l'utente SSH. 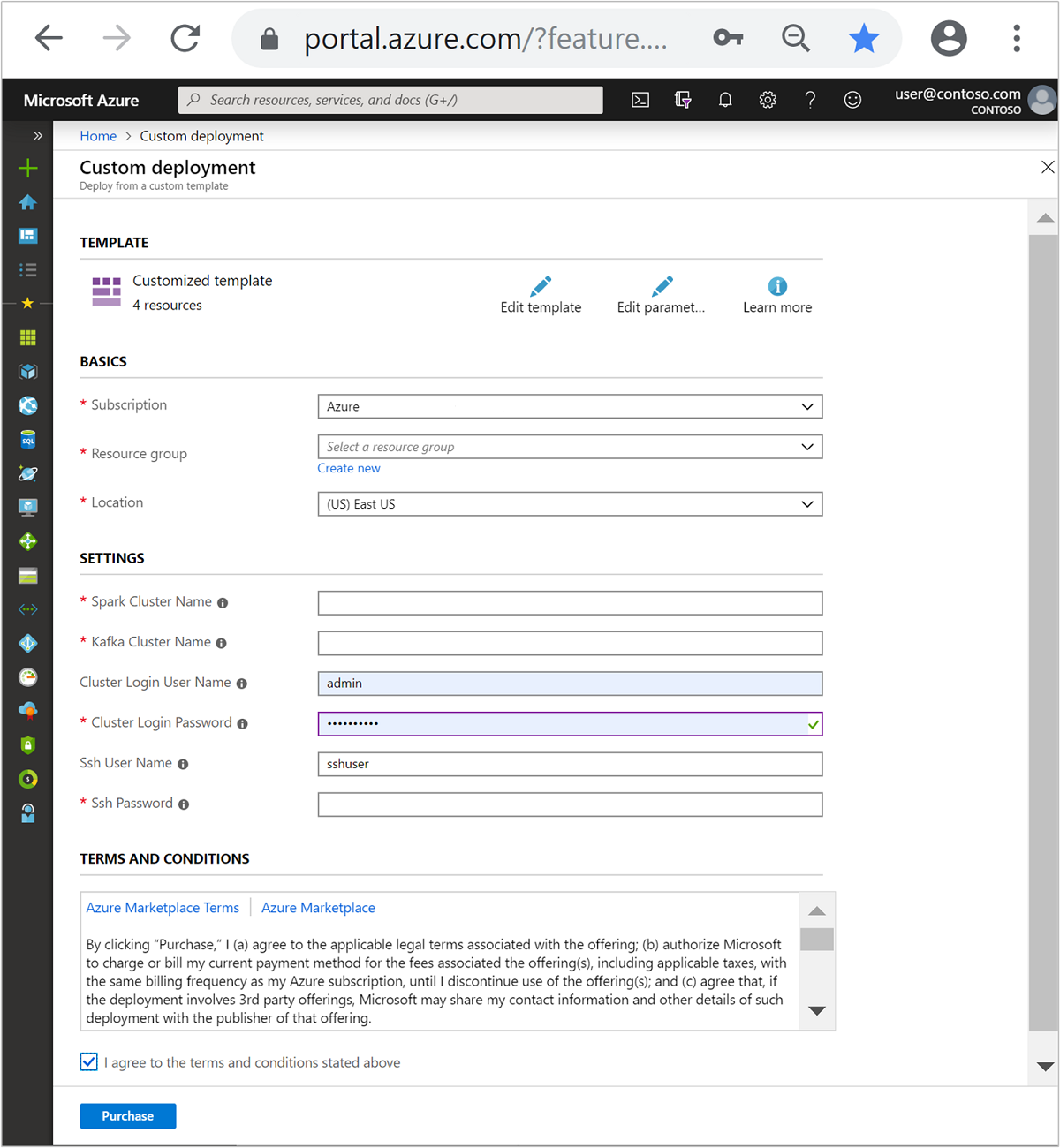
Leggere le Condizioni e quindi selezionare Accetto le condizioni riportate sopra.
Selezionare Acquista.
Nota
La creazione dei cluster può richiedere fino a 20 minuti.
Usare Spark Structured Streaming
Questo esempio illustra come usare Spark Structured Streaming con Kafka in HDInsight. Usa i dati relativi alle corse dei taxi, forniti dalla città di New York. Il set di dati usato da questo notebook è ricavato dalla pagina 2016 Green Taxi Trip Data (Dati sulle corse dei taxi verdi del 2016).
Raccogliere le informazioni sull'host. Usare i comandi curl e jq indicati sotto per ottenere le informazioni sugli host ZooKeeper e broker di Kafka. I comandi sono progettati per un prompt dei comandi di Windows. Per gli altri ambienti saranno necessarie piccole variazioni. Sostituire
KafkaClustercon il nome utente del cluster Kafka eKafkaPasswordcon la password di accesso al cluster. Sostituire ancheC:\HDI\jq-win64.execon il percorso effettivo dell'installazione jq. Immettere i comandi in un prompt dei comandi di Windows e salvare l'output per i passaggi successivi.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"In un Web browser passare a
https://CLUSTERNAME.azurehdinsight.net/jupyterdoveCLUSTERNAMEè il nome del cluster. Quando richiesto, immettere l'account di accesso (amministratore) e la password usati durante la creazione del cluster.Selezionare Nuovo > Spark per creare un notebook.
Lo streaming Spark prevede il microbatching, di conseguenza i dati vengono ricevuti sotto forma di batch e gli executor vengono eseguiti sui batch di dati. Se il timeout di inattività degli executor è minore del tempo necessario per elaborare il batch, gli executor vengono aggiunti e rimossi costantemente. Se il timeout di inattività degli executor è maggiore della durata del batch, l'esecutore non viene mai rimosso. Di conseguenza è consigliabile disabilitare l'allocazione dinamica impostando spark.dynamicAllocation.enabled su false durante l'esecuzione di applicazioni di streaming.
Caricare i pacchetti usati dal notebook immettendo le informazioni seguenti in una cella del notebook. Eseguire il comando usando CTRL + INVIO.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Creare l'argomento Kafka. Modificare il comando seguente sostituendo
YOUR_ZOOKEEPER_HOSTScon le informazioni sull'host ZooKeeper estratte nel primo passaggio. Immettere il comando modificato nell'istanza di Jupyter Notebook per creare l'argomentotripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersRecuperare i dati sulle corse dei taxi. Immettere il comando nella cella successiva per caricare i dati sulle corse dei taxi di New York City. I dati vengono caricati in un frame di dati e quindi il frame di dati viene visualizzato come output della cella.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Impostare le informazioni sugli host broker di Kafka. Sostituire
YOUR_KAFKA_BROKER_HOSTScon le informazioni sugli host broker estratte nel passaggio 1. Immettere il comando modificato nella cella successiva di Jupyter Notebook.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Inviare i dati a Kafka. Nel comando seguente il campo
vendoridviene usato come valore chiave per il messaggio di Kafka. La chiave viene usata da Kafka durante il partizionamento dei dati. Tutti i campi vengono archiviati nel messaggio di Kafka come valore di stringa JSON. Immettere il comando seguente in Jupyter per salvare i dati a Kafka usando una query in batch.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Dichiarare uno schema. Il comando seguente illustra come usare uno schema durante la lettura di dati JSON da Kafka. Immettere il comando nella cella successiva di Jupyter.
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Selezionare i dati e avviare il flusso. Il comando seguente illustra come recuperare dati da Kafka con una query batch e quindi scrivere i risultati in HDFS nel cluster Spark. In questo esempio
selectrecupera il messaggio (campo value) da Kafka e vi applica lo schema. I dati vengono quindi scritti in Hadoop Distributed File System (WASB o ADL) in formato Parquet. Immettere il comando nella cella successiva di Jupyter.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")È possibile verificare che i file siano stati creati immettendo il comando nella cella successiva di Jupyter, che elenca i file nella directory
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataMentre l'esempio precedente ha usato una query in batch, il comando seguente illustra come eseguire la stessa operazione usando una query di streaming. Immettere il comando nella cella successiva di Jupyter.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Eseguire la cella seguente per verificare che i file siano stati scritti dalla query di streaming.
%%bash hdfs dfs -ls /example/streamingtripdata
Pulire le risorse
Per pulire le risorse create da questa esercitazione, eliminare il gruppo di risorse. Se si elimina il gruppo di risorse, viene eliminato anche il cluster HDInsight associato ed eventuali altre risorse associate al gruppo di risorse.
Per rimuovere il gruppo di risorse usando il portale di Azure:
- Nel portale di Azure espandere il menu a sinistra per aprire il menu dei servizi e quindi scegliere Gruppi di risorse per visualizzare l'elenco dei gruppi di risorse.
- Individuare il gruppo di risorse da eliminare e quindi fare clic con il pulsante destro del mouse su Altro (...) a destra dell'elenco.
- Scegliere Elimina gruppo di risorse e quindi confermare.
Avviso
La fatturazione del cluster HDInsight inizia dopo la creazione del cluster e si interrompe solo quando questo viene eliminato. La fatturazione avviene con tariffa oraria, perciò si deve sempre eliminare il cluster in uso quando non lo si usa più.
Se si elimina un cluster Kafka su HDInsight vengono eliminati anche eventuali dati archiviati in Kafka.