Gestione traffico di Azure con Azure Site Recovery
Gestione traffico di Azure consente di controllare in che modo il traffico viene distribuito tra gli endpoint dell'applicazione. Un endpoint è un servizio con connessione Internet ospitato all'interno o all'esterno di Azure.
Gestione traffico usa Domain Name System (DNS) per indirizzare le richieste client all'endpoint più appropriato, in base a un metodo di routing del traffico e all'integrità degli endpoint. Gestione traffico offre diversi metodi di routing del traffico e opzioni di monitoraggio degli endpoint per soddisfare le diverse esigenze delle applicazioni e i modelli di failover automatico. I client si connettono direttamente all'endpoint selezionato. Gestione traffico non è un proxy o un gateway e non rileva il traffico tra il client e il servizio.
Questo articolo descrive come combinare il routing intelligente di Gestione traffico di Azure con le potenti funzionalità di ripristino di emergenza e migrazione di Azure Site Recovery.
Failover dall'ambiente locale ad Azure
Per il primo scenario, si supponga che la società A esegua l'intera infrastruttura delle applicazioni nell'ambiente locale. Per motivi di conformità e di continuità aziendale, la società A decide di usare Azure Site Recovery per proteggere le applicazioni.
La società A esegue le applicazioni con endpoint pubblici e vuole poter reindirizzare senza problemi il traffico ad Azure nel caso di un'emergenza. Il metodo di routing del traffico Priorità in Gestione traffico di Azure permette alla società A di implementare facilmente questo modello di failover.
La configurazione è la seguente:
- La società A crea un profilo di Gestione traffico.
- Usando il metodo di routing Priorità, la società A crea due endpoint, uno definito Primario per l'ambiente locale e uno definito Failover per Azure. All'endpoint Primario viene assegnata la priorità 1, mentre all'endpoint Failover viene assegnata la priorità 2.
- Poiché l'endpoint Primario è ospitato esternamente ad Azure, viene creato come endpoint Esterno.
- Con Azure Site Recovery, il sito di Azure non ha macchine virtuali o applicazioni in esecuzione prima del failover. Di conseguenza, anche l'endpoint Failover viene creato come endpoint Esterno.
- Per impostazione predefinita, il traffico utente viene indirizzato all'applicazione locale, perché a questo endpoint è associata la priorità più alta. Nessuna parte di traffico viene indirizzata ad Azure se l'endpoint Primario è integro.
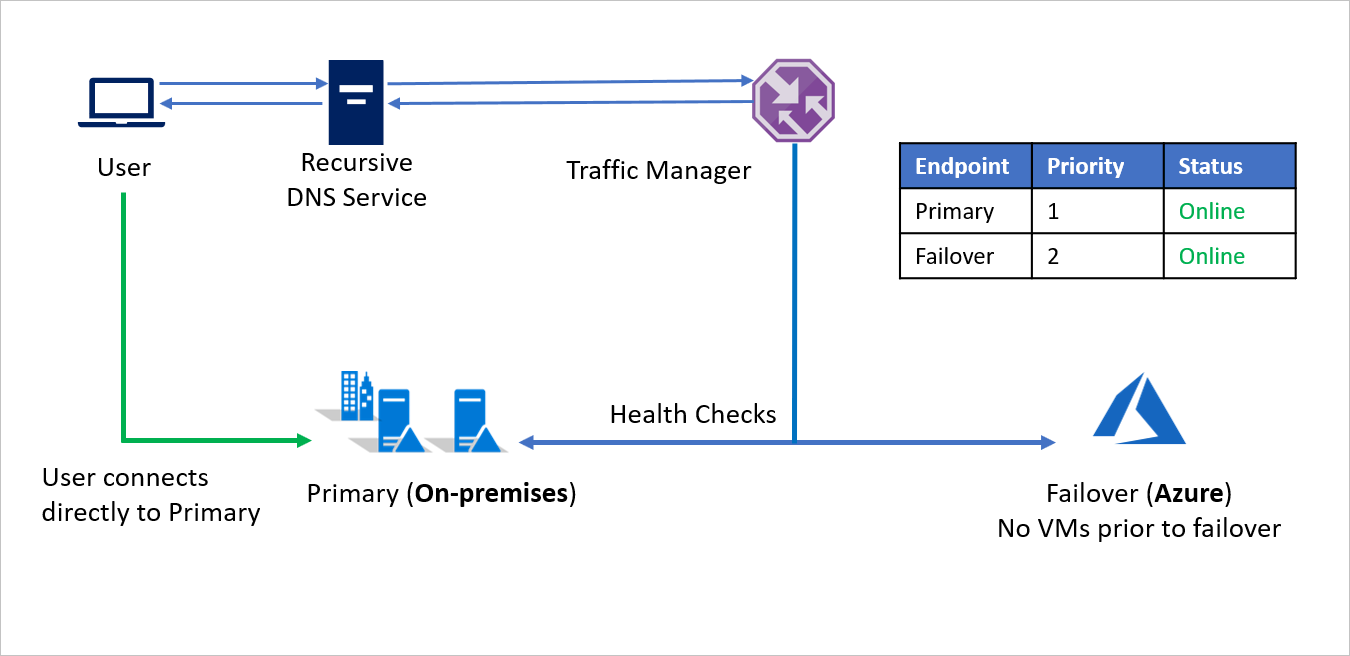
Nel caso di un'emergenza, la società A può attivare un failover in Azure e ripristinare le applicazioni in Azure. Quando Gestione traffico rileva che l'endpoint Primario non è più integro, usa automaticamente l'endpoint Failover nella risposta DNS e gli utenti si connettono all'applicazione ripristinata in Azure.
A seconda dei requisiti aziendali, la società A può scegliere una frequenza di probe maggiore o minore per passare dall'ambiente locale ad Azure nel caso di un'emergenza e assicurare tempo di inattività minimo per gli utenti.
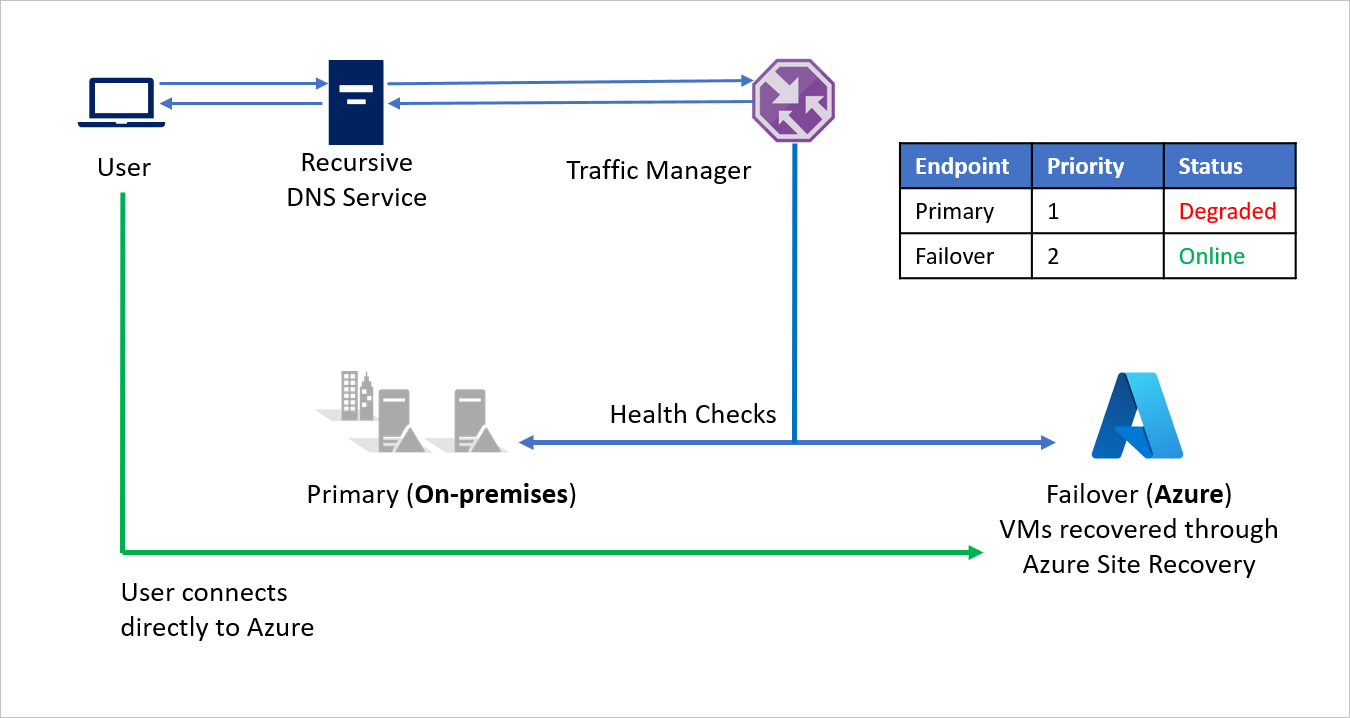
Quando l'emergenza viene risolta, la società A può eseguire il failback da Azure all'ambiente locale (VMware o Hyper-V) tramite Azure Site Recovery. A questo punto, quando Gestione traffico rileva che l'endpoint Primario è di nuovo integro, utilizza automaticamente questo endpoint Primario nelle risposte DNS.
Migrazione dall'ambiente locale ad Azure
Oltre al ripristino di emergenza, Azure Site Recovery permette anche di eseguire migrazioni in Azure. Usando le potenti funzionalità di failover di test di Azure Site Recovery, i clienti possono valutare le prestazioni dell'applicazione in Azure senza influire sull'ambiente locale. Quando i clienti sono pronti per la migrazione, possono scegliere di eseguire la migrazione degli interi carichi di lavoro tutti insieme oppure optare per una migrazione e un ridimensionamento graduali.
Il metodo di routing Ponderato di Gestione traffico di Azure può essere usato per indirizzare una parte del traffico in ingresso ad Azure, indirizzandone la maggior parte all'ambiente locale. Questo approccio può aiutare a valutare le prestazioni di ridimensionamento mentre si continua a incrementare il peso assegnato ad Azure con l'aumentare dei carichi di lavoro migrati in Azure.
Ad esempio, la società B sceglie una migrazione in fasi, spostando una parte dell'ambiente dell'applicazione e mantenendo il resto in locale. Durante le fasi iniziali, quando la maggior parte dell'ambiente è locale, viene assegnato un peso maggiore all'ambiente locale. Gestione traffico restituisce un endpoint in base al peso assegnato agli endpoint disponibili.
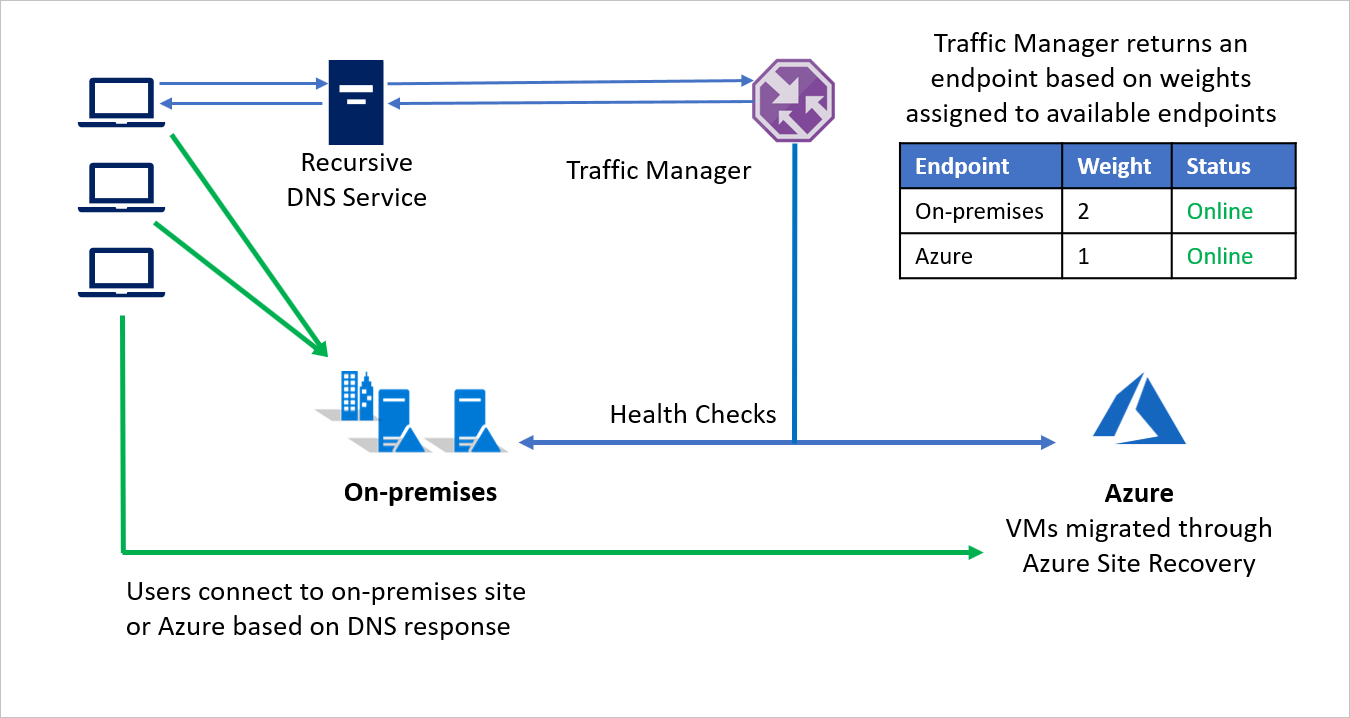
Durante la migrazione, entrambi gli endpoint sono attivi e la maggior parte del traffico viene indirizzata all'ambiente locale. Con il procedere della migrazione, è possibile assegnare un peso maggiore all'endpoint in Azure e infine disattivare l'endpoint locale al termine della migrazione.
Failover da Azure ad Azure
Per questo esempio, si supponga che la società C esegua l'intera infrastruttura delle applicazioni in Azure. Per motivi di conformità e di continuità aziendale, la società C decide di usare Azure Site Recovery per proteggere le applicazioni.
La società C esegue le applicazioni con endpoint pubblici e vuole poter reindirizzare in modo uniforme il traffico a un'area di Azure diversa nel caso di un'emergenza. Il metodo di routing del traffico Priorità permette alla società C di implementare facilmente questo modello di failover.
La configurazione è la seguente:
- La società C crea un profilo di Gestione traffico.
- Usando il metodo di routing Priorità, la società C crea due endpoint, uno definito Primario per l'area di origine (area Asia orientale di Azure) e uno definito Failover per l'area di ripristino (area Asia sud-orientale di Azure). All'endpoint Primario viene assegnata la priorità 1, mentre all'endpoint Failover viene assegnata la priorità 2.
- Poiché l'endpoint Primario è ospitato in Azure, l'endpoint può essere un endpoint di Azure.
- Con Azure Site Recovery, il sito di ripristino di Azure non ha macchine virtuali o applicazioni in esecuzione prima del failover. Di conseguenza, l'endpoint Failover può essere creato come endpoint Esterno.
- Per impostazione predefinita, il traffico utente viene indirizzato all'area di origine (Asia orientale), perché a questo endpoint è associata la priorità più alta. Nessuna parte di traffico viene indirizzata all'area di ripristino se l'endpoint Primario è integro.
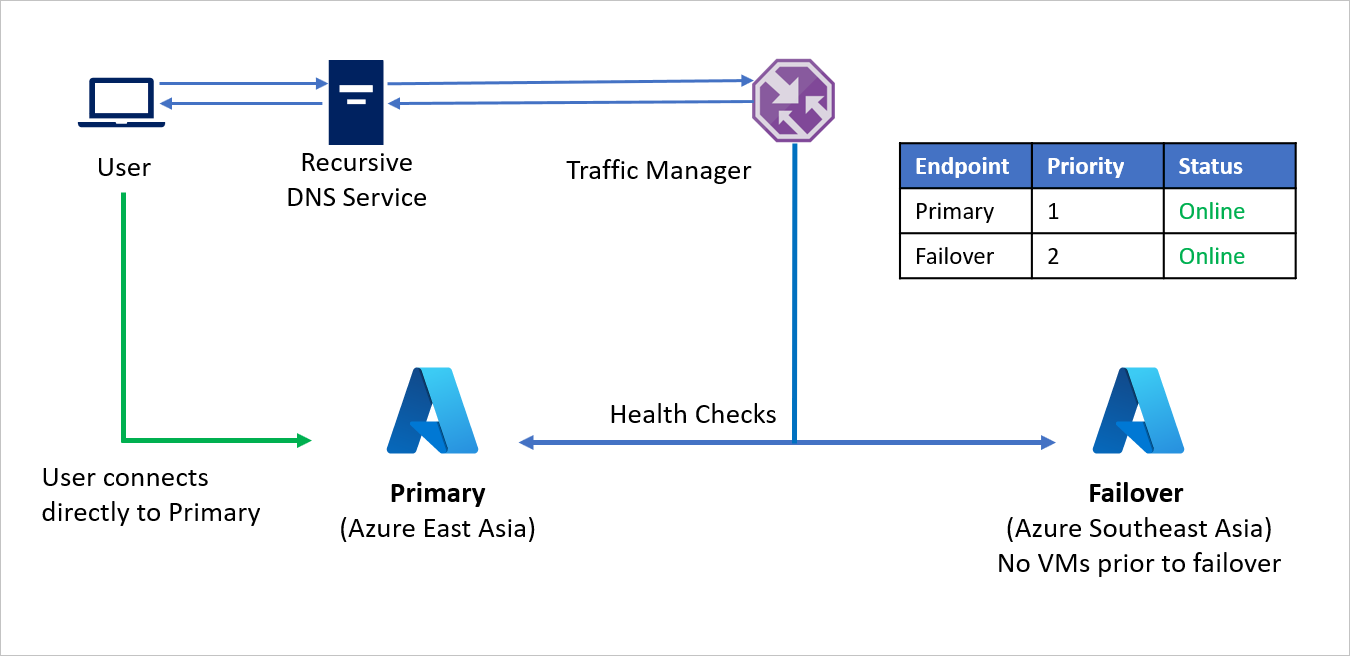
Nel caso di un'emergenza, la società C può attivare un failover e ripristinare le applicazioni nell'area di Azure di ripristino. Quando Gestione traffico rileva che l'endpoint Primario non è più integro, usa automaticamente l'endpoint Failover nella risposta DNS e gli utenti si connettono all'applicazione ripristinata nell'area di Azure di ripristino (Asia sud-orientale).
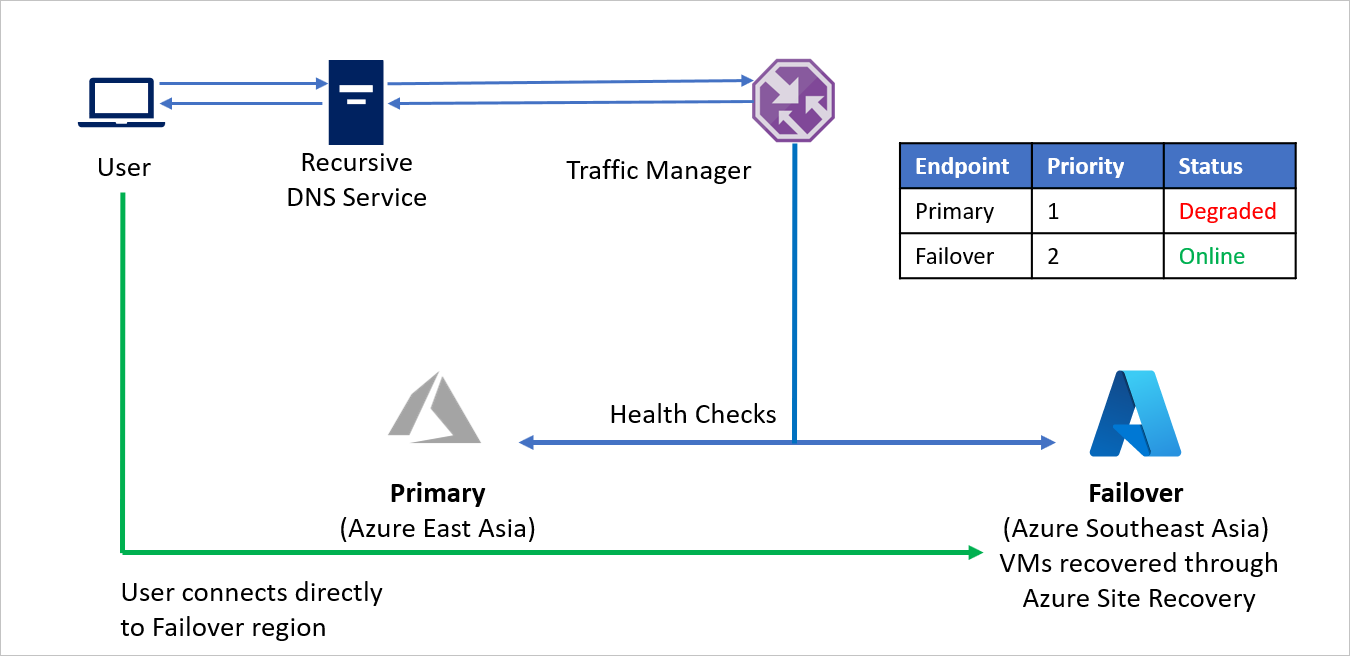
A seconda dei requisiti aziendali, la società C può scegliere una frequenza di probe maggiore o minore per passare tra l'area di origine e quella di ripristino e assicurare tempo di inattività minimo per gli utenti.
Quando l'emergenza viene risolta, la società C può eseguire il failback dall'area di Azure di ripristino all'area di Azure di origine tramite Azure Site Recovery. A questo punto, quando Gestione traffico rileva che l'endpoint Primario è di nuovo integro, utilizza automaticamente questo endpoint Primario nelle risposte DNS.
Protezione di applicazioni aziendali in più aree
Le aziende globali migliorano spesso l'esperienza dei clienti ottimizzando le proprie applicazioni per soddisfare esigenze in aree specifiche. La localizzazione e la riduzione di latenza possono comportare la divisione dell'infrastruttura delle applicazioni tra aree diverse. Le organizzazioni sono anche vincolate a leggi locali sui dati in certe aree e possono scegliere di isolare parte della propria infrastruttura delle applicazioni all'interno dei confini regionali.
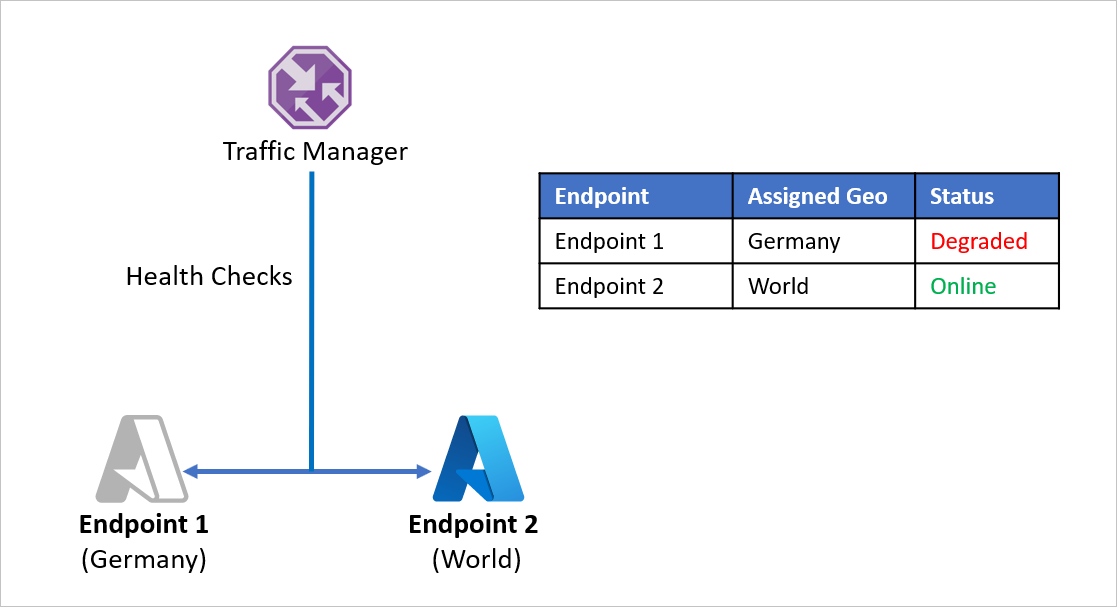
Ad esempio, si supponga che la società D abbia diviso i propri endpoint applicazione in modo da gestire separatamente la Germania e il resto del mondo. La società D usa il metodo di routing Geografico di Gestione traffico di Azure per la configurazione a questo scopo. Tutto il traffico proveniente dalla Germania viene indirizzato all'endpoint 1, mentre il traffico che ha origine esternamente alla Germania viene indirizzato all'endpoint 2.
Il problema con questa configurazione è che se l'endpoint 1 smette di funzionare per qualsiasi motivo, non viene attivato alcun reindirizzamento del traffico all'endpoint 2. Il traffico proveniente dalla Germania continua a essere indirizzato all'endpoint 1 indipendentemente dall'integrità dell'endpoint, lasciando gli utenti della Germania senza accesso all'applicazione della società D. Analogamente, se l'endpoint 2 è offline, non viene attivato alcun reindirizzamento del traffico all'endpoint 1.
Per evitare di riscontrare questo problema e garantire la resilienza dell'applicazione, la società D usa profili di Gestione traffico annidati con Azure Site Recovery. In una configurazione con profili annidati, il traffico non viene indirizzato a singoli endpoint, ma ad altri profili di Gestione traffico. Ecco come funziona questa configurazione:
- Invece di usare il metodo di routing Geografico con singoli endpoint, la società D usa questo metodo con profili di Gestione traffico.
- Ogni profilo di Gestione traffico figlio usa il routing di tipo Priorità con un endpoint primario e un endpoint di ripristino, annidando quindi il routing Priorità all'interno del routing Geografico.
- Per fornire la resilienza dell'applicazione, ogni distribuzione del carico di lavoro usa Azure Site Recovery per eseguire il failover in un'area di ripristino nel caso di un'emergenza.
- Quando il profilo di Gestione traffico padre riceve una query DNS, questa viene indirizzata al profilo di Gestione traffico figlio pertinente, che risponde alla query con un endpoint disponibile.
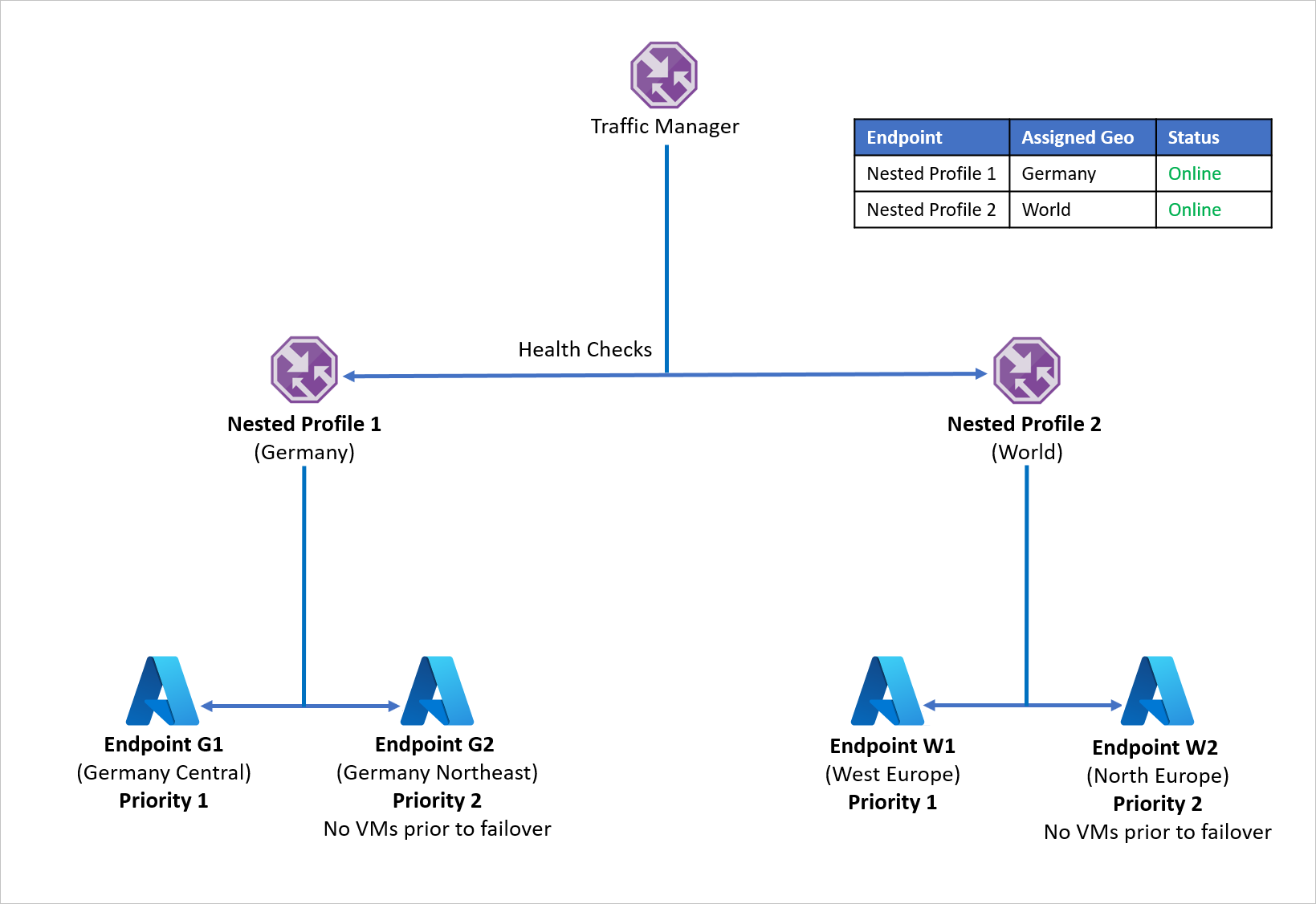
Ad esempio, in caso di errore dell'endpoint in Germania centrale, l'applicazione può essere rapidamente ripristinata in Germania nord-orientale. Il nuovo endpoint gestisce il traffico proveniente dalla Germania con tempo di inattività minimo per gli utenti. Analogamente, l'interruzione di un endpoint in Europa occidentale può essere gestito ripristinando il carico di lavoro dell'applicazione in Europa settentrionale, con Gestione traffico che gestisce i reindirizzamenti DNS all'endpoint disponibile.
La configurazione descritta sopra può essere estesa in modo da includere tutte le combinazioni di aree ed endpoint necessarie. Gestione traffico permette fino a dieci livelli di profili annidati e non consente cicli all'interno della configurazione annidata.
Considerazioni relative all'obiettivo del tempo di ripristino (RTO)
Nella maggior parte delle organizzazioni, l'aggiunta o la modifica di record DNS viene gestita da un team separato o da qualcuno esterno all'organizzazione. Questo approccio rende molto impegnativa l'attività di modifica dei record DNS. Il tempo impiegato da altri team o organizzazioni che gestiscono l'infrastruttura DNS per aggiornare i record DNS varia in base all'organizzazione e ha un impatto sull'obiettivo del tempo di ripristino dell'applicazione.
Con Gestione traffico è possibile agire d'anticipo riguardo alle attività necessarie per gli aggiornamenti dei record DNS. Al momento dell'effettivo failover, non saranno necessarie attività manuali o tramite script. Questo approccio permette di completare rapidamente il passaggio (e di conseguenza di ridurre i tempi di ripristino), nonché di evitare errori di modifica dei record DNS dispendiosi in termini di costi e di tempo nel caso di un'emergenza. Con Gestione traffico anche il passaggio di failback, che altrimenti dovrebbe essere gestito separatamente, è automatizzato.
L'impostazione del corretto intervallo di probe tramite controlli di integrità con intervallo di base o veloce può migliorare notevolmente l'obiettivo del tempo di ripristino durante il failover e ridurre il tempo di inattività per gli utenti.
È possibile ottimizzare ulteriormente il valore di durata (TTL) DNS per il profilo di Gestione traffico. TTL è il valore di tempo durante il quale una voce DNS è memorizzata nella cache da un client. Per un record, non vengono eseguite query due volte su DNS all'interno dell'intervallo TTL. A ogni record DNS è associato un valore TTL. La riduzione di questo valore produce più query DNS in Gestione traffico, ma può migliorare l'obiettivo del tempo di ripristino rilevando le interruzioni più rapidamente.
Il TTL riscontrato dal client non aumenta se aumenta il numero di resolver DNS tra il client e il server DNS rilevante. I resolver DNS eseguono il "conto alla rovescia" del TTL e passano solo un valore TTL che riflette il tempo trascorso dal momento in cui il record è stato memorizzato nella cache. In questo modo, il record DNS viene aggiornato nel client dopo il TTL, indipendentemente dal numero di resolver DNS nella catena.
Passaggi successivi
- Leggere altre informazioni sui metodi di routing di Gestione traffico.
- Leggere altre informazioni sui profili di Gestione traffico annidati.
- Altre informazioni sul monitoraggio degli endpoint.
- Leggere altre informazioni sui piani di ripristino per automatizzare il failover delle applicazioni.