Raccogliere dati da modelli in produzione
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Questo articolo illustra come raccogliere dati da un modello di Azure Machine Learning distribuito in un cluster del servizio Azure Kubernetes (AKS). I dati raccolti, quindi, vengono archiviati nell'archivio BLOB di Azure.
Dopo aver abilitato la raccolta, i dati raccolti consentono di:
Monitorare le derive dei dati sui dati di produzione raccolti.
Analizzare i dati raccolti usando Power BI o Azure Databricks
Prendere decisioni migliori su quando ripetere il training o quando ottimizzare il modello.
Ripetere il training del modello con i dati raccolti.
Limiti
- La funzionalità di raccolta dati del modello può funzionare solo con l'immagine Ubuntu 18.04.
Importante
A partire dal 10/03/2023, l'immagine Ubuntu 18.04 è ora deprecata. Il supporto per le immagini Ubuntu 18.04 verrà eliminato a partire da gennaio 2023 quando esso raggiunge l’EOL, il 30 aprile 2023.
La funzionalità MDC non è compatibile con qualsiasi altra immagine diversa da Ubuntu 18.04, che non è disponibile una volta deprecata l'immagine Ubuntu 18.04.
Per altre informazioni che è possibile fare riferimento a:
Nota
La funzionalità di raccolta dati è attualmente in fase di anteprima, tutte le funzionalità di anteprima non sono consigliate per i carichi di lavoro di produzione.
Quali informazioni vengono raccolte e dove sono trasferite
Possono essere raccolti i dati seguenti:
Dati di input del modello provenienti di servizi Web distribuiti in un cluster del servizio Azure Kubernetes. Audio vocale, immagini e video nonvengono raccolti.
Previsioni del modello usando i dati di input di produzione.
Nota
La pre-aggregazione e i pre-calcoli su questi dati attualmente non fanno parte del servizio di raccolta.
L'output viene salvato nell'archivio BLOB. Poiché i dati vengono aggiunti all'archivio BLOB, è possibile scegliere lo strumento preferito per eseguire l'analisi.
La sintassi per il percorso dei dati di output nel BLOB è la seguente:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Nota
Nelle versioni dell’SDK di Azure Machine Learning per Python precedenti alla versione 0.1.0a16, l'argomento designation è denominato identifier. Se il codice è stato sviluppato con una versione precedente, è necessario aggiornarlo.
Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
È necessario installare un'area di lavoro di Azure Machine Learning, una directory locale contenente gli script e l’SDK Python di Azure Machine Learning. Per informazioni su come installarli, vedere Come configurare un ambiente di sviluppo.
È necessario un modello di Machine Learning sottoposto a training da distribuire nel servizio Azure Kubernetes. Se non è disponibile un modello, vedere l'esercitazione Eseguire il training di un modello di classificazione immagini.
È necessario un cluster del servizio Azure Kubernetes. Per informazioni su come crearne uno e distribuirlo, vedere Distribuire modelli di Machine Learning in Azure.
Configurare l'ambiente e installare Azure Machine Learning Monitoring SDK.
Usare un'immagine Docker basata su Ubuntu 18.04 fornita con
libssl 1.0.0, la dipendenza essenziale di modeldatacollector. È possibile fare riferimento alle immagini predefinite.
Abilitare la raccolta dati
È possibile abilitare la raccolta dati indipendentemente dal modello distribuito tramite Azure Machine Learning o altri strumenti.
Per abilitare la raccolta dati, è necessario:
Aprire il file di assegnazione dei punteggi.
Aggiungere il codice seguente all'inizio del file:
from azureml.monitoring import ModelDataCollectorDichiarare le variabili per la raccolta dei dati nella funzione
init:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId è un parametro facoltativo. Non è necessario usarlo se il modello non lo richiede. L'uso di CorrelationId facilita il mapping con altri dati, ad esempio LoanNumber o CustomerId.
Il parametro Identifier viene usato successivamente per la generazione della struttura di cartelle nel BLOB. È possibile usarlo per distinguere dati non elaborati da quelli elaborati.
Aggiungere le righe di codice seguenti alla funzione
run(input_df):data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobLa raccolta dati non viene impostata automaticamente su true quando si distribuisce un servizio nel servizio Azure Kubernetes. Aggiornare il file di configurazione come indicato nell'esempio seguente:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)È anche possibile abilitare Application Insights per il monitoraggio del servizio modificando questa configurazione:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Per creare una nuova immagine e distribuire il modello di Machine Learning, vedere Distribuire modelli di Machine Learning in Azure.
Aggiungere il pacchetto pip "Azure-Monitoring" alle dipendenze conda dell'ambiente del servizio Web:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Disabilitare la raccolta dei dati
È possibile arrestare la raccolta dei dati in qualunque momento. Usare il codice Python per disabilitare la raccolta dati.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Convalidare e analizzare i dati
È possibile scegliere lo strumento preferito per analizzare i dati raccolti nell'archivio BLOB.
Accesso rapido ai dati BLOB
Accedi al portale di Azure.
Aprire l'area di lavoro.
Selezionare Archiviazione.

Seguire il percorso dei dati di output di BLOB con questa sintassi:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analizzare i dati del modello con Power BI
Scaricare e aprire Power BI Desktop.
Selezionare Recupera dati, quindi selezionare Archiviazione BLOB di Azure.

Aggiungere il nome dell'account di archiviazione e immettere la chiave di archiviazione. È possibile trovare queste informazioni selezionando Impostazioni>Chiavi di accesso nel BLOB.
Selezionare il contenitore di dati del modello e selezionare Modifica.
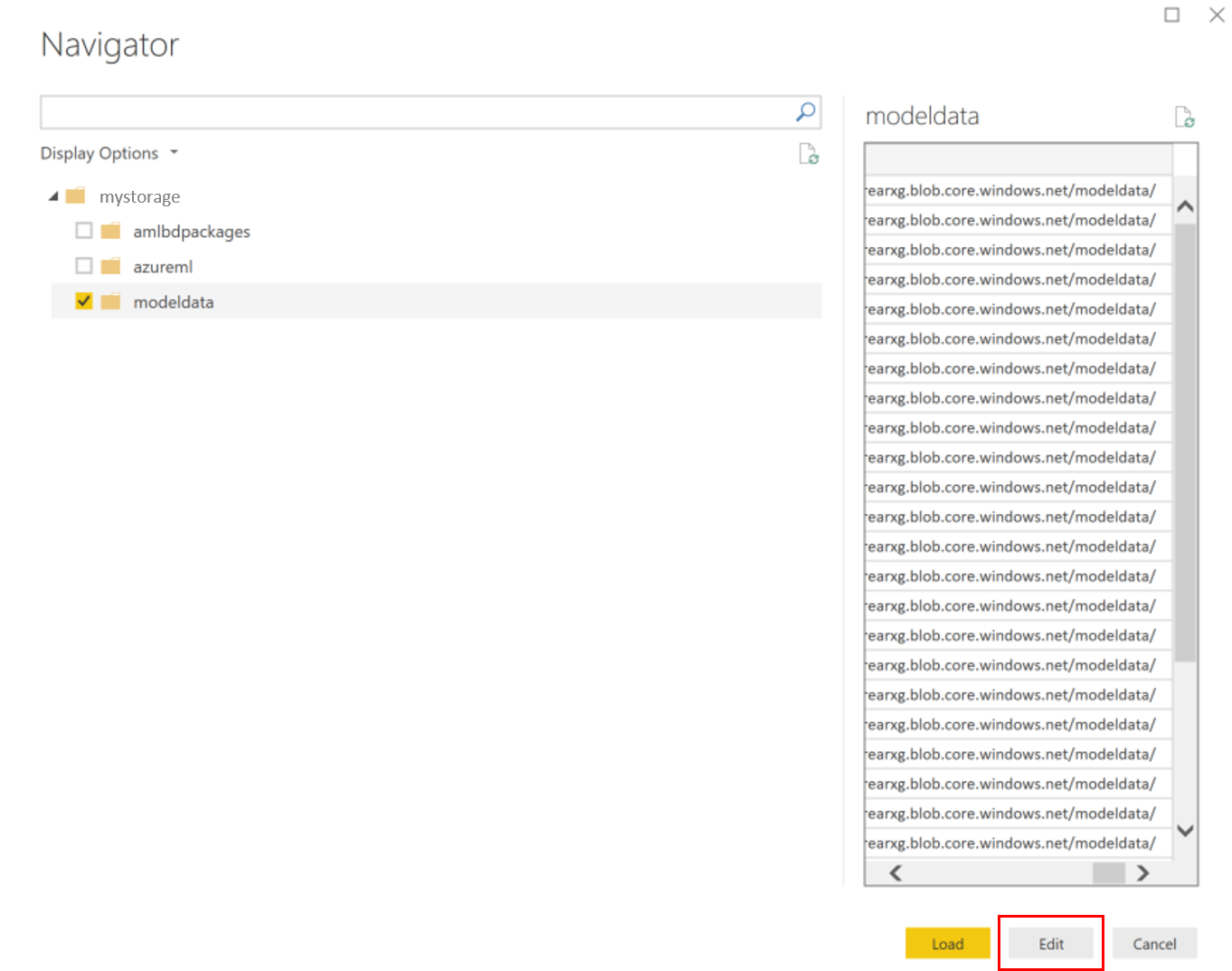
Nell'editor di query, fare clic sotto la colonna Nome e aggiungere il proprio account di archiviazione.
Immettere il percorso del modello nel filtro. Per esaminare solo i file di un anno o un mese specifico, basta espandere il percorso di filtro. Ad esempio, per esaminare solo i dati di marzo, usare questo percorso di filtro:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Filtrare i dati pertinenti in base ai valori Nome. Se sono stati archiviati input e stime, è necessario creare una query per ognuno.
Selezionare le doppie frecce verso il basso accanto all'intestazione di colonna Contenuto per combinare i file.

Seleziona OK. I dati vengono precaricati.

Seleziona Chiudi e applica.
Se sono stati aggiunti input e stime, le tabelle verranno ordinate automaticamente in base ai valori RequestId.
Iniziare a creare report personalizzati per i dati del modello.




Analizzare i dati del modello con Azure Databricks
Creare un'area di lavoro di Azure Databricks.
Passare all'area di lavoro di Databricks.
Nell'area di lavoro di Databricks selezionare Carica dati.

Selezionare Crea nuova tabella, quindi selezionare Altre origini dati>Archiviazione BLOB di Azure>Crea tabella in notebook.

Aggiornare il percorso dei dati. Ecco un esempio:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"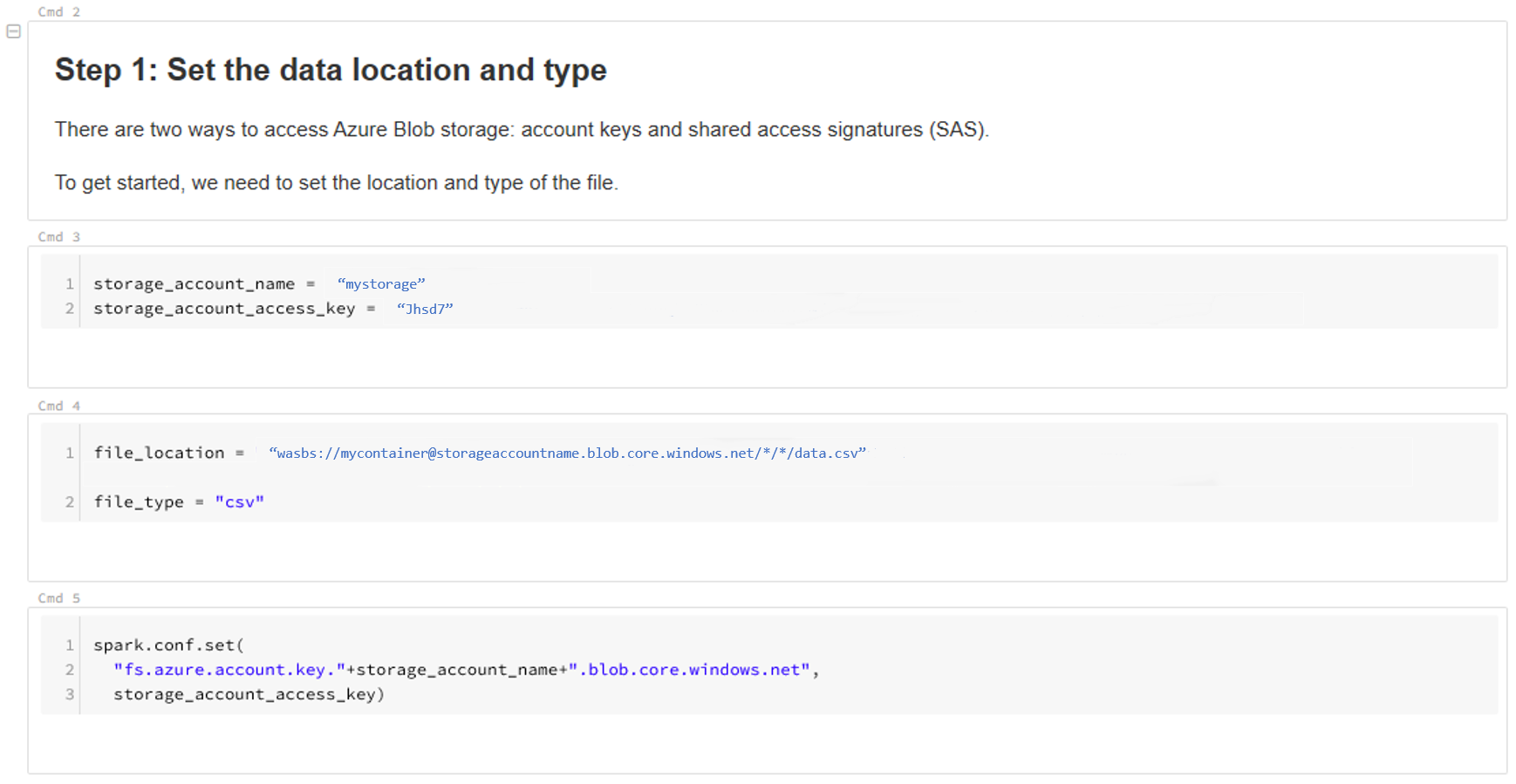
Seguire la procedura del modello per visualizzare e analizzare i dati.



Passaggi successivi
Rilevare la deriva dei dati sui dati raccolti.