Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In Ricerca di intelligenza artificiale di Azure esistono diversi modi per eseguire un indicizzatore:
- Eseguire immediatamente al momento della creazione dell'indicizzatore. Si tratta dell'impostazione predefinita, a meno che non si crei l'indicizzatore in uno stato "disabilitato".
- Eseguire in base a una pianificazione per richiamare l'esecuzione a intervalli regolari.
- Eseguire su richiesta, con o senza una "ripristino".
Questo articolo illustra come eseguire indicizzatori su richiesta, con e senza reimpostazione. Descrive anche l'esecuzione, la durata e la concorrenza dell'indicizzatore.
Come gli indicizzatori si connettono alle risorse di Azure
Gli indicizzatori sono uno dei pochi sottosistemi che effettuano chiamate in uscita ad altre risorse di Azure. È possibile usare chiavi o ruoli per autenticare la connessione.
In termini di ruoli di Azure, gli indicizzatori non hanno identità separate: una connessione dal motore di ricerca a un'altra risorsa di Azure viene eseguita usando l'identità gestita assegnata dal sistema o dall'utente di un servizio di ricerca, oltre a un'assegnazione di ruolo nella risorsa di Azure di destinazione. Se l'indicizzatore si connette a una risorsa di Azure in una rete virtuale, è necessario creare un collegamento privato condiviso per tale connessione.
Esecuzione dell'indicizzatore
Un servizio di ricerca esegue un processo indicizzatore per ogni unità di ricerca. Ogni servizio di ricerca inizia con un'unità di ricerca, ma ogni nuova partizione o replica aumenta le unità di ricerca del servizio. È possibile controllare il numero di unità di ricerca nella sezione Informazioni di base del portale di Azure della pagina Panoramica. Se è necessaria un'elaborazione simultanea, assicurarsi che le unità di ricerca includano repliche sufficienti. Gli indicizzatori non vengono eseguiti in background, quindi è probabile che si verifichino più limitazioni delle query rispetto al solito se il servizio è sotto carico.
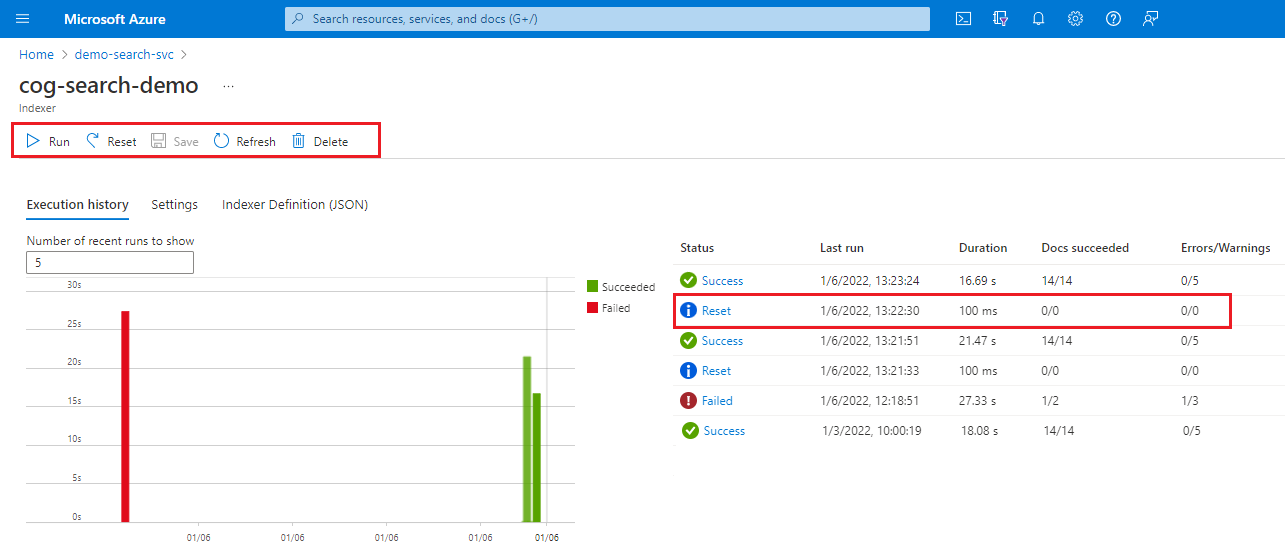
Lo screenshot seguente mostra il numero di unità di ricerca, che determina il numero di indicizzatori che possono essere eseguiti contemporaneamente.

Una volta avviata l'esecuzione dell'indicizzatore, non è possibile sospendere o arrestarla. L'esecuzione dell'indicizzatore si arresta quando non sono più presenti documenti da caricare o aggiornare o quando viene raggiunto il limite massimo di tempo di esecuzione.
È possibile eseguire più indicizzatori contemporaneamente presupponendo capacità sufficiente, ma ogni indicizzatore è a istanza singola. L'avvio di una nuova istanza mentre l'indicizzatore è già in esecuzione genera questo errore: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Ambiente di esecuzione dell'indicizzatore
Un processo dell'indicizzatore viene eseguito in un ambiente di esecuzione gestito. Attualmente sono disponibili due ambienti:
Un ambiente di esecuzione privato viene eseguito nei cluster di ricerca specifici del servizio di ricerca.
Un ambiente multi-tenant include processori di contenuto gestiti e protetti da Microsoft senza costi aggiuntivi. Questo ambiente viene usato per eseguire l'offload dell'elaborazione a elevato utilizzo di calcolo, lasciando disponibili risorse specifiche del servizio per le operazioni di routine. Quando possibile, la maggior parte dei set di competenze viene eseguita nell'ambiente multi-tenant. Si tratta dell'impostazione predefinita.
L'elaborazione a elevato utilizzo di calcolo si riferisce a set di competenze in esecuzione su processori di contenuto e processi indicizzatore che elaborano un volume elevato di documenti o documenti di grandi dimensioni. La gestione delle elaborazioni sui processori di contenuti multi-tenant, che non riguarda le competenze, è determinata da euristiche e informazioni di sistema e non è sotto il controllo dei clienti.
È possibile impedire l'utilizzo dell'ambiente multi-tenant nei servizi Standard2 o superiori aggiungendo un indicizzatore e l'elaborazione del set di competenze esclusivamente ai cluster di ricerca.
Impostare il executionEnvironment parametro nella definizione dell'indicizzatore per eseguire sempre un indicizzatore nell'ambiente di esecuzione privato.
I firewall IP bloccano l'ambiente multi-tenant, quindi, se si dispone di un firewall, creare una regola che consenta le connessioni del processore multi-tenant.
I limiti dell'indicizzatore variano per ogni ambiente:
| Carico di lavoro | Durata massima | Numero massimo di processi | Ambiente di esecuzione |
|---|---|---|---|
| Esecuzione privata | 24 ore | Un processo indicizzatore per unità di ricerca1. | L'indicizzazione non viene eseguita in background. Il servizio di ricerca bilancia invece tutti i processi di indicizzazione rispetto alle query in corso e alle azioni di gestione degli oggetti, ad esempio la creazione o l'aggiornamento di indici. Quando si eseguono indicizzatori, è consigliabile vedere una latenza di query se i volumi di indicizzazione sono di grandi dimensioni. |
| Multi-tenant | 2 ore 2 | Indeterminato 3 | Poiché il cluster di elaborazione del contenuto è multi-tenant, i processori di contenuto vengono aggiunti per soddisfare la domanda. Se si verifica un ritardo nell'esecuzione su richiesta o pianificata, è probabile che il sistema stia aggiungendo processori o aspettando che uno diventi disponibile. |
1 Le unità di ricerca possono essere combinazioni flessibili di partizioni e repliche, ma i processi dell'indicizzatore non sono associati a uno o all'altro. In altre parole, se si dispone di 12 unità, è possibile avere 12 processi indicizzatore in esecuzione simultaneamente nell'esecuzione privata, indipendentemente dalla modalità di distribuzione delle unità di ricerca.
2 Se sono necessarie più di due ore per elaborare tutti i dati, abilitare il rilevamento delle modifiche e pianificare l'esecuzione dell'indicizzatore a intervalli di 5 minuti per riprendere rapidamente l'indicizzazione se si arresta a causa di un timeout. Per altre strategie, vedere Indicizzazione di un set di dati di grandi dimensioni .
3 "Indeterminate" indica che il limite non è quantificato in base al numero di processi. Alcuni carichi di lavoro, ad esempio l'elaborazione del set di competenze, possono essere eseguiti in parallelo, il che potrebbe comportare molti processi anche se è coinvolto un solo indicizzatore. Anche se l'ambiente non impone vincoli, i limiti dell'indicizzatore per il servizio di ricerca vengono ancora applicati.
Esecuzione senza reimpostazione
Un'operazione Esegui indicizzatore rileva ed elabora solo ciò che è necessario per sincronizzare l'indice di ricerca con le modifiche nell'origine dati sottostante. L'indicizzazione incrementale inizia individuando un contrassegno interno ad alta acqua per trovare l'ultimo documento di ricerca aggiornato, che diventa il punto di partenza per l'esecuzione dell'indicizzatore su documenti nuovi e aggiornati nell'origine dati.
Rilevamento modifiche è essenziale per determinare le novità o gli aggiornamenti nell'origine dati. Gli indicizzatori usano le funzionalità di rilevamento delle modifiche dell'origine dati sottostante per determinare le novità o gli aggiornamenti nell'origine dati.
Archiviazione di Azure include il rilevamento delle modifiche predefinito tramite la relativa proprietà LastModified.
È necessario configurare altre origini dati, ad esempio Azure SQL o Azure Cosmos DB, per il rilevamento delle modifiche prima che l'indicizzatore possa leggere righe nuove e aggiornate.
Se il contenuto sottostante è invariato, un'operazione di esecuzione non ha alcun effetto. In questo caso, la cronologia di esecuzione dell'indicizzatore indica 0\0 i documenti elaborati.
È necessario reimpostare l'indicizzatore, come illustrato nella sezione successiva, per rielaborare completamente.
Reimpostazione degli indicizzatori
Dopo l'esecuzione iniziale, un indicizzatore monitora i documenti indicizzati tramite un livello di riferimento interno. Il marcatore non viene mai esposto, ma internamente l'indicizzatore sa dove è stato arrestato.
Se è necessario ricompilare tutto o parte di un indice, usare le API Reset disponibili a livelli decrescenti nella gerarchia degli oggetti:
- Reimpostare indicizzatori cancella il contrassegno ad alta acqua ed esegue una reindicizzazione completa di tutti i documenti
- Resync Indexers (anteprima) esegue una reindicizzazione parziale efficiente di tutti i documenti
- Reimpostare i documenti (anteprima) reindicizza un documento o un elenco di documenti specifici
- Reimpostare le competenze (anteprima) richiama l'elaborazione delle competenze per una competenza specifica
Dopo la reimpostazione, seguire il comando Esegui per rielaborare i documenti nuovi ed esistenti. I documenti di ricerca orfani che non hanno alcuna controparte nell'origine dati non possono essere rimossi tramite reimpostazione/esecuzione. Se è necessario eliminare documenti, vedere Documenti - Indice.
Nota
Le tabelle non possono essere vuote. Se si usa TRUNCATE TABLE per cancellare le righe, una reimpostazione e una riesecuzione dell'indicizzatore non rimuoverà i documenti di ricerca corrispondenti. Per rimuovere i documenti di ricerca orfani, è necessario indicizzarli con un'azione di eliminazione.
Come reimpostare ed eseguire indicizzatori
Reimpostare cancella il segno d'acqua elevato. Tutti i documenti nell'indice di ricerca vengono contrassegnati per la sovrascrittura completa, senza aggiornamenti inline o unione nel contenuto esistente. Per gli indicizzatori con un set di competenze e la memorizzazione nella cache di arricchimento, la reimpostazione dell'indice comporta anche una reimpostazione del set di competenze.
Il lavoro effettivo si verifica quando si segue una reimpostazione con un comando Esegui:
- Tutti i nuovi documenti trovati nell'origine sottostante vengono aggiunti all'indice di ricerca.
- Tutti i documenti presenti sia nell'origine dati che nell'indice di ricerca vengono sovrascritti nell'indice di ricerca.
- Tutti i contenuti arricchiti creati dai set di competenze vengono ricompilati. La cache di arricchimento, se abilitata, viene aggiornata.
Come indicato in precedenza, la reimpostazione è un'operazione passiva: è necessario seguire con una richiesta Esegui per ricompilare l'indice.
Le operazioni di reimpostazione/esecuzione si applicano a un indice di ricerca o a un archivio conoscenze, a documenti o proiezioni specifici e agli arricchimenti memorizzati nella cache se una reimpostazione include in modo esplicito o implicito le competenze.
La reimpostazione si applica anche alle operazioni di creazione e aggiornamento. Non attiverà l'eliminazione o la pulizia dei documenti orfani nell'indice di ricerca. Per altre informazioni sull'eliminazione di documenti, vedere Documenti - Indice.
Dopo aver reimpostato un indicizzatore, non è possibile annullare l'azione.
Accedere al portale di Azure e aprire la pagina del servizio di ricerca.
Nella pagina Panoramica selezionare la scheda Indicizzatori.
Selezionare un indicizzatore.
Selezionare il comando Reimposta e quindi selezionare Sì per confermare l'azione.
Aggiornare la pagina per visualizzare lo stato. È possibile selezionare l'elemento per visualizzarne i dettagli.
Selezionare Esegui per avviare l'elaborazione dell'indicizzatore oppure attendere l'esecuzione pianificata successiva.
Come reimpostare le competenze (anteprima)
Per gli indicizzatori con set di competenze, è possibile reimpostare le singole competenze per forzare l'elaborazione di tale competenza e qualsiasi competenza downstream che dipende dall'output. Anche la cache di arricchimento, se abilitata, viene aggiornata.
Reset Skills è attualmente disponibile solo REST, disponibile fino alla versione 2020-06-30-anteprima o successiva. È consigliabile usare l'API di anteprima più recente.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
È possibile specificare singole competenze, come indicato nell'esempio precedente, ma se una di queste competenze richiede output da competenze non elencate (da 2 a 4), le competenze non elencate verranno eseguite a meno che la cache non possa fornire le informazioni necessarie. Affinché ciò sia vero, gli arricchimenti memorizzati nella cache per le competenze da 2 a #4 non devono avere dipendenze da #1 (elencato per la reimpostazione).
Se non vengono specificate competenze, viene eseguito l'intero set di competenze e, se la memorizzazione nella cache è abilitata, viene aggiornata anche la cache.
Ricordarsi di eseguire il completamento con Run Indexer per richiamare l'elaborazione effettiva.
Come reimpostare la documentazione (anteprima)
Gli indicizzatori - Reimposta documenti accettano un elenco di chiavi di documento in modo da poter aggiornare documenti specifici. Se specificato, i parametri di reimpostazione diventano l'unico determinante di ciò che viene elaborato, indipendentemente dalle altre modifiche nei dati sottostanti. Ad esempio, se sono stati aggiunti o aggiornati 20 BLOB dall'ultima esecuzione dell'indicizzatore, ma si reimposta un solo documento, solo il documento viene elaborato.
Per ogni documento, tutti i campi del documento di ricerca vengono aggiornati con valori e metadati dall'origine dati. Non è possibile selezionare e scegliere i campi da aggiornare.
Se l'origine dati è Azure Data Lake Storage (ADLS) Gen2 e i blob sono associati ai metadati delle autorizzazioni, quelle autorizzazioni vengono reintrodotte nell'indice di ricerca se cambiano nei dati sottostanti. Per altre informazioni, vedere Re-indexing ACL and RBAC scope with ADLS Gen2 indexers (Ridedicizzazione dell'ACL e dell'ambito RBAC con indicizzatori ADLS Gen2).
Se il documento viene arricchito tramite un set di competenze e contiene dati memorizzati nella cache, il set di competenze viene richiamato solo per i documenti specificati e la cache viene aggiornata per i documenti rielaborati.
Quando si testa questa API per la prima volta, le API seguenti consentono di convalidare e testare i comportamenti. È possibile usare l'API di anteprima versione 2020-06-30-preview e successive. È consigliabile usare l'API di anteprima più recente.
Chiamare Indicizzatori: ottieni stato con una versione dell'API di anteprima per controllare lo stato di reimpostazione e lo stato di esecuzione. È possibile trovare informazioni sulla richiesta di reimpostazione alla fine della risposta di stato.
Chiamare Indicizzatori: reimposta la documentazione con una versione dell'API di anteprima per specificare i documenti da elaborare.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Le chiavi del documento fornite nella richiesta sono valori dell'indice di ricerca, che possono essere diversi dai campi corrispondenti nell'origine dati. Se non si è certi del valore della chiave, inviare una query per restituire il valore. È possibile usare
selectper restituire solo il campo chiave del documento.Per i BLOB analizzati in più documenti di ricerca (dove parsingMode è impostato su jsonLines o jsonArrays o delimitedText), la chiave del documento viene generata dall'indicizzatore e potrebbe essere sconosciuta. In questo scenario, una query per la chiave del documento per restituire il valore corretto.
Chiamare Esegui l’indicizzatore (qualsiasi versione dell'API) per elaborare i documenti specificati. Vengono indicizzati solo i documenti specifici.
Chiamare Esegui Indicizzatore una seconda volta per l'elaborazione dall'ultimo segno di acqua alta.
Chiamare cerca documenti per verificare la presenza di valori aggiornati e anche per restituire le chiavi del documento se non si è certi del valore. Usare
"select": "<field names>"se si desidera limitare i campi visualizzati nella risposta.
Sovrascrivere l'elenco di chiavi del documento
Chiamando l'API Reimposta documenti più volte con chiavi diverse, le nuove chiavi vengono aggiunte all'elenco delle chiavi del documento reimpostate. Se si chiama l'API con il parametro overwrite impostato su true, l'elenco corrente verrà sovrascritto con quello nuovo:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Come risincronizzare gli indicizzatori (anteprima)
Resync Indexers è una nuova API di anteprima che esegue una reindicizzazione parziale di tutti i documenti. Un indicizzatore viene considerato sincronizzato con l'origine dati quando campi specifici di tutti i documenti nell'indice di destinazione sono coerenti con i dati nell'origine dati. In genere, un indicizzatore ottiene la sincronizzazione dopo un'esecuzione iniziale riuscita. Se un documento viene eliminato dall'origine dati, l'indicizzatore rimane sincronizzato in base a questa definizione. Tuttavia, durante l'esecuzione successiva dell'indicizzatore, il documento corrispondente nell'indice di destinazione verrà rimosso se il rilevamento dell'eliminazione è abilitato.
Se un documento viene modificato nell'origine dati, l'indicizzatore diventa non sincronizzato. In genere, i meccanismi di rilevamento delle modifiche risincronizzeranno l'indicizzatore durante l'esecuzione successiva. Ad esempio, in Archiviazione di Azure, la modifica di un BLOB aggiorna l'ora dell'ultima modifica, consentendone la reindicizzazione nell'esecuzione successiva dell'indicizzatore perché il tempo aggiornato supera il limite massimo impostato dall'esecuzione precedente.
Al contrario, per determinate origini dati come ADLS Gen2, la modifica degli elenchi di controllo di accesso (ACL) di un BLOB non modifica il tempo dell'ultima modifica, rendendo inefficace il rilevamento delle modifiche se gli elenchi di controllo di accesso devono essere inglobati. Di conseguenza, il blob modificato non verrà indicizzato nuovamente nell'esecuzione successiva, perché vengono elaborati solo i documenti modificati dopo l'ultimo punto di riferimento.
Anche se l'uso di "reset" o "reset docs" può risolvere questo problema, la "reimpostazione" può richiedere molto tempo e inefficiente per i set di dati di grandi dimensioni e "reimpostare la documentazione" richiede l'identificazione della chiave del documento del BLOB destinata all'aggiornamento.
Resync Indexers offre un'alternativa efficiente e conveniente. Gli utenti posizionano semplicemente l'indicizzatore in modalità risincronizzazione e specificano il contenuto da risincronizzare chiamando l'API degli indicizzatori risincroni. Nell'esecuzione successiva, l'indicizzatore esamina solo la parte rilevante dei dati nell'origine ed evita qualsiasi elaborazione non necessaria non correlata ai dati specificati. Eseguirà anche una query sui documenti esistenti nell'indice di destinazione e aggiornerà solo i documenti che mostrano discrepanze tra l'origine dati e l'indice di destinazione. Dopo la risincronizzazione, l'indicizzatore verrà sincronizzato e ripristinato alla modalità di esecuzione ordinaria per le esecuzioni successive.
Come risincronizzare ed eseguire indicizzatori
Richiama Indiciatori - Risincronizza con una versione di anteprima dell'API per specificare quale contenuto risincronizzare.
POST https://[service name].search.windows.net/indexers/[indexer name]/resync?api-version=2025-05-01-preview { "options" : [ "permissions" ] }- Il campo
optionsè obbligatorio. Attualmente l'unica opzione supportata èpermissions. Ovvero, verranno aggiornati solo i campi di filtro delle autorizzazioni nell'indice di destinazione.
- Il campo
Chiamare Run Indexer (qualsiasi versione dell'API) per sincronizzare nuovamente l'indicizzatore.
Chiamare Esegui Indicizzatore una seconda volta per l'elaborazione dall'ultimo segno di acqua alta.
Controllare lo stato di reimpostazione "currentState"
Per controllare lo stato di reimpostazione e per vedere quali chiavi del documento vengono accodate per l'elaborazione, seguire questa procedura.
Chiamare Ottieni stato indicizzatore con un'API di anteprima.
L'API di anteprima restituirà la sezione
currentState, trovata alla fine della risposta."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resyncInitialTrackingState": null, "resyncFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Controllare la "modalità":
Per Reimposta competenze, "modalità" deve essere impostato su
indexingAllDocs(perché potenzialmente tutti i documenti sono interessati, in termini di campi popolati tramite l'arricchimento tramite intelligenza artificiale).Per gli indicizzatori risincroni, "mode" deve essere impostato su
indexingResync. L'indicizzatore controlla tutti i documenti e si concentra sui dati interessati nell'origine dati e sui campi interessati nell'indice di destinazione.Per Reimposta documenti, "modalità" deve essere impostato su
indexingResetDocs. L'indicizzatore mantiene questo stato finché non vengono elaborate tutte le chiavi del documento fornite nella chiamata ai documenti di reimpostazione, durante il quale non verranno eseguiti altri processi dell'indicizzatore durante l'avanzamento dell'operazione. L'individuazione di tutti i documenti nell'elenco delle chiavi del documento richiede l'individuazione e la corrispondenza di ogni documento sulla chiave e questo può richiedere del tempo se il set di dati è di grandi dimensioni. Se un contenitore BLOB contiene centinaia di BLOB e i documenti da reimpostare sono alla fine, l'indicizzatore non troverà i BLOB corrispondenti fino a quando tutti gli altri non saranno stati controllati per primi.Dopo la rielaborazione dei documenti, eseguire di nuovo Get Indexer Status (Ottieni stato indicizzatore). L'indicizzatore torna alla modalità
indexingAllDocsed elabora tutti i documenti nuovi o aggiornati all'esecuzione successiva.
Passaggi successivi
Le API di reimpostazione vengono usate per informare l'ambito dell'esecuzione successiva dell'indicizzatore. Per l'elaborazione effettiva, è necessario richiamare un'esecuzione dell'indicizzatore su richiesta o consentire a un processo pianificato di completare il lavoro. Al termine dell'esecuzione, l'indicizzatore torna alla normale elaborazione, indipendentemente dal fatto che si tratti di una pianificazione o di un'elaborazione su richiesta.
Dopo aver reimpostato ed eseguito di nuovo i processi dell'indicizzatore, è possibile monitorare lo stato dal servizio di ricerca o ottenere informazioni dettagliate tramite la registrazione delle risorse.