Configurare il ripristino di emergenza per SQL Server
Questo articolo descrive come proteggere il back-end di SQL Server di un'applicazione. A tale scopo, usare una combinazione di tecnologie di continuità aziendale e ripristino di emergenza di SQL Server e Azure Site Recovery.
Prima di iniziare, assicurarsi di comprendere le funzionalità di ripristino di emergenza di SQL Server. Tali funzionalità includono:
- Clustering di failover
- Gruppi di disponibilità AlwaysOn
- Mirroring del database
- Log shipping
- Replica geografica attiva
- Gruppi di failover automatico
Combinazione di tecnologie BCDR con Site Recovery
La scelta di una tecnologia BCDR per ripristinare le istanze di SQL Server deve essere basata sulle esigenze dell'obiettivo del tempo di ripristino (RTO) e dell'obiettivo del punto di ripristino (RPO), come descritto nella tabella seguente. Combinare Site Recovery con l'operazione di failover della tecnologia scelta per orchestrare il ripristino dell'intera applicazione.
| Tipo di distribuzione | Tecnologia BCDR | RTO previsto per SQL Server | RPO previsto per SQL Server |
|---|---|---|---|
| SQL Server in una macchina virtuale IaaS (Infrastructure as a Service) di Azure o in locale. | Gruppo di disponibilità AlwaysOn | Tempo impiegato per rendere primaria la replica secondaria. | Poiché la replica secondaria è asincrona, si verifica una perdita di dati. |
| SQL Server in una macchina virtuale IaaS di Azure o in locale. | Clustering di failover (istanza del cluster di failover AlwaysOn) | Tempo impiegato per eseguire il failover tra i nodi. | Poiché l'istanza del cluster di failover Always On usa l'archiviazione condivisa, la stessa visualizzazione dell'istanza di archiviazione è disponibile in caso di failover. |
| SQL Server in una macchina virtuale IaaS di Azure o in locale. | Mirroring del database (modalità a prestazioni elevate) | Tempo impiegato per forzare il servizio, che usa il server mirror come server warm standby. | La replica è asincrona. Il database mirror potrebbe avere un certo ritardo rispetto al database principale. Il ritardo è in genere ridotto, ma può diventare esteso se il sistema del server principale o mirror è sottoposto a un carico elevato. Il log shipping può essere un supplemento al mirroring del database. Si tratta di un'alternativa favorevole al mirroring asincrono del database. |
| SQL as platform as a Service (PaaS) in Azure. Questo tipo di distribuzione include database singoli e pool elastici. |
Replica geografica attiva | 30 secondi dopo l'attivazione del failover. Una volta attivato il failover per uno dei database secondari, tutti gli altri database secondari vengono automaticamente collegati al nuovo database primario. |
RPO di cinque secondi. La replica geografica attiva usa la tecnologia Always On di SQL Server. Replica in modo asincrono le transazioni di cui è stato eseguito il commit nel database primario in un database secondario usando l'isolamento dello snapshot. I dati secondari non hanno mai transazioni parziali. |
| SQL come PaaS configurato con la replica geografica attiva in Azure. Questo tipo di distribuzione include istanze gestite, pool elastici e database singoli. |
Gruppi di failover automatico | RTO di un'ora. | RPO di cinque secondi. I gruppi di failover automatico forniscono la semantica del gruppo sopra la replica geografica attiva. Viene tuttavia usato lo stesso meccanismo di replica asincrona. |
| SQL Server in una macchina virtuale IaaS di Azure o in locale. | Replica con Azure Site Recovery | L'obiettivo RTO è in genere inferiore a 15 minuti. Per altre informazioni, leggere il contratto di servizio RTO fornito da Site Recovery. | Un'ora per la coerenza dell'applicazione e cinque minuti per la coerenza degli arresti anomali. Se si sta cercando un RPO inferiore, usare altre tecnologie BCDR. |
Nota
Alcune considerazioni importanti quando si aiutano a proteggere i carichi di lavoro SQL con Site Recovery:
- Site Recovery è indipendente dall'applicazione. Site Recovery consente di proteggere qualsiasi versione di SQL Server distribuita in un sistema operativo supportato. Per altre informazioni, vedere la matrice di supporto per il ripristino di computer replicati.
- È possibile scegliere di usare Site Recovery per qualsiasi distribuzione in Azure, Hyper-V, VMware o infrastruttura fisica. Seguire le indicazioni alla fine di questo articolo su come proteggere un cluster di SQL Server con Site Recovery.
- Assicurarsi che la frequenza di modifica dei dati osservata nel computer sia entro i limiti di Site Recovery. La frequenza di modifica viene misurata in byte di scrittura al secondo. Per i computer che eseguono Windows, è possibile visualizzare questa frequenza di modifica selezionando la scheda Prestazioni in Gestione attività. Osservare la velocità di scrittura per ogni disco.
- Site Recovery supporta la replica delle istanze del cluster di failover in Spazi di archiviazione diretta. Per altre informazioni, vedere come abilitare la replica di Spazi di archiviazione diretta.
Quando si esegue la migrazione del carico di lavoro SQL ad Azure, è consigliabile applicare le Linee guida per le prestazioni per SQL Server in macchine virtuali di Azure.
Ripristino di emergenza di un'applicazione
Site Recovery orchestra il failover di test e il failover dell'intera applicazione con l'aiuto dei piani di ripristino.
Esistono alcuni prerequisiti per assicurarsi che il piano di ripristino sia completamente personalizzato in base alle esigenze. Qualsiasi distribuzione di SQL Server richiede in genere una distribuzione di Active Directory. Richiede anche la connettività per il livello applicazione.
Passaggio 1: Configurare Active Directory
Per garantire la corretta esecuzione di SQL Server, configurare Active Directory nel sito di ripristino secondario.
- Piccole organizzazioni: sono disponibili alcune applicazioni e un singolo controller di dominio per il sito locale. Per eseguire il failover dell'intero sito, usare la replica di Site Recovery. Questo servizio replica il controller di dominio nel data center secondario o in Azure.
- Organizzazioni da medie a grandi: potrebbe essere necessario configurare controller di dominio aggiuntivi.
- Se si dispone di un numero elevato di applicazioni, si dispone di una foresta Active Directory e si vuole eseguire il failover per applicazione o carico di lavoro, configurare un altro controller di dominio nel data center secondario o in Azure.
- Se si usano gruppi di disponibilità Always On per eseguire il ripristino in un sito remoto, configurare un altro controller di dominio nel sito secondario o in Azure. Questo controller di dominio viene usato per l'istanza di SQL Server ripristinata.
Le istruzioni contenute in questo articolo presuppongono che un controller di dominio sia disponibile nella posizione secondaria. Per altre informazioni, vedere le procedure per contribuire alla protezione di Active Directory con Site Recovery.
Passaggio 2: Verificare la connettività con altri livelli
Dopo l'esecuzione del livello di database nell'area di Azure di destinazione, assicurarsi di avere connettività con l'applicazione e i livelli Web. Eseguire i passaggi necessari in anticipo per convalidare la connettività con il failover di test.
Per comprendere come progettare applicazioni per considerazioni sulla connettività, vedere gli esempi seguenti:
- Progettare un'applicazione per il ripristino di emergenza cloud
- Strategie di ripristino di emergenza del pool elastico
Passaggio 3: Interoperabilità con Always On, replica geografica attiva e gruppi di failover automatico
Le tecnologie BCDR Always On, la replica geografica attiva e i gruppi di failover automatico hanno repliche secondarie di SQL Server in esecuzione nell'area di Azure di destinazione. Il primo passaggio per il failover dell'applicazione consiste nello specificare questa replica come primaria. Questo passaggio presuppone che sia già presente un controller di dominio nel database secondario. Il passaggio potrebbe non essere necessario se si sceglie di eseguire un failover automatico. Eseguire il failover dei livelli Web e dell'applicazione solo dopo il completamento del failover del database.
Nota
Se si è contribuito a proteggere i computer SQL con Site Recovery, è sufficiente creare un gruppo di ripristino di questi computer e aggiungerne il failover nel piano di ripristino.
Creare un piano di ripristino con macchine virtuali a livello Web e applicazione. La procedura seguente illustra come aggiungere il failover del livello di database:
Importare gli script per eseguire il failover del gruppo di disponibilità SQL in una macchina virtuale Resource Manager e in una macchina virtuale classica. Importare gli script nell'account di Automazione di Azure.

Aggiungere lo script ASR-SQL-FailoverAG come azione preliminare del primo gruppo del piano di ripristino.
Seguire le istruzioni disponibili nello script per creare una variabile di automazione. Questa variabile fornisce il nome dei gruppi di disponibilità.
Passaggio 4: Eseguire un failover di test
Alcune tecnologie BCDR, ad esempio SQL AlwaysOn, non supportano in modo nativo il failover di test. È consigliabile usare l'approccio seguente solo quando si usano tali tecnologie.
Configurare Backup di Azure nella macchina virtuale che ospita la replica del gruppo di disponibilità in Azure.
Prima di attivare il failover di test del piano di ripristino, ripristinare la macchina virtuale dal backup eseguito nel passaggio precedente.
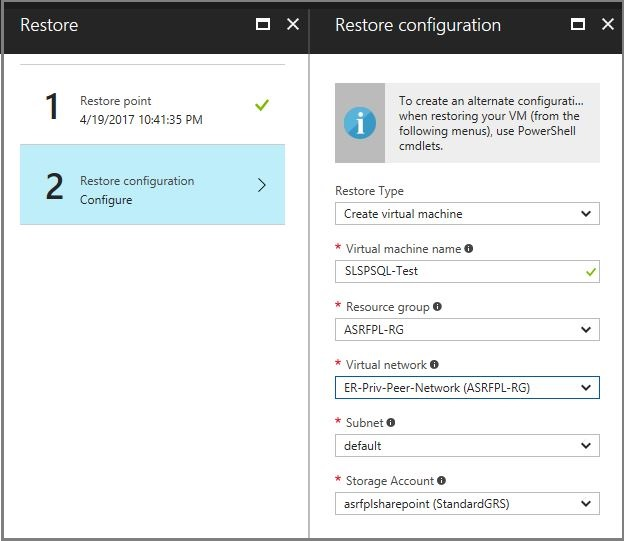
Forzare un quorum nella macchina virtuale ripristinata dal backup.
Aggiornare l'indirizzo IP del listener in modo che sia un indirizzo disponibile nella rete di failover di test.
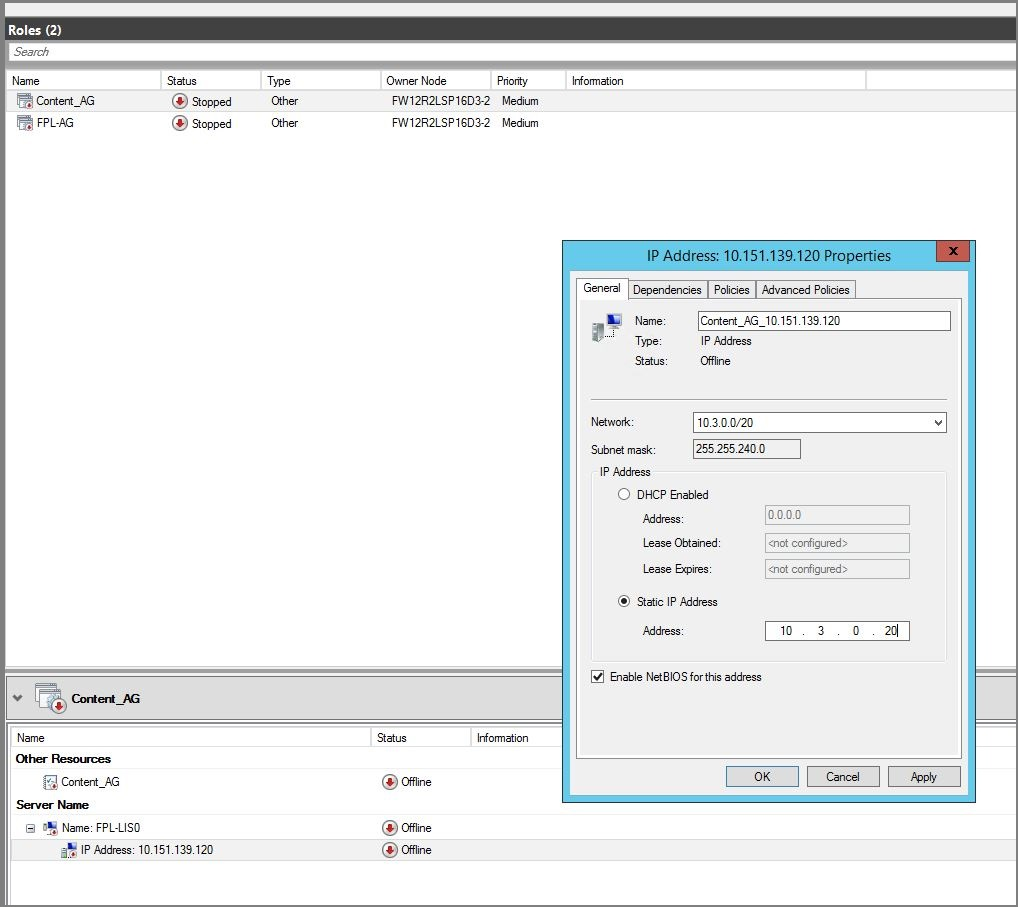
Portare il listener online.
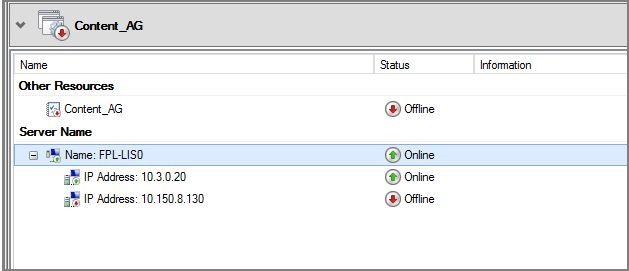
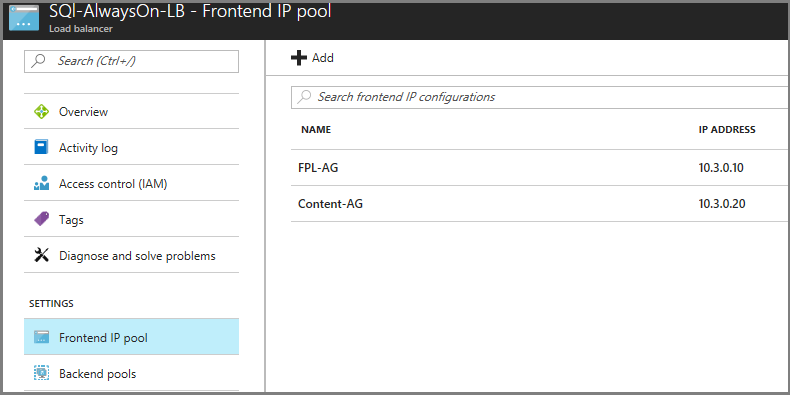
Assicurarsi che il servizio di bilanciamento del carico nella rete di failover abbia un indirizzo IP, dal pool di indirizzi IP front-end corrispondente a ogni listener del gruppo di disponibilità e con la macchina virtuale di SQL Server nel pool back-end.
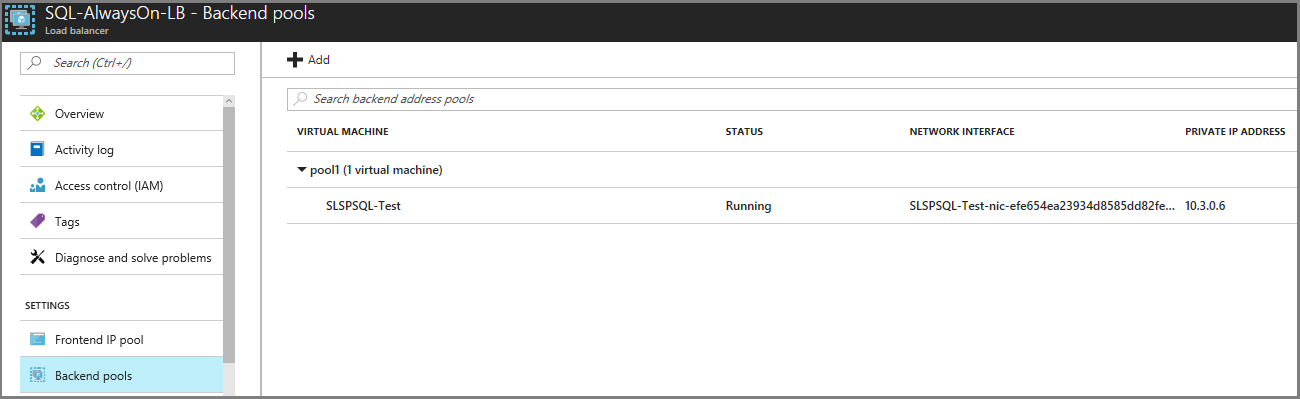
Nei gruppi di ripristino successivi aggiungere il failover del livello applicazione seguito dal livello Web per questo piano di ripristino.
Eseguire un failover di test del piano di ripristino per testare il failover end-to-end dell'applicazione.
Passaggi per eseguire un failover
Dopo aver aggiunto lo script nel passaggio 3 e convalidarlo nel passaggio 4, è possibile eseguire un failover del piano di ripristino creato nel passaggio 3.
I passaggi di failover per i livelli applicazione e Web devono essere gli stessi nei piani di failover di test e di ripristino di failover.
Come proteggere un cluster di SQL Server
Per un cluster che esegue SQL Server Standard Edition o SQL Server 2008 R2, è consigliabile usare la replica di Site Recovery per contribuire a proteggere SQL Server.
Da Azure ad Azure e da locale ad Azure
Site Recovery non offre supporto per i cluster guest durante la replica in un'area di Azure. SQL Server Standard Edition non offre anche una soluzione di ripristino di emergenza a basso costo. In questo scenario è consigliabile proteggere il cluster SQL Server in un'istanza autonoma di SQL Server nel percorso primario e ripristinarlo nel database secondario.
Configurare un'altra istanza autonoma di SQL Server nell'area primaria di Azure o nel sito locale.
Configurare l'istanza in modo che funga da mirror per i database da proteggere. Configurare il mirroring in modalità protezione elevata.
Configurare Site Recovery nel sito primario per Azure, Hyper-Vo macchine virtuali VMware e server fisici.
Usare la replica di Site Recovery per replicare la nuova istanza di SQL Server nel sito secondario. Poiché si tratta di una copia mirror ad alta sicurezza, viene sincronizzata con il cluster primario ma replicata usando la replica di Site Recovery.
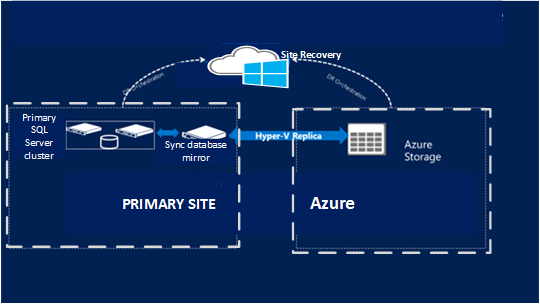
Considerazioni sul failback
Per i cluster SQL Server Standard, il failback dopo un failover non pianificato richiede un backup e un ripristino di SQL Server. Questa operazione viene eseguita dall'istanza mirror al cluster originale con la ricreazione del mirror.
Domande frequenti
In che modo SQL Server viene concesso in licenza quando viene usato con Site Recovery?
La replica di Site Recovery per SQL Server è coperta dal vantaggio del ripristino di emergenza di Software Assurance. Questa copertura si applica a tutti gli scenari di Site Recovery: in locale al ripristino di emergenza di Azure e al ripristino di emergenza IaaS di Azure tra aree. Per altre informazioni, vedere i prezzi di Azure Site Recovery.
Site Recovery supporterà la versione di SQL Server?
Site Recovery è indipendente dall'applicazione. Site Recovery consente di proteggere qualsiasi versione di SQL Server distribuita in un sistema operativo supportato. Per altre informazioni, vedere la matrice di supporto per il ripristino di computer replicati.
Azure Site Recovery funziona con la replica transazionale SQL?
A causa di Azure Site Recovery che usa la copia a livello di file, SQL non può garantire che i server in una topologia di replica SQL associata siano sincronizzati al momento del failover di Azure Site Recovery. Ciò può causare l'esito negativo del lettore di log e/o degli agenti di distribuzione a causa della mancata corrispondenza LSN, che può interrompere la replica. Se si esegue il failover del server di pubblicazione, del server di distribuzione o del sottoscrittore in una topologia di replica, è necessario ricompilare la replica. È consigliabile reinizializzare la sottoscrizione a SQL Server.
Passaggi successivi
- Altre informazioni sull'architettura di Site Recovery.
- Per SQL Server in Azure, altre informazioni su soluzioni a disponibilità elevata per il ripristino in un'area di Azure secondaria.
- Per il database SQL, altre informazioni sulle opzioni di continuità aziendale e disponibilità elevata per il ripristino in un'area di Azure secondaria.
- Per i computer SQL Server in locale, altre informazioni sulle opzioni di disponibilità elevata per il ripristino in Macchine virtuali di Azure.