Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
HDInsight include due installazioni di Python predefinite nel cluster Spark, Anaconda Python 2.7 e Python 3.5. I clienti potrebbero dover personalizzare l'ambiente Python, ad esempio l'installazione di pacchetti Python esterni. In questo articolo viene illustrata la procedura consigliata per gestire in modo sicuro gli ambienti Python per cluster Apache Spark in HDInsight.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight. Se non si dispone di un cluster Spark in HDInsight, è possibile eseguire azioni script durante la creazione del cluster. Vedere la documentazione su come usare azioni script personalizzate.
Supporto per software open source usato nei cluster HDInsight
Il servizio Microsoft Azure HDInsight usa un ecosistema di tecnologie open source progettate su Apache Hadoop. Microsoft Azure offre un livello di supporto generale per le tecnologie open source. Per altre informazioni, vedere il sito Web delle domande frequenti del supporto di Azure. Il servizio HDInsight offre un livello di supporto aggiuntivo per i componenti predefiniti.
Nel servizio HDInsight sono disponibili due tipi di componenti open source:
| Componente | Descrizione |
|---|---|
| Predefinito | Questi componenti sono preinstallati nei cluster HDInsight e forniscono la funzionalità di base del cluster. Ad esempio, a questa categoria appartengono Apache Hadoop YARN Resource Manager, il linguaggio di query Apache Hive (HiveQL) e la libreria Mahout. L'elenco completo dei componenti del cluster è disponibile in Novità delle versioni del cluster Apache Hadoop incluse in HDInsight. |
| Personalizzazione | In qualità di utente del cluster è possibile installare o usare nel carico di lavoro qualsiasi componente disponibile nella community o creato autonomamente. |
Importante
I componenti forniti con il cluster HDInsight sono completamente supportati. Il supporto tecnico Microsoft aiuta a isolare e risolvere i problemi legati a tali componenti.
I componenti personalizzati ricevono supporto commercialmente ragionevole per semplificare la risoluzione dei problemi. Il supporto tecnico Microsoft potrebbe essere in grado di risolvere il problema OPPURE richiedere di usare i canali disponibili per le tecnologie open source, in cui è possibile ottenere supporto estremamente competente per la tecnologia specifica. Ad esempio, sono disponibili molti siti della community che possono essere usati, ad esempio: pagina delle domande di Microsoft Q&A per HDInsight, https://stackoverflow.com. Anche per i progetti Apache sono disponibili siti specifici in https://apache.org.
Informazioni sull'installazione predefinita di Python
I cluster HDInsight Spark includono Anaconda installato. Nel cluster sono presenti due installazioni di Python, Anaconda Python 2.7 e Python 3.5. La tabella seguente illustra le impostazioni python predefinite per Spark, Livy e Jupyter.
| Impostazione | Python 2.7 | Python 3.5 |
|---|---|---|
| Percorso | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Versione di Spark | Impostazione predefinita: 2.7 | Può modificare la configurazione in 3.5 |
| Versione di Livy | Impostazione predefinita: 2.7 | Può modificare la configurazione in 3.5 |
| Jupyter | Kernel PySpark | Kernel PySpark3 |
Per la versione di Spark 3.1.2, il kernel Apache PySpark viene rimosso e viene installato un nuovo ambiente Python 3.8 in /usr/bin/miniforge/envs/py38/bin, usato dal kernel PySpark3. Le PYSPARK_PYTHON variabili di ambiente e PYSPARK3_PYTHON vengono aggiornate con quanto segue:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
Installare pacchetti Python esterni in modo sicuro
Il cluster HDInsight dipende dall'ambiente Python incorporato, sia Python 2.7 che Python 3.5. L'installazione diretta di pacchetti personalizzati in questi ambienti predefiniti incorporati può causare modifiche impreviste della versione della libreria. e compromettere ulteriormente il cluster. Per installare in modo sicuro pacchetti Python esterni personalizzati per le applicazioni Spark, seguire questa procedura.
Creare un ambiente virtuale Python tramite Conda. Un ambiente virtuale fornisce uno spazio isolato per i progetti senza compromettere altri elementi. Quando si crea l'ambiente virtuale Python, è possibile specificare la versione di Python da usare. Sarà comunque necessario creare un ambiente virtuale anche se si vuole usare Python 2.7 e 3.5. Questo requisito consiste nel verificare che l'ambiente predefinito del cluster non venga compromesso. Eseguire azioni script nel cluster per tutti i nodi con lo script seguente per creare un ambiente virtuale Python.
--prefixspecifica un percorso in cui risiede un ambiente virtuale Conda. Sono disponibili diverse configurazioni che devono essere modificate ulteriormente in base al percorso qui specificato. In questo esempio viene usato py35new, perché il cluster dispone già di un ambiente virtuale esistente denominato PY35.python=specifica la versione di Python per l'ambiente virtuale. In questo esempio viene usata la versione 3.5, ovvero la stessa versione del cluster compilato. Per creare un ambiente virtuale è anche possibile usare altre versioni di Python.anacondaspecifica package_spec come Anaconda per installare pacchetti Anaconda nell'ambiente virtuale.
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yesSe necessario, installare pacchetti Python esterni nell'ambiente virtuale creato. Eseguire azioni script nel cluster per tutti i nodi con lo script seguente per installare pacchetti Python esterni. Per scrivere i file nella cartella dell'ambiente virtuale è necessario disporre del privilegio sudo.
Per un elenco completo dei pacchetti disponibili, eseguire una ricerca nell'indice di pacchetto. È anche possibile ottenere un elenco dei pacchetti disponibili da altre origini. Per esempio, è possibile installare pacchetti resi disponibili tramite conda-forge.
Usare il comando seguente se si vuole installare una libreria con la versione più recente:
Usare il canale Conda:
seabornindica il nome del pacchetto da installare.-n py35newpermette di specificare il nome dell'ambiente virtuale appena creato. Assicurarsi di modificare il nome in modo corrispondente, in base alla creazione dell'ambiente virtuale.
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesIn alternativa, usare il repository PyPi e modificare
seabornepy35newin modo corrispondente:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
Usare il comando seguente se si vuole installare una libreria con una versione specifica:
Usare il canale Conda:
numpy=1.16.1indica il nome e la versione del pacchetto da installare.-n py35newpermette di specificare il nome dell'ambiente virtuale appena creato. Assicurarsi di modificare il nome in modo corrispondente, in base alla creazione dell'ambiente virtuale.
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesIn alternativa, usare il repository PyPi e modificare
numpy==1.16.1epy35newin modo corrispondente:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
Se non si conosce il nome dell'ambiente virtuale, è possibile connettersi tramite SSH al nodo head del cluster ed eseguire
/usr/bin/anaconda/bin/conda info -eper visualizzare tutti gli ambienti virtuali.Modificare le configurazioni di Spark e Livy e puntare all'ambiente virtuale creato.
Aprire l'interfaccia utente di Ambari, passare alla pagina Spark 2, scheda Configurazioni.
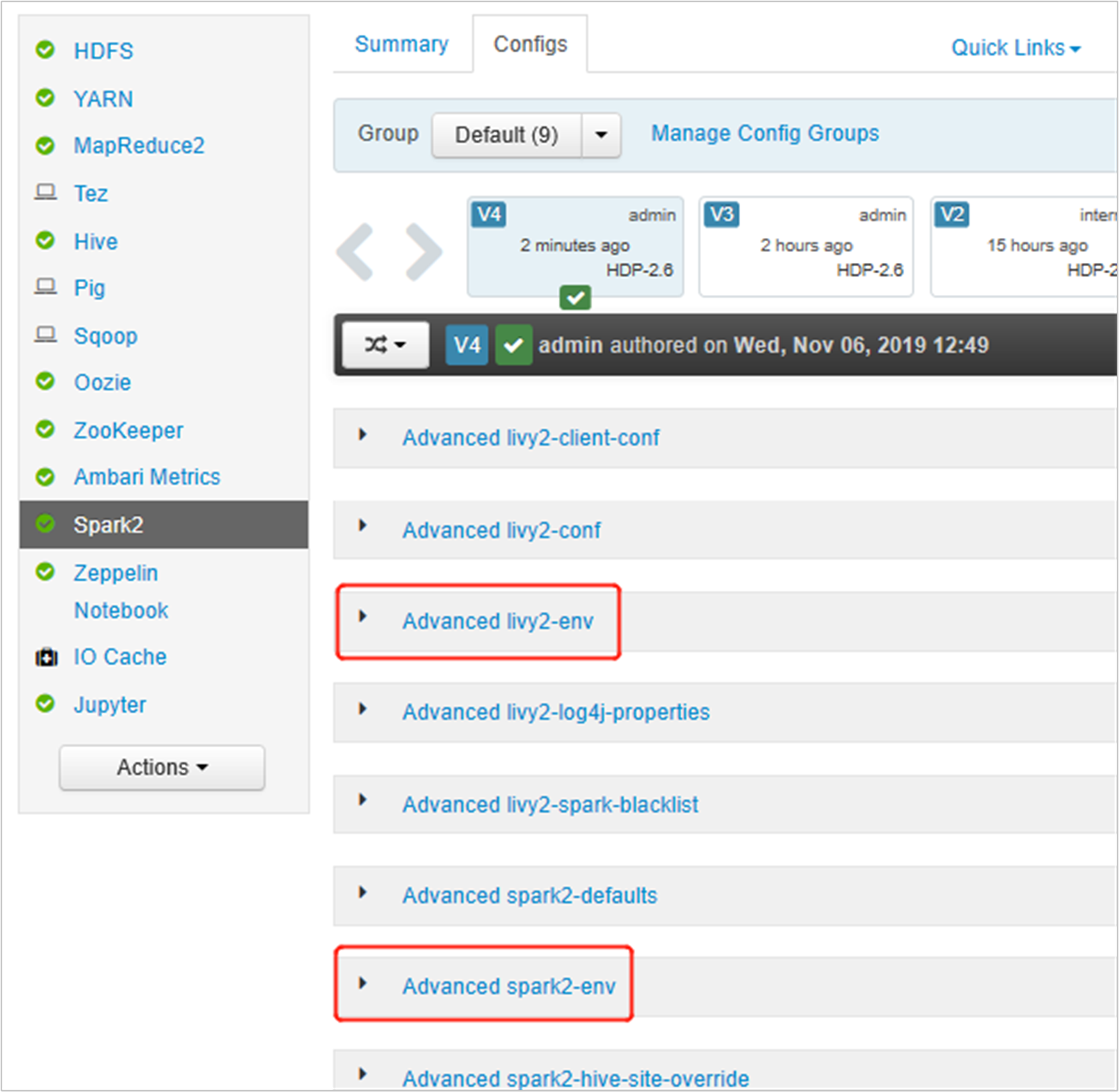
Espandere Avanzate livy2-env, aggiungere le istruzioni seguenti nella parte inferiore. Se l'ambiente virtuale è stato installato con un prefisso diverso, modificare il percorso di conseguenza.
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python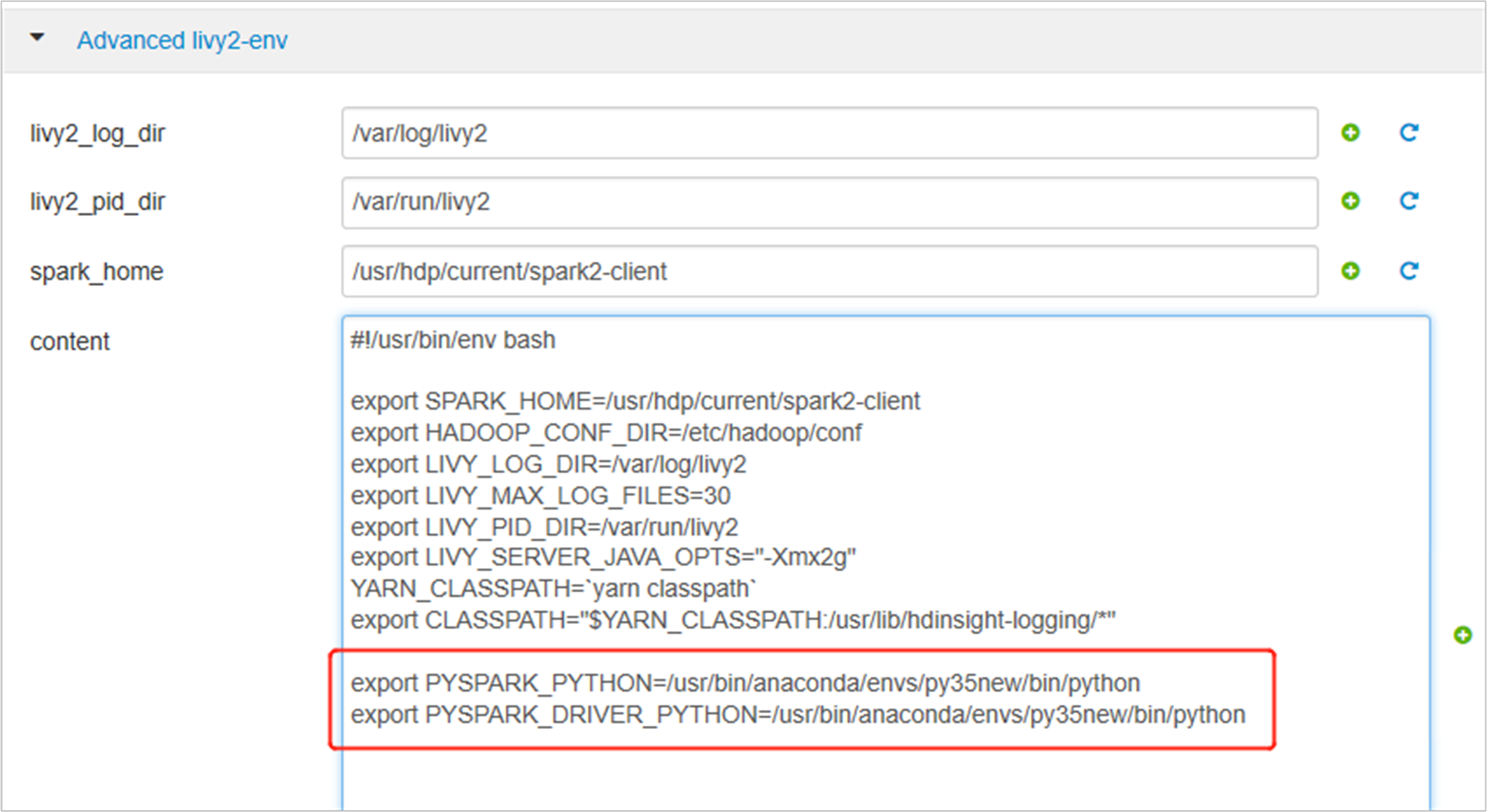
Espandere Advanced spark2-env e sostituire l'istruzione di esportazione PYSPARK_PYTHON esistente in basso. Se l'ambiente virtuale è stato installato con un prefisso diverso, modificare il percorso di conseguenza.
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}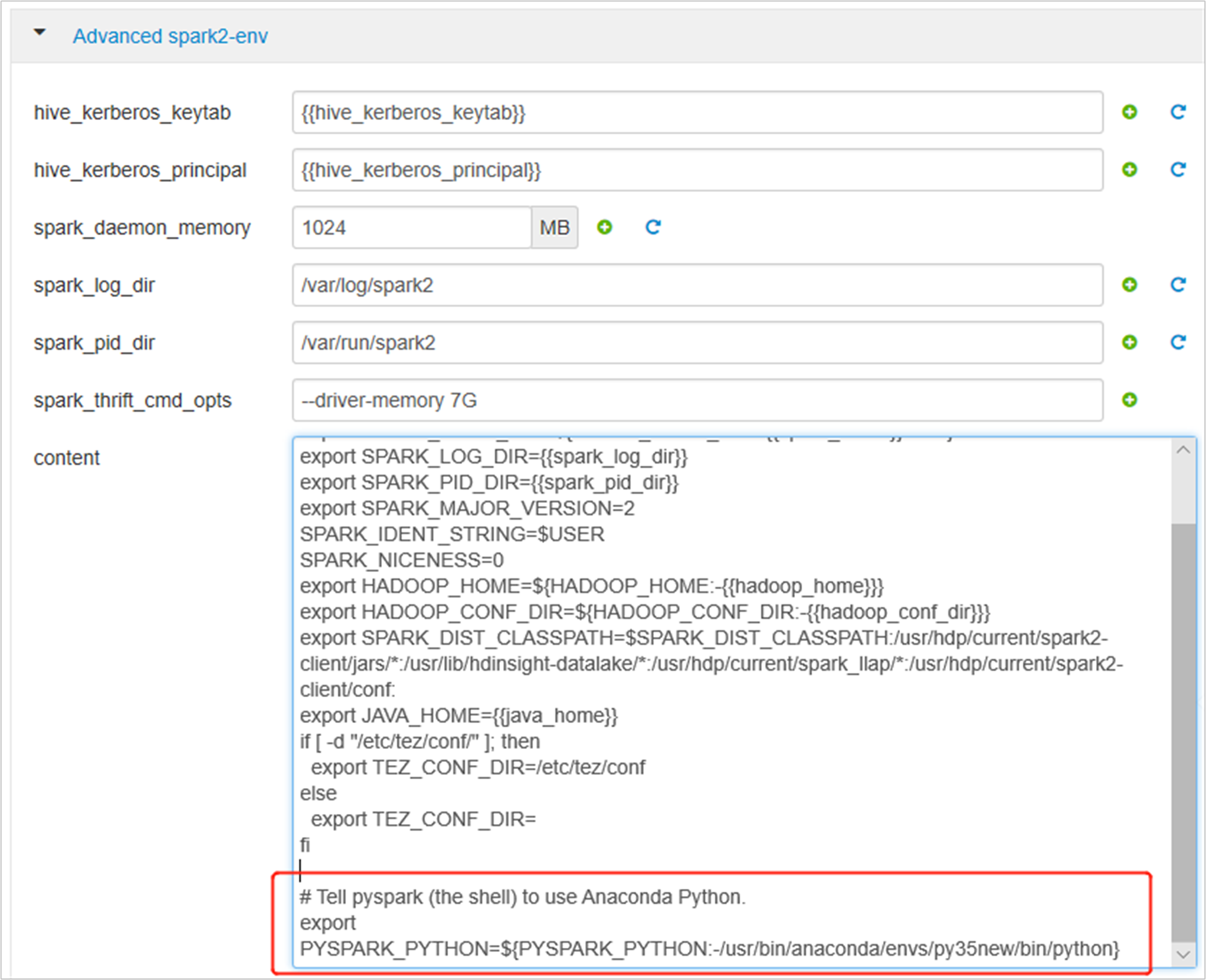
Salvare le modifiche e riavviare i servizi interessati. Queste modifiche richiedono un riavvio del servizio Spark 2. L'interfaccia utente di Ambari mostrerà un promemoria per indicare la necessità di un riavvio; fare quindi clic su Riavvia per riavviare tutti i servizi interessati.
Impostare due proprietà sulla sessione di Spark per assicurarsi che il processo punti alla configurazione spark aggiornata:
spark.yarn.appMasterEnv.PYSPARK_PYTHONespark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON.Usando il terminale o un notebook, usare la
spark.conf.setfunzione .spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")Se si usa
livy, aggiungere le proprietà seguenti al corpo della richiesta:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
Per usare il nuovo ambiente virtuale creato in Jupyter. Modificare le configurazioni di Jupyter e riavviare Jupyter. Eseguire azioni script in tutti i nodi di intestazione con l'istruzione seguente per puntare Jupyter al nuovo ambiente virtuale creato. Assicurarsi di modificare il percorso con il prefisso specificato per l'ambiente virtuale. Dopo l'esecuzione di questa azione script, riavviare il servizio Jupyter tramite l'interfaccia utente di Ambari per rendere disponibile questa modifica.
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonÈ possibile confermare l'ambiente Python in Jupyter Notebook eseguendo il codice: