Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning.
Usare questo componente per caricare i dati in una pipeline di Machine Learning da servizi dati cloud esistenti.
Nota
Tutte le funzionalità fornite da questo componente possono essere eseguite dall'archivio dati e dai set di dati nella pagina di destinazione dell'area di lavoro. È consigliabile usare l'archivio dati e il set di dati che includono funzionalità aggiuntive, ad esempio il monitoraggio dei dati. Per altre informazioni, vedere l'articolo How to Access Data (Come accedere ai dati ) e How to Register Datasets (Come registrare i set di dati). Dopo aver registrato un set di dati, è possibile trovarlo nella categoria Datasets -My Datasets> nell'interfaccia della finestra di progettazione. Questo componente è riservato agli utenti di Studio (versione classica) per un'esperienza familiare.
Il componente Importa dati supporta la lettura dei dati dalle origini seguenti:
- URL tramite HTTP
- Archiviazioni cloud di Azure tramite archivi dati)
- Contenitore BLOB di Azure
- Condivisione file di Azure
- Azure Data Lake
- Azure Data Lake Gen2
- Database SQL di Azure
- Azure PostgreSQL
Prima di usare l'archiviazione cloud, è necessario registrare prima un archivio dati nell'area di lavoro di Azure Machine Learning. Per altre informazioni, vedere Come accedere ai dati.
Dopo aver definito i dati desiderati e connessi all'origine, Importa dati deduce il tipo di dati di ogni colonna in base ai valori contenuti e carica i dati nella pipeline della finestra di progettazione. L'output di Import Data è un set di dati che può essere usato con qualsiasi pipeline di progettazione.
Se i dati di origine cambiano, è possibile aggiornare il set di dati e aggiungere nuovi dati eseguendo di nuovo l'importazione dei dati.
Avviso
Se l'area di lavoro si trova in una rete virtuale, è necessario configurare gli archivi dati per usare le funzionalità di visualizzazione dei dati della finestra di progettazione. Per altre informazioni su come usare archivi dati e set di dati in una rete virtuale, vedere Usare Studio di Azure Machine Learning in una rete virtuale di Azure.
Come configurare l'importazione di dati
Aggiungere il componente Importa dati alla pipeline. È possibile trovare questo componente nella categoria Input dati e Output nella finestra di progettazione.
Selezionare il componente per aprire il riquadro destro.
Selezionare Origine dati e scegliere il tipo di origine dati. Potrebbe essere HTTP o archivio dati.
Se si sceglie l'archivio dati, è possibile selezionare gli archivi dati esistenti già registrati nell'area di lavoro di Azure Machine Learning o creare un nuovo archivio dati. Definire quindi il percorso dei dati da importare nell'archivio dati. È possibile esplorare facilmente il percorso selezionando Sfoglia percorso.
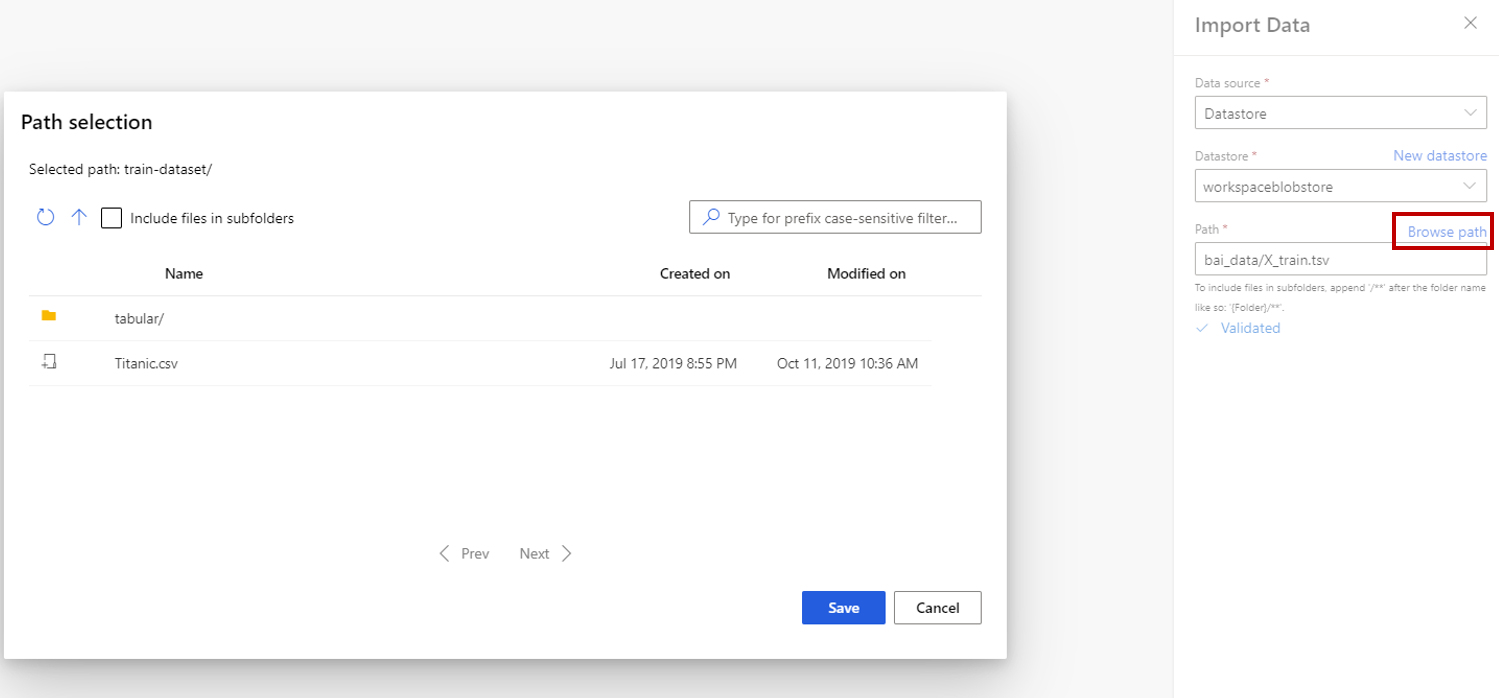
Nota
Il componente Import Data è solo per i dati tabulari . Se si desidera importare più file di dati tabulari una sola volta, sono necessarie le condizioni seguenti. In caso contrario, si verificheranno errori:
- Per includere tutti i file di dati nella cartella, è necessario immettere
folder_name/**per Path. - Tutti i file di dati devono essere codificati in unicode-8.
- Tutti i file di dati devono avere gli stessi numeri di colonna e nomi di colonna.
- Il risultato dell'importazione di più file di dati consiste nel concatenare tutte le righe da più file in ordine.
- Per includere tutti i file di dati nella cartella, è necessario immettere
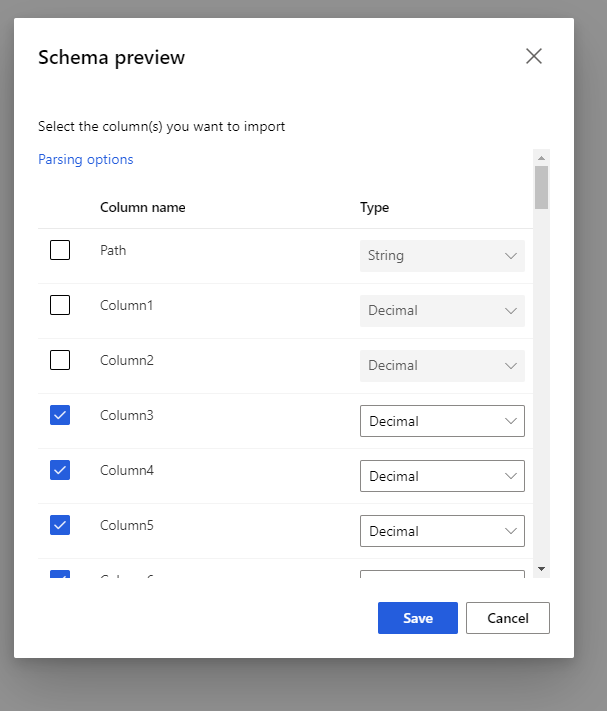
Selezionare lo schema di anteprima per filtrare le colonne da includere. È anche possibile definire impostazioni avanzate come Delimiter nelle opzioni di analisi.
La casella di controllo Rigenera l'output decide se eseguire il componente per rigenerare l'output in fase di esecuzione.
È deselezionata per impostazione predefinita, ovvero se il componente è stato eseguito con gli stessi parametri in precedenza, il sistema riutilizza l'output dell'ultima esecuzione per ridurre il tempo di esecuzione.
Se è selezionata, il sistema esegue di nuovo il componente per rigenerare l'output. Selezionare quindi questa opzione quando i dati sottostanti nell'archiviazione vengono aggiornati, può essere utile per ottenere i dati più recenti.
Inviare la pipeline.
Quando Importa dati carica i dati nella finestra di progettazione, deduce il tipo di dati di ogni colonna in base ai valori contenuti, numerici o categorici.
Se è presente un'intestazione, l'intestazione viene usata per denominare le colonne del set di dati di output.
Se non sono presenti intestazioni di colonna esistenti nei dati, i nuovi nomi di colonna vengono generati usando il formato col1, col2,... , coln*.

Risultati
Al termine dell'importazione, fare clic con il pulsante destro del mouse sul set di dati di output e selezionare Visualizza per verificare se i dati sono stati importati correttamente.
Se si desidera salvare i dati per il riutilizzo, anziché importare un nuovo set di dati ogni volta che viene eseguita la pipeline, selezionare l'icona Registra set di dati nella scheda Output e log nel pannello destro del componente. Scegliere un nome per il set di dati. Il set di dati salvato mantiene i dati al momento del salvataggio. Il set di dati non viene aggiornato quando viene rieseguita la pipeline, anche se il set di dati nella pipeline cambia. Ciò può essere utile per creare snapshot di dati.
Dopo aver importato i dati, potrebbero essere necessari alcuni preparativi aggiuntivi per la modellazione e l'analisi:
Usare Modifica metadati per modificare i nomi delle colonne, gestire una colonna come tipo di dati diverso o indicare che alcune colonne sono etichette o funzionalità.
Usare Select Columns in Dataset (Seleziona colonne nel set di dati ) per selezionare un subset di colonne da trasformare o usare nella modellazione. Le colonne trasformate o rimosse possono essere facilmente ricongiunte al set di dati originale usando il componente Aggiungi colonne .
Usare Partition e Sample per dividere il set di dati, eseguire il campionamento o ottenere le prime n righe.
Limiti
A causa della limitazione di accesso all'archivio dati, se la pipeline di inferenza contiene il componente Importa dati , viene rimossa automaticamente quando viene distribuita nell'endpoint in tempo reale.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.