Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: App per la logica di Azure (A consumo e Standard)
Il modo adottato da qualsiasi architettura di integrazione per gestire in maniera appropriata i tempi di inattività o i problemi causati da sistemi dipendenti può costituire una difficoltà. Per contribuire a creare integrazioni solide e resilienti che consentano di gestire correttamente problemi ed errori, App per la logica di Azure offre un'esperienza all'avanguardia per la gestione degli errori e delle eccezioni.
Criteri di ripetizione dei tentativi
Per la gestione degli errori e delle eccezioni più di base, è possibile usare il criterio di ripetizione dei tentativi se questa funzionalità esiste in un trigger o in un'azione, ad esempio l'azione HTTP. Se la richiesta originale del trigger o dell'azione raggiunge il timeout o ha esito negativo, generando una risposta 408, 429 o 5xx, il criterio di ripetizione specifica che il trigger o l'azione invia nuovamente la richiesta per ogni impostazione dei criteri.
Limiti dei criteri di ripetizione
Per altre informazioni su criteri di ripetizione, impostazioni, limiti e altre opzioni, vedere Limiti dei criteri di ripetizione.
Tipi di criteri di ripetizione
Le operazioni del connettore che supportano i criteri di ripetizione usano i criteri predefiniti, a meno che non si selezioni un criterio di ripetizione diverso.
| Criteri di ripetizione | Descrizione |
|---|---|
| Valore predefinito | Per la maggior parte delle operazioni, il criterio di ripetizione predefinito è un criterio di intervallo esponenziale che invia fino a 4 tentativi a intervalli in aumento esponenziale. Questi intervalli vengono ridimensionati di 7,5 secondi, ma sono limitati tra 5 e 45 secondi. Diverse operazioni usano un criterio di ripetizione predefinito diverso, ad esempio un criterio a intervallo fisso. Per altre informazioni, vedere il tipo di criterio di ripetizione predefinito. |
| Nessuno | Questi criteri non ripetono la richiesta. Per altre informazioni, vedere Nessun criterio di ripetizione. |
| Intervallo esponenziale | Questi criteri attendono un intervallo casuale, che viene selezionato da un intervallo con crescita esponenziale prima di inviare la richiesta successiva. Per altre informazioni, vedere il tipo di criterio intervallo esponenziale. |
| Intervallo fisso | Questi criteri attendono l'intervallo specificato prima di inviare la richiesta successiva. Per altre informazioni, vedere il tipo di criterio intervallo fisso. |
Modificare il tipo di criterio di ripetizione nella finestra di progettazione
Nel portale di Azure apri la risorsa dell'app per la logica.
Nella barra laterale della risorsa, seguire questa procedura per aprire la finestra di progettazione del flusso di lavoro in base all’app per la logica:
Consumo: selezionare la finestra di progettazione per aprire il flusso di lavoro in Strumenti di sviluppo.
Standard
In Flussi di lavoro selezionare Flussi di lavoro.
Nella pagina Flussi di lavoro selezionare il flusso di lavoro.
In Strumenti selezionare la finestra di progettazione per aprire il flusso di lavoro.
Nel trigger o nell'azione in cui si vuole modificare il tipo di criterio di ripetizione dei tentativi, seguire questa procedura per aprire le impostazioni:
Nella finestra di progettazione selezionare l'operazione.
Nel riquadro informazioni sull'operazione selezionare Impostazioni.
In Rete, in Criteri di ripetizione dei tentativi, selezionare il tipo di criterio desiderato.
Modificare il tipo di criterio di ripetizione nell'editor della visualizzazione codice
Verificare se il trigger o l’azione supporta i criteri di ripetizione dei tentativi completando i passaggi precedenti nella finestra di progettazione.
Aprire il flusso di lavoro dell'app per la logica nell'editor della visualizzazione codice.
Nella definizione del trigger o dell'azione aggiungere l'oggetto
retryPolicyJSON all'oggetto del trigger o dell'azioneinputs. Se non esiste alcunretryPolicyoggetto, il trigger o l'azione utilizza il criterio di ripetizione deidefaulttentativi."inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}Obbligatorio
Proprietà valore Type Descrizione type<tipo-di-politica-di-riprova> string Tipo di criterio di ripetizione da usare: default,none,fixedoexponentialcount<retry-attempts> Integer Per i tipi di criteri fixedeexponential, il numero di tentativi, ovvero un valore compreso tra 1 e 90. Per altre informazioni, vedere Intervallo fisso e Intervallo esponenziale.interval<intervallo tra tentativi> string Per i tipi di criteri fixedeexponential, il valore intervallo tra tentativi in formato ISO 8601. Per il criterioexponential, è anche possibile specificare intervalli massimi e minimi facoltativi. Per altre informazioni, vedere Intervallo fisso e Intervallo esponenziale.
Consumo: da 5 secondi (PT5S) a 1 giorno (P1D).
Standard: per i flussi di lavoro con stato, da 5 secondi (PT5S) a 1 giorno (P1D). Per i flussi di lavoro senza stato, da 1 secondo (PT1S) a 1 minuto (PT1M).Facoltativo
Proprietà valore Type Descrizione maximumInterval<intervallo massimo> string Per i criteri exponential, l'intervallo più grande per l'intervallo selezionato casualmente in formato ISO 8601. Il valore predefinito è 1 giorno (P1D). Per altre informazioni, vedere Intervallo esponenziale.minimumInterval<intervallo minimo> string Per i criteri exponential, l'intervallo più piccolo per l'intervallo selezionato casualmente in formato ISO 8601. Il valore predefinito è 5 secondi (PT5S). Per altre informazioni, vedere Intervallo esponenziale.
Criterio di ripetizione dei tentativi predefinito
Le operazioni del connettore che supportano i criteri di ripetizione usano i criteri predefiniti, a meno che non si selezioni un criterio di ripetizione diverso. Per la maggior parte delle operazioni, il criterio di ripetizione predefinito è un criterio di intervallo esponenziale che invia fino a 4 tentativi a intervalli in aumento esponenziale. Questi intervalli vengono ridimensionati di 7,5 secondi, ma sono limitati tra 5 e 45 secondi. Diverse operazioni usano un criterio di ripetizione predefinito diverso, ad esempio un criterio a intervallo fisso.
Nella definizione del flusso di lavoro la definizione del trigger o dell'azione non definisce in modo esplicito i criteri predefiniti, ma l'esempio seguente illustra il comportamento dei criteri di ripetizione predefiniti per l'azione HTTP:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
Nessuno - Nessun criterio di ripetizione
Per specificare che l'azione o il trigger non ripete richieste con esito negativo, impostare <retry-policy-type> su none.
Criteri di ripetizione degli intervalli fissi
Per specificare che l'azione o il trigger attende l'intervallo specificato prima di inviare la richiesta successiva, impostare <retry-policy-type> su fixed.
Esempio
Dopo una prima richiesta con esito negativo, questi criteri di ripetizione provano altre due volte a ricevere le ultime notizie con un intervallo di 30 secondo tra ciascun tentativo:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
Criteri di ripetizione intervallo esponenziale
Il criterio di ripetizione dell'intervallo esponenziale specifica che il trigger o l'azione attende un intervallo casuale prima di inviare la richiesta successiva. L'intervallo casuale viene selezionato da un intervallo con crescita esponenziale. Facoltativamente, è possibile eseguire l'override degli intervalli minimi e massimi predefiniti specificando intervalli minimo e massimo personalizzati, in base al flusso di lavoro di un'app per la logica Consumo o standard.
| Nome | Limite di consumo | Limite standard | Note |
|---|---|---|---|
| Ritardo massimo | Impostazione predefinita: 1 giorno | Predefinito: 1 ora | Per modificare il limite predefinito in un flusso di lavoro dell'app per la logica Consumo, usare il parametro dei criteri di ripetizione. Per modificare il limite predefinito in un flusso di lavoro dell'app per la logica Standard, vedere Modificare le impostazioni dell'host e dell'app per la logica per le app per la logica in App per la logica di Azure a tenant singolo. |
| Ritardo minimo | Predefinito: 5 secondi | Predefinito: 5 secondi | Per modificare il limite predefinito in un flusso di lavoro dell'app per la logica Consumo, usare il parametro dei criteri di ripetizione. Per modificare il limite predefinito in un flusso di lavoro dell'app per la logica Standard, vedere Modificare le impostazioni dell'host e dell'app per la logica per le app per la logica in App per la logica di Azure a tenant singolo. |
Intervalli variabili casuali
Per i criteri di ripetizione dell'intervallo esponenziale, la tabella seguente illustra l'algoritmo generale usato da App per la logica di Azure per generare una variabile casuale uniforme nell'intervallo specificato per ogni tentativo. L'intervallo specificato può essere fino a e includere il numero di tentativi.
| Numero di ripetizioni | Intervallo minimo | Intervallo massimo |
|---|---|---|
| 1 | max(0, <intervallo> minimo) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * intervallo, <intervallo> massimo) |
| 3 | max(2 * intervallo, <intervallo> minimo) | min(4 * intervallo, <intervallo massimo>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * intervallo, <intervallo> massimo) |
| .... | .... | .... |
Gestire il comportamento "Esegui dopo"
Quando si aggiungono azioni nella finestra di progettazione del flusso di lavoro, si dichiara in modo implicito la sequenza per l'esecuzione di tali azioni. Al termine dell'esecuzione di un'azione, l'azione viene contrassegnata con uno stato come Riuscito, Non riuscito,Ignorato o In pausa. In altre parole, l'azione predecessore deve prima terminare con uno qualsiasi degli stati consentiti prima che l'azione successore possa essere eseguita.
Per impostazione predefinita, un'azione aggiunta nella finestra di progettazione viene eseguita solo se l'azione precedente viene completata con lo stato Succeeded . Questo comportamento di esecuzione successiva specifica esattamente l'ordine di esecuzione per le azioni in un flusso di lavoro.
Nella finestra di progettazione è possibile modificare il comportamento predefinito "Esegui dopo" per un'azione modificando l'impostazione Esegui dopo l'azione. Questa impostazione è disponibile solo nelle azioni successive che seguono la prima azione in un flusso di lavoro. La prima azione in un flusso di lavoro viene sempre eseguita dopo che il trigger è stato eseguito con successo. L'impostazione Esegui dopo non è quindi disponibile e non si applica alla prima azione.
Nella definizione JSON sottostante di un'azione, l'impostazione Esegui dopo è la stessa della runAfter proprietà . Questa proprietà specifica una o più azioni predecessore che devono prima terminare con specifici stati consentiti prima che l'azione successore possa essere eseguita. La runAfter proprietà è un oggetto JSON che offre flessibilità consentendo di specificare tutte le azioni predecessori che devono essere completate prima dell'esecuzione dell'azione successore. Questo oggetto definisce anche una matrice di stati accettabili.
Ad esempio, per eseguire un'azione dopo che l'azione A ha esito positivo e anche dopo che l'azione B ha esito positivo o negativo quando si lavora sulla definizione JSON di un'azione, configurare la proprietà seguente runAfter :
{
// Other parts in action definition
"runAfter": {
"Action A": ["Succeeded"],
"Action B": ["Succeeded", "Failed"]
}
}
Comportamento "Esegui dopo" per la gestione degli errori
Quando un'azione genera un errore o un'eccezione non gestita, l'azione viene contrassegnata come Non riuscito e qualsiasi azione successore viene contrassegnata come Ignorato. Se questo comportamento si verifica per un'azione con rami paralleli, il motore di App per la logica di Azure segue gli altri rami per determinare i relativi stati di completamento. Ad esempio, se un ramo termina con un'azione Ignorata, lo stato di completamento del ramo si basa sullo stato predecessore dell'azione ignorata. Al termine dell'esecuzione del flusso di lavoro, il motore determina lo stato dell'intera esecuzione valutando tutti gli stati del ramo. Se un ramo termina in caso di errore, l'intera esecuzione del flusso di lavoro è contrassegnata come Non riuscito.

Per assicurarsi che un'azione possa comunque essere eseguita nonostante lo stato del predecessore, è possibile modificare il comportamento di "esecuzione dopo" di un'azione per gestire gli stati non riusciti del predecessore. In questo modo, l'azione viene eseguita quando lo stato del predecessore è Riuscito, Non riuscito, Ignorato, In pausa o tutti questi stati.
Ad esempio, per eseguire l'azione Office 365 Outlook Invia un messaggio di posta elettronica dopo che l'azione precedente Aggiungi una riga in una tabella di Excel Online è stata contrassegnata come Non riuscito, anziché Riuscito, modificare il comportamento "esegui dopo" usando la finestra di progettazione o l'editor della visualizzazione codice.
Modificare il comportamento "Esegui dopo" nella finestra di progettazione
Nel portale di Azure apri la risorsa dell'app per la logica.
Nella barra laterale della risorsa, seguire questa procedura per aprire la finestra di progettazione del flusso di lavoro in base all’app per la logica:
Consumo: selezionare la finestra di progettazione per aprire il flusso di lavoro in Strumenti di sviluppo.
Standard
Nella barra laterale della risorsa, in Flussi di lavoro, selezionare Flussi di lavoro.
Nella pagina Flussi di lavoro selezionare il flusso di lavoro.
In Strumenti selezionare la finestra di progettazione per aprire il flusso di lavoro.
Nel trigger o nell’azione in cui si vuole modificare il comportamento di “Esegui dopo”, seguire questa procedura per aprire le impostazioni dell’operazione:
Selezionare l’operazione nella finestra di progettazione.
Nel riquadro informazioni sull'operazione selezionare Impostazioni.
La sezione Esegui dopo contiene un elenco Seleziona azioni , che mostra le operazioni predecessori disponibili per l'operazione attualmente selezionata, ad esempio:

Nell'elenco Seleziona azioni espandere l'operazione predecessore corrente, ovvero HTTP in questo esempio:

Per impostazione predefinita, lo stato “Esegui dopo” è impostato su Esito positivo. Questo valore indica che l'operazione predecessore deve essere completata correttamente prima che l'azione corrente possa essere eseguita.

Per modificare il comportamento di “Esegui dopo” con gli stati desiderati, selezionare gli stati.
Nell’esempio seguente viene selezionato Esito negativo.
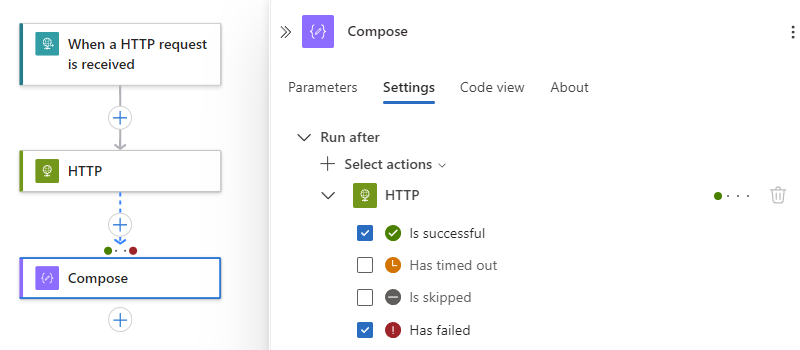
Per specificare che l'operazione corrente viene eseguita solo quando l'azione precedente viene completata con lo stato di fallimento, salto o scadenza, selezionare questi stati e quindi rimuovere lo stato predefinito, ad esempio:
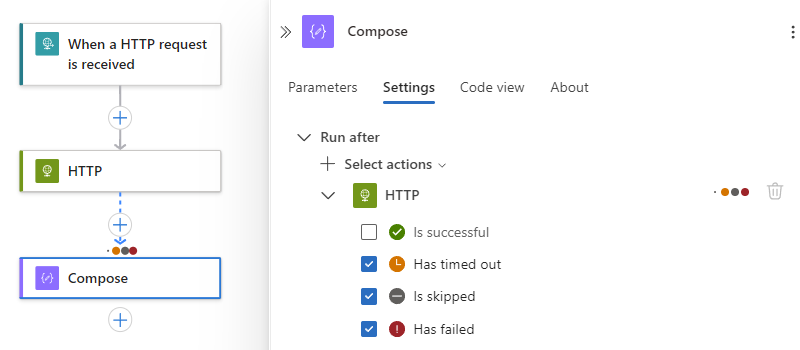
Note
Prima di cancellare lo stato predefinito, assicurarsi di selezionare un altro stato. È necessario avere sempre almeno uno stato selezionato.
Seguire questa procedura per richiedere l’esecuzione e il completamento di più operazioni dei predecessori, ognuna con i propri stati “Esegui dopo”:
Aprire l'elenco Seleziona azioni e selezionare le operazioni predecessore desiderate.
Selezionare gli stati "Esegui dopo" per ogni operazione.
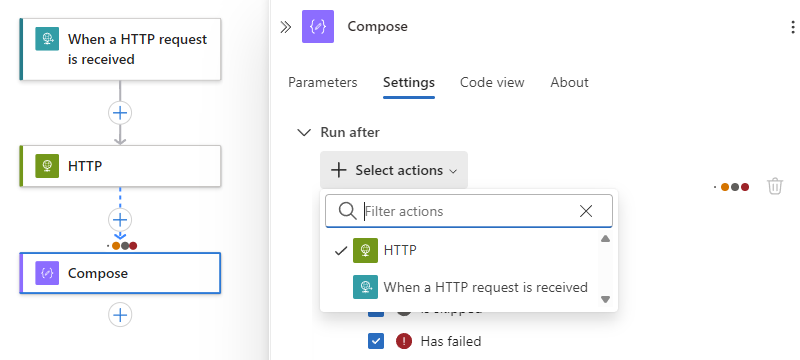
Al termine, chiudere il riquadro informazioni sull'operazione.






Modificare il comportamento "Esegui dopo" nell'editor della visualizzazione codice
Nella barra laterale della risorsa, seguire questa procedura per aprire l’editor di visualizzazione del codice in base all’app per la logica:
Consumo: in Strumenti di sviluppo selezionare la visualizzazione del codice per aprire il flusso di lavoro nell'editor JSON.
Standard
In Flussi di lavoro selezionare Flussi di lavoro.
Nella pagina Flussi di lavoro selezionare il flusso di lavoro.
In Strumenti selezionare visualizzazione codice per aprire il flusso di lavoro nell'editor JSON.
Nella definizione JSON dell'azione modificare la proprietà
runAftercon la sintassi seguente:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }Per questo esempio, modificare la proprietà
runAfterdaSucceededaFailed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }Per specificare che l'azione viene eseguita se l'azione predecessore è contrassegnata come
Failed,SkippedoTimedOut, aggiungere gli altri stati:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
Valutare le azioni con ambiti e i relativi risultati
Come quando si eseguono i passaggi dopo le singole azioni con la proprietà "esegui dopo", è possibile raggruppare le azioni in un ambito. Quando si vuole raggruppare le azioni logicamente, valutare lo stato di aggregazione dell'ambito ed eseguire azioni in base a tale stato, è possibile usare gli ambiti. Al termine dell'esecuzione di tutte le azioni in un ambito, l'ambito stesso ottiene il proprio stato.
Per controllare lo stato di un ambito, è possibile usare lo gli stessi criteri usati per controllare lo stato di esecuzione di un flusso di lavoro, ad esempio Riuscito, Non riuscito e così via.
Per impostazione predefinita, quando tutte le azioni dell'ambito hanno esito positivo lo stato dell'ambito viene contrassegnato come Succeeded. Se l'azione finale in un ambito restituisce Non riuscito o Interrotto, lo stato dell'ambito viene contrassegnato come Non riuscito.
Per rilevare le eccezioni in un ambito Non riuscito ed eseguire le azioni che gestiscono tali errori, è possibile usare la proprietà "esegui dopo" per tale ambito Non riuscito. In tal modo, se una qualsiasi azione nell'ambito ha esito negativo e si usa la proprietà "esegui dopo" per tale ambito, è possibile creare una singola azione per rilevare gli errori.
Per i limiti degli ambiti, vedere Limiti e configurazione.
Configurare un ambito con “Esegui dopo” per la gestione delle eccezioni
Nel portale di Azure aprire la risorsa e il flusso di lavoro dell'app per la logica nella finestra di progettazione.
Il flusso di lavoro deve avere già un trigger che avvia il flusso di lavoro.
Nella finestra di progettazione, seguire questi passaggi generici per aggiungere un’azione di controllo chiamata Ambito al flusso di lavoro.
Nell’azione Ambito, seguire questa procedura generica per aggiungere azioni da eseguire, ad esempio:
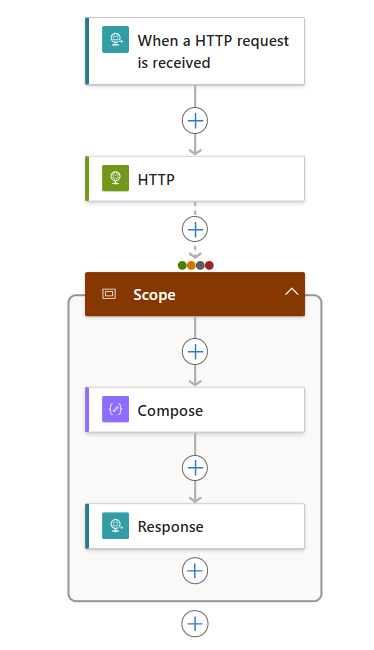
L’elenco seguente mostra alcune azioni di esempio che è possibile includere all’interno di un’azione Ambito:
- Ottenere dati da un’API.
- Elaborare i dati.
- Salvare i dati in un database.
Definire ora le regole “Esegui dopo” per l’esecuzione delle azioni nell’ambito.
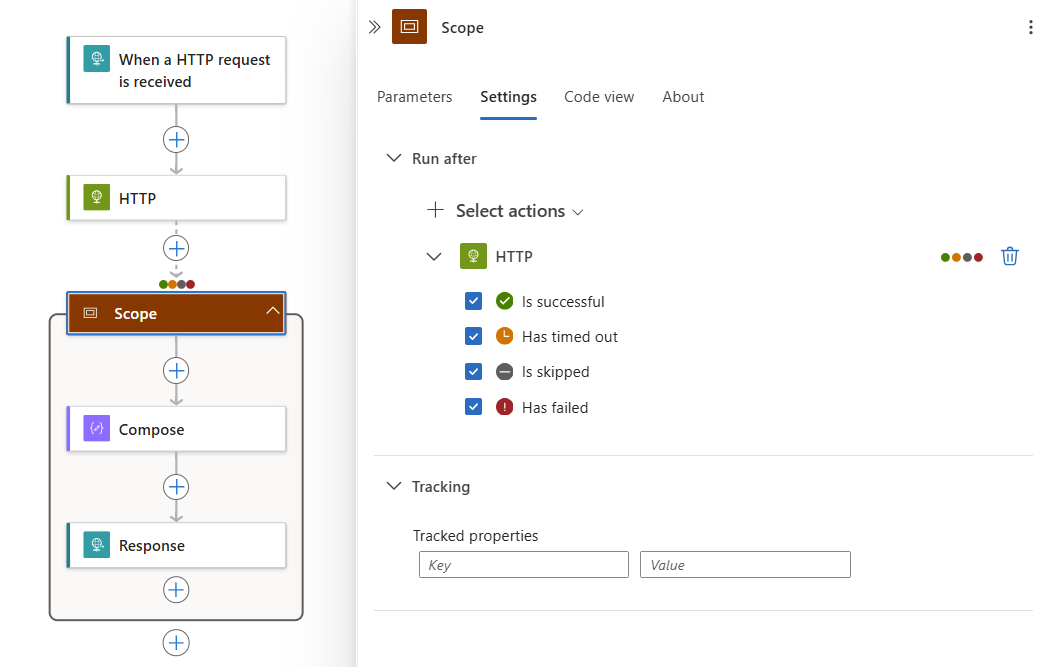
Selezionare il titolo dell’Ambito nella finestra di progettazione. Quando si apre il riquadro delle informazioni per l’ambito, selezionare Impostazioni.
Se nel flusso di lavoro sono presenti più azioni precedenti, selezionare l’azione dopo la quale si desidera eseguire le azioni con ambito dall’elenco Seleziona azioni.
Per l’azione selezionata, selezionare tutti gli stati delle azioni che possono eseguire le azioni con ambito.
In altre parole, qualsiasi stato scelto risultante dall’azione selezionata fa sì che le azioni nell’ambito vengano eseguite.
Nell'esempio seguente, le azioni con ambito vengono eseguite dopo il completamento dell’azione HTTP con uno qualsiasi degli stati selezionati:
Ottenere il contesto e i risultati per gli errori
Anche se l'intercettazione degli errori da un ambito è utile, è anche possibile che si voglia più contesto per apprendere le azioni esatte non riuscite più eventuali errori o codici di stato. La result() funzione restituisce i risultati delle azioni di primo livello in un'azione con ambito. Questa funzione accetta il nome dell'ambito come singolo parametro e restituisce una matrice con i risultati di tali azioni di primo livello. Questi oggetti azione hanno gli stessi attributi degli attributi restituiti dalla funzione actions(), ad esempio l'ora di inizio dell'azione, l'ora di fine, lo stato, gli input, gli ID di correlazione e gli output.
Note
La funzione result() restituisce i risultati solo dalle azioni di primo livello e non da azioni annidate più approfondite, ad esempio azioni switch o condition.
Per ottenere il contesto delle azioni non riuscite in un ambito, è possibile usare l'espressione @result() con il nome dell'ambito e l'impostazione "Esegui dopo". Per filtrare la matrice restituita in base alle azioni con stato Non riuscito, è possibile aggiungere l'azione Filtra matrice. Per eseguire un'azione per un'azione non riuscita restituita, eseguire la matrice filtrata restituita e usare un ciclo Per ognuna.
L'esempio JSON seguente invia una richiesta HTTP POST con il corpo della risposta per tutte le azioni non riuscite all'interno dell'azione di ambito denominata My_Scope. Una spiegazione dettagliata segue l'esempio.
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
I passaggi seguenti descrivono cosa accade in questo esempio:
Per ottenere il risultato di tutte le azioni nell'ambito My_Scope, l'azione Filtra matrice usa questa espressione filtro:
@result('My_Scope')La condizione per Filtra matrice è qualsiasi elemento
@result()con stato uguale aFailed. Questa condizione filtra la matrice che ha tutti i risultati dell'azione da My_Scope fino a una matrice con i soli risultati delle azioni non riuscite.Eseguire un'azione del ciclo
For_eachsugli output della matrice filtrata. Questo passaggio esegue un'azione per ogni risultato di azione non riuscita precedentemente filtrato.Se una sola azione nell'ambito ha esito negativo, le azioni nel ciclo
For_eachvengono eseguite una sola volta. Molte azioni non riuscite determinano un'azione per errore.Inviare HTTP POST nel corpo della risposta dell'elemento
For_each, cioè l'espressione@item()['outputs']['body'].La forma dell'elemento
@result()è uguale alla forma di@actions()e può essere analizzata nello stesso modo.Inclusione di due intestazioni personalizzate con il nome dell'azione non riuscita (
@item()['name']) e l'ID rilevamento client dell'esecuzione non riuscita (@item()['clientTrackingId']).
Come riferimento, di seguito è riportato un esempio di un singolo elemento @result(), che mostra le proprietà name, body, e clientTrackingId analizzate nell'esempio precedente. All'esterno di un'azione For_each, @result() restituisce una matrice di questi oggetti.
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
Le espressioni descritte in precedenza in questo articolo possono essere usate per eseguire diversi modelli di gestione delle eccezioni. È possibile scegliere di eseguire una singola azione di gestione delle eccezioni all'esterno dell'ambito che accetta l'intera matrice filtrata degli errori e rimuovere l'azione For_each. È anche possibile includere altre proprietà utili della risposta \@result() come illustrato in precedenza.
Configurare i log di Monitoraggio di Azure
I modelli precedenti sono modi utili per gestire gli errori e le eccezioni che si verificano all'interno di un'esecuzione. Tuttavia, è anche possibile identificare e rispondere agli errori che si verificano indipendentemente dall'esecuzione. Per valutare gli stati delle esecuzioni, è possibile monitorare i log e le metriche delle esecuzioni, o pubblicarli nello strumento di monitoraggio preferito.
Ad esempio, Monitoraggio di Azure offre un modo semplificato per inviare tutti gli eventi del flusso di lavoro, inclusi tutti gli stati di esecuzione e azione, a una destinazione. È possibile configurare avvisi per metriche e soglie specifiche in Monitoraggio di Azure. È anche possibile inviare eventi del flusso di lavoro a un'area di lavoro Log Analytics o a un account di archiviazione di Azure. In alternativa, è possibile trasmettere tutti gli eventi tramite Hub eventi di Azure in Analisi di flusso di Azure. In Analisi di flusso è possibile scrivere query dinamiche in base a un'anomalia, una media o un errore dei log di diagnostica. È possibile usare Analisi di flusso per inviare informazioni ad altre origini dati, ad esempio a code, argomenti, SQL, Azure Cosmos DB o Power BI.
Per altre informazioni, vedere Configurare i log di Monitoraggio di Azure e raccogliere dati di diagnostica per App per la logica di Azure.