Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Note
Gli archivi di conoscenze sono risorse di archiviazione secondarie presenti in Archiviazione di Azure e contengono gli output dei gruppi di competenze di Azure AI Search. Sono separati dalle origini delle informazioni e dalle basi di conoscenza, usate nei flussi di lavoro di recupero agentico.
L'archivio conoscenze è una risorsa di archiviazione secondaria per contenuti arricchiti con intelligenza artificiale creati da un set di competenze in Azure AI Search. In Azure AI Search, un processo di indicizzazione invia sempre l'output a un indice di ricerca, ma se si collega un set di competenze a un indicizzatore, è possibile inviare anche un output arricchito dall'intelligenza artificiale a un contenitore o a una tabella in Archiviazione di Azure. Un archivio conoscenze può essere usato per l'analisi indipendente o l'elaborazione downstream in scenari non di ricerca come il knowledge mining.
I due output dell'indicizzazione, un indice di ricerca e un archivio conoscenze, sono prodotti della stessa pipeline che si escludono a vicenda. Derivano dagli stessi input e contengono gli stessi dati, ma il contenuto è strutturato, archiviato e usato in applicazioni diverse.

Fisicamente, un archivio conoscenze è una risorsa di archiviazione di Azure, ad esempio una risorsa di archiviazione tabelle di Azure, di archiviazione BLOB di Azure o entrambe. Qualsiasi strumento o processo in grado di connettersi ad archiviazione di Azure può usare il contenuto di un archivio conoscenze. Non è disponibile alcun supporto per le query in Azure AI Search per il recupero di contenuti da un archivio conoscenze.
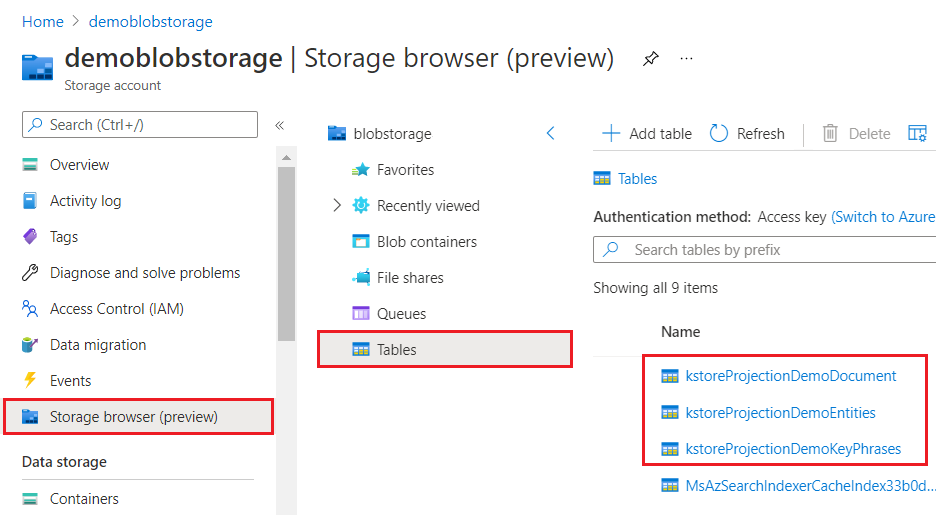
Quando viene visualizzato tramite il portale di Azure, un archivio conoscenze ha l’aspetto di qualsiasi altra raccolta di tabelle, oggetti o file. Lo screenshot seguente mostra un archivio conoscenze composto da tre tabelle. È possibile adottare una convenzione di denominazione, ad esempio un prefisso kstore, per mantenere insieme il contenuto.
Vantaggi del knowledge store
I principali vantaggi di un archivio conoscenze sono l'accesso flessibile al contenuto e la possibilità di modellare i dati.
A differenza di un indice di ricerca accessibile solo tramite query in Azure AI Search, un archivio conoscenze è accessibile a qualsiasi strumento, app o processo che supporta le connessioni ad Archiviazione di Azure. Questa flessibilità apre nuovi scenari per l'utilizzo del contenuto analizzato e arricchito prodotto da una pipeline di arricchimento.
Lo stesso set di competenze che arricchisce i dati può essere usato anche per modellare i dati. Alcuni strumenti come Power BI funzionano meglio con le tabelle, mentre un carico di lavoro di data science potrebbe richiedere una struttura di dati complessa in formato BLOB. L'aggiunta di una competenza Shaper a un set di competenze consente di controllare la forma dei dati. È quindi possibile passare queste forme alle proiezioni, ovvero tabelle o BLOB, per creare strutture di dati fisici allineate all'uso previsto dei dati.
Il video seguente illustra entrambi questi vantaggi e altro ancora.
Definizione di archivio conoscenze
Un archivio conoscenze viene definito all'interno della definizione di un set di competenze e ha due componenti:
Una stringa di connessione ad Archiviazione di Azure
Proiezioni che determinano se l'archivio conoscenze è costituito da tabelle, oggetti o file. L'elemento proiezioni è una matrice. È possibile creare più set di combinazioni file oggetto tabella all'interno di un archivio conoscenze.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Il tipo di proiezione specificato in questa struttura determina il tipo di archiviazione usato dall'archivio conoscenze, ma non la struttura. I campi in tabelle, oggetti e file sono determinati dall'output dell'abilità Shaper se si sta creando l'archivio delle conoscenze programmaticamente o tramite la procedura guidata Importa dati se si usa il portale di Azure.
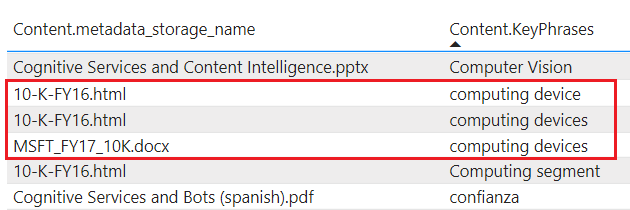
tablesproietta contenuto arricchito in Archiviazione tabelle. Definire una proiezione di tabella se si necessita di strutture di report tabulari per gli input negli strumenti analitici o per l'esportazione come frame di dati in altri archivi dati. È possibile specificare piùtablesall'interno dello stesso gruppo di proiezioni per ottenere un subset o una sezione trasversale dei documenti arricchiti. All'interno dello stesso gruppo di proiezione, le relazioni tra tabelle vengono conservate in modo che sia possibile utilizzarle tutte.Il contenuto proiettato non è aggregato o normalizzato. Lo screenshot seguente mostra una tabella, ordinata in base alla frase chiave, con il documento padre indicato nella colonna adiacente. A differenza dell'inserimento dati durante l'indicizzazione, non esiste alcuna analisi linguistica o aggregazione del contenuto. Le forme plurali e le differenze tra maiuscole e minuscole sono considerate istanze univoche.
objectsproietta il documento JSON nell'archivio BLOB. La rappresentazione fisica di unobjectè una struttura JSON gerarchica che rappresenta un documento arricchito.filesproietta i file di immagine nell'archivio BLOB. Unfileè un'immagine estratta da un documento, trasferita intatta nell'archiviazione BLOB. Anche se è denominato "file", viene visualizzato in Archiviazione BLOB, non nell'archiviazione file.
Creare un knowledge store
Usare il portale di Azure, le API REST o un pacchetto di Azure SDK per creare un archivio conoscenze. Tutti i metodi richiedono Archiviazione di Azure, un set di competenze e un indicizzatore. Poiché gli indicizzatori richiedono un indice di ricerca, è necessario specificare anche una definizione di indice.
LE API REST e gli SDK offrono il controllo completo sulle proiezioni: tabelle, oggetti e file. Il portale di Azure crea automaticamente un archivio conoscenze come parte del flusso di lavoro RAG multimodale, che è limitato alle proiezioni di file delle immagini estratte.
La procedura guidata Importa dati consente di creare un archivio di conoscenze solo per lo scenario RAG multimodale. Per iniziare, consulta Guida introduttiva: Ricerca multimodale nel portale di Azure.
Connettersi con le app
Una volta che i contenuti arricchiti sono presenti nell'archiviazione, è possibile usare qualsiasi strumento o tecnologia che si connette ad Archiviazione di Azure per esplorare, analizzare o utilizzare i contenuti. È possibile iniziare con l'elenco seguente:
Storage Explorer o browser archiviazione nel portale di Azure per visualizzare la struttura e i contenuti dei documenti arricchiti. Considerare questo strumento come lo strumento di base per visualizzare i contenuti del knowledge store.
Power BI per la creazione di report e l'analisi.
Azure Data Factory per ulteriori elaborazioni.
Ciclo di vita del contenuto
Ogni volta che si eseguono l'indicizzatore e il set di competenze, l’archivio conoscenze viene aggiornato se il set di competenze o i dati di origine sono stati modificati. Tutte le modifiche rilevate dall'indicizzatore vengono propagate tramite il processo di arricchimento alle proiezioni nell'archivio conoscenze, assicurandosi che i dati proiettati siano una rappresentazione attuale del contenuto nell'origine dati di origine.
Note
Anche se è possibile modificare i dati nelle proiezioni, qualsiasi modifica verrà sovrascritta nella chiamata alla pipeline successiva, presupponendo che il documento nei dati di origine sia aggiornato.
Modifiche apportate ai dati di origine
Per le origini dati che supportano il rilevamento delle modifiche, un indicizzatore elabora documenti nuovi e modificati e ignora i documenti esistenti già elaborati. Le informazioni sul timestamp variano in base all'origine dati, ma in un contenitore BLOB l'indicizzatore esamina la data lastmodified per determinare quali BLOB devono essere inseriti.
Modifiche a un set di competenze
Se si apportano modifiche a un set di competenze, è consigliabile abilitare la memorizzazione nella cache di documenti arricchiti per riutilizzare gli arricchimenti esistenti, se possibile.
Senza memorizzazione nella cache incrementale, l'indicizzatore elabora sempre i documenti in nell’ordine del punto più elevato, senza andare indietro. Per i BLOB, l'indicizzatore elabora i BLOB ordinati in base a lastModified, indipendentemente dalle modifiche apportate alle impostazioni dell'indicizzatore o al set di competenze. Se si modifica un set di competenze, i documenti elaborati in precedenza non vengono aggiornati per riflettere il nuovo set di competenze. I documenti elaborati dopo la modifica del set di competenze useranno il nuovo set di competenze, con conseguente combinazione di set di competenze vecchi e nuovi a comporre i documenti dell’indice.
Con la memorizzazione nella cache incrementale e dopo l’aggiornamento del set di competenze, l'indicizzatore riutilizza tutti gli arricchimenti che non sono interessati dalla modifica del set di competenze. Gli arricchimenti upstream vengono estratti dalla cache, come tutti gli arricchimenti indipendenti e isolati dalla competenza modificata.
Deletions
Anche se un indicizzatore crea e aggiorna strutture e contenuti in Archiviazione di Azure, non li elimina. Le proiezioni continuano a esistere anche quando l'indicizzatore o il set di competenze viene eliminato. Come proprietario dell'account di archiviazione, è necessario eliminare una proiezione se non è più necessaria.
Passaggi successivi
L'Archivio conoscenze offre la persistenza dei documenti arricchiti, utile durante la progettazione di un set di competenze o la creazione di nuove strutture e contenuto per l'utilizzo da parte di qualsiasi applicazione client in grado di accedere a un account di archiviazione di Azure.
L'approccio più semplice per la creazione di documenti arricchiti a livello di codice consiste nell'usare le API REST.