Usare i parametri della pipeline per ripetere il training dei modelli nella finestra di progettazione
Questo articolo illustra come usare la finestra di progettazione di Azure Machine Learning per ripetere il training di un modello di Machine Learning usando i parametri della pipeline. Verranno usate le pipeline pubblicate per automatizzare il flusso di lavoro e impostare i parametri per eseguire il training del modello con i nuovi dati. I parametri della pipeline consentono di riutilizzare le pipeline esistenti per processi diversi.
In questo articolo vengono illustrate le operazioni seguenti:
- Eseguire il training di un modello di Machine Learning.
- Creare un parametro della pipeline.
- Pubblicare la pipeline di training.
- Ripetere il training del modello con nuovi parametri.
Prerequisiti
- Area di lavoro di Azure Machine Learning
- Completare la parte 1 di questa serie di procedure, Trasformare i dati nella finestra di progettazione
Importante
Se gli elementi grafici citati in questo documento non vengono visualizzati, ad esempio i pulsanti di Studio o della finestra di progettazione, è possibile che non si abbia il livello di autorizzazioni appropriato per l'area di lavoro. Contattare l'amministratore della sottoscrizione di Azure per verificare che sia stato concesso il livello di accesso corretto. Per altre informazioni, vedere Gestire utenti e ruoli.
Questo articolo presuppone anche che l'utente abbia conoscenze di base sulla creazione di pipeline nella finestra di progettazione. Per un'introduzione guidata, eseguire l'esercitazione.
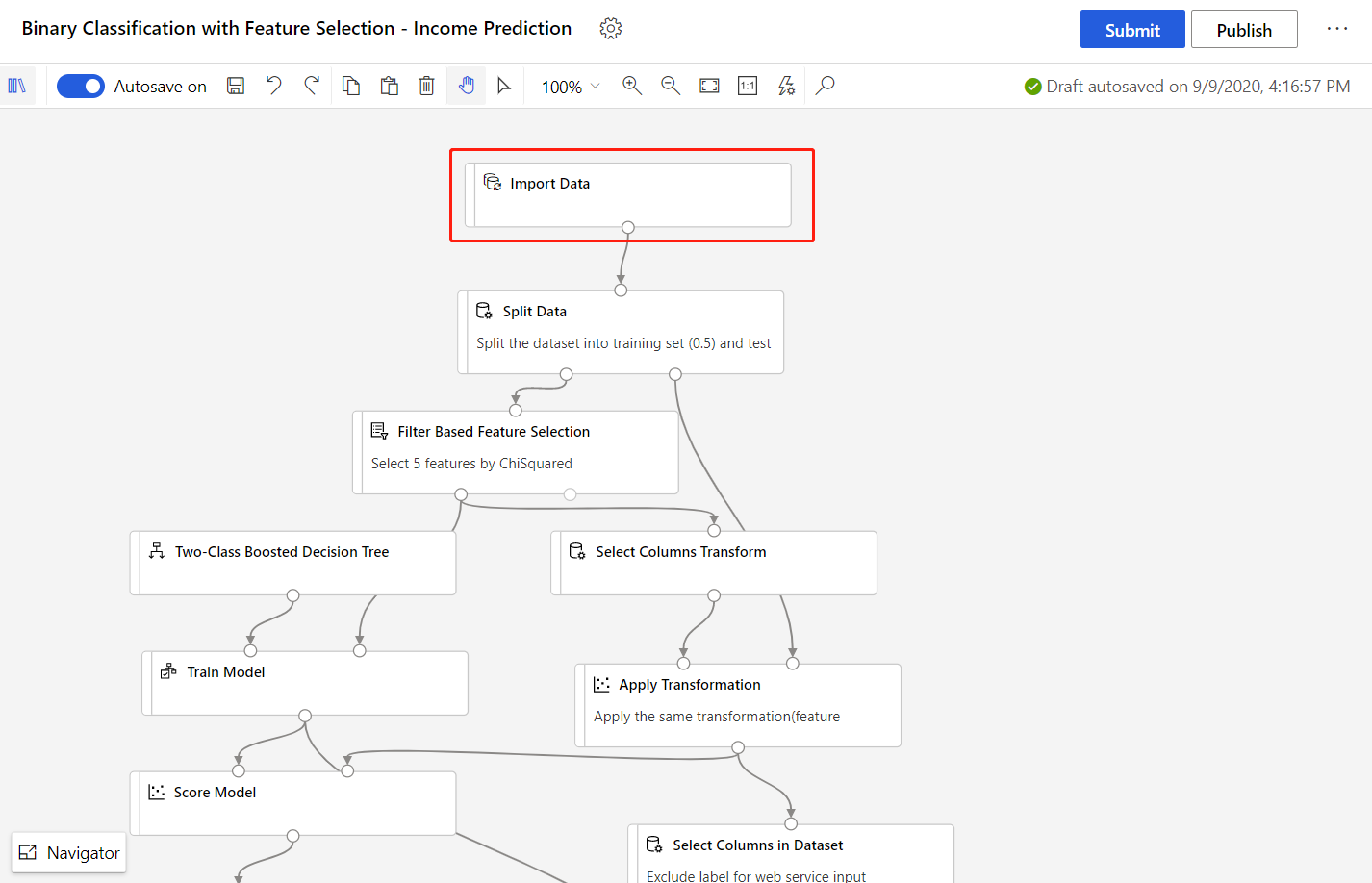
Pipeline di esempio
La pipeline usata in questo articolo è una versione modificata di una pipeline di esempio Previsione del reddito nella homepage della finestra di progettazione. La pipeline usa il componente Importa dati anziché il set di dati di esempio per illustrare come eseguire il training dei modelli con i propri dati.
Creare un parametro della pipeline
I parametri della pipeline vengono usati per creare pipeline versatili che possono essere inviate di nuovo in seguito con valori di parametro variabili. Alcuni scenari comuni sono l'aggiornamento dei set di dati o di alcuni iper parametri per la ripetizione del training. Creare i parametri della pipeline per impostare dinamicamente le variabili durante il runtime.
I parametri della pipeline possono essere aggiunti ai parametri dell'origine dati o del componente in una pipeline. Quando la pipeline viene inviata di nuovo, è possibile specificare i valori di questi parametri.
Per questo esempio, il percorso dei dati di training verrà modificato da un valore fisso a un parametro in modo che sia possibile ripetere il training del modello con dati diversi. È anche possibile aggiungere altri parametri del componente come parametri della pipeline, in base al caso d'uso.
Selezionare il componente Importa dati.
Nota
Questo esempio usa il componente Importa dati per accedere ai dati di un archivio dati registrato. Tuttavia, se si usano modelli di accesso ai dati alternativi, è possibile seguire una procedura simile.
Nel riquadro dei dettagli del componente, a destra del canvas, selezionare l'origine dati.
Immettere il percorso dei dati. È anche possibile selezionare Browse path (Sfoglia percorso) per esplorare l'albero dei file.
Passare il mouse sul campo Path (Percorso) e selezionare i tre punti visualizzati sopra il campo Path (Percorso).
Selezionare Add to pipeline parameter (Aggiungi a parametro pipeline).
Specificare un nome di parametro e un valore predefinito.
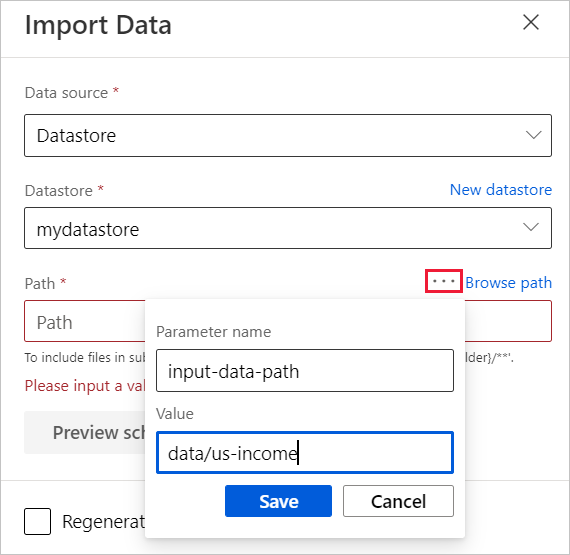
Seleziona Salva.
Nota
È anche possibile rimuovere un parametro del componente dal parametro della pipeline nel riquadro dei dettagli del componente, in modo analogo all'aggiunta di parametri della pipeline.
È possibile esaminare e modificare i parametri della pipeline selezionando l'icona a forma di ingranaggio Settings (Impostazioni) accanto al titolo della bozza della pipeline.
- Dopo la rimozione, è possibile eliminare il parametro della pipeline nel riquadro Impostazioni.
- È anche possibile aggiungere un parametro della pipeline nel riquadro Impostazioni e poi applicarlo a qualche parametro del componente.
Inviare il processo della pipeline.
Pubblicare una pipeline di training
Pubblicare una pipeline in un endpoint della pipeline per riutilizzare facilmente le pipeline in futuro. Un endpoint della pipeline crea un endpoint REST per richiamare la pipeline in futuro. In questo esempio, l'endpoint della pipeline consente di riutilizzare la pipeline per ripetere il training di un modello con dati diversi.
Selezionare Publish (Pubblica) sopra il canvas della finestra di progettazione.
Selezionare o creare un endpoint della pipeline.
Nota
È possibile pubblicare più pipeline in un singolo endpoint. A ogni pipeline di un determinato endpoint viene assegnato un numero di versione che è possibile specificare quando si chiama l'endpoint della pipeline.
Selezionare Pubblica.
Ripetere il training del modello
Ora che è disponibile una pipeline di training pubblicata, è possibile usarla per ripetere il training del modello con i nuovi dati. È possibile inviare i processi da un endpoint della pipeline dall'area di lavoro di Studio o a livello di codice.
Inviare i processi usando il portale di Studio
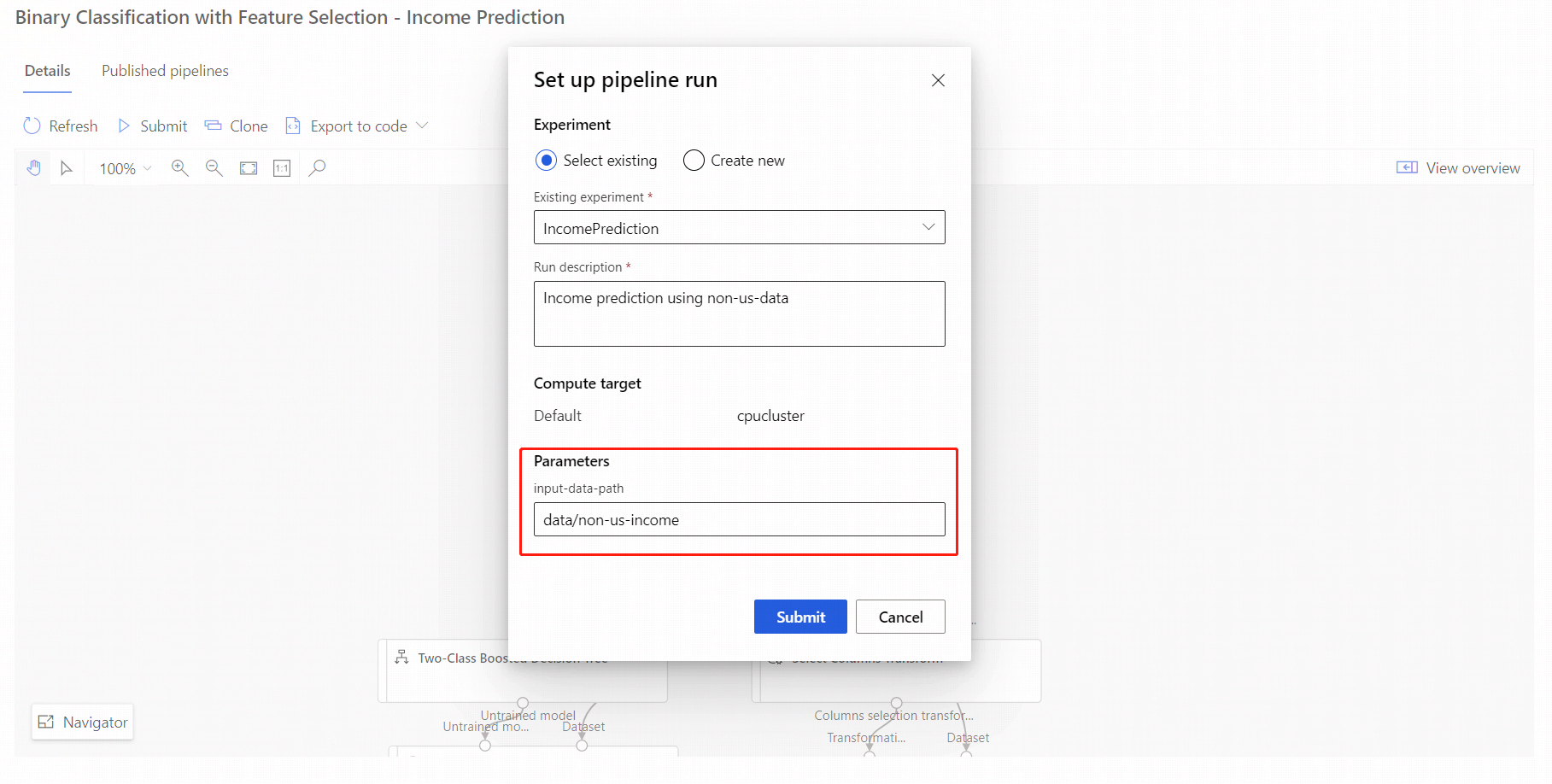
Usare la procedura seguente per inviare un processo dell'endpoint della pipeline con parametri dal portale di Studio:
- Passare alla pagina Endpoints (Endpoint) nell'area di lavoro di Studio.
- Selezionare la scheda Pipeline endpoints (Endpoint pipeline). Quindi selezionare l'endpoint della pipeline.
- Selezionare la scheda Published pipelines (Pipeline pubblicate). Quindi selezionare la versione della pipeline che si vuole eseguire.
- Selezionare Invia.
- Nella finestra di dialogo di configurazione è possibile specificare i valori dei parametri per il processo. Per questo esempio, aggiornare il percorso dei dati per eseguire il training del modello usando un set di dati diverso da US.
Inviare processi usando il codice
L'endpoint REST di una pipeline pubblicata è disponibile nel pannello di panoramica. Chiamando l'endpoint è possibile ripetere il training della pipeline pubblicata.
Per eseguire una chiamata REST è necessaria un'intestazione di autenticazione di tipo bearer token OAuth 2.0. Per informazioni sulla configurazione dell'autenticazione all'area di lavoro e sull'esecuzione di una chiamata REST con parametri, vedere Usare REST per gestire le risorse.
Passaggi successivi
In questo articolo si è appreso come creare un endpoint della pipeline di training con parametri usando la finestra di progettazione.
Per la procedura dettagliata completa per distribuire un modello per eseguire stime, vedere l'esercitazione con la finestra di progettazione per eseguire il training e la distribuzione di un modello di regressione.
Per informazioni su come pubblicare e inviare un processo all'endpoint della pipeline usando l'SDK v1, vedere Pubblicare pipeline.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per