Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A:  SDK Python azure-ai-ml v2 (corrente)
SDK Python azure-ai-ml v2 (corrente)
In questa esercitazione, farai:
- Caricare i dati nell'archiviazione nel cloud
- Creare un asset di dati di Azure Machine Learning
- Accedere ai dati in un notebook per lo sviluppo interattivo
- Creare nuove versioni degli asset di dati
Un progetto di apprendimento automatico in genere inizia con l'analisi esplorativa dei dati (EDA), la pre-elaborazione dei dati (pulizia, ingegneria delle funzionalità) e lo sviluppo di prototipi di modelli di machine learning per convalidare le ipotesi. Questa fase di creazione di prototipi del progetto è altamente interattiva e si presta allo sviluppo in un notebook Jupyter o in un IDE con una console interattiva Python. Questa esercitazione descrive questi concetti.
Prerequisiti
-
Per usare Azure Machine Learning, è necessaria un'area di lavoro. Se non è disponibile, completare Creare le risorse necessarie per iniziare per creare un'area di lavoro e ottenere maggiori informazioni su come usarla.
Importante
Se l'area di lavoro di Azure Machine Learning è configurata con una rete virtuale gestita, potrebbe essere necessario aggiungere regole in uscita per consentire l'accesso ai repository di pacchetti Python pubblici. Per altre informazioni, vedere Scenario: accedere ai pacchetti di apprendimento automatico pubblici.
-
Accedere allo studio e selezionare l'area di lavoro, se non è già aperta.
-
Aprire o creare un nuovo notebook nell'area di lavoro:
- Se si vuole copiare e incollare il codice nelle celle, creare un nuovo notebook.
- In alternativa, aprire tutorials/get-started-notebooks/explore-data.ipynb dalla sezione Esempi dello studio. Selezionare quindi Clona per aggiungere il notebook in File. Per trovare notebook di esempio, vedere Apprendere da notebook di esempio.
Impostare il kernel e aprirlo in Visual Studio Code (VS Code)
Nella barra superiore sopra il notebook aperto creare un'istanza di ambiente di calcolo, se non ne è già disponibile una.

Se l'istanza di calcolo viene arrestata, selezionare Avviare ambiente di calcolo e attendere fino a quando non è in esecuzione.

Attendere che l'istanza di ambiente calcolo sia in esecuzione. Assicurarsi quindi che il kernel situato in alto a destra sia
Python 3.10 - SDK v2. In caso contrario, usare l'elenco a discesa per selezionare questo kernel.
Se questo kernel non viene visualizzato, verificare che l'istanza di ambiente di calcolo sia in esecuzione. In caso affermativo, selezionare il pulsante Aggiorna in alto a destra del notebook.
Se viene visualizzato un banner che indica che è necessario eseguire l'autenticazione, selezionare Autentica.
È possibile eseguire il notebook qui o aprirlo in VS Code per usare un ambiente di sviluppo integrato (IDE) completo con la potenza delle risorse di Azure Machine Learning. Selezionare Apri in VS Code, quindi selezionare l'opzione Web o desktop. Quando viene avviato in questo modo, VS Code viene collegato all'istanza di ambiente di calcolo, al kernel e al file system dell'area di lavoro.





Importante
La parte rimanente di questa esercitazione contiene le celle del notebook dell'esercitazione. Copiarle e incollarle nel nuovo notebook oppure passare al notebook, se è stato clonato.
Scaricare i dati usati in questa esercitazione
Per l'inserimento dati, Esplora dati di Azure gestisce i dati non elaborati in questi formati. Questa esercitazione usa un esempio di dati client con carta di credito in formato CSV. La procedura viene eseguita in una risorsa di Azure Machine Learning. In tale risorsa si crea una cartella locale con il nome suggerito dei dati, direttamente nella cartella in cui si trova il notebook.
Note
Questa esercitazione dipende dai dati inseriti in un percorso di cartella della risorsa di Azure Machine Learning. Per questa esercitazione, 'locale' significa un percorso di cartella in tale risorsa di Azure Machine Learning.
Selezionare Apri terminale sotto i tre puntini, come illustrato in questa immagine:
La finestra del terminale viene aperta in una nuova scheda.
Assicurarsi di modificare la directory (
cd) nella stessa cartella in cui si trova questo notebook. Ad esempio, se il notebook si trova in una cartella denominata get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedImmettere questi comandi nella finestra del terminale per copiare i dati nell'istanza di ambiente di calcolo:
mkdir data cd data # the subfolder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvÈ ora possibile chiudere la finestra del terminale.
Per altre informazioni sui dati nel repository di Machine Learning di UC Irvine, visitare questa risorsa.
Creare un handle per l'area di lavoro
Prima di esplorare il codice, è necessario un modo per fare riferimento all'area di lavoro. Si crea ml_client come handle per l'area di lavoro. Sarà quindi possibile usare ml_client per gestire le risorse e i processi.
Nella cella successiva immettere l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi valori:
- In alto a destra nella barra degli strumenti di Azure Machine Learning Studio selezionare il nome dell'area di lavoro.
- Copiare i valori per l'area di lavoro, il gruppo di risorse e l'ID sottoscrizione nel codice.
- È necessario copiare ogni valore singolarmente, uno alla volta. Chiudere l'area, incollare il valore, quindi continuare con quello successivo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Note
La creazione di MLClient non si connetterà all'area di lavoro. L'inizializzazione del client è differita e attenderà fino a quando sarà necessario effettuare una chiamata. Ciò si verifica nella cella di codice successiva.
Caricare i dati nell'archiviazione cloud
Azure Machine Learning usa URI (Uniform Resource Identifier) che puntano alle posizioni di archiviazione nel cloud. Un URI semplifica l'accesso ai dati nei notebook e nei processi. I formati URI dati sono simili agli URL Web usati nel Web browser per accedere alle pagine Web. Ad esempio:
- Accedere ai dati dal server https pubblico:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Accedere ai dati da Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Un asset di dati di Azure Machine Learning è simile ai segnalibri (preferiti) del Web browser. Invece di ricordare percorsi di archiviazione lunghi (URI) che puntano ai dati usati più di frequente, è possibile creare un asset di dati e quindi accedere a tale asset con un nome descrittivo.
Creando un asset di dati, si crea anche un riferimento alla posizione dell'origine dati insieme a una copia dei relativi metadati. Poiché i dati rimangono nella posizione esistente, non vengono addebitati costi di archiviazione aggiuntivi e non si rischia l'integrità dell'origine dati. È possibile creare asset di dati da archivi dati di Azure Machine Learning, Archiviazione di Azure, URL pubblici e file locali.
Suggerimento
Per i caricamenti di dati più piccoli, la creazione di asset di dati di Azure Machine Learning è ideale per caricare i dati dalle risorse del computer locale all'archiviazione cloud. Questo approccio evita la necessità di strumenti o utilità aggiuntivi. Tuttavia, i caricamenti di dati di dimensioni maggiori potrebbero richiedere uno strumento o un'utilità dedicata, ad esempio azcopy. Lo strumento da riga di comando azcopy sposta i dati da e verso Archiviazione di Azure. Per altre informazioni su azcopy, vedere Introduzione ad AzCopy.
La cella del notebook successiva crea l'asset di dati. L'esempio di codice carica il file di dati non elaborato nella risorsa di archiviazione nel cloud designata.
Ogni volta che si crea un asset di dati, è necessaria una versione univoca. Se la versione esiste già, viene visualizzato un errore. In questo codice si usa "initial" per la prima lettura dei dati. Se tale versione esiste già, il codice non lo ricrea.
È possibile omettere il parametro version. In questo caso, viene generato automaticamente un numero di versione, a partire da 1 e incrementando da questa posizione.
In questa esercitazione viene usato il nome "initial" come prima versione. L'esercitazione Creare pipeline di Machine Learning di produzione usa anche questa versione dei dati, quindi si usa un valore visualizzato di nuovo in tale esercitazione.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# Update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# Set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Per esaminare i dati caricati, selezionare Dati nella sezione Asset del menu di spostamento a sinistra. I dati vengono caricati e viene creato un asset di dati:

Questi dati sono denominati carta di credito. Nella scheda Asset di dati è possibile visualizzarli nella colonna Nome.
Un archivio dati di Azure Machine Learning funge da riferimento per un account di archiviazione di Azure esistente. Un archivio dati offre i vantaggi seguenti:
Un'API comune e facile da usare per interagire con diversi tipi di archiviazione:
- Azure Data Lake Storage
- BLOB
- File
e metodi di autenticazione.
Un modo più semplice per individuare archivi dati utili quando si lavora come team.
Negli script, un modo per nascondere le informazioni di connessione per l'accesso ai dati basato sulle credenziali (entità servizio/firma di accesso condiviso/chiave).
Accedere ai dati in un notebook
Si vogliono creare asset di dati per i dati a cui si accede di frequente. È possibile accedere ai dati usando l'URI come descritto in Accedere ai dati da un URI dell'archivio dati come si farebbe con un file system. Tuttavia, come accennato in precedenza, può diventare difficile ricordare questi URI.
Un'alternativa consiste nell'usare la libreria azureml-fsspec, che fornisce un'interfaccia di file system per gli archivi dati di Azure Machine Learning. Questo è un modo più semplice per accedere al file CSV in Pandas:
Importante
In una cella del notebook eseguire questo codice per installare la libreria Python azureml-fsspec nel kernel Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# Read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Per altre informazioni sull'accesso ai dati in un notebook, vedere Accedere ai dati dall'archiviazione cloud di Azure durante lo sviluppo interattivo.
Creare una nuova versione dell'asset di dati
I dati hanno bisogno di una pulizia leggera per renderli adatti al training di un modello di Machine Learning. Le sue caratteristiche sono:
- Due intestazioni
- Colonna ID client che non verrebbe usata come funzionalità in Machine Learning
- Spazi nel nome della variabile di risposta
Inoltre, rispetto al formato CSV, il formato di file Parquet è un modo migliore per archiviare questi dati. Parquet offre compressione e mantiene lo schema. Per pulire i dati e archiviarli in formato Parquet:
# Read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# Rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# Remove ID column
df.drop("ID", axis=1, inplace=True)
# Write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Questa tabella mostra la struttura dei dati nel file default_of_credit_card_clients.csv originale scaricato in un passaggio precedente. I dati caricati contengono 23 variabili esplicative e 1 variabile di risposta, come illustrato di seguito:
| Nomi colonna | Tipo di variabile | Descrizione |
|---|---|---|
| X1 | Esplicativa | Importo del credito specificato (dollaro NT): include sia il credito del singolo consumatore che il credito familiare (supplementare). |
| X2 | Esplicativa | Sesso (1 = maschio; 2 = femmina). |
| X3 | Esplicativa | Istruzione (1 = master; 2 = università; 3 = scuola superiore; 4 = altri). |
| X4 | Esplicativa | Stato coniugale (1 = sposato; 2 = single; 3 = altri). |
| X5 | Esplicativa | Età (anni). |
| X6-X11 | Esplicativa | Cronologia del pagamento precedente. I record di pagamento mensili precedenti sono stati registrati da aprile a settembre 2005. -1 = pagamenti regolari; 1 = ritardo di pagamento per un mese; 2 = ritardo di pagamento per due mesi; . . .; 8 = ritardo di pagamento per otto mesi; 9 = ritardo di pagamento per nove mesi e superiori. |
| X12-17 | Esplicativa | Importo dell'estratto conto (dollaro NT) da aprile a settembre 2005. |
| X18-23 | Esplicativa | Importo del pagamento precedente (dollaro NT) da aprile a settembre 2005. |
| Sì | Risposta | Pagamento predefinito (Sì = 1, No = 0) |
Successivamente, creare una nuova versione dell'asset di dati. I dati vengono caricati automaticamente nell'archiviazione cloud. Per questa versione, aggiungere un valore di ora in modo che ogni volta che viene eseguito il codice, viene creato un numero di versione diverso.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new version of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## Create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Il file Parquet pulito è l'origine dati della versione più recente. Questo codice mostra prima il set di risultati della versione CSV, quindi la versione Parquet:
import pandas as pd
# Get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# Print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# Print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Pulire le risorse
Se si prevede di continuare con altre esercitazioni, procedere direttamente a Passaggi successivi.
Arrestare l'istanza di ambiente di calcolo
Se non si prevede di usarlo ora, arrestare l'istanza di ambiente di calcolo:
- Nel riquadro sinistro dello studio selezionare Calcolo.
- Nelle schede in alto selezionare Istanze di ambiente di calcolo.
- Selezionare l'istanza di ambiente di calcolo nell'elenco.
- Nella barra degli strumenti in alto, selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se le risorse create non servono più, eliminarle per evitare addebiti:
Nella casella di ricerca della portale di Azure immettere Gruppi di risorse e selezionarlo nei risultati.
Nell'elenco selezionare il gruppo di risorse creato.
Nella pagina Panoramica selezionare Elimina gruppo di risorse.
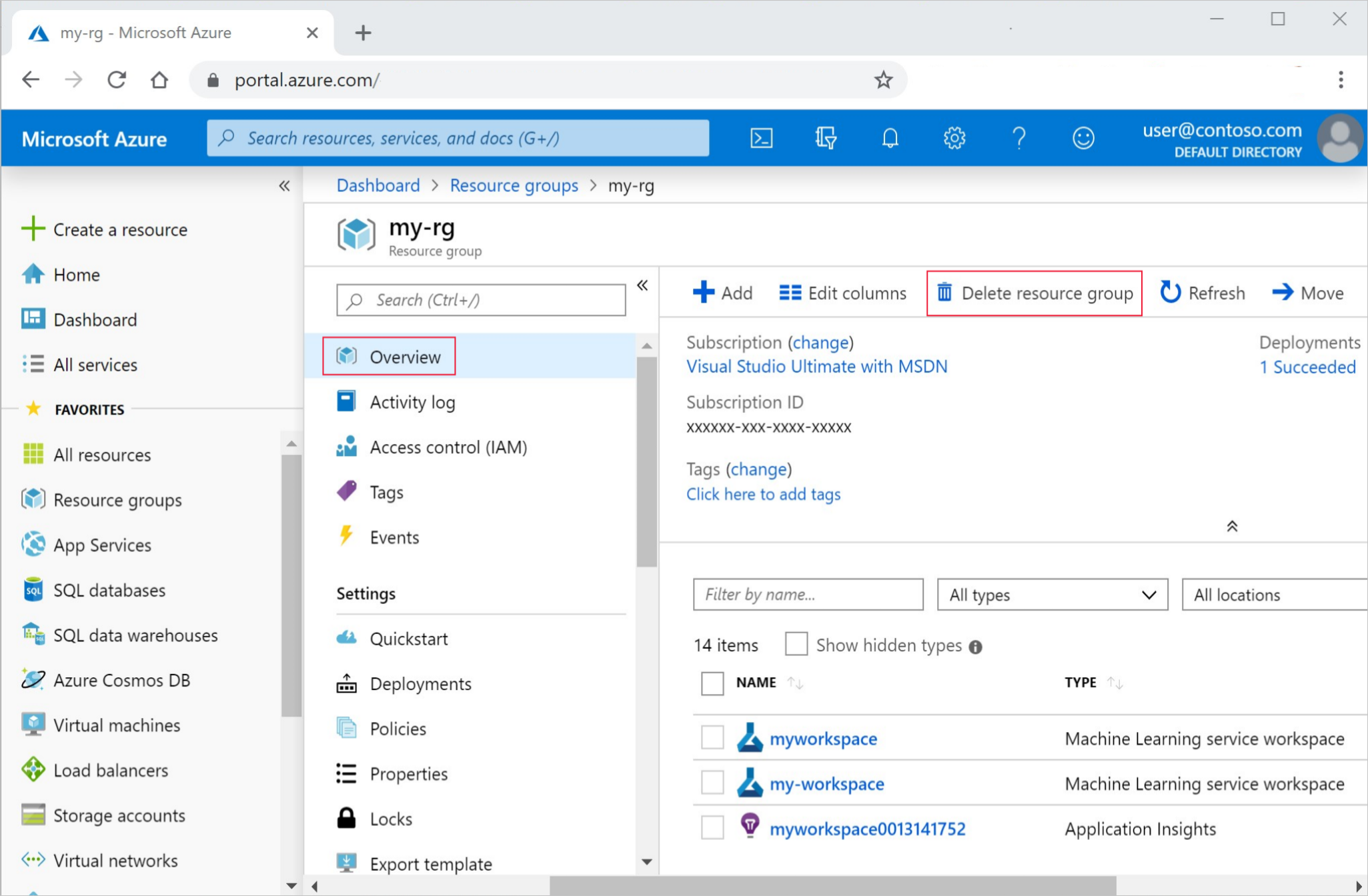
Immettere il nome del gruppo di risorse. Selezionare Elimina.
Passaggi successivi
Per altre informazioni sugli asset di dati, vedere l'articolo Creare gli asset di dati.
Per altre informazioni sugli archivi dati, vedere Creare archivi dati.
Continuare con l'esercitazione successiva per informazioni su come sviluppare uno script di training: