Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo documento illustra diverse aree da considerare quando si distribuisce SQL Server per il carico di lavoro SAP nell'infrastruttura distribuita come servizio (IaaS) di Azure. Come precondizione per questo documento, vedere Considerazioni sulla distribuzione DBMS di Macchine virtuali di Azure per il carico di lavoro SAP. Vedere anche altre guide nel carico di lavoro SAP nella documentazione di Azure.
Importante
L'ambito di questo documento è la versione Windows di SQL Server. SAP non supporta la versione Linux di SQL Server con uno dei software SAP. Il documento non illustra il database SQL di Microsoft Azure, ovvero un'offerta PaaS (Platform as a Service) della piattaforma Microsoft Azure. La discussione in questo articolo riguarda l'esecuzione del prodotto SQL Server, noto per le distribuzioni locali in macchine virtuali (VM) di Azure, usando la funzionalità IaaS di Azure. Le capacità e le funzionalità del database tra queste due offerte sono diverse e non dovrebbero essere confuse tra loro. Per altre informazioni, vedere Database SQL di Azure.
Per eseguire i carichi di lavoro SAP in IaaS di Azure, è consigliabile in linea generale usare le versioni più recenti di SQL Server. Le versioni più recenti di SQL Server offrono una migliore integrazione con alcuni dei servizi e delle funzionalità di Azure o contengono modifiche che ottimizzano le operazioni in un'infrastruttura IaaS di Azure.
La documentazione generale su SQL Server in esecuzione in una macchina virtuale di Azure è disponibile negli articoli seguenti:
- SQL Server in Macchine virtuali di Azure (Windows)
- Automatizzare la gestione con l'estensione dell'agente IaaS per SQL Server di Windows
- Configurare l'integrazione di Azure Key Vault per SQL Server nelle macchine virtuali di Azure (Resource Manager)
- Elenco di controllo: procedure consigliate per SQL Server nelle macchine virtuali di Azure
- Vedere Archiviazione: procedure consigliate per le prestazioni per SQL Server nelle macchine virtuali di Azure
- Procedure consigliate per la configurazione HADR (SQL Server nelle macchine virtuali di Azure)
Non tutti i contenuti e le istruzioni eseguite nella documentazione generale di SQL Server nella macchina virtuale di Azure si applicano al carico di lavoro SAP. Tuttavia, la documentazione ne illustra bene principi. Un esempio di funzionalità non supportate per il carico di lavoro SAP è l'uso del clustering di istanza del cluster di failover.
Di seguito sono indicate alcune informazioni specifiche su SQL Server in IaaS che è necessario conoscere per poter continuare:
Supporto della versione di SQL: anche con la nota SAP #1928533 che indica che la versione minima supportata di SQL Server è SQL Server 2008 R2, la finestra delle versioni di SQL Server supportate in Azure è dettata anche dal ciclo di vita di SQL Server. La manutenzione estesa di SQL Server 2012 è terminata a metà del 2022. Di conseguenza, la versione minima corrente per i sistemi distribuiti di recente deve essere SQL Server 2014. È consigliabile usare sempre la versione più recente. Le versioni più recenti di SQL Server offrono una migliore integrazione con alcuni dei servizi e delle funzionalità di Azure o contengono modifiche che ottimizzano le operazioni in un'infrastruttura IaaS di Azure.
Uso di immagini da Azure Marketplace: il modo più rapido per distribuire una nuova macchina virtuale di Microsoft Azure consiste nell'usare un'immagine di Azure Marketplace. In Azure Marketplace sono disponibili immagini che contengono le versioni più recenti di SQL Server. Non è però possibile usare subito per le applicazioni SAP NetWeaver le immagini in cui SQL Server è già installato. Il motivo è che le regole di confronto predefinite di SQL Server vengono installate all'interno di tali immagini e non le regole di confronto necessarie per i sistemi SAP NetWeaver. Per usare queste immagini, vedere la procedura documentata nel capitolo Uso di un'immagine di SQL Server da Microsoft Azure Marketplace.
Supporto per più istanze di SQL Server all'interno di una singola macchina virtuale di Azure: questo metodo di distribuzione è supportato. Tuttavia, tenere presente le limitazioni delle risorse, in particolare per quanto riguarda la larghezza di banda di rete e di archiviazione del tipo di macchina virtuale in uso. Le informazioni dettagliate sono disponibili nell'articolo Dimensioni delle macchine virtuali in Azure. Queste limitazioni di quota potrebbero impedire l'implementazione della stessa architettura a più istanze che è possibile implementare in locale. A partire dalla configurazione e dall'interferenza della condivisione delle risorse disponibili in una singola macchina virtuale, è necessario tenere presente le stesse considerazioni dell'ambiente locale.
Più database SAP in una singola istanza di SQL Server in una singola macchina virtuale: sono supportate configurazioni simili a queste. Le considerazioni relative a più database SAP che condividono le risorse condivise di una singola istanza di SQL Server sono le stesse delle distribuzioni locali. Tenere presenti altri limiti, ad esempio il numero di dischi che possono essere collegati a un tipo di macchina virtuale specifico. Oppure i limiti di quota di rete e archiviazione di tipi di macchina virtuale specifici come illustrato in Dimensioni delle macchine virtuali in Azure.
Nuove macchine virtuali serie M e SQL Server
Azure ha rilasciato alcune nuove famiglie di SKU serie M nella famiglia di Mv3. Alcuni tipi di vm in questa famiglia non devono essere usati per SQL Server, incluso SQL Server 2022 senza disabilitare SMT (Hyperthreading) nel sistema operativo guest di Windows Server. Il motivo è che il numero di nodi NUMA presentati nel sistema operativo guest di Windows Server, quando ci sono più di 64 vCPU, è troppo elevato perché SQL Server possa gestirlo. Disabilitando SMT nel sistema operativo guest di Windows Server, il numero di vCPU viene ridotto. Di conseguenza, il numero di vCPU è minore di 64 in ogni nodo NUMA. Il modo in cui disabilitare SMT è descritto Disabilitare SMT in una macchina virtuale di Azure. I tipi di macchina virtuale specifici sono:
- M176(d)s_3_v3: disabilitare SMT o usare M176bds_4_v3 o M176bds_4_v3 come alternativa
- M176(d)s_4_v3: disabilitare SMT o usare M176bds_4_v3 come alternativa
- M624(d)s_12_v3: disabilitare SMT o usare M416ms_v2 come alternativa
- M832(d)s_12_v3: disabilitare SMT o usare M416ms_v2 come alternativa
- M832i(d)s_16_v3 : disabilitare SMT o usare M416ms_v2 come alternativa
Note
Con alcuni dei nuovi tipi di VM M(b)v3, l'uso dell'archiviazione PREMIUM SSD v1 in lettura memorizzata nella cache potrebbe comportare una velocità di I/O al secondo di lettura e scrittura inferiore rispetto a quella che si otterrebbe se non si usa la cache di lettura.
Raccomandazioni sulla struttura di VM/dischi rigidi virtuali per distribuzioni di SQL Server correlate a SAP
In base alla descrizione generale, il sistema operativo, i file eseguibili di SQL Server, i file eseguibili SAP devono trovarsi o essere installati in dischi di Azure separati. In genere, la maggior parte dei database di sistema di SQL Server non viene usata a livello generale con il carico di lavoro SAP NetWeaver. Tuttavia, i database di sistema di SQL Server devono trovarsi, insieme alle altre directory di SQL Server, in un disco di Azure separato. SQL Server tempdb deve trovarsi nell'unità D:\ non persistente o in un disco separato.
- Con tutti i tipi di VM certificati SAP (vedere SAP Note #1928533),
tempdbi dati e i file di log possono essere inseriti nell'unità D:\ non gestita. - Nelle versioni di SQL Server, in cui SQL Server viene installato
tempdbcon un solo file di dati, è consigliabile usare più file di datitempdb. Tenere presente che i volumi dell'unità D:\ hanno dimensioni e funzionalità diversi in base al tipo di macchina virtuale. Per le dimensioni esatte dell'unità D:\ delle diverse VM, vedere l'articolo Dimensioni per le macchine virtuali Windows in Azure.
Queste configurazioni consentono a tempdb di usare più spazio e un numero maggiore di operazioni di I/O al secondo (IOPS) e un maggiore banda passante rispetto a quanto l'unità di sistema sia in grado di fornire. L'unità D:\ non persistente offre anche una migliore latenza e velocità effettiva di I/O. Per determinare le dimensioni appropriate tempdb , è possibile controllare le tempdb dimensioni nei sistemi esistenti.
Note
Se si inserisce tempdb file di dati e file di log in una cartella nell'unità D:\ creata, è necessario assicurarsi che la cartella esista dopo il riavvio di una macchina virtuale. Poiché l'unità D:\ può essere appena inizializzata dopo il riavvio di una macchina virtuale, è possibile cancellare tutti i file e le strutture di directory. È possibile ricreare le strutture di directory nell'unità D:\ prima dell'avvio del servizio SQL Server in Uso di unità SSD nelle macchine virtuali di Azure per archiviare le estensioni del pool di buffer e TEMPDB di SQL Server.
Una configurazione di macchina virtuale, che esegue SQL Server con un database SAP e in cui tempdb i dati e tempdb i file di log vengono inseriti nell'unità D:\ e Archiviazione Premium di Azure v1 o v2 saranno simili ai seguenti:
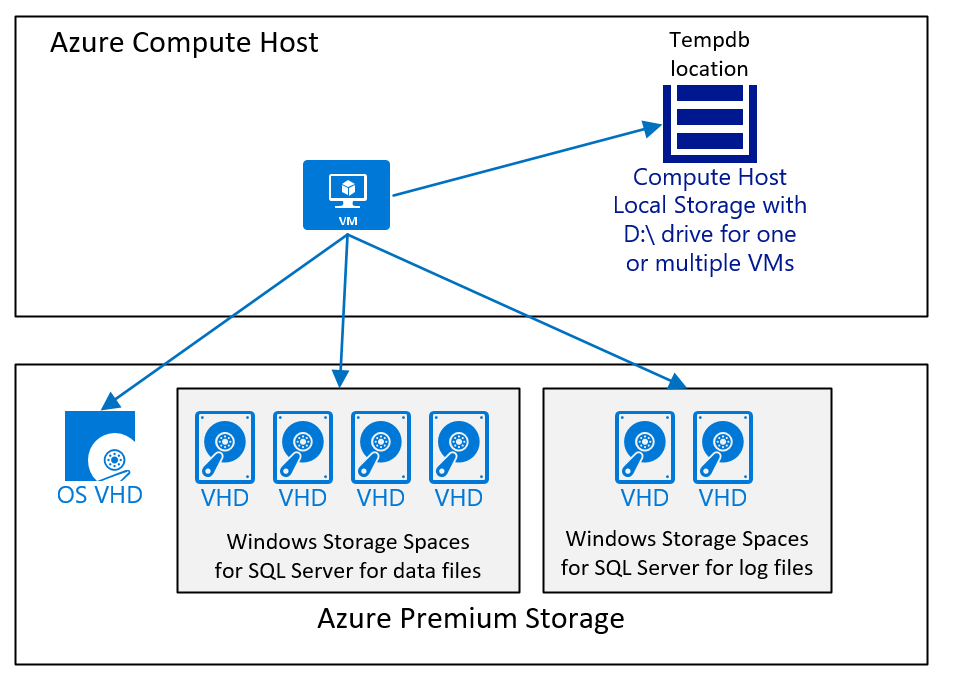
Il diagramma visualizza un caso semplice. Come accennato nell'articolo Considerazioni sulla distribuzione DBMS di Macchine virtuali di Azure per un carico di lavoro SAP, il tipo, il numero e la dimensione di archiviazione di Azure dipendono da diversi fattori. È tuttavia consigliabile:
- Per le distribuzioni più piccole e di dimensioni medie, che usano un volume di grandi dimensioni, che contiene i file di dati di SQL Server. Il motivo di questa configurazione è che è più facile gestire carichi di lavoro di I/O diversi nel caso in cui i file di dati di SQL Server non abbiano lo stesso spazio disponibile. Mentre nelle distribuzioni di grandi dimensioni, in particolare le distribuzioni in cui il cliente si è trasferito con una migrazione eterogenea del database a SQL Server in Azure, sono stati usati dischi separati e quindi distribuiti i file di dati in tali dischi. Questa architettura ha esito positivo solo quando ogni disco ha lo stesso numero di file di dati, tutti i file di dati hanno le stesse dimensioni e hanno approssimativamente lo stesso spazio libero.
- Usare l'unità D:\ per
tempdbfintanto che le prestazioni sono sufficientemente buone. Se le prestazioni complessive del carico di lavoro sono limitate sull'unitàtempdbD:\, è necessario trasferiretempdbsu Archiviazione Premium di Azure v1 o v2 o su Ultra Disk, come consigliato nelle procedure consigliate per le prestazioni.
Il meccanismo di riempimento proporzionale di SQL Server distribuisce le operazioni di lettura e scrittura in tutti i file di dati purché tutti i file di dati di SQL Server abbiano le stesse dimensioni e lo stesso spazio libero. SAP in SQL Server offre prestazioni ottimali quando le letture e le scritture vengono distribuite uniformemente in tutti i file di dati disponibili. Se un database contiene un numero troppo basso di file di dati o i file di dati esistenti sono altamente sbilanciati, il metodo migliore per correggere questa situazione è un'esportazione e un'importazione R3load. Un'operazione di esportazione e importazione R3load comporta tempi di inattività e deve essere eseguita solo se si verifica un evidente problema di prestazioni che deve essere risolto. Se i file di dati sono solo dimensioni moderatamente diverse, aumentare tutti i file di dati alla stessa dimensione e SQL Server ribilancia i dati nel corso del tempo. SQL Server aumenta automaticamente i file di dati in modo uniforme se il flag di traccia 1117 è impostato o se SQL Server 2016 o versione successiva viene usato senza flag di traccia.
Considerazione per le macchine virtuali serie M
Per la macchina virtuale serie M di Azure, la latenza di scrittura nel log delle transazioni può essere ridotta rispetto alle prestazioni di Archiviazione Premium di Azure v1 quando si usa l'acceleratore di scrittura di Azure. Se la latenza fornita dall'archiviazione Premium v1 limita la scalabilità del carico di lavoro SAP, il disco in cui è archiviato il file di log delle transazioni di SQL Server può essere abilitato per l'acceleratore di scrittura. I dettagli sono disponibili nel documento relativo all'acceleratore di scrittura. L'acceleratore di scrittura di Azure non funziona con Archiviazione Premium di Azure v2 e il disco Ultra. In entrambi i casi, la latenza è migliore rispetto a quella erogata da Storage Premium di Azure v1. L'acceleratore di scrittura non supporta Azure Premium SSD v2.
Note
Con alcuni dei nuovi tipi di VM M(b)v3, l'uso dell'archiviazione PREMIUM SSD v1 in lettura memorizzata nella cache potrebbe comportare una velocità di I/O al secondo di lettura e scrittura inferiore rispetto a quella che si otterrebbe se non si usa la cache di lettura.
Formattazione dei dischi
Per SQL Server, le dimensioni del blocco NTFS per i dischi contenenti i file di dati e di log di SQL Server devono essere di 64 KB. Non è necessario formattare l'unità D:\. Questa unità viene preformattata.
Per evitare che il ripristino o la creazione di database inizializzi i file di dati e che il loro contenuto venga azzerato, assicurarsi che per il contesto utente in cui viene eseguito il servizio SQL Server abbia il diritto utente Eseguire attività di manutenzione del volume. Per altre informazioni, vedere Inizializzazione immediata dei file di database.
Archiviazione dei file di database direttamente in Archiviazione BLOB di Azure
In SQL Server 2014 e versioni successive è possibile archiviare file di database direttamente in Archiviazione BLOB di Azure senza il "wrapper" di un disco rigido virtuale. Questa funzionalità è stata concepita per risolvere le carenze degli anni precedenti dell'archiviazione a blocchi di Azure. In questi giorni non è consigliabile usare questo metodo di distribuzione e scegliere invece Archiviazione Premium di Azure v1 o v2 o Disco Ultra a seconda dei requisiti.
Considerazioni sul backup e sul ripristino per SQL Server
Durante la distribuzione di SQL Server in Azure, è necessario esaminare l'architettura di backup. Anche se il sistema non è un sistema di produzione, è necessario eseguire periodicamente il backup del database SAP di SQL Server. Dal momento che in Archiviazione di Azure vengono mantenute tre immagini, ora un backup è meno importante rispetto alla compensazione di un arresto anomalo della risorsa di archiviazione. La priorità per la gestione di un piano di backup e ripristino appropriato è importante per la funzionalità di ripristino temporizzato per compensare gli errori logici/manuali. L'obiettivo è usare i backup per ripristinare il database a un determinato punto nel tempo. In alternativa, usare i backup in Azure per eseguire il seeding di un altro sistema con la copia del backup del database esistente.
Esistono diversi modi per eseguire il backup e il ripristino dei database di SQL Server in Azure. Per ottenere la panoramica e i dettagli migliori, leggere il documento Backup e ripristino per SQL Server in macchine virtuali di Azure. L'articolo descrive molti modi diversi.
Uso di un'immagine di SQL Server da Microsoft Azure Marketplace
Microsoft offre macchine virtuali in Azure Marketplace, che contiene già versioni di SQL Server. Per i clienti SAP che necessitano delle licenze per SQL Server e Windows l'uso di queste immagini può essere un'opportunità per ottenere le licenze necessarie scegliendo le VM con SQL Server già installato. Per usare tali immagini per SAP, è necessario considerare quanto segue:
- I costi delle versioni di SQL Server non di valutazione sono più elevati rispetto a una macchina virtuale "solo Windows" distribuita da Azure Marketplace. Per confrontare i prezzi, vedere Prezzi di macchine virtuali Windows e Prezzi di Macchine virtuali SQL Server Enterprise.
- È possibile usare solo le versioni di SQL Server supportate da SAP per il software.
- Le regole di confronto dell'istanza di SQL Server installata nelle macchine virtuali offerte in Azure Marketplace non sono quelle da eseguire nell'istanza di SQL Server per SAP NetWeaver. È comunque possibile modificare le regole di confronto attenendosi alle istruzioni della sezione seguente.
Modifica delle regole di confronto di SQL Server in una macchina virtuale SQL Server di Microsoft Windows
Poiché le immagini di SQL Server in Azure Marketplace non sono configurate per l'uso delle regole di confronto, necessarie per le applicazioni SAP NetWeaver, è necessario modificarle immediatamente dopo la distribuzione. Per SQL Server, questa modifica delle regole di confronto può essere eseguita con i passaggi seguenti non appena viene distribuita la macchina virtuale e un amministratore è in grado di accedere alla macchina virtuale distribuita:
- Aprire una finestra di comando di Windows come amministratore.
- Passare alla directory C:\Programmi\SQL Server\110\Setup Bootstrap\SQLServer2012.
- Eseguire il comando: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name>è l'account definito come account amministratore quando si distribuisce la macchina virtuale per la prima volta tramite la raccolta.
-
Il processo dovrebbe richiedere solo alcuni minuti. Per verificare la correttezza del risultato finale del passaggio, seguire questa procedura:
- Aprire SQL Server Management Studio.
- Aprire una finestra di query.
- Eseguire il comando sp_helpsort nel database master di SQL Server.
Il risultato dovrebbe essere simile a quello della figura seguente:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Se il risultato è diverso, ARRESTARE la distribuzione e scoprire perché il comando di configurazione non ha funzionato nel modo previsto. La distribuzione di applicazioni SAP NetWeaver in un'istanza di SQL Server con tabelle codici di SQL Server diverse da quella indicata NON è supportata per le distribuzioni di NetWeaver.
Disponibilità elevata di SQL Server per SAP in Azure
Usando SQL Server nelle distribuzioni IaaS di Azure per SAP, è possibile aggiungere diverse possibilità per distribuire il livello di database a disponibilità elevata. Azure offre contratti di servizio diversi per una singola macchina virtuale usando:
- Archiviazioni a blocchi di Azure diverse
- Coppia di macchine virtuali distribuite in un set di disponibilità di Azure
- Coppia di macchine virtuali distribuite tra zone di disponibilità di Azure
Per i sistemi di produzione, si prevede di distribuire una coppia di macchine virtuali all'interno di un set di scalabilità di macchine virtuali con orchestrazione flessibile in due zone di disponibilità. Per altre informazioni, vedere Confronto tra diversi tipi di distribuzione per il carico di lavoro SAP. Una macchina virtuale esegue l'istanza di SQL Server attiva. L'altra macchina virtuale esegue l'istanza passiva.
Clustering di SQL Server tramite il file server scale-out di Windows o il disco condiviso di Azure
Con Windows Server 2016, Microsoft ha introdotto la funzionalità Spazi di archiviazione diretta. Basato sulla distribuzione degli spazi di archiviazione e sulla distribuzione diretta, il clustering dell'istanza del cluster di failover di SQL Server è supportato in generale. Azure offre anche dischi condivisi di Azure che possono essere usati per il clustering di Windows. Per il carico di lavoro SAP non sono supportate queste opzioni a disponibilità elevata.
Log shipping di SQL Server
Una funzionalità di disponibilità elevata è il log shipping di SQL Server. Se le macchine virtuali che partecipano alla configurazione della disponibilità elevata hanno una risoluzione dei nomi funzionante, non c'è alcun problema. La configurazione in Azure non è diversa da qualsiasi configurazione eseguita in locale correlata alla configurazione del log shipping e ai principi relativi al log shipping. I dettagli sul log shipping di SQL Server sono disponibili nell'articolo Informazioni sul log shipping (SQL Server).
La funzionalità di log shipping di SQL Server viene usata raramente in Azure per ottenere la disponibilità elevata in una singola area di Azure. Negli scenari seguenti, tuttavia, i clienti SAP usano il log shipping con successo insieme ad Azure:
- Scenari di ripristino di emergenza da un'area di Azure in un'altra area di Azure
- Configurazione di ripristino di emergenza da un'area locale in un'area di Azure
- Scenari di cutover da un'area locale ad Azure. In questi casi, il log shipping viene usato per sincronizzare la nuova distribuzione di database in Azure con il sistema di produzione in corso in locale. Al momento del passaggio, la produzione viene arrestata e ci si assicura che gli ultimi e più recenti backup dei log delle transazioni siano stati trasferiti nella distribuzione del database di Azure. La distribuzione del database di Azure viene quindi aperta per la produzione.
SQL Server AlwaysOn
Always On è supportato per SAP locale (vedere SAP Note #1772688) e supportato in combinazione con SAP in Azure. Bisogna fare alcune considerazioni speciali sulla distribuzione del listener del gruppo di disponibilità di SQL Server (da non confondere con il set di disponibilità di Azure). Pertanto, sono necessari passaggi di installazione diversi.
Di seguito sono elencate alcune considerazioni relative all'uso di un listener del gruppo di disponibilità.
- L'uso di un listener del gruppo di disponibilità è possibile solo con Windows Server 2012 e versioni successive come sistema operativo guest della macchina virtuale. Per Windows Server 2012, verificare che i listener del gruppo di disponibilità di SQL Server sulle macchine virtuali Microsoft Azure basate su Windows Server 2008 R2 e Windows Server 2012 vengano applicati.
- Per Windows Server 2008 R2, questa patch non esiste. In questo caso, è necessario usare Always On nello stesso modo del mirroring del database: Specificando un partner di failover nella stringa di connessioni come fatto tramite il parametro sap default.pfl dbs/mss/server. Vedere la nota SAP #965908.
- Quando si usa un listener del gruppo di disponibilità, le macchine virtuali del database devono essere connesse a un Load Balancer dedicato. È necessario assegnare indirizzi IP statici alle interfacce di rete di tali macchine virtuali nella configurazione Always On. La definizione di un indirizzo IP statico è descritta in Creare una macchina virtuale con un indirizzo IP privato statico. Gli indirizzi IP statici rispetto al protocollo DHCP impediscono l'assegnazione di nuovi indirizzi IP nei casi in cui entrambe le macchine virtuali potrebbero essere arrestate.
- Durante la compilazione della configurazione del cluster WSFC è necessario eseguire passaggi speciali in cui il cluster necessita di un indirizzo IP speciale assegnato. Azure, con la funzionalità corrente, assegna al cluster lo stesso indirizzo IP del nodo in cui viene creato il cluster. Questo comportamento richiede l'esecuzione di un passaggio manuale per assegnare al cluster un indirizzo IP diverso.
- Il listener del gruppo di disponibilità verrà creato in Azure con gli endpoint TCP/IP assegnati alle VM che eseguono le repliche primaria e secondaria del gruppo di disponibilità.
- Potrebbe essere necessario proteggere questi endpoint con ACL.
Di seguito è elencata la documentazione dettagliata sulla distribuzione di Always On con SQL Server in macchine virtuali di Azure:
- Panoramica sui gruppi di disponibilità Always On di SQL Server in macchine virtuali di Azure
- Configurare un gruppo di disponibilità Always On in macchine virtuali di Azure in aree diverse
- Configurare un servizio di bilanciamento del carico interno per un gruppo di disponibilità Always On in Azure
- Procedure consigliate per la configurazione HADR (SQL Server nelle macchine virtuali di Azure)
Note
Leggere Panoramica sui gruppi di disponibilità Always On di SQL Server in macchine virtuali di Azure, consente di avere informazioni sul listener DNN (Direct Network Name) di SQL Server. La funzionalità DNN è stata introdotta con SQL Server 2019 CU8. e rende obsoleto l'utilizzo di un servizio di bilanciamento del carico di Azure che gestisce l'indirizzo IP virtuale del listener del gruppo di disponibilità.
SQL Server AlwaysOn è la funzionalità di disponibilità elevata e ripristino di emergenza più comunemente usata in Azure per le distribuzioni del carico di lavoro SAP. La maggior parte dei clienti usa Always On per la disponibilità elevata all'interno di una singola area di Azure. Se la distribuzione è limitata a due soli nodi, sono disponibili due opzioni per la connettività:
Utilizzo del listener del gruppo di disponibilità. Con il listener del gruppo di disponibilità, è necessario distribuire un servizio di bilanciamento del carico di Azure.
Il listener DNN (Direct Network Name) può essere usato invece di un servizio di bilanciamento del carico di Azure. DNN elimina il requisito di usare un servizio di bilanciamento del carico di Azure, che si applica anche a:
SQL Server 2016 SP3
- Versioni più recenti di SQL Server in Windows Server 2016
SQL Server 2017 CU 25
SQL Server 2019 CU8
L'uso dei parametri di connettività del mirroring del database di SQL Server deve essere considerato solo per l'analisi dei problemi con gli altri due metodi. In questo caso, è necessario configurare la connettività delle applicazioni SAP in modo che entrambi i nomi dei nodi siano nominati. I dettagli precisi di tale configurazione lato SAP sono illustrati nella nota SAP #965908. Se si usa questa opzione, è necessario configurare un listener del gruppo di disponibilità. E in questo modo nessun servizio di bilanciamento del carico di Azure potrebbe analizzare i problemi di tali componenti. Si deve tuttavia tenere presente che questa opzione funziona solo se si limita il gruppo di disponibilità a due istanze.
La maggior parte dei clienti usa la funzionalità Always On di SQL Server per la funzionalità di ripristino di emergenza tra aree di Azure. Molti clienti usano anche la possibilità di eseguire il backup da una replica secondaria.
Transparent Data Encryption di SQL Server
Molti clienti usano Transparent Data Encryption (TDE) di SQL Server per la distribuzione dei database SQL Server per SAP in Azure. SAP supporta completamente la funzionalità TDE di SQL Server. Vedere La nota SAP #1380493.
Applicazione della funzionalità TDE di SQL Server
Nei casi in cui si esegue una migrazione eterogenea da un altro database, in esecuzione in locale, a Windows SQL Server in esecuzione in Azure, è necessario creare il database di destinazione vuoto in SQL Server in anticipo. Come passaggio successivo si applicherà la funzionalità TDE di SQL Server a questo database vuoto. Il motivo per cui conviene attenersi a questa sequenza è che il processo di crittografia del database vuoto può richiedere molto tempo. I processi di importazione SAP importano quindi i dati nel database crittografato durante la fase di inattività. Nel complesso l'importazione in un database crittografato ha un impatto temporale inferiore rispetto alla crittografia del database dopo la fase di esportazione nella fase di inattività. Sono state effettuate esperienze negative quando si tenta di applicare TDE con il carico di lavoro SAP in esecuzione sul database. È pertanto consigliabile gestire la distribuzione di TDE come un'attività da svolgere senza carichi di lavoro SAP o con carichi ridotti su un database specifico. Da SQL Server 2016 in poi è possibile arrestare e riprendere l'analisi TDE che esegue la crittografia iniziale.
Nei casi in cui si spostano i database di SQL Server per SAP dal livello locale in Azure, è consigliabile testare in quale infrastruttura è possibile applicare la crittografia più velocemente. Per questo caso, tenere presenti queste considerazioni:
- Non è possibile definire il numero di thread che viene usato per applicare la crittografia dei dati al database. Il numero di thread dipende principalmente dal numero di volumi del disco su cui vengono distribuiti i file di dati e di log SQL Server. Maggiore è il numero di volumi distinti (lettere delle unità), maggiore sarà il numero di thread eseguiti in parallelo per eseguire la crittografia. Tale configurazione contraddice il suggerimento di configurazione del disco precedente per crearne uno o un numero ridotto di spazi di archiviazione per i file di database SQL Server nelle macchine virtuali Azure. Una configurazione con alcuni volumi porta a pochi thread che eseguono la crittografia. Un singolo thread di crittografia legge gli extent di 64 KB, li crittografa e quindi scrive un record nel file di log delle transazioni per notare che l'extent è stato crittografato. Di conseguenza, il carico nel log delle transazioni è moderato.
- Nelle versioni precedenti di SQL Server la compressione dei backup non è più efficiente quando si crittografa il database SQL Server. Questo comportamento potrebbe trasformarsi in un problema quando si pianifica di crittografare il database SQL locale e quindi copiare un backup in Azure per ripristinare il database in Azure. La compressione dei backup di SQL Server può raggiungere un rapporto di compressione di fattore 4.
- Con SQL Server 2016, è stata introdotta una nuova funzionalità che consente anche la compressione dei backup dei database crittografati in modo efficiente. Per i dettagli, vedere questo blog.
Uso di Azure Key Vault
Azure offre il servizio Key Vault per archiviare le chiavi di crittografia. SQL Server offre invece un connettore per usare Azure Key Vault come archivio per i certificati TDE.
Altre informazioni sull'utilizzo di Azure Key Vault per TDE di SQL Server sono disponibili in:
More Questions From Customers About SQL Server Transparent Data Encryption – TDE + Azure Key Vault (Altre domande dei clienti sulla funzionalità Transparent Data Encryption di SQL Server - TDE + Azure Key Vault).
Importante
Quando si usa SQL Server TDE, in particolare con Azure Key Vault, è consigliabile usare le patch più recenti di SQL Server 2014, SQL Server 2016 e SQL Server 2017. Il motivo è che in base ai commenti e suggerimenti ricevuti dai clienti, al codice sono state applicate ottimizzazioni e correzioni. Controllare ad esempio KBA #4058175.
Configurazioni minime della distribuzione
In questa sezione viene suggerito un set di configurazioni minime per database di dimensioni diverse nel carico di lavoro SAP. È troppo difficile valutare se le dimensioni sono adatte al carico di lavoro specifico. In alcuni casi, è possibile che la quantità di memoria sia eccessiva rispetto alle dimensioni del database. D'altra parte, il dimensionamento del disco potrebbe essere troppo ridotto per alcuni carichi di lavoro. Pertanto, queste configurazioni devono essere considerate per quelle che sono. Si tratta di configurazioni che dovrebbero essere un punto di partenza. Configurazioni per ottimizzare i requisiti specifici del carico di lavoro e di efficienza dei costi.
Un esempio di configurazione per una piccola istanza di SQL Server con dimensioni del database comprese tra 50 GB e 250 GB potrebbe essere simile al seguente:
| Configurazione | Macchina virtuale del database | Commenti |
|---|---|---|
| Tipo macchina virtuale | E4s_v3/v4/v5 (4 vCPU/32 GiB RAM) | |
| Rete accelerata | Abilitare | |
| Versione di SQL Server | SQL Server 2019 o una versione più recenti | |
| n. di file di dati | 4 | |
| n. di file di log | 1 | |
| n. di file di dati temporanei | 4 o un valore predefinito a partire da SQL Server 2016 | |
| Sistema operativo | Windows Server 2019 o una versione più recenti | |
| Aggregazione del disco | Spazi di archiviazione, se desiderati | |
| Sistema di file | NTFS | |
| Dimensioni blocco del formato | 64 kB | |
| n. e tipo di dischi dati | Archiviazione Premium v1: 2 x P10 (RAID0) Archiviazione Premium v2: 2 x 150 GiB (RAID0) - Operazioni di I/O al secondo e velocità effettiva predefinite o unità SSD Premium v2 equivalenti |
Cache = Sola lettura per l'archiviazione Premium v1 |
| n. e tipo di dischi di log | Archiviazione Premium v1: 1 x P20 Archiviazione Premium v2: 1 x 128 GiB: operazioni di I/O al secondo e velocità effettiva predefinite o unità SSD Premium v2 equivalenti |
Cache = NESSUNA |
| Parametro massimo per la memoria di SQL Server | 90% di RAM fisica | Presupponendo una singola istanza |
Ad esempio, questa configurazione è la configurazione della macchina virtuale di database di sap Business Suite in SQL Server. Questa macchina virtuale ospita il database da 30 TB della singola istanza globale di SAP Business Suite di una società globale con ricavi annuali di oltre 200 MILIARDI di dollari e oltre 200.000 dipendenti a tempo pieno. Il sistema esegue tutte le elaborazioni finanziarie, le elaborazioni relative alle vendite e alla distribuzione e molti altri processi aziendali di aree diverse, tra cui la contabilità dell'America del Nord. Il sistema è in esecuzione in Azure dall'inizio del 2018 usando macchine virtuali serie M di Azure come macchine virtuali di database. Poiché la disponibilità elevata del sistema usa Always On con una replica sincrona in un'altra zona di disponibilità della stessa area di Azure. Un'altra replica asincrona in un'altra area di Azure. Il livello applicazione NetWeaver viene distribuito nelle famiglie di macchine virtuali D(a)/E(a) più recenti.
| Configurazione | Macchina virtuale del database | Commenti |
|---|---|---|
| Tipo macchina virtuale | M192dms_v2 (192 vCPU/4.196 GiB RAM) | |
| Rete accelerata | Attivato | |
| Versione di SQL Server | SQL Server 2019 | |
| n. di file di dati | 32 | |
| n. di file di log | 1 | |
| n. di file di dati temporanei | 8 | |
| Sistema operativo | Windows Server 2019 | |
| Aggregazione del disco | Spazi di archiviazione | |
| Sistema di file | NTFS | |
| Dimensioni blocco del formato | 64 kB | |
| n. e tipo di dischi dati | Archiviazione Premium v1: 16 x P40 o SSD Premium equivalente v2 | Cache = Sola lettura |
| n. e tipo di dischi di log | Archiviazione Premium v1: 1 x P60 o ssd Premium equivalente v2 | Uso dell'acceleratore di scrittura |
Numero e tipo di dischi tempdb |
Archiviazione Premium v1: 1 x P30 o ssd Premium v2 equivalente | Nessuna memorizzazione nella cache |
| Parametro massimo per la memoria di SQL Server | 95% di RAM fisica |
Riepilogo generale di SQL Server per SAP in Azure
Questa guida contiene numerosi consigli che è preferibile leggere più volte prima di pianificare la distribuzione di Azure. In generale, assicurarsi di seguire le raccomandazioni principali di SQL Server in Azure:
- Usare la versione più recente di SQLServer, ad esempio SQL Server 2022, con i vantaggi più significativi in Azure.
- Per bilanciare il layout dei file di dati e le restrizioni di Azure, pianificare attentamente il panorama del sistema SAP in Azure:
- Non usare troppi dischi, ma un numero sufficiente a garantire il numero necessario di operazioni di I/O al secondo.
- Se è necessaria una velocità effettiva maggiore, eseguire lo striping solo tra dischi.
- Non usare troppi dischi, ma un numero sufficiente a garantire il numero necessario di operazioni di I/O al secondo.
- Non installare mai il software o inserire file che richiedono la persistenza nell'unità D:\ perché non è gestito. Qualsiasi elemento in questa unità può essere perso al riavvio di Windows o al riavvio della macchina virtuale.
- Per replicare i dati del database, usare la soluzione SQL Server Always On.
- Usare sempre la risoluzione dei nomi e non fare affidamento sugli indirizzi IP.
- Quando si usa la funzionalità TDE di SQL Server, applicare le patch più recenti di SQL Server.
- Prestare attenzione all'uso di immagini di SQL Server da Azure Marketplace. Se si usa quella di SQL Server, è necessario modificare le regole di confronto dell'istanza prima di installarvi un qualsiasi sistema SAP NetWeaver.
- Installare e configurare la funzionalità di monitoraggio dell'host SAP per Azure come illustrato nella Guida alla distribuzione.