Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La ricerca tra diversi tipi di contenuto archiviati in Archiviazione BLOB di Azure può essere un problema da risolvere, ma Azure AI Search offre un'integrazione approfondita a livello di contenuto, l'estrazione e l'inferenza di informazioni testuali, che possono quindi essere sottoposte a query in un indice di ricerca.
In questo articolo, esaminare il flusso di lavoro di base per estrarre contenuto e metadati dai BLOB e inviarli a un indice di ricerca in Azure AI Search. L'indice risultante può essere sottoposto a query usando la ricerca full-text o la ricerca vettoriale. Facoltativamente, è possibile inviare contenuto BLOB elaborato a un archivio conoscenze per scenari non di ricerca.
Nota
Hai già familiarità con il flusso di lavoro e la composizione? Configurare un indicizzatore BLOB è il passaggio successivo.
Cosa significa aggiungere la ricerca sui dati BLOB
Azure AI Search è un servizio di ricerca autonomo che supporta l'indicizzazione e le query dei carichi di lavoro su indici definiti dall'utente, che contengono il contenuto ricercabile privato ospitato nel cloud. Collocare il contenuto ricercabile insieme al motore di query nel cloud è necessario per le prestazioni, per restituire i risultati alla velocità che gli utenti si aspettano dalle query di ricerca.
Ricerca di intelligenza artificiale di Azure si integra con Archiviazione BLOB di Azure a livello di indicizzazione, importando il contenuto del BLOB come documenti di ricerca indicizzati in indici invertiti e in altre strutture di query che supportano query di testo in formato libero, query vettoriali ed espressioni di filtro. Poiché il contenuto del BLOB è indicizzato in un indice di ricerca, è possibile utilizzare la gamma completa di funzionalità di query in Azure AI Search per trovare informazioni nel proprio contenuto del BLOB.
Gli input sono i BLOB, in un singolo contenitore, nell'archivio BLOB di Azure. I BLOB possono essere pressoché qualunque tipo di dati di testo. Se i BLOB contengono immagini, è possibile aggiungere l'arricchimento tramite intelligenza artificiale per creare ed estrarre testo e funzionalità dalle immagini.
L'output è sempre un indice di Azure AI Search, usato per la ricerca, il recupero e l'esplorazione veloci del testo nelle applicazioni client. Al centro c'è l'architettura della pipeline di indicizzazione vera e propria. La pipeline è basata sulla funzionalità indicizzatore, descritta più avanti in questo articolo.
Una volta creato e popolato, l'indice esiste indipendentemente dal contenitore BLOB, ma è possibile eseguire nuovamente le operazioni di indicizzazione per aggiornarlo sulla base dei documenti modificati. Per il rilevamento delle modifiche vengono usate le informazioni di data e ora nei singoli BLOB. Come meccanismo di aggiornamento si può optare per l'esecuzione pianificata o per l'indicizzazione su richiesta.
Risorse usate in una soluzione di ricerca BLOB
Sono necessari Azure AI Search, Archiviazione BLOB di Azure e un client. Azure AI Search è in genere uno dei diversi componenti di una soluzione, dove il codice dell'applicazione emette richieste API e gestisce le risposte. Si potrebbe anche scrivere del codice applicativo per gestire l'indicizzazione, anche se per i test proof-of-concept e per le attività estemporanee è comune utilizzare il portale Azure come client di ricerca.
All'interno di Archiviazione BLOB è necessario un contenitore che fornisca il contenuto di origine. È possibile impostare criteri di inclusione ed esclusione dei file e specificare le parti di un BLOB indicizzate in Azure AI Search.
Si può iniziare direttamente nella pagina del portale dell'account di archiviazione.
Nella pagina di spostamento a sinistra, in Gestione dati, selezionare Azure AI Search per selezionare o creare un servizio di ricerca.
Seguire i passaggi della procedura guidata per estrarre e, facoltativamente, creare contenuto ricercabile dai BLOB. Il flusso di lavoro è costituito dalla procedura guidata Importa dati. Il flusso di lavoro crea un indicizzatore, un'origine dati, un indice e uno skillset di opzioni sul servizio Azure AI Search.
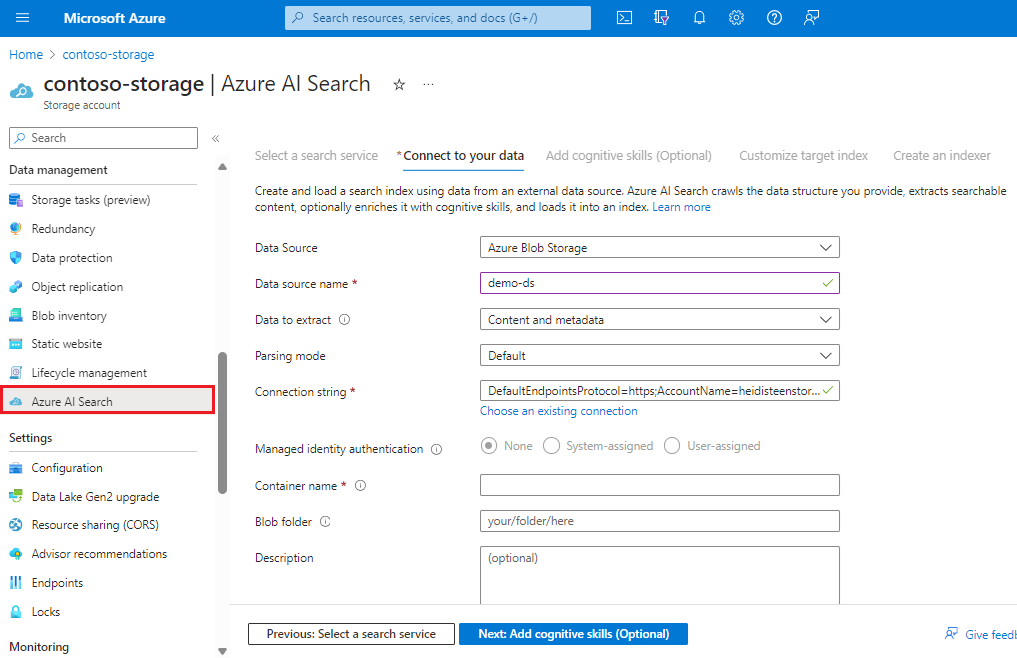
Usare Esplora ricerche nella pagina del portale di ricerca per eseguire query sul contenuto.
La procedura guidata è lo strumento migliore da cui partire, ma si scopriranno opzioni più flessibili quando si configurerà un indicizzatore BLOB manualmente. È possibile usare un client REST. Esercitazione: Indicizzare e cercare dati semistrutturati (BLOB JSON) illustra i passaggi per chiamare l'API REST.
Come vengono indicizzati i BLOB
Per impostazione predefinita, la maggior parte dei BLOB viene indicizzata come un singolo documento di ricerca nell'indice, inclusi i BLOB con contenuto strutturato, ad esempio JSON o CSV, indicizzati come un singolo blocco di testo. Tuttavia, per i documenti JSON o CSV dotati di una struttura interna (delimitatori), è possibile assegnare modalità di analisi per generare singoli documenti di ricerca per ciascuna riga o ciascun elemento:
- Indicizzazione di BLOB JSON
- Indicizzazione di BLOB CSV
- Indicizzazione di BLOB Markdown
- Indicizzazione di BLOB di testo normale
Anche un documento composito o incorporato (ad esempio, un archivio ZIP, un documento di Word con una e-mail di Outlook incorporata con allegati o un file .MSG con allegati) viene indicizzato come documento singolo. Ad esempio, tutte le immagini estratte dagli allegati di un file .MSG verranno restituite nel campo normalized_images. Se si dispone di immagini, è consigliabile aggiungere l'arricchimento tramite intelligenza artificiale per ottenere più utilità di ricerca da tale contenuto.
Il contenuto testuale di un documento viene estratto in un campo stringa denominato "content". È anche possibile estrarre metadati standard e definiti dall'utente.
Nota
Azure AI Search impone limiti all'indicizzatore in relazione alla quantità di testo estratto in base al piano tariffario. Se i documenti vengono troncati, verrà visualizzato un avviso nella risposta di stato dell'indicizzatore.
Utilizzare un indicizzatore BLOB per l'estrazione di contenuto
Un indicizzatore è un sottoservizio presente in Azure AI Search in grado di riconoscere le origini dati dotato di logica interna per il campionamento dei dati, la lettura e il recupero di dati e metadati e la serializzazione dei dati in documenti JSON a partire dal formato nativo per la successiva importazione.
I BLOB in Archiviazione di Azure vengono indicizzati usando l'indicizzatore BLOB. È possibile richiamare questo indicizzatore usando il comando Ricerca di intelligenza artificiale di Azure in Archiviazione di Azure, le procedure guidate Importa dati, un'API REST o .NET SDK. Nel codice, questo indicizzatore si usa impostando il tipo e fornendo le informazioni di connessione, che includono un account di Archiviazione di Azure e un contenitore BLOB. È possibile suddividere in subset i BLOB creando una directory virtuale, che si potrà poi passare come parametro, oppure filtrando in base a un'estensione del tipo di file.
Un indicizzatore esegue il "cracking di un documento", aprendo un BLOB per esaminare il contenuto. Dopo la connessione all'origine dati, è il primo passaggio della pipeline. Per i dati BLOB, è la fase in cui vengono rilevati PDF, documenti di Office e altri tipi di contenuto. Il cracking di documenti con estrazione del testo non prevede alcun addebito. Se i BLOB contengono contenuto di tipo immagine, le immagini vengono ignorate, a meno che non si aggiunga l'arricchimento tramite intelligenza artificiale. L'indicizzazione standard si applica solo al contenuto di testo.
L'indicizzatore BLOB di Azure accetta parametri di configurazione e supporta il rilevamento delle modifiche se i dati sottostanti forniscono informazioni sufficienti. Altre informazioni sulle funzionalità di base sono disponibili in Dati dell'indice da Archiviazione BLOB di Azure.
Livelli di accesso supportati
I livelli di accesso di archiviazione BLOB includono accesso frequente, sporadico, saltuario e archivio. Gli indicizzatori possono recuperare BLOB in livelli di accesso frequente, sporadico e saltuario.
Tipi di contenuto supportati
Eseguendo un indicizzatore BLOB su un contenitore, è possibile estrarre testo e metadati dai tipi di contenuto seguenti con un'unica query:
- CSV (vedere Indicizzazione di BLOB CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (vedere Indicizzazione di BLOB JSON)
- KML (XML per le rappresentazioni geografiche)
- Formati di Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPTM, MSG (messaggi di posta elettronica di Outlook), XML (sia 2003 che 2006 WORD XML)
- Formati di documento aperti: ODT, ODS, ODP
- File di testo normale (vedere anche Indicizzazione di testo normale)
- RTF
- XML
- ZIP
Controllo dei BLOB da indicizzare
È possibile controllare quali BLOB vengono indicizzati, e quali vengono ignorati, dal tipo di file del BLOB oppure impostando le proprietà sul BLOB stesso, il che fa sì che l'indicizzatore li ignori.
Includere estensioni di file specifiche impostando "indexedFileNameExtensions" su un elenco delimitato da virgole di estensioni di file (con un punto iniziale). Escludere estensioni di file specifiche impostando "excludedFileNameExtensions" sulle estensioni da ignorare. Se la stessa estensione si trova in entrambi gli elenchi, questa viene esclusa dall'indicizzazione.
PUT /indexers/[indexer name]?api-version=2024-07-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Aggiungere metadati "ignora" al BLOB
I parametri di configurazione dell'indicizzatore si applicano a tutti i BLOB nel contenitore o nella cartella. In alcuni casi si desidera controllare il modo in cui vengono indicizzati i singoli BLOB.
Aggiungere le proprietà e i valori dei metadati seguenti ai BLOB in Archiviazione BLOB. Quando l'indicizzatore rileva questa proprietà, ignora il BLOB o il relativo contenuto nell'esecuzione dell'indicizzazione.
| Nome della proprietà | Valore proprietà | Spiegazione |
|---|---|---|
| "AzureSearch_Skip" | "true" |
Indica all'indicizzatore BLOB di ignorare completamente il BLOB. Non verrà tentata l'estrazione dei metadati né del contenuto. È utile quando un determinato BLOB ha ripetutamente esito negativo e interrompe il processo di indicizzazione. |
| "AzureSearch_SkipContent" | "true" |
Equivale all'impostazione "dataToExtract" : "allMetadata" descritta in precedenza nell'ambito di un BLOB specifico. |
Indicizzazione di metadati BLOB
Uno scenario comune che semplifica l'ordinamento nei BLOB di qualsiasi tipo di contenuto consiste nell'indicizzare i metadati personalizzati e le proprietà di sistema per ogni BLOB. In questo modo, le informazioni per tutti i BLOB vengono indicizzate indipendentemente dal tipo di documento, archiviate in un indice nel servizio di ricerca. Usando il nuovo indice, è quindi possibile ordinare, filtrare e ottimizzare tutto il contenuto dell'archivio BLOB.
Nota
I tag indice dei BLOB sono indicizzati in modo nativo dal servizio di archiviazione BLOB ed esposti per l'esecuzione di query. Se gli attributi chiave/valore dei BLOB richiedono funzionalità di indicizzazione e filtro, i tag di indice BLOB devono essere usati invece dei metadati.
Per altre informazioni sull'indice BLOB, vedere Gestire e trovare i dati in Archiviazione BLOB di Azure con l'indice BLOB.
Cercare contenuto BLOB in un indice di ricerca
L'output di un indicizzatore è un indice di ricerca, usato per l'esplorazione interattiva con query con testo libero e filtrate in un'app client. Per l'esplorazione iniziale e la verifica del contenuto, è consigliabile iniziare con Esplora ricerche nel portale di Azure per esaminare la struttura del documento. In Esplora ricerche è possibile usare:
Una soluzione più permanente consiste nel raccogliere gli input della query e presentare la risposta sotto forma di risultati della ricerca in un'applicazione client. L'esercitazione C# seguente illustra come creare un'applicazione di ricerca: Aggiungere la ricerca a un'applicazione ASP.NET Core (MVC).