Indicizzatori in Azure AI Search
Un indicizzatore in Azure AI Search è un crawler che estrae dati testuali da origini dati cloud e popola un indice di ricerca usando mapping da campo a campo tra i dati di origine e un indice di ricerca. Questo approccio viene talvolta definito "modello pull" perché il servizio di ricerca esegue il pull dei dati in senza dover scrivere codice per aggiungere dati a un indice.
Gli indicizzatori gestiscono anche l'esecuzione del set di competenze e l'arricchimento tramite intelligenza artificiale, consentendo di configurare le competenze per integrare l'elaborazione aggiuntiva del contenuto durante l'instradamento a un indice. Alcuni esempi sono l'OCR sui file immagine, la capacità di suddividere il testo per la suddivisione in blocchi di dati e la traduzione di testi in più lingue.
Gli indicizzatori hanno come target le origini dati supportate. La configurazione di un indicizzatore specifica una origine dati (origine) e un indice di ricerca (destinazione). Diverse origini, ad esempio Archiviazione BLOB di Azure, dispongono di più proprietà di configurazione specifiche per quel tipo di contenuto.
È possibile eseguire gli indicizzatori su richiesta o in base a una pianificazione di aggiornamento dati ricorrente che viene eseguita ogni cinque minuti. Gli aggiornamenti più frequenti richiedono un 'modello push' che aggiorni contemporaneamente i dati sia in Azure AI Search che nell'origine dati esterna.
Un servizio di ricerca esegue un processo indicizzatore per ogni unità di ricerca. Se è necessaria l'elaborazione simultanea, assicurarsi di disporre di un numero di repliche sufficienti. Gli indicizzatori non vengono eseguiti in background, quindi è possibile rilevare una limitazione delle query maggiore del solito se il servizio è sotto pressione.
Scenari e casi d'uso dell'indicizzatore
È possibile usare un indicizzatore come unico mezzo per l'inserimento dei dati o in combinazione con altre tecniche. La tabella seguente riepiloga gli scenari principali.
| Scenario | Strategia |
|---|---|
| Singola origine dati | Questo modello è il più semplice: una origine dati è l'unico provider di contenuti per un indice di ricerca. La maggior parte delle origini dati supportate fornisce una qualche forma di rilevamento delle modifiche in modo che le successive esecuzioni dell'indicizzatore rilevino la differenza quando il contenuto viene aggiunto o aggiornato nell'origine. |
| Più origini dati | La specifica di un indicizzatore può avere una sola origine dati, ma l'indice di ricerca stesso può accettare contenuti da più origini, in cui ogni esecuzione dell'indicizzatore porta nuovi contenuti da un provider di dati diverso. Ogni origine può contribuire con la propria quota di documenti completi, oppure popolare campi selezionati in ogni documento. Per un'analisi più dettagliata di questo scenario, vedere Esercitazione: Indicizzazione da più origini dati. |
| Più indicizzatori | Più origini dati vengono in genere associate a più indicizzatori se è necessario variare i parametri di runtime, la pianificazione o i mapping dei campi. Un altro scenario è la Scalabilità orizzontale tra aree di Azure AI Search. È possibile che siano presenti copie dello stesso indice di ricerca in aree diverse. Per sincronizzare il contenuto dell'indice di ricerca, è possibile eseguire il pull di più indicizzatori dalla stessa origine dati, in cui ogni indicizzatore è destinato a un indice di ricerca diverso in ogni area. L' indicizzazione parallela di set di dati di grandi dimensioni richiede anche una strategia multi-indicizzatore, in cui ogni indicizzatore è destinato a un subset di dati. |
| Trasformazione del contenuto | Gli indicizzatori guidano l'esecuzione del set di competenze e l'arricchimento tramite intelligenza artificiale. Le trasformazioni del contenuto vengono definite in un set di competenze che viene collegato all'indicizzatore. È possibile usare le competenze per incorporare la suddivisione in blocchi di dati e la vettorializzazione. |
È consigliabile pianificare la creazione di un indicizzatore per ogni combinazione di indice di destinazione e origine dati. È possibile avere più indicizzatori che svolgono operazioni di scrittura nello stesso indice e riutilizzare la stessa origine dati per più indicizzatori. Tuttavia, un indicizzatore può utilizzare solo un'origine dati alla volta e può scrivere solo su un singolo indice. Come illustrato nell'immagine seguente, un'origine dati fornisce l'input a un indicizzatore, che a sua volta popola un singolo indice:

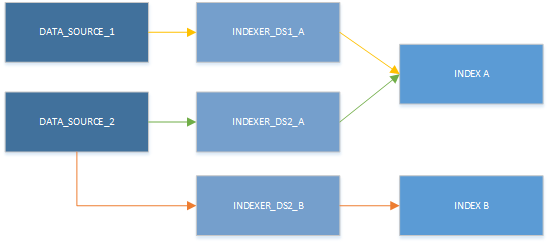
Sebbene sia possibile usare un solo indicizzatore alla volta, le risorse possono essere usate in diverse combinazioni. L'aspetto principale dell'illustrazione seguente è che l'origine dati può essere associata a più di un indicizzatore e che più indicizzatori possono scrivere sullo stesso indice.
Origini dati supportate
Gli indicizzatori effettuano una ricerca per indicizzazione negli archivi dati in Azure e all'esterno di Azure.
- Archiviazione BLOB di Azure
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Database SQL di Azure
- Archiviazione tabelle di Azure
- Istanza gestita di database SQL di Azure
- SQL Server in Macchine virtuali di Azure
- File di Azure (in anteprima)
- MySQL di Azure (in anteprima)
- SharePoint in Microsoft 365 (in anteprima)
- Azure Cosmos DB for MongoDB (in anteprima)
- Azure Cosmos DB for Apache Gremlin (in anteprima)
Azure Cosmos DB per Cassandra non è supportato.
Gli indicizzatori accettano set di righe bidimensionali, ad esempio una tabella o una vista, oppure elementi in un contenitore o in una cartella. Nella maggior parte dei casi, crea un documento di ricerca per riga, record o elemento.
Le connessioni dell'indicizzatore alle origini dati remote possono essere effettuate con connessioni Internet standard (pubbliche) o con connessioni private crittografate quando si usa un collegamento privato condiviso. È anche possibile configurare le connessioni per l'autenticazione usando un'identità gestita. Per altre informazioni sulle connessioni sicure, vedere Accesso dell'indicizzatore al contenuto protetto dalle funzionalità di sicurezza di rete di Azure e Connettersi a un'origine dati usando un'identità gestita.
Fasi dell'indicizzazione
In un'esecuzione iniziale, quando l'indice è vuoto, un indicizzatore leggerà tutti i dati forniti nella tabella o nel contenitore. Nelle esecuzioni successive, l'indicizzatore riesce solitamente a rilevare e recuperare solo i dati modificati. Per i dati BLOB, il rilevamento delle modifiche è automatico. Per altre origini dati come Azure SQL o Azure Cosmos DB, è necessario abilitare il rilevamento delle modifiche.
Per ogni documento ricevuto, un indicizzatore implementa o coordina più passaggi, dal recupero del documento al "passaggio" finale al motore di ricerca per l'indicizzazione. Facoltativamente, un indicizzatore gestisce anche l'esecuzione e l'output del set di competenze, sempre che sia stato definito un set di competenze.

Fase 1: Cracking di documenti
Il cracking di documenti è il processo di apertura dei file ed estrazione del contenuto. Il contenuto basato su testo può essere estratto da file in un servizio, da righe in una tabella o da elementi in un contenitore o raccolta. Se si aggiunge un set di competenze e le competenze di immagine, il cracking di documenti può anche estrarre le immagini e metterle in coda per l'elaborazione immagini.
A seconda dell'origine dati, l'indicizzatore tenterà diverse operazioni per estrarre il contenuto potenzialmente indicizzabile:
Quando il documento è un file con immagini incorporate, ad esempio un PDF, l'indicizzatore estrae testo, immagini e metadati. Gli indicizzatori possono aprire file da Archiviazione BLOB di Azure, Azure Data Lake Storage Gen2e SharePoint.
Quando il documento è un record in Azure SQL, l'indicizzatore estrae il contenuto non binario da ogni campo di ogni record.
Quando il documento è un record in Azure Cosmos DB, l'indicizzatore estrae il contenuto non binario dai campi e i sottocampi del documento di Azure Cosmos DB.
Fase 2: Mapping dei campi
Un indicizzatore estrae il testo da un campo di origine e lo invia a un campo di destinazione in un indice o in un archivio conoscenze. Quando i nomi dei campi e i tipi di dati coincidono, il percorso è chiaro. Tuttavia, potrebbe essere necessario specificare nomi o tipi diversi nell'output, nel qual caso sarà necessario indicare all'indicizzatore come eseguire il mapping del campo.
Per specificare i mapping dei campi, immettere i campi di origine e di destinazione nella definizione dell'indicizzatore.
Il mapping dei campi viene eseguito dopo il cracking di documenti, ma prima delle trasformazioni, quando l'indicizzatore legge dai documenti di origine. Quando si definisce un mapping dei campi, il valore del campo di origine viene inviato così com'è al campo di destinazione, senza modifiche.
Fase 3: Esecuzione del set di competenze
L'esecuzione del set di competenze è un passaggio facoltativo che richiama l'elaborazione di intelligenza artificiale predefinita o personalizzata. I set di competenze possono aggiungere il riconoscimento ottico dei caratteri (OCR) o altre forme di analisi delle immagini se il contenuto è binario. I set di competenze possono anche aggiungere l'elaborazione del linguaggio naturale. Ad esempio, è possibile aggiungere la traduzione del testo o l'estrazione di frasi chiave.
Qualunque sia la trasformazione, l'esecuzione del set di competenze è la posizione in cui avviene l'arricchimento. Se un indicizzatore è una pipeline, è possibile considerare un set di competenze come una "pipeline all'interno della pipeline".
Fase 4: Mapping dei campi di output
Se si include un set di competenze, è necessario specificare i mapping dei campi di output nella definizione dell'indicizzatore. L'output di un set di competenze viene visualizzato internamente come struttura ad albero denominata documento arricchito. I mapping dei campi di output consentono di selezionare le parti dell'albero di cui eseguire il mapping nei campi dell'indice.
Nonostante la somiglianza nei nomi, i mapping dei campi di output e i mapping dei campi creano associazioni da origini diverse. I mapping dei campi associano il contenuto del campo di origine a un campo di destinazione in un indice di ricerca. I mapping dei campi di output associano il contenuto di un documento arricchito interno (output delle competenze) ai campi di destinazione nell'indice. A differenza dei mapping dei campi, che sono considerati facoltativi, il mapping dei campi di output è necessario per qualsiasi contenuto trasformato che debba essere presente nell'indice.
L'immagine successiva mostra una sessione di debug dell'indicizzatore che rappresenta le fasi dell'indicizzatore: cracking di documenti, mapping dei campi, esecuzione del sessione di competenze e mapping dei campi di output.

Flusso di lavoro di base
Gli indicizzatori possono offrire funzionalità univoche per l'origine dati. In questo senso, alcuni aspetti della configurazione dell'indicizzatore o dell'origine dati possono variare a seconda del tipo di indicizzatore. Tutti gli indicizzatori, tuttavia, condividono la stessa composizione e gli stessi requisiti di base. Le procedure comuni a tutti gli indicizzatori sono descritte sotto.
Passaggio 1: Creare un'origine dati
Gli indicizzatori richiedono un oggetto origine dati che fornisce una stringa di connessione ed eventualmente le credenziali. Le origini dati sono oggetti indipendenti. Più indicizzatori possono usare lo stesso oggetto origine dati per caricare più indici alla volta.
È possibile creare un'origine dati usando uno di questi approcci:
- Usando il portale di Azure, nella scheda origini dati delle pagine del servizio di ricerca selezionare Aggiungi origine dati per specificare la definizione dell'origine dati.
- Usando il portale di Azure, la procedura Importazione guidata dati restituisce un'origine dati.
- Usando le API REST, chiamare Crea origine dati.
- Usando Azure SDK per .NET, chiamare la classe SearchIndexerDataSourceConnection
Passaggio 2: Creare un indice
Un indicizzatore consente di automatizzare alcune attività relative all'inserimento dei dati, ma la creazione di un indice in genere non fa parte di esse. Come prerequisito, è necessario disporre di un indice predefinito che contenga i campi di destinazione corrispondenti per tutti i campi di origine nell'origine dati esterna. I campi devono corrispondere per nome e tipo di dati. In caso contrario, è possibile definire i mapping dei campi per stabilire l'associazione.
Per altre informazioni, vedere Creare un indice.
Passaggio 3: Creare ed eseguire (o pianificare) l'indicizzatore
La definizione di un indicizzatore consiste in proprietà che identificano in modo univoco l'indicizzatore, specificano l'origine dati e l'indice da usare e forniscono altre opzioni di configurazione che influenzano il comportamento di runtime, tra cui l'esecuzione dell'indicizzatore su richiesta o in base a una pianificazione.
Eventuali errori o avvisi relativi all'accesso ai dati o alla convalida del set di competenze si verificheranno durante l'esecuzione dell'indicizzatore. Fino all'avvio dell'esecuzione dell'indicizzatore, gli oggetti dipendenti, come le origini dati, gli indici e i set di competenze sono passivi sul servizio di ricerca.
Per altre informazioni, vedere Creare un indicizzatore
Dopo la prima esecuzione dell'indicizzatore, è possibile eseguirla di nuovo su richiesta o configurare una pianificazione.
È possibile monitorare lo stato dell'indicizzatore nel portale o tramite l'API Get Indexer Status. È anche necessario eseguire query sull'indice per verificare che il risultato sia quello previsto.
Gli indicizzatori non dispongono di risorse di elaborazione dedicate. Per questo motivo, lo stato degli indicizzatori può essere visualizzato come inattivo prima dell'esecuzione (a seconda dei processi in coda) e i tempi di esecuzione potrebbero non essere prevedibili. Anche altri fattori definiscono le prestazioni dell'indicizzatore, tra cui le dimensioni e la complessità del documento, l'analisi delle immagini, tra gli altri.
Passaggi successivi
Dopo aver introdotto gli indicizzatori, il passo successivo è quello di esaminare le proprietà, i parametri, la pianificazione e il monitoraggio dell'indicizzatore. In alternativa, è possibile tornare all'elenco delle origini dati supportate per altre informazioni su un'origine specifica.