Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo contiene il supporto per il ripristino di emergenza tra aree e il e per la continuità aziendale per Gestione traffico di Azure.
Ripristino di emergenza e continuità aziendale tra aree
Il ripristino di emergenza si riferisce alle procedure usate dalle organizzazioni per il ripristino da eventi ad alto impatto, ad esempio calamità naturali o distribuzioni non riuscite che comportano tempi di inattività e perdita di dati. Indipendentemente dalla causa, il miglior rimedio per un'emergenza è un piano di ripristino di emergenza ben definito e testato e una progettazione di applicazioni che supporta attivamente tale ripristino. Prima di iniziare a creare il piano di ripristino di emergenza, vedere Raccomandazioni per la progettazione di una strategia di ripristino di emergenza.
Per il ripristino di emergenza, Microsoft usa il modello di responsabilità condivisa. In questo modello Microsoft garantisce che siano disponibili l'infrastruttura di base e i servizi della piattaforma. Tuttavia, molti servizi di Azure non replicano automaticamente i dati o non eseguono il fallback da un'area non riuscita per eseguire la replica incrociata in un'altra area abilitata. Per questi servizi, si è responsabili della configurazione di un piano di ripristino di emergenza che funzioni per il carico di lavoro. La maggior parte dei servizi eseguiti nelle offerte PaaS (Platform as a Service) di Azure offre funzionalità e indicazioni per supportare il ripristino di emergenza. È possibile usare funzionalità specifiche del servizio per supportare il ripristino rapido per sviluppare il piano di ripristino di emergenza.
Gestione traffico di Azure è un servizio di bilanciamento del carico del traffico basato su DNS che consente di distribuire il traffico alle applicazioni pubbliche tra aree di Azure globali. Gestione traffico fornisce anche disponibilità elevata e velocità di risposta rapida agli endpoint pubblici.
Gestione traffico usa DNS per indirizzare le richieste dei client all'endpoint di servizio più appropriato in base a un metodo di routing del traffico. Gestione traffico fornisce anche il monitoraggio dello stato per ogni endpoint. L'endpoint può essere qualsiasi servizio con connessione Internet ospitato all'interno o all'esterno di Azure. Gestione traffico offre diversi metodi di routing del traffico e opzioni di monitoraggio degli endpoint per soddisfare le diverse esigenze delle applicazioni e i modelli di failover automatico. Gestione traffico è resiliente agli errori, incluso l'errore di un'intera area di Azure.
Ripristino di emergenza nella geografia in più aree
DNS è uno dei meccanismi più efficienti per deviare il traffico di rete. DNS è efficiente perché DNS è spesso globale ed esterno al data center. DNS è inoltre isolato da eventuali errori a livello di area o di zona di disponibilità (AZ).
Per configurare un'architettura di ripristino di emergenza è possibile adottare due diverse strategie:
Uso di un meccanismo di distribuzione per replicare le istanze, i dati e le configurazioni tra l'ambiente primario e quello di standby. Questo tipo di ripristino di emergenza può essere eseguito in modo nativo tramite Azure Site Recovery; vedere la documentazione di Azure Site Recovery tramite appliance/servizi partner di Microsoft Azure, ad esempio Veritas o NetApp.
Sviluppo di una soluzione per deviare il traffico Web o di rete dal sito primario a quello di standby. Questo tipo di ripristino di emergenza può essere ottenuto tramite DNS di Azure, Gestione traffico di Azure (DNS) o software di bilanciamento del carico globale di terze parti.
Questo articolo è incentrato in particolare sulla pianificazione del ripristino di emergenza di Gestione traffico di Azure.
Rilevamento, notifica e gestione di interruzioni
Durante un'emergenza, l'endpoint primario viene sottoposto a sondaggio tramite probe, lo stato diventa danneggiato e il sito di ripristino di emergenza rimane Online. Per impostazione predefinita, tutto il traffico viene inviato all'endpoint primario (o con priorità più elevata). Se l'endpoint primario risulta danneggiato, Gestione traffico indirizza il traffico verso il secondo endpoint purché rimanga integro. In Gestione traffico è possibile configurare più endpoint da usare come endpoint di failover aggiuntivi o per bilanciare il carico condividendo il carico tra endpoint.
Configurare il ripristino di emergenza e il rilevamento di interruzioni
Se si hanno architetture complesse e più set di risorse in grado di eseguire la stessa funzione, è possibile configurare Gestione traffico di Azure (basato su DNS) per controllare l'integrità delle risorse e indirizzare il traffico dalla risorsa non integra a quella integra.
Nell'esempio seguente l'area primaria e quella secondaria presentano una distribuzione completa. Questa distribuzione include i servizi cloud e un database sincronizzato.
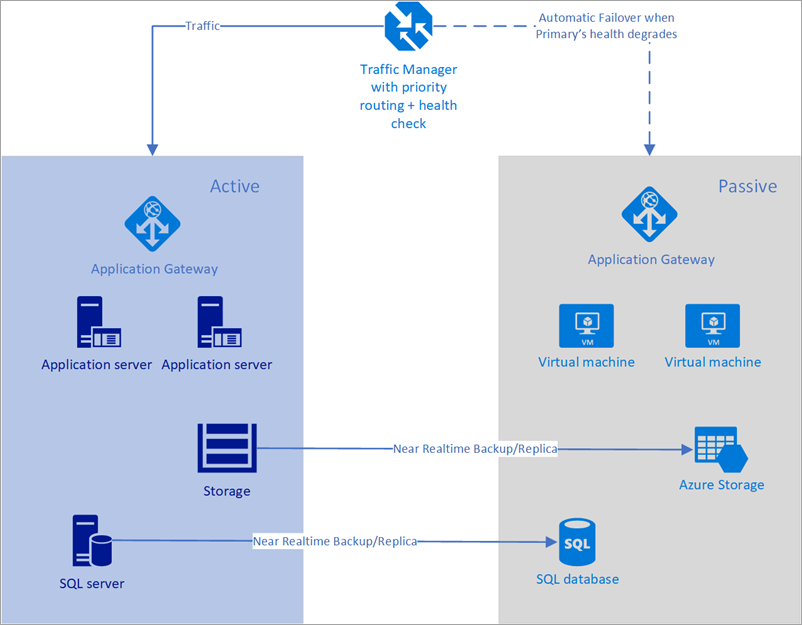
Figura: Failover automatico con Gestione traffico di Azure
Tuttavia, solo l'area primaria gestisce attivamente le richieste di rete degli utenti. Quella secondaria si attiva solo quando nell'area primaria si verifica un'interruzione del servizio. In questo caso tutte le richieste di rete vengono reindirizzate all'area secondaria. Poiché il backup del database è quasi istantaneo, entrambi i servizi di bilanciamento del carico hanno indirizzi IP di cui può essere controllata l'integrità e le istanze sono sempre in esecuzione, questa topologia offre una buona opzione per una configurazione con basso RTO e failover senza intervento manuale. L'area di failover secondaria deve essere pronta ad attivarsi immediatamente in caso di problemi con quella primaria.
Questo scenario è ideale per l'uso di Gestione traffico di Azure con probe incorporati per vari tipi di controlli di integrità, inclusi HTTP/HTTPS e TCP. Gestione traffico di Azure ha anche un motore regole di business che può essere configurato per effettuare il failover in caso di errore, come descritto di seguito. Si consideri la soluzione seguente che prevede l'uso di Gestione traffico:
- Il cliente ha un endpoint di Area 1, denominato prod.contoso.com, con indirizzo IP statico 100.168.124.44 e un endpoint di Area 2, denominato dr.contoso.com, con indirizzo IP statico 100.168.124.43.
- Ognuno di questi ambienti è gestito tramite una proprietà pubblica come servizio di bilanciamento del carico. Quest'ultimo può essere configurato con un endpoint basato su DNS o un nome di dominio completo (FQDN), come illustrato in precedenza.
- Tutte le istanze in Area 2 vengono replicate quasi in tempo reale con Area 1. Inoltre, le immagini del computer sono aggiornate e a tutti i dati di software/configurazione è stata applicata una patch e sono in linea con l’area 1.
- La scalabilità automatica è preconfigurata in anticipo.
Per configurare il failover con Gestione traffico di Azure:
Creare un nuovo profilo di Gestione traffico di Azure Creare un nuovo profilo di Gestione traffico di Azure con il nome contoso123 e selezionare il metodo Routing come Priorità. Se si dispone di un gruppo di risorse preesistente a cui si vuole associare, è possibile selezionare un gruppo di risorse esistente; in caso contrario, creare un nuovo gruppo di risorse.
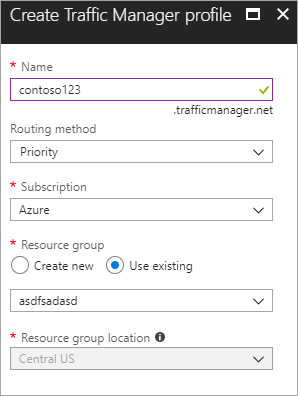
Immagine- Creare un profilo di Gestione traffico
Creare endpoint all'interno del profilo di Gestione traffico
In questo passaggio si creano endpoint che puntano ai siti di produzione e di ripristino di emergenza. In questo caso, scegliere un endpoint esterno come Tipo, ma se la risorsa è ospitata in Azure, è possibile scegliere anche Endpoint Azure. Se si sceglie Endpoint Azure, selezionare come Risorsa di destinazione un servizio App o un IP pubblico allocato da Azure. In priorità viene impostato il valore 1 perché si tratta del servizio primario per l’area 1. Con una procedura analoga, creare l'endpoint di ripristino di emergenza anche all'interno di Gestione traffico.
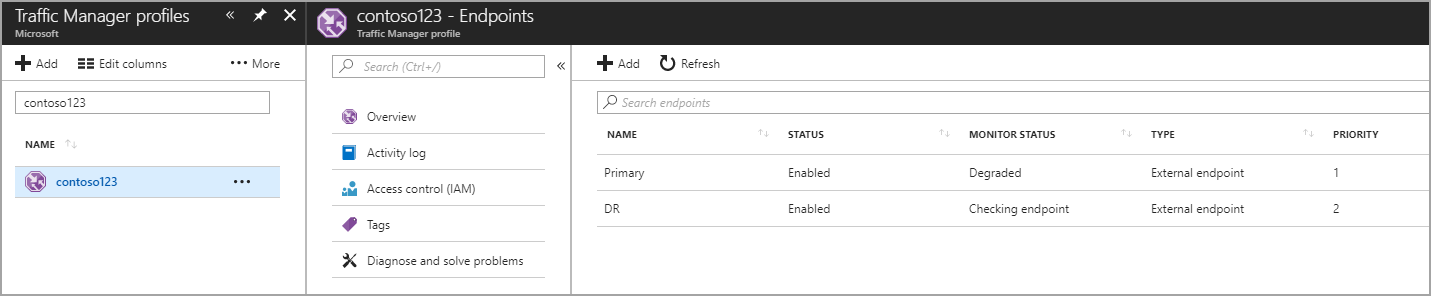
Figura: Creare endpoint di ripristino di emergenza
Definire la configurazione per il controllo di integrità e il failover
In questo passaggio si imposta la durata TTL di DNS su 10 secondi, un valore che viene rispettato dalla maggior parte dei resolver ricorsivi con connessione Internet. Questa configurazione indica che nessun resolver DNS memorizzerà le informazioni nella cache per più di 10 secondi.
Per le impostazioni di monitoraggio degli endpoint, il percorso è impostato sulla radice (o /), ma è possibile personalizzare le impostazioni degli endpoint in modo da valutare un percorso, ad esempio prod.contoso.com/index.
Come protocollo di sondaggio nell'esempio seguente è impostato HTTPS, ma è possibile scegliere anche HTTP o TCP. La scelta del protocollo dipende dall'applicazione finale. L'intervallo di sondaggio è impostato su 10 secondi, in modo da consentire un'individuazione rapida tramite probe, e come valore di retry è impostato 3. Di conseguenza, Gestione traffico effettuerà il failover nel secondo endpoint se tre intervalli consecutivi registrano un errore.
La formula seguente definisce il time totale per un failover automatizzato:
Time for failover = TTL + Retry * Probing intervalE In questo caso, il valore è 10 + 3 * 10 = 40 secondi (max).
Se il valore di retry è impostato su 1 e la durata TTL su 10 secondi, il tempo per il failover sarà 10 + 1 * 10 = 20 secondi.
Impostare il valore di retry su un valore maggiore di 1 per evitare l'esecuzione del failover a causa di falsi positivi o problemi di rete irrilevanti.
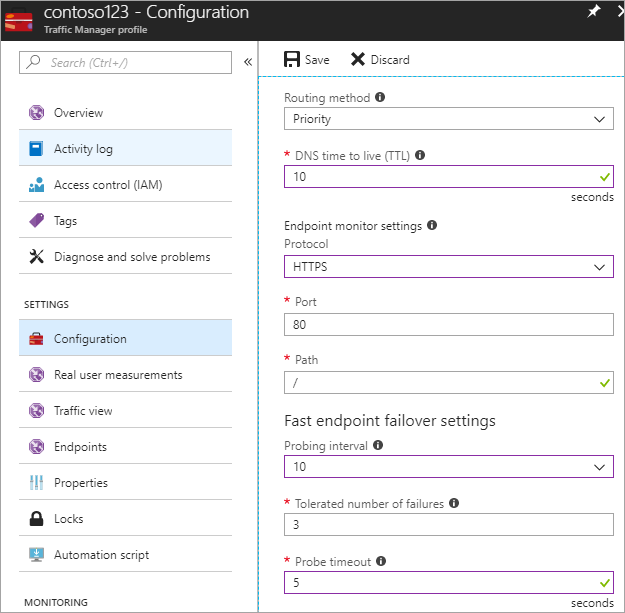
Figura: Definire la configurazione per il controllo di integrità e il failover
Passaggi successivi
Altre informazioni su Gestione traffico di Azure.
Altre informazioni su DNS di Azure.