Pubblicare pipeline di Machine Learning e tenerne traccia
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come condividere una pipeline di Machine Learning con i colleghi o i clienti.
Le pipeline di Machine Learning sono flussi di lavoro riutilizzabili per le attività di Machine Learning. Un vantaggio delle pipeline è la maggiore collaborazione. È anche possibile eseguire pipeline di versione, consentendo ai clienti di usare il modello corrente mentre si sta lavorando a una nuova versione.
Prerequisiti
Creare un'area di lavoro di Azure Machine Learning che conterrà tutte le risorse della pipeline
Configurare l'ambiente di sviluppo per installare Azure Machine Learning SDK o usare un'istanza di ambiente di calcolo di Azure Machine Learning con l'SDK già installato
Creare ed eseguire una pipeline di Machine Learning,per esempio seguendo Esercitazione: Creare una pipeline di Azure Machine Learning per l'assegnazione dei punteggi batch. Per altre opzioni, vedere Creare ed eseguire le pipeline di Machine Learning con Azure Machine Learning SDK
Pubblicare una pipeline
Dopo che una pipeline è in esecuzione, è possibile pubblicare una pipeline in modo che venga eseguita con input diversi. Affinché l'endpoint REST di una pipeline già pubblicata accetti i parametri, è necessario configurarla in modo da usare PipelineParameter oggetti per gli argomenti che variano.
Per creare un parametro per la pipeline, usare un oggetto PipelineParameter con un valore predefinito.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Aggiungere l'oggetto
PipelineParametercome parametro a uno dei passaggi della pipeline, come indicato di seguito:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Pubblicare la pipeline che accetterà un parametro quando richiamata.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Dopo aver pubblicato la pipeline, è possibile archiviarla nell'interfaccia utente. L'ID della pipeline è l'univoco identificato della pipeline pubblicata.


Eseguire una pipeline pubblicata
Tutte le pipeline pubblicate hanno un endpoint REST Con l'endpoint della pipeline, è possibile attivare un'esecuzione della pipeline da qualsiasi sistema esterno, inclusi i client non Python. Questo endpoint consente la "ripetibilità gestita" in scenari di ripetizione del training e assegnazione di punteggi in batch.
Importante
Se, per gestire l'accesso alla pipeline, si usa il controllo degli accessi in base al ruolo di Azure, impostare le autorizzazioni per lo scenario della pipeline (training o punteggio).
Per richiamare l'esecuzione della pipeline precedente, è necessario un token di intestazione di autenticazione di Microsoft Entra. Come ottenere un token di questo tipo è descritto nella classe di riferimento AzureCliAuthentication e nel notebook Authentication in Azure Machine Learning.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
L'argomento json della richiesta POST deve contenere, per la chiave ParameterAssignments, un dizionario contenente i parametri della pipeline e i relativi valori. Inoltre, l'argomento json può contenere le chiavi seguenti:
| Chiave | Descrizione |
|---|---|
ExperimentName |
Nome dell'esperimento associato a questo endpoint |
Description |
Testo freeform che descrive l'endpoint |
Tags |
Coppie chiave-valore freeform che possono essere usate per etichettare e annotare le richieste |
DataSetDefinitionValueAssignments |
Dizionario usato per modificare i set di dati senza ripetere il training (vedere la discussione seguente) |
DataPathAssignments |
Dizionario usato per modificare i percorsi dati senza ripetere il training (vedere la discussione seguente) |
Eseguire una pipeline pubblicata con C#
Il codice seguente illustra come chiamare una pipeline in modo asincrono da C#. Il frammento di codice parziale mostra solo la struttura delle chiamate e non fa parte di un esempio Microsoft. Non mostra classi complete o gestione degli errori.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Eseguire una pipeline pubblicata con Java
Il codice seguente illustra una chiamata a una pipeline che richiede l'autenticazione (vedere Configurare l'autenticazione per le risorse e i flussi di lavoro di Azure Machine Learning). Se la pipeline viene distribuita pubblicamente, non sono necessarie le chiamate che producono authKey. Il frammento di codice parziale non mostra la classe Java e il boilerplate di gestione delle eccezioni. Il codice usa Optional.flatMap per concatenare le funzioni che possono restituire un oggetto vuoto Optional. L'uso di flatMap abbrevia e chiarisce il codice, ma si noti che getRequestBody() si mangia le eccezioni.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Modifica di set di dati e percorsi dati senza ripetere il training
È possibile eseguire il training e l'inferenza in set di dati e percorsi dati diversi. Ad esempio, è possibile eseguire il training su un set di dati più piccolo, ma l'inferenza eseguirla nel set di dati completo. È possibile cambiare set di dati con la chiave DataSetDefinitionValueAssignments nell'argomento json della richiesta. È possibile cambiare percorso dati con DataPathAssignments. La tecnica per entrambi è simile:
Nello script di definizione della pipeline creare un oggetto
PipelineParameterper il set di dati. Creare un oggettoDatasetConsumptionConfigoDataPathdaPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Nello script di Machine Learning accedere al set di dati specificato in modo dinamico usando
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Si noti che lo script di ML accede al valore specificato per (
DatasetConsumptionConfigtabular_dataset) e non al valore diPipelineParameter(tabular_ds_param).Nello script di definizione della pipeline, impostare
DatasetConsumptionConfigcome parametro perPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Per cambiare set di dati in modo dinamico nella chiamata REST di inferenza, usare
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
I notebook Showcasing Dataset e PipelineParameter e Showcasing DataPath e PipelineParameter hanno esempi completi di questa tecnica.
Creare un endpoint della pipeline con versione
È possibile creare un endpoint della pipeline con più pipeline pubblicate dietro di essa. Questa tecnica offre un endpoint REST fisso durante l'iterazione e l'aggiornamento delle pipeline di Machine Learning.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Inviare un processo a un endpoint della pipeline
È possibile inviare un processo alla versione predefinita di un endpoint della pipeline:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
È anche possibile inviare un processo a una versione specifica:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
La stessa operazione può essere eseguita usando l'API REST:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Usare le pipeline pubblicate nello studio
È anche possibile eseguire una pipeline pubblicata da Studio:
Accedere ad Azure Machine Learning Studio.
A sinistra selezionare Endpoint.
Nella parte superiore selezionare Endpoint pipeline.
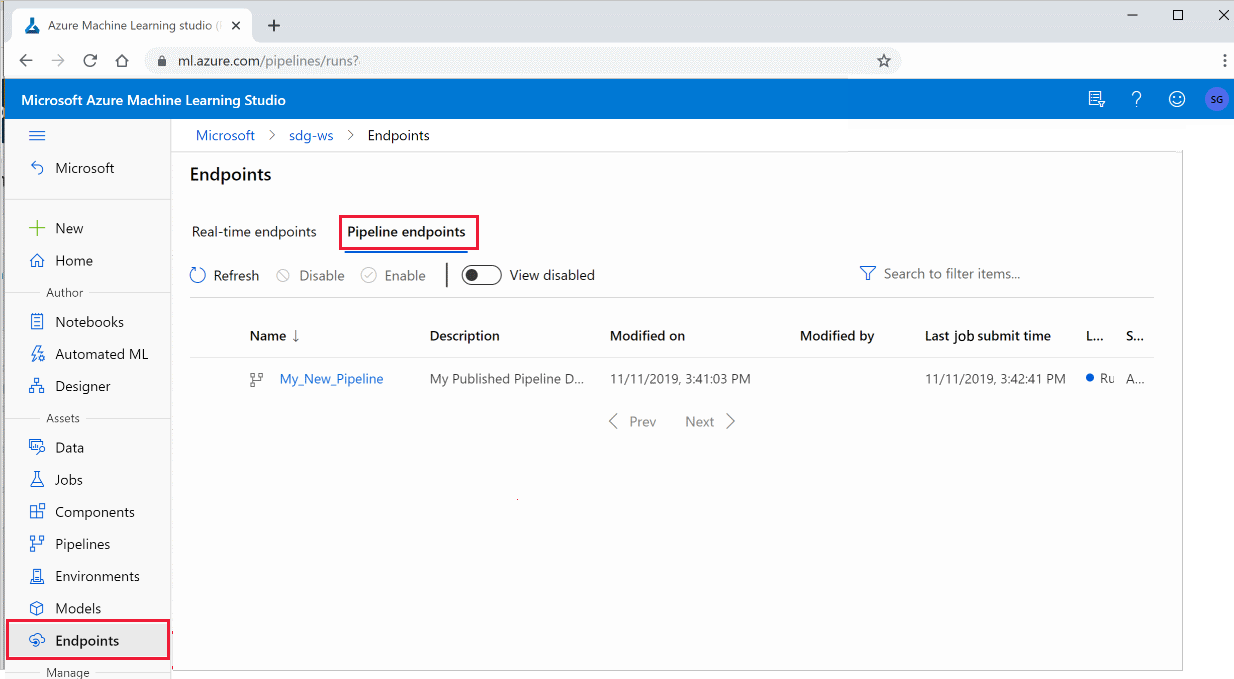
Selezionare una pipeline specifica da eseguire, utilizzare o esaminare i risultati delle esecuzioni precedenti dell'endpoint della pipeline.
Disabilitare una pipeline pubblicata
Per nascondere una pipeline dall'elenco di pipeline pubblicate, disabilitarla in Studio o nell'SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
È possibile abilitarlo di nuovo con p.enable(). Per altre informazioni, vedere Le informazioni di riferimento sulla classe PublishedPipeline.
Passaggi successivi
- Usare questi notebook di Jupyter in GitHub per esplorare più in dettaglio le pipeline di Machine Learning.
- Vedere la guida di riferimento dell'SDK per i pacchetti azureml-pipeline-core e azureml-pipelines-steps.
- Vedere le procedure per suggerimenti sul debug e la risoluzione dei problemi delle pipeline.