Configurare il training autoML con Python
SI APPLICA A: azureml sdk Python v1
azureml sdk Python v1
Questa guida illustra come configurare un machine learning automatizzato, AutoML e come eseguire il training con Azure Machine Learning Python SDK usando Machine Learning automatizzato ML. Machine Learning automatizzato seleziona automaticamente un algoritmo e iperparametri, e genera un modello pronto per la distribuzione. Questa guida fornisce informazioni dettagliate sulle varie opzioni che è possibile usare per configurare esperimenti di Machine Learning automatizzati.
Per un esempio end-to-end, vedere Esercitazione: AutoML- eseguire il training del modello di regressione.
Se si preferisce un'esperienza senza codice, è anche possibile Configurare il training AutoML senza codice in Azure Machine Learning Studio.
Prerequisiti
Per questo articolo è necessario,
Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, vedere Creare risorse dell'area di lavoro.
Azure Machine Learning Python SDK installato. Per installare l'SDK, è possibile,
Creare un'istanza di calcolo, che installa automaticamente l'SDK ed è preconfigurata per i flussi di lavoro di Machine Learning. Per altre informazioni, vedere Creare e gestire un'istanza di calcolo di Azure Machine Learning.
Installare il pacchetto
automlmanualmente, che include l'installazione predefinita dell'SDK.
Importante
I comandi Python in questo articolo richiedono la versione più recente del pacchetto
azureml-train-automl.- Installare il pacchetto di
azureml-train-automlpiù recente nell'ambiente locale. - Per informazioni dettagliate sul pacchetto di
azureml-train-automlpiù recente, vedere le note sulla versione.
Avviso
Python 3.8 non è compatibile con
automl.
Selezionare il tipo di esperimento
Prima di iniziare l'esperimento, è necessario determinare il tipo di problema di machine learning da risolvere. Il machine learning automatizzato supporta i tipi di attività classification, regression e forecasting. Altre informazioni sui tipi di attività.
Nota
Supporto per le attività di elaborazione del linguaggio naturale (NLP): la classificazione delle immagini (multiclasse e multi-etichetta) e il riconoscimento delle entità denominate è disponibile in anteprima pubblica. Altre informazioni sulle attività NLP in ML automatizzato.
Queste funzionalità di anteprima vengono fornite senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero avere funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Il codice seguente usa il parametro task nel costruttore AutoMLConfig per specificare il tipo di esperimento come classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Origine dati e formato
Il processo di Machine Learning automatizzato supporta dati presenti nel desktop locale o nel cloud, ad esempio Archiviazione BLOB di Azure. I dati possono essere letti in un dataframe Pandas o in un TabularDataset di Azure Machine Learning. Altre informazioni sui set di dati.
Requisiti per i dati di training in Machine Learning:
- I dati devono essere in formato tabulare.
- Il valore da stimare, la colonna di destinazione, deve essere presente nei dati.
Importante
Gli esperimenti di Machine Learning automatizzati non supportano il training con set di dati che usano l'accesso ai dati basato sull'identità.
Per gli esperimenti remoti, i dati di training devono essere accessibili dal calcolo remoto. Machine Learning automatizzato accetta solo set di dati tabulari di Azure Machine Learning quando si lavora su un ambiente di calcolo remoto.
I seti di dati di Azure Machine Learning espongono la funzionalità per:
- Trasferire facilmente i dati da file statici o origini URL nell'area di lavoro.
- rendere i dati disponibili per gli script di training durante l'esecuzione in risorse di calcolo sul cloud. Vedere Come eseguire il training con set di dati per un esempio di uso della classe
Datasetper montare i dati nella destinazione di calcolo remota.
Il codice seguente crea un TabularDataset da un URL Web. Vedere Creare un TabularDataset per esempi di codice su come creare set di dati da altre origini, ad esempio file locali e archivi dati.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Per gli esperimenti di calcolo locali, è consigliabile usare i dataframe pandas per tempi di elaborazione più rapidi.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Training, convalida e test dei dati
È possibile specificare set di dati di training e di convalida separati direttamente nel costruttore di AutoMLConfig. Altre informazioni su come configurare i dati di training, convalida, convalida incrociata e test per gli esperimenti AutoML.
Se non si specifica in modo esplicito un parametro validation_data o n_cross_validation, ML automatizzato applica tecniche predefinite per determinare come viene eseguita la convalida. Questa determinazione dipende dal numero di righe nel set di dati assegnato al parametro training_data.
| Dimensioni dei dati di training | Tecnica di convalida |
|---|---|
| Più grande di 20.000 righe | Viene applicata la suddivisione dei dati di training/convalida. Il valore predefinito consiste nell'accettare il 10% del set di dati di training iniziale come set di convalida. A sua volta, il set di convalida viene usato per il calcolo delle metriche. |
| Più piccolo di 20.000 righe | Viene applicato l'approccio di convalida incrociata. Il numero predefinito di riduzioni dipende dal numero di righe. Se il set di dati è minore di 1.000 righe, vengono usate 10 riduzioni. Se le righe sono comprese tra 1.000 e 20.000, vengono usate tre riduzioni. |
Suggerimento
È possibile caricare dati di test (anteprima) per valutare i modelli generati automaticamente da Machine Learning automatizzato. Queste funzionalità sono funzionalità sperimentali di anteprima e possono cambiare in qualsiasi momento. Scopri come:
- Passare i dati di test all'oggetto AutoMLConfig.
- Testare i modelli generati da ML automatizzato per l'esperimento.
Se si preferisce un'esperienza senza codice, vedere il passaggio 12 in Configurare AutoML con l'interfaccia utente di Studio
Dati di grandi dimensioni
Il Machine Learning automatizzato supporta un numero limitato di algoritmi per il training su dati di grandi dimensioni che possono compilare correttamente modelli per Big Data in macchine virtuali di piccole dimensioni. Le euristiche di Machine Learning automatizzata dipende da proprietà quali le dimensioni dei dati, le dimensioni della memoria della macchina virtuale, il timeout dell'esperimento e le impostazioni di definizione delle caratteristiche per determinare se questi algoritmi di dati di grandi dimensioni devono essere applicati. Altre informazioni sui modelli supportati nel ML automatizzato.
Per la regressione, regressore di discesa del gradiente online e regressore lineare veloce
Per la classificazione, classificatore perceptron medio e classificatore SVM lineare; in cui il classificatore Linear SVM include sia dati di grandi dimensioni che versioni di dati di piccole dimensioni.
Per eseguire l'override di queste euristiche, applicare le impostazioni seguenti:
| Attività | Impostazione | Note |
|---|---|---|
| Bloccare gli algoritmi di streaming dei dati | blocked_models nell'oggetto AutoMLConfig ed elencare i modelli che non si desidera usare. |
Restituisce un errore di esecuzione o un tempo di esecuzione lungo |
| Usare algoritmi di streaming dei dati | allowed_models nell'oggetto AutoMLConfig ed elencare i modelli da usare. |
|
| Usare algoritmi di streaming dei dati (esperimenti dell'interfaccia utente di Studio) |
Bloccare tutti i modelli ad eccezione degli algoritmi di Big Data da usare. |
Calcolo per eseguire l'esperimento
Successivamente, determinare dove verrà eseguito il training del modello. Un esperimento di training automatizzato di Machine Learning può essere eseguito nelle opzioni di calcolo seguenti.
Scegliere un computer locale: se lo scenario riguarda le esplorazioni iniziali o delle demo che usano piccoli dati e brevi training (ad esempio, secondi o un paio di minuti per esecuzione figlio), il training sul computer locale potrebbe essere una scelta migliore. Non sono presenti tempi di installazione, le risorse dell'infrastruttura (PC o macchina virtuale) sono direttamente disponibili. Vedere questo notebook per un esempio di calcolo locale.
Scegliere un cluster di calcolo di Machine Learning remoto: se si esegue il training con set di dati più grandi, ad esempio nel training di produzione, la creazione di modelli che richiedono training più lunghi offre prestazioni di tempo end-to-end molto migliori perché
AutoMLparallelizzerà i training tra i nodi del cluster. In un ambiente di calcolo remoto, il tempo di avvio per l'infrastruttura interna aggiungerà circa 1,5 minuti per esecuzione figlio, più altri minuti per l'infrastruttura del cluster se le macchine virtuali non sono ancora in esecuzione. Il calcolo gestito di Azure Machine Learning è un servizio gestito che consente di eseguire il training di modelli di Machine Learning in cluster di macchine virtuali di Azure. L'istanza di calcolo è supportata anche come destinazione di calcolo.Un cluster di Azure Databricks nella sottoscrizione di Azure. Per altre informazioni, vedere Configurare un cluster di Azure Databricks per machine learning automatizzato. Visitare il sito GitHub per esempi di notebook con Azure Databricks.
Quando si sceglie la destinazione di calcolo, tenere in considerazione i fattori seguenti:
| Vantaggi | Svantaggi | |
|---|---|---|
| Destinazione di calcolo locale | ||
| Cluster di elaborazione di Machine Learning remoti |
Configurare le impostazioni di esperimento
Sono disponibili diverse opzioni che è possibile usare per configurare l'esperimento di Machine Learning automatizzato. Questi parametri vengono impostati creando un oggetto AutoMLConfig. Vedere la Classe AutoMLConfig per un elenco completo dei parametri.
L'esempio seguente è relativo a un'attività di classificazione. L'esperimento usa l'interfaccia utente ponderata come metrica primaria e ha un timeout dell'esperimento impostato su 30 minuti e 2 riduzioni di convalida incrociata.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
È anche possibile configurare le attività di previsione, che richiedono una configurazione aggiuntiva. Per altri dettagli, vedere l'articolo Configurare AutoML per le previsioni delle serie temporali.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Modelli supportati
Il Machine Learning automatizzato prova modelli e algoritmi diversi durante il processo di automazione e ottimizzazione. Come utente, non è necessario specificare l'algoritmo.
I tre diversi valori dei parametri task determinano l'elenco di algoritmi, o modelli, da applicare. Usare i parametri allowed_models o blocked_models per modificare ulteriormente le iterazioni con i modelli disponibili da includere o escludere.
La tabella seguente riepiloga i modelli supportati in base al tipo di attività.
Nota
Se si prevede di esportare i modelli di Machine Learning automatizzati creati in un modello ONNX, solo gli algoritmi indicati con un *(asterisco) possono essere convertiti nel formato ONNX. Altre informazioni sulla conversione di modelli in ONNX.
Si noti anche che in questo momento ONNX supporta solo le attività di classificazione e regressione.
| Classificazione | Regressione | Previsione di una serie temporale |
|---|---|---|
| Logistic Regression* | Elastic Net* | AutoARIMA |
| Light GBM* | Light GBM* | Prophet |
| Gradient Boosting* | Gradient Boosting* | Elastic Net |
| Decision Tree* | Decision Tree* | Light GBM |
| K Nearest Neighbors* | K Nearest Neighbors* | Gradient Boosting |
| Linear SVC* | LARS Lasso* | Decision Tree |
| Support Vector Classification (SVC)* | Stochastic Gradient Descent (SGD)* | Arimax |
| Random Forest* | Random Forest | LARS Lasso |
| Extremely Randomized Trees* | Extremely Randomized Trees* | Stochastic Gradient Descent (SGD) |
| Xgboost* | Xgboost* | Random Forest |
| Averaged Perceptron Classifier | Online Gradient Descent Regressor | Xgboost |
| Naive Bayes* | Fast Linear Regressor | ForecastTCN |
| Stochastic Gradient Descent (SGD)* | Naive | |
| Linear SVM Classifier* | SeasonalNaive | |
| Media | ||
| SeasonalAverage | ||
| ExponentialSmoothing |
Primary metric (Metrica principale)
Il parametro primary_metric determina la metrica da usare durante il training del modello per l'ottimizzazione. Le metriche disponibili che è possibile selezionare sono determinate dal tipo di attività scelto.
La scelta di una metrica primaria per ML automatizzato da ottimizzare dipende da molti fattori. È consigliabile scegliere una metrica che rappresenti al meglio le esigenze aziendali. Valutare quindi se la metrica è adatta al profilo del set di dati (dimensioni dei dati, intervallo, distribuzione di classi e così via). Le sezioni seguenti riepilogano le metriche principali consigliate in base al tipo di attività e allo scenario aziendale.
Per informazioni sulle definizioni specifiche di queste metriche, vedere Risultati del Machine Learning automatizzato.
Metriche per gli scenari di classificazione
Le metriche dipendenti dalla soglia, ad esempio accuracy, recall_score_weighted, norm_macro_recall e precision_score_weighted potrebbero non essere ottimizzate anche per i set di dati di piccole dimensioni, che hanno un'asimmetria di classe molto elevata (squilibrio di classe) o quando il valore della metrica previsto è molto vicino a 0,0 o 1,0. In questi casi, AUC_weighted può essere una scelta migliore per la metrica primaria. Al termine dell'automazione di Machine Learning, è possibile scegliere il modello vincente in base alla metrica più adatta alle esigenze aziendali.
| Metric | Caso/i d'uso di esempio |
|---|---|
accuracy |
Classificazione delle immagini, analisi della valutazione, stima della varianza |
AUC_weighted |
Rilevamento delle frodi, classificazione delle immagini, rilevamento anomalie/rilevamento della posta indesiderata |
average_precision_score_weighted |
Analisi valutazione |
norm_macro_recall |
Previsione abbandono |
precision_score_weighted |
Metriche per i modelli di regressione
r2_score, normalized_mean_absolute_error e normalized_root_mean_squared_error stanno tentando di ridurre al minimo gli errori di stima. r2_score e normalized_root_mean_squared_error riducono al minimo gli errori quadratici medi mentre normalized_mean_absolute_error riduce al minimo il valore assoluto medio degli errori. Il valore assoluto tratta gli errori in tutte le dimensioni e gli errori quadratici avranno una penalità molto maggiore per gli errori con valori assoluti più grandi. A seconda che gli errori più grandi debbano essere puniti più o meno, è possibile scegliere di ottimizzare l'errore quadratico o l'errore assoluto.
La differenza principale tra r2_score e normalized_root_mean_squared_error è il modo in cui vengono normalizzati e i loro significati. normalized_root_mean_squared_error è la radice errore quadratico medio normalizzata per intervallo e può essere interpretata come la grandezza dell'errore medio per la stima. r2_score è un errore quadratico medio normalizzato da una stima della varianza dei dati. È la proporzione di variazione che può essere acquisita dal modello.
Nota
Anche r2_score e normalized_root_mean_squared_error si comportano in modo analogo come metriche primarie. Se viene applicato un set di convalida fisso, queste due metriche ottimizzano la stessa destinazione e lo stesso errore quadratico medio, e verranno ottimizzate dallo stesso modello. Quando è disponibile solo un set di training e viene applicata la convalida incrociata, il normalizzatore per normalized_root_mean_squared_error è fisso come intervallo di training impostato, ma il normalizzatore per r2_score varia per ogni riduzione in quanto è la varianza per ogni riduzione.
Se la classificazione, anziché il valore esatto, è di interesse, spearman_correlation può essere una scelta migliore perché misura la correlazione di classificazione tra valori reali e stime.
Tuttavia, attualmente nessuna metrica primaria per la regressione affronta la differenza relativa. Tutti i r2_score, normalized_mean_absolute_error e normalized_root_mean_squared_error trattano un errore di previsione di 20.000 $ allo stesso modo sia per un lavoratore con uno stipendio di 30.000 $ che per un lavoratore che guadagna 20 milioni di dollari, se questi due punti di dati appartengono allo stesso set di dati per la regressione o alla stessa serie temporale specificata dall'identificatore della serie temporale. Mentre in realtà, prevedere solo 20.000 dollari di differenza da uno stipendio di 20 milioni di dollari è molto vicino (una piccola differenza relativa dello 0,1%), mentre 20.000 dollari di differenza da 30.000 non lo è (una grande differenza relativa del 67%). Per risolvere il problema della differenza relativa, è possibile eseguire il training di un modello con le metriche primarie disponibili e quindi selezionare il modello con il miglior mean_absolute_percentage_error o root_mean_squared_log_error.
| Metric | Caso/i d'uso di esempio |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Previsione dei prezzi (casa/prodotto/mancia), Previsione del punteggio della recensione |
r2_score |
Ritardo della compagnia aerea, stima dello stipendio, tempo di risoluzione dei bug |
normalized_mean_absolute_error |
Metriche per gli scenari di previsione delle serie temporali
Le raccomandazioni sono simili a quelle indicate per gli scenari di regressione.
| Metric | Caso/i d'uso di esempio |
|---|---|
normalized_root_mean_squared_error |
Stima dei prezzi (previsione), ottimizzazione dell'inventario, previsione della domanda |
r2_score |
Stima dei prezzi (previsione), ottimizzazione dell'inventario, previsione della domanda |
normalized_mean_absolute_error |
Definizione delle funzionalità dei dati
In ogni esperimento di Machine Learning automatizzato, i dati vengono ridimensionati e normalizzati automaticamente per determinati algoritmi che sono sensibili alle funzionalità su scale diverse. Questa scalabilità e normalizzazione viene chiamata definizione di funzionalità. Per altri dettagli ed esempi di codice, vedere Definizione delle funzionalità in AutoML.
Nota
I passaggi di definizione delle funzionalità di Machine Learning automatizzato (normalizzazione delle funzionalità, gestione dei dati mancanti, conversione dei valori di testo in formato numerico e così via) diventano parte del modello sottostante. Quando si usa il modello per le previsioni, gli stessi passaggi di definizione delle funzionalità applicati durante il training vengono automaticamente applicati ai dati di input.
Quando si configurano gli esperimenti nell'oggetto AutoMLConfig, è possibile abilitare/disabilitare l'impostazione featurization. La tabella seguente illustra le impostazioni accettate per la definizione delle funzionalità nell'oggetto AutoMLConfig.
| Configurazione della definizione delle funzionalità | Descrizione |
|---|---|
"featurization": 'auto' |
Indica che i passaggi di protezione dati e definizione delle funzionalità vengono eseguiti automaticamente come parte della pre-elaborazione. Impostazione predefinita. |
"featurization": 'off' |
Indica che il passaggio di definizione delle caratteristiche non deve essere eseguito automaticamente. |
"featurization": 'FeaturizationConfig' |
Indica che deve essere usata la definizione delle funzionalità personalizzata. Informazioni su come personalizzare la definizione delle funzionalità. |
Configurazione di ensemble
I modelli di ensemble sono abilitati per impostazione predefinita e vengono visualizzati come iterazioni di esecuzione finali in un'esecuzione AutoML. Sono attualmente supportati VotingEnsemble e StackEnsemble.
Il voto implementa il voto flessibile, che usa medie ponderate. L'implementazione dello stack usa un'implementazione a due livelli, in cui il primo livello ha gli stessi modelli dell'ensemble di voto e il secondo modello di livello viene usato per trovare la combinazione ottimale dei modelli dal primo livello.
Se si usano modelli ONNX, o si ha abilitata la spiegabilità del modello, lo stacking è disabilitato e viene usata solo la votazione.
Il training di Ensemble può essere disabilitato usando i parametri booleani enable_voting_ensemble e enable_stack_ensemble.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Per modificare il comportamento predefinito di ensemble, è possibile specificare più argomenti predefiniti come kwargs in un oggetto AutoMLConfig.
Importante
I parametri seguenti non sono parametri espliciti della classe AutoMLConfig.
ensemble_download_models_timeout_sec: durante la generazione di modelli VotingEnsemble e StackEnsemble, vengono scaricati più modelli montati dalle esecuzioni figlio precedenti. Se si verifica questo errore:AutoMLEnsembleException: Could not find any models for running ensembling, potrebbe essere necessario fornire più tempo per il download dei modelli. Il valore predefinito è 300 secondi per il download di questi modelli in parallelo e non è previsto un limite massimo di timeout. Se è necessario più tempo, configurare questo parametro con un valore superiore a 300 secondi.Nota
Se viene raggiunto il timeout e sono stati scaricati modelli, l'Ensemble procede con il numero di modelli scaricati. Non è necessario che tutti i modelli vengano scaricati per terminare prima del timeout. I parametri seguenti si applicano solo ai modelli StackEnsemble:
stack_meta_learner_type: il meta-apprendimento è un modello di cui è stato eseguito il training nell'output dei singoli modelli eterogenei. I modelli di meta-apprendimento predefiniti sonoLogisticRegressionper le attività di classificazione (oppureLogisticRegressionCVse è abilitata la convalida incrociata) eElasticNetper le attività di regressione o previsione (oppureElasticNetCVse è abilitata la convalida incrociata). Questo parametro può essere una delle stringhe seguenti:LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet,ElasticNetCV,LightGBMRegressoroLinearRegression.stack_meta_learner_train_percentage: specifica la proporzione del set di training (quando si sceglie il tipo training e convalida) da riservare per il training del meta-apprendimento. Il valore predefinito è0.2.stack_meta_learner_kwargs: parametri facoltativi da passare all'inizializzatore del meta-apprendimento. Questi parametri e tipi di parametro rispecchiano i parametri e i tipi di parametro del costruttore del modello corrispondente e vengono trasmessi al costruttore del modello.
Il codice seguente mostra un esempio di specifica di un comportamento Ensemble personalizzato in un oggetto AutoMLConfig.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Criteri di uscita
Esistono alcune opzioni che è possibile definire in AutoMLConfig per terminare l'esperimento.
| Criteri | description |
|---|---|
| Nessun criterio | Se non si definiscono parametri di uscita, l'esperimento continua fino a quando non vengono apportati ulteriori progressi sulla metrica primaria. |
| Dopo un periodo di tempo | Usare experiment_timeout_minutes nelle impostazioni per definire per quanto tempo, in minuti, l'esperimento deve continuare a essere eseguito. Per evitare errori di timeout dell'esperimento, sono previsti almeno 15 minuti, o 60 minuti se la dimensione della riga per colonna supera i 10 milioni. |
| È stato raggiunto un punteggio | L'uso di experiment_exit_score completa l'esperimento dopo che è stato raggiunto un punteggio di metrica primario specificato. |
Eseguire esperimento
Avviso
Se si esegue più volte un esperimento con le stesse impostazioni di configurazione e la stessa metrica primaria, è probabile che si vedano variazioni nel punteggio finale di ogni esperimento e nei modelli generati. Gli algoritmi automatizzati di Machine Learning hanno una casualità intrinseca che può causare lievi variazioni nell'output dei modelli dall'esperimento e nel punteggio finale delle metriche del modello consigliato, ad esempio l'accuratezza. È probabile che vengano visualizzati anche i risultati con lo stesso nome del modello, ma vengono usati iperparametri diversi.
Per il Machine Learning automatizzato, si crea un oggetto Experiment che è un oggetto denominato in una Workspace usata per eseguire gli esperimenti.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Avviare l'esperimento per eseguire e generare un modello. Passare il AutoMLConfig al metodo submit per generare il modello.
run = experiment.submit(automl_config, show_output=True)
Nota
Le dipendenze vengono prima installate in un nuovo computer. Potrebbero occorrere fino a 10 minuti prima che venga visualizzato l'output.
Se si imposta show_output su True, l'output viene visualizzato nella console.
Più esecuzioni figlio nei cluster
Le esecuzioni figlio dell'esperimento di Machine Learning automatizzato possono essere eseguite in un cluster che esegue già un altro esperimento. Tuttavia, la tempistica dipende dal numero di nodi del cluster e se tali nodi sono disponibili per eseguire un esperimento diverso.
Ogni nodo del cluster funge da singola macchina virtuale (VM) che può eseguire una singola esecuzione di training; per il ML automatizzato questo significa un'esecuzione figlio. Se tutti i nodi sono occupati, il nuovo esperimento viene accodato. Tuttavia, se sono presenti dei nodi gratuiti, il nuovo esperimento eseguirà esecuzioni figlio di Machine Learning automatizzate in parallelo nei nodi/macchine virtuali disponibili.
Per gestire le esecuzioni figlio e quando possono essere eseguite, è consigliabile creare un cluster dedicato per esperimento e associare il numero di max_concurrent_iterations dell'esperimento al numero di nodi nel cluster. In questo modo, si usano tutti i nodi del cluster contemporaneamente con il numero di esecuzioni/iterazioni figlio simultanee desiderate.
Configurare max_concurrent_iterations nell'oggetto AutoMLConfig. Se non è configurata, per impostazione predefinita è consentita una sola esecuzione/iterazione figlio simultanea per esperimento.
Nel caso dell'istanza di calcolo, max_concurrent_iterations può essere impostato come uguale al numero di core nella macchina virtuale dell'istanza di calcolo.
Esplorare modelli e metriche
Il Machine Learning automatizzato offre opzioni per monitorare e valutare i risultati del training.
È possibile visualizzare i risultati del training in un widget o inline in un notebook. Per altri dettagli, vedere Monitorare le esecuzioni automatizzate di Machine Learning.
Per definizioni ed esempi dei grafici delle prestazioni e delle metriche fornite per ogni esecuzione, vedere Valutare i risultati dell'esperimento di Machine Learning automatizzato.
Per ottenere un riepilogo delle caratteristiche e comprendere quali funzionalità sono state aggiunte a un modello specifico, vedere Trasparenza delle funzionalità.
È possibile visualizzare gli iperparametri, le tecniche di ridimensionamento e normalizzazione e l'algoritmo applicati a una specifica esecuzione automatica di Machine Learning con la soluzione di codice personalizzata, print_model().
Suggerimento
Il Machine Learning automatizzato consente anche di visualizzare il codice di training del modello generato per i modelli sottoposti a training di Machine Learning automatico. Questa funzionalità è disponibile in anteprima pubblica e può cambiare in qualsiasi momento.
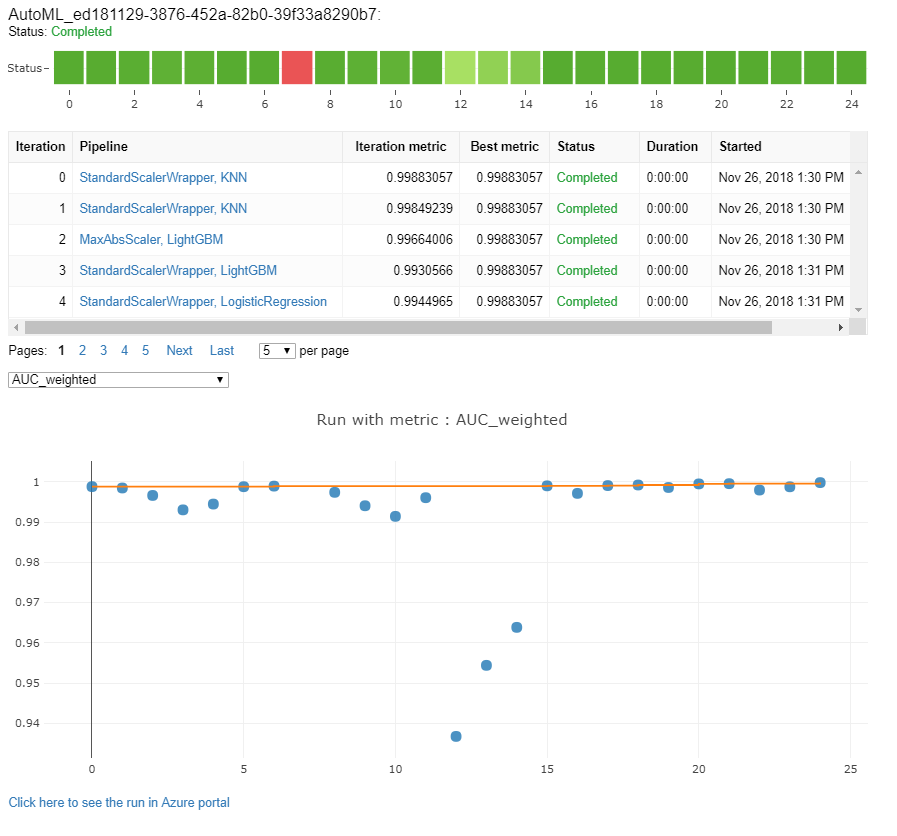
Monitorare le esecuzioni automatizzate di Machine Learning
Per le esecuzioni automatizzate di Machine Learning, per accedere ai grafici da un'esecuzione precedente, sostituire <<experiment_name>> con il nome dell'esperimento appropriato:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Modelli di test (anteprima)
Importante
Il test dei modelli con un set di dati di test per valutare i modelli generati da Machine Learning automatizzato è una funzionalità di anteprima. Questa funzionalità è una funzionalità sperimentale anteprima e può cambiare in qualsiasi momento.
Avviso
Questa funzionalità non è disponibile per gli scenari di Machine Learning automatizzati seguenti
Passando i parametri test_data o test_size in AutoMLConfig, si attiva automaticamente un'esecuzione di test remota che usa i dati di test forniti per valutare il modello migliore consigliato dal Machine Learning automatizzato al completamento dell'esperimento. Questa esecuzione di test remoto viene eseguita alla fine dell'esperimento, una volta determinato il modello migliore. Vedere come passare i dati di test in AutoMLConfig.
Ottenere i risultati del processo di test
È possibile ottenere le stime e le metriche dal processo di test remoto da Azure Machine Learning Studio o con il codice seguente.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Il processo di test del modello genera il file predictions.csv archiviato nell'archivio dati predefinito creato con l'area di lavoro. Questo archivio dati è visibile a tutti gli utenti con la stessa sottoscrizione. I processi di test non sono consigliati per gli scenari se una delle informazioni usate per o create dal processo di test deve rimanere privata.
Testare il modello di Machine Learning automatizzato esistente
Per testare altri modelli esistenti di Machine Learning automatizzato che si sono creati, processi ottimali o processi figlio, usare ModelProxy() per testare un modello dopo il completamento dell'esecuzione dell’AutoML principale. ModelProxy() restituisce già le stime e le metriche e non richiede un'ulteriore elaborazione per recuperare gli output.
Nota
ModelProxy è una classe sperimentale di anteprima e può cambiare in qualsiasi momento.
Il codice seguente illustra come testare un modello da qualsiasi esecuzione usando il metodo ModelProxy.test(). Nel metodo test() è possibile specificare se si vogliono visualizzare solo le stime dell'esecuzione del test con il parametro include_predictions_only.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Registrare e distribuire modelli
Dopo aver testato un modello e aver confermato di voler usarlo nell'ambiente di produzione, è possibile registrarlo per usarlo in un secondo momento e
Per registrare un modello da un'esecuzione automatizzata di Machine Learning, usare il metodo register_model().
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Per informazioni dettagliate su come creare una configurazione di distribuzione e distribuire un modello registrato in un servizio Web, vedere come e dove distribuire un modello.
Suggerimento
Per i modelli registrati, la distribuzione con un clic è disponibile tramite Azure Machine Learning Studio. Vedere come distribuire i modelli registrati dallo studio.
Interpretabilità dei modelli
L'interpretabilità dei modelli consente di comprendere il motivo per cui i modelli hanno eseguito stime e i valori di importanza delle funzionalità sottostanti. L'SDK include diversi pacchetti per abilitare le funzionalità di interpretabilità dei modelli, sia in fase di training che di inferenza, per i modelli locali e distribuiti.
Vedere come abilitare le funzionalità di interpretabilità in modo specifico all'interno di esperimenti automatizzati di Machine Learning.
Per informazioni generali su come abilitare le spiegazioni dei modelli e l'importanza delle funzionalità in altre aree dell'SDK al di fuori del Machine Learning automatizzato, vedere l'articolo relativo al concetto di interpretabilità.
Nota
Il modello ForecastTCN non è attualmente supportato dal client di spiegazione. Questo modello non restituisce un dashboard di spiegazione se viene restituito come modello migliore, e non supporta le esecuzioni di spiegazioni su richiesta.