Creare un indicizzatore in Ricerca di intelligenza artificiale di Azure
Usare un indicizzatore per automatizzare l'importazione e l'indicizzazione dei dati in Ricerca di intelligenza artificiale di Azure. Un indicizzatore è un oggetto denominato in un servizio di ricerca che si connette a un'origine dati esterna di Azure, legge i dati e lo passa a un motore di ricerca per l'indicizzazione. L'uso degli indicizzatori riduce significativamente la quantità e la complessità del codice che è necessario scrivere se si usa un'origine dati supportata.
Gli indicizzatori supportano due flussi di lavoro:
Indicizzazione basata su testo, estrazione di stringhe e metadati dal contenuto testuale per scenari di ricerca full-text.
Indicizzazione basata sulle competenze, usando competenze predefinite o personalizzate che aggiungono l'apprendimento automatico integrato per l'analisi sulle immagini e su contenuti indifferenziati di grandi dimensioni, l'estrazione o l'inferenza di testo e struttura. L'indicizzazione basata su competenze consente la ricerca su contenuto che non è altrimenti facilmente ricercabile full-text. Per altre informazioni, vedere Arricchimento tramite intelligenza artificiale in Ricerca di intelligenza artificiale di Azure.
Questo articolo è incentrato sui passaggi di base della creazione di un indicizzatore. A seconda dell'origine dati e del flusso di lavoro, potrebbe essere necessaria una configurazione maggiore.
Prerequisiti
Origine dati supportata che contiene il contenuto da inserire.
Origine dati dell'indicizzatore che configura una connessione a dati esterni.
Indice di ricerca che può accettare i dati in ingresso.
Essere sotto i limiti massimi per il livello di servizio. Il livello Gratuito consente tre oggetti di ogni tipo e 1-3 minuti di elaborazione dell'indicizzatore o 3-10 se è presente un set di competenze.
Modelli dell'indicizzatore
Quando si crea un indicizzatore, la definizione è uno dei due modelli seguenti: indicizzazione basata su testo o arricchimento tramite intelligenza artificiale con competenze. I modelli sono gli stessi, ad eccezione del fatto che l'indicizzazione basata sulle competenze ha più definizioni.
Esempio di indicizzatore per l'indicizzazione basata su testo
L'indicizzazione basata su testo per la ricerca full-text è il caso d'uso principale per gli indicizzatori e, per questo flusso di lavoro, un indicizzatore è simile a questo esempio.
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
Gli indicizzatori hanno i requisiti seguenti:
- Proprietà
"name"che identifica in modo univoco l'indicizzatore nell'insieme dell'indicizzatore. - Proprietà
"dataSourceName"che punta a un oggetto origine dati. Specifica una connessione a dati esterni. - Proprietà
"targetIndexName"che punta all'indice di ricerca di destinazione.
Altri parametri sono facoltativi e modificano i comportamenti di runtime, ad esempio il numero di errori da accettare prima di non riuscire l'intero processo. I parametri obbligatori vengono specificati in tutti gli indicizzatori e sono documentati nelle informazioni di riferimento sull'API REST.
Gli indicizzatori specifici dell'origine dati per BLOB, SQL e Azure Cosmos DB forniscono parametri aggiuntivi "configuration" per comportamenti specifici dell'origine. Ad esempio, se l'origine è Blob Archiviazione, è possibile impostare un parametro che filtra le estensioni di file: "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } }. Se l'origine è Azure SQL, è possibile impostare un parametro di timeout della query.
I mapping dei campi vengono usati per eseguire il mapping esplicito dei campi da origine a destinazione in caso di discrepanze in base al nome o al tipo tra un campo nell'origine dati e un campo nell'indice di ricerca.
Per impostazione predefinita, un indicizzatore viene eseguito immediatamente quando viene creato nel servizio di ricerca. Se non si vuole eseguire l'indicizzatore, impostare su "disabled" true durante la creazione dell'indicizzatore.
È anche possibile specificare una pianificazione o impostare una chiave di crittografia per la crittografia supplementare della definizione dell'indicizzatore.
Esempio di indicizzatore per l'indicizzazione basata sulle competenze
Gli indicizzatori determinano anche l'arricchimento tramite intelligenza artificiale. Tutte le proprietà e i parametri precedenti da applicare, ma le proprietà aggiuntive seguenti sono specifiche per l'arricchimento tramite intelligenza artificiale: "skillSetName", , "cache""outputFieldMappings".
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
L'arricchimento tramite intelligenza artificiale è una propria area di interesse ed è fuori ambito per questo articolo. Per altre informazioni, iniziare con l'arricchimento tramite intelligenza artificiale, i set di competenze in Ricerca di intelligenza artificiale di Azure, Creare un set di competenze, mappare i campi di output di arricchimento del mapping e Abilitare la memorizzazione nella cache per l'arricchimento tramite intelligenza artificiale.
Preparare i dati esterni
Gli indicizzatori funzionano con i set di dati. Quando si esegue un indicizzatore, si connette all'origine dati, recupera i dati dal contenitore o dalla cartella, serializzandoli facoltativamente in JSON prima di passarli al motore di ricerca per l'indicizzazione. Questa sezione descrive i requisiti dei dati in ingresso per l'indicizzazione basata su testo.
| Dati di origine | Attività |
|---|---|
| Documenti JSON | Assicurarsi che la struttura o la forma dei dati in ingresso corrisponda allo schema dell'indice di ricerca. La maggior parte degli indici di ricerca è piuttosto piatta, in cui la raccolta di campi è costituita da campi allo stesso livello. Tuttavia, le strutture gerarchica o nidificate sono possibili tramite campi e raccolte complessi. |
| Relazionale | Specificarlo come set di righe bidimensionale, in cui ogni riga diventa un documento di ricerca completo o parziale nell'indice. Per rendere flat i dati relazionali in un set di righe, è necessario creare una vista SQL o creare una query che restituisca record padre e figlio nella stessa riga. Ad esempio, il set di dati di esempio di hotel predefiniti è un database SQL con 50 record (uno per ogni hotel), collegato ai record delle sale in una tabella correlata. La query che rende flat i dati collettivi in un set di righe incorpora tutte le informazioni sulla stanza nei documenti JSON in ogni record dell'hotel. Le informazioni sulle sale incorporate sono generate da una query che usa una clausola FOR JSON AUTO . Per altre informazioni su questa tecnica, vedere Definire una query che restituisce JSON incorporato. Questo è solo un esempio; è possibile trovare altri approcci che producono lo stesso risultato. |
| File | Un indicizzatore crea in genere un documento di ricerca per ogni file, in cui il documento di ricerca è costituito da campi per contenuto e metadati. A seconda del tipo di file, l'indicizzatore può talvolta analizzare un file in più documenti di ricerca. Ad esempio, in un file CSV ogni riga può diventare un documento di ricerca autonomo. |
Tenere presente che è sufficiente eseguire il pull dei dati ricercabili e filtrabili:
- I dati ricercabili sono testo.
- I dati filtrabili sono alfanumerici.
Ricerca di intelligenza artificiale di Azure non può eseguire ricerche sui dati binari in alcun formato, anche se può estrarre e dedurre descrizioni di testo dei file di immagine (vedere Arricchimento tramite intelligenza artificiale) per creare contenuto ricercabile. Analogamente, il testo di grandi dimensioni può essere suddiviso e analizzato dai modelli in linguaggio naturale per trovare la struttura o le informazioni pertinenti, generando nuovo contenuto che è possibile aggiungere a un documento di ricerca.
Dato che gli indicizzatori non risondono problemi di dati, potrebbero essere necessarie altre forme di pulizia o manipolazione dei dati. Per altre informazioni, vedere la documentazione del prodotto di database di Azure.
Preparare un'origine dati
Gli indicizzatori richiedono un'origine dati che specifica il tipo, il contenitore e la connessione.
Assicurarsi di usare un tipo di origine dati supportato.
Creare una definizione di origine dati. L'elenco seguente include alcune delle origini dati usate più di frequente:
Se l'origine dati è un database, ad esempio Azure SQL o Cosmos DB, abilitare il rilevamento delle modifiche. Archiviazione di Azure include il rilevamento delle modifiche predefinito tramite la
LastModifiedproprietà in ogni BLOB, file e tabella. I collegamenti precedenti per le varie origini dati illustrano quali metodi di rilevamento delle modifiche sono supportati dagli indicizzatori.
Preparare un indice
Gli indicizzatori richiedono anche un indice di ricerca. Tenere presente che gli indicizzatori passano i dati al motore di ricerca per l'indicizzazione. Proprio come gli indicizzatori hanno proprietà che determinano il comportamento di esecuzione, uno schema di indice ha proprietà che influiscono profondamente sulla modalità di indicizzazione delle stringhe (vengono analizzate e tokenizzate solo le stringhe).
Iniziare con Creare un indice di ricerca.
Configurare l'insieme dei campi e gli attributi dei campi.
I campi sono gli unici recettori del contenuto esterno. A seconda della modalità di assegnazione dei campi nello schema, i valori per ogni campo vengono analizzati, tokenizzati o archiviati come stringhe verbatim per filtri, ricerca fuzzy e query typeahead.
Gli indicizzatori possono eseguire automaticamente il mapping dei campi di origine ai campi di indice di destinazione quando i nomi e i tipi sono equivalenti. Se non è possibile eseguire il mapping implicito di un campo, tenere presente che è possibile definire un mapping esplicito dei campi che indica all'indicizzatore come instradare il contenuto.
Esaminare le assegnazioni dell'analizzatore in ogni campo. Gli analizzatori possono trasformare le stringhe. Di conseguenza, le stringhe indicizzate potrebbero essere diverse da quelle passate. È possibile valutare gli effetti degli analizzatori usando Analizza testo (REST). Per altre informazioni sugli analizzatori, vedere Analizzatori per l'elaborazione del testo.
Durante l'indicizzazione, un indicizzatore controlla solo i nomi e i tipi di campo. Non esiste alcun passaggio di convalida che garantisce che il contenuto in ingresso sia corretto per il campo di ricerca corrispondente nell'indice.
Creare un indicizzatore
Quando si è pronti per creare un indicizzatore in un servizio di ricerca remoto, è necessario un client di ricerca. Un client di ricerca può essere il portale di Azure, un client REST o un codice che crea un'istanza di un client indicizzatore. È consigliabile usare le API REST o portale di Azure per lo sviluppo anticipato e il test di verifica.
Accedere al portale di Azure.
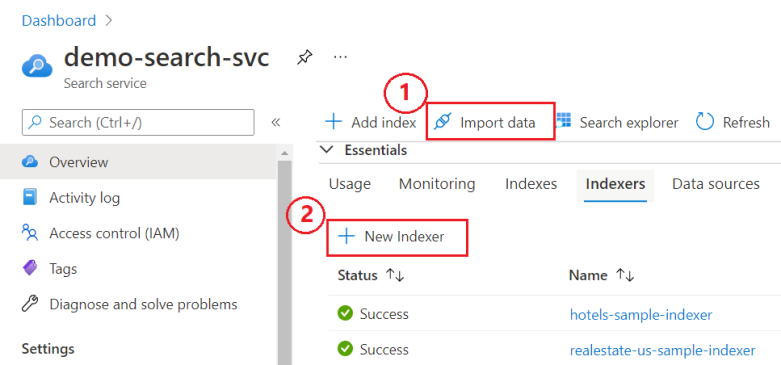
Nella pagina Panoramica del servizio di ricerca scegliere tra due opzioni:
Importazione guidata dati. La procedura guidata è univoca in quanto crea tutti gli elementi necessari. Altri approcci richiedono un'origine dati e un indice predefiniti.
Nuovo indicizzatore, un editor visivo per specificare una definizione dell'indicizzatore.
Lo screenshot seguente mostra dove è possibile trovare queste funzionalità nel portale.
Eseguire l'indicizzatore
Per impostazione predefinita, un indicizzatore viene eseguito immediatamente quando viene creato nel servizio di ricerca. È possibile eseguire l'override di questo comportamento impostando "disabled" su true nella definizione dell'indicizzatore. L'esecuzione dell'indicizzatore è il momento della verità in cui si verificano problemi con connessioni, mapping dei campi o costruzione del set di competenze.
Esistono diversi modi per eseguire un indicizzatore:
Esecuzione alla creazione o all'aggiornamento dell'indicizzatore (impostazione predefinita).
Eseguire su richiesta quando non sono presenti modifiche alla definizione o anteporre la reimpostazione per l'indicizzazione completa. Per altre informazioni, vedere Eseguire o reimpostare gli indicizzatori.
Pianificare l'elaborazione dell'indicizzatore per richiamare l'esecuzione a intervalli regolari.
L'esecuzione pianificata viene in genere implementata quando è necessaria l'indicizzazione incrementale in modo da poter raccogliere le modifiche più recenti. Di conseguenza, la pianificazione ha una dipendenza dal rilevamento delle modifiche.
Gli indicizzatori sono uno dei pochi sottosistemi che effettuano chiamate in uscita ad altre risorse di Azure. In termini di ruoli di Azure, gli indicizzatori non hanno identità separate: una connessione dal motore di ricerca a un'altra risorsa di Azure viene eseguita usando l'identità gestita assegnata dal sistema o dall'utente di un servizio di ricerca. Se l'indicizzatore si connette a una risorsa di Azure in una rete virtuale, è necessario creare un collegamento privato condiviso per tale connessione. Per altre informazioni sulle connessioni sicure, vedere Sicurezza in Ricerca di intelligenza artificiale di Azure.
Controllare i risultati
Monitorare lo stato dell'indicizzatore per verificare lo stato. L'esecuzione riuscita può comunque includere avvisi e notifiche. Assicurarsi di controllare le notifiche di stato riuscite e non riuscite per informazioni dettagliate sul processo.
Per la verifica del contenuto, eseguire query sull'indice popolato che restituiscono interi documenti o campi selezionati.
Rilevamento delle modifiche e stato interno
Se l'origine dati supporta il rilevamento delle modifiche, un indicizzatore può rilevare le modifiche sottostanti nei dati ed elaborare solo i documenti nuovi o aggiornati in ogni esecuzione dell'indicizzatore, lasciando invariato il contenuto così come è. Se la cronologia di esecuzione dell'indicizzatore indica che un'esecuzione ha avuto esito positivo con 0/0 i documenti elaborati, significa che l'indicizzatore non ha trovato righe o BLOB nuovi o modificati nell'origine dati sottostante.
La logica di rilevamento delle modifiche è incorporata nelle piattaforme dati. Il modo in cui un indicizzatore supporta il rilevamento delle modifiche varia in base all'origine dati:
Archiviazione di Azure ha il rilevamento delle modifiche predefinito, il che significa che un indicizzatore può riconoscere automaticamente i documenti nuovi e aggiornati. Archiviazione BLOB, Archiviazione tabelle di Azure e Azure Data Lake Archiviazione Gen2 contrassegna ogni aggiornamento di BLOB o riga con data e ora. Un indicizzatore usa automaticamente queste informazioni per determinare quali documenti aggiornare nell'indice. Per altre informazioni sul rilevamento dell'eliminazione, vedere Eliminare il rilevamento usando gli indicizzatori per Archiviazione di Azure in Ricerca di intelligenza artificiale di Azure.
Le tecnologie di database cloud offrono funzionalità facoltative di rilevamento delle modifiche nelle proprie piattaforme. Per queste origini dati, il rilevamento delle modifiche non è automatico. È necessario specificare nella definizione dell'origine dati quale criterio viene usato:
Gli indicizzatori tengono traccia dell'ultimo documento elaborato dall'origine dati tramite un indicatore d'acqua elevato interno. L'indicatore non viene mai esposto nell'API, ma internamente l'indicizzatore tiene traccia della posizione in cui è stata arrestata. Quando l'indicizzazione riprende, tramite un'esecuzione pianificata o una chiamata su richiesta, l'indicizzatore fa riferimento al contrassegno di acqua elevato in modo che possa riprendere la posizione in cui è stata interrotta.
Se è necessario cancellare il segno d'acqua elevato per reindicizzare completamente, è possibile usare Reset Indexer. Per una reindicizzazione più selettiva, usare Reimposta competenze o Reimposta documenti. Tramite le API di reimpostazione, è possibile cancellare lo stato interno e scaricare anche la cache se è stato abilitato l'arricchimento incrementale. Per altre informazioni sullo sfondo e sul confronto di ogni opzione di reimpostazione, vedere Eseguire o reimpostare indicizzatori, competenze e documenti.